web
HTTP协议
flowchart LR
v1(HTTP1.1-1999年) --分帧复用--> v2(HTTP2-2015年)
v2 --tcp转向udp-->v3(HTTP3-2021年)
-
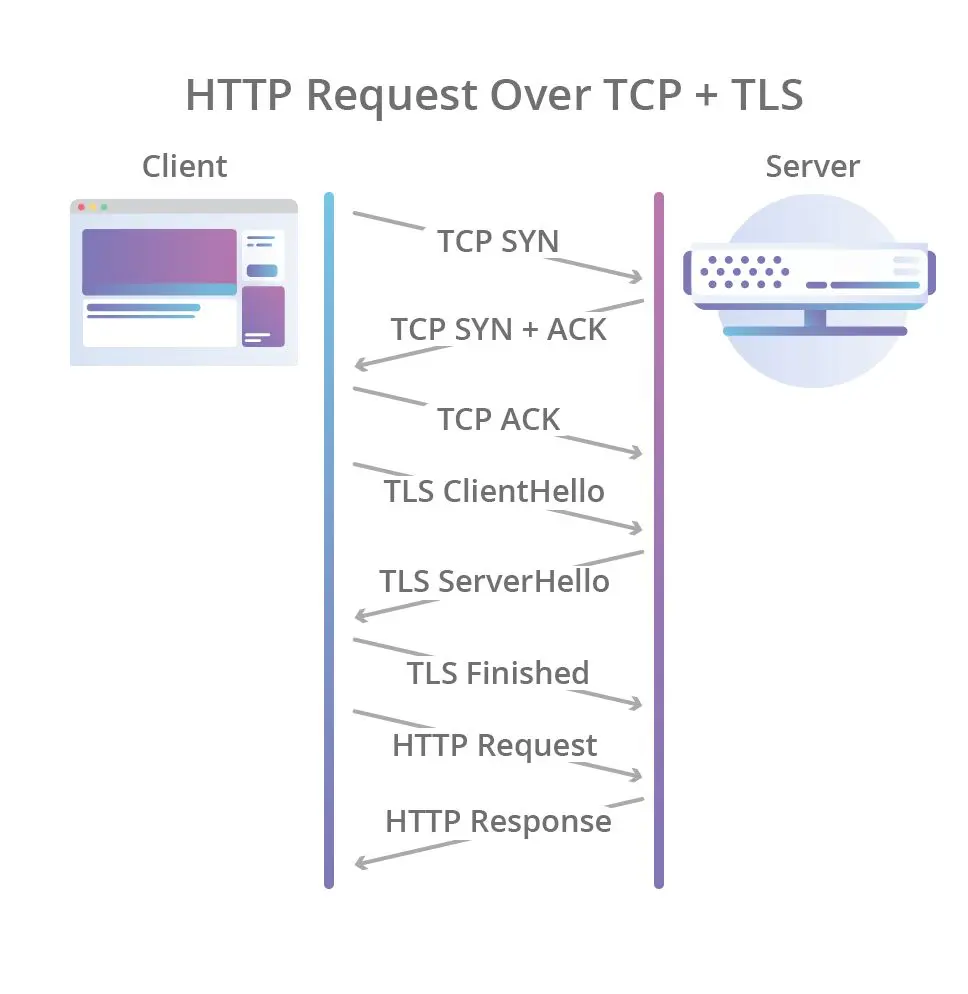
HTTP不变的协议过程
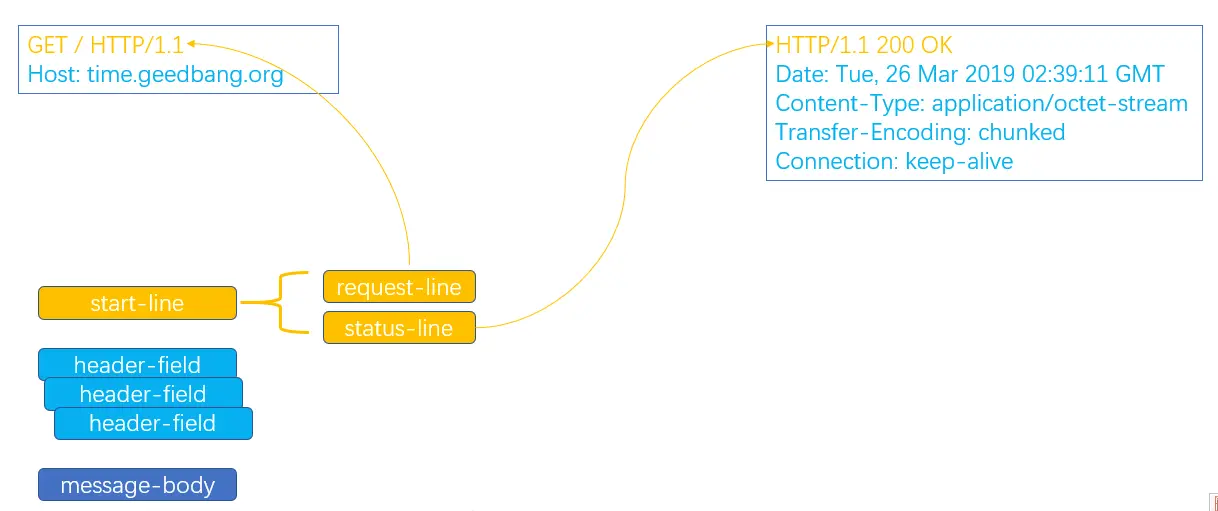
-
HTTP底层传输变化
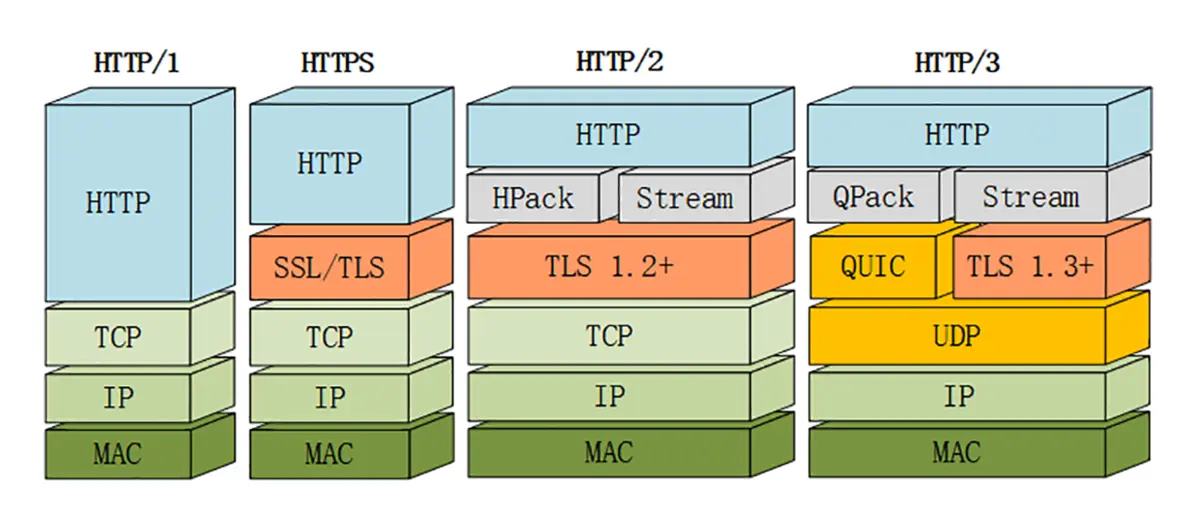
-
HTTP1.1改进
- 默认持久连接
- 增加Cookie,虚拟主机,动态内容支持
- 使用CDN的实现域名分片机制
-
HTTP1.1问题
- TCP的慢启动
- 多条TCP连接竞争带宽
- 队头阻塞
-
HTTP2改进
- 二进制分帧层
- 请求的优先级
- 服务器推送
- 头部压缩
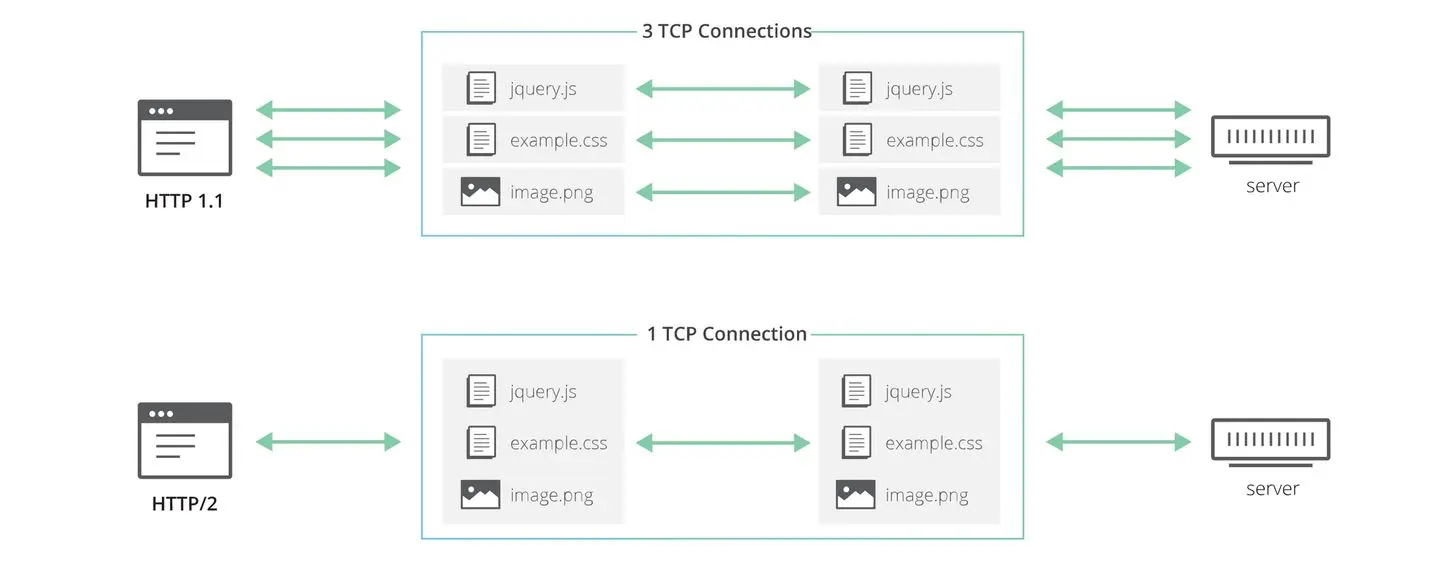
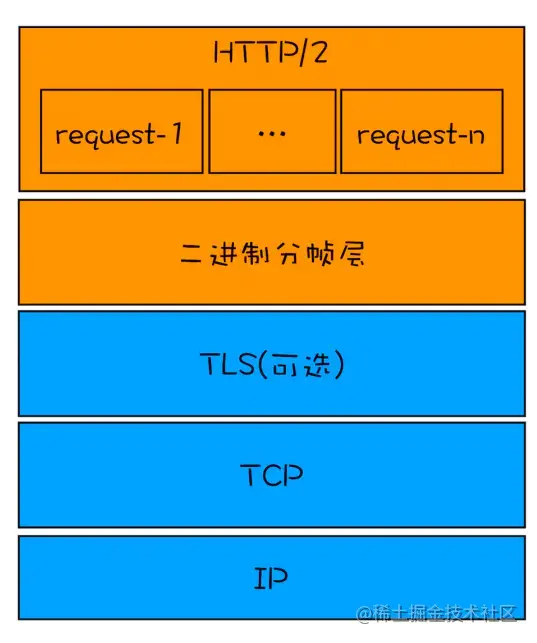
-
HTTP2问题
- 有序字节流引出的队头阻塞(Head-of-line blocking),使得HTTP2的多路复用能力大打折扣
- TCP与TLS叠加了握手时延,建链时长还有1倍的下降空间
- 基于TCP四元组确定一个连接,这种诞生于有线网络的设计,并不适合移动状态下的无线网络,这意味着IP地址的频繁变动会导致TCP连接、TLS会话反复握手,成本高昂。
-
HTTP3改进
- HTTP3基于UDP协议重新定义了连接,在QUIC层实现了无序、并发字节流的传输,解决了队头阻塞问题
- HTTP3重新定义了TLS协议加密QUIC头部的方式,既提高了网络攻击成本,又降低了建立连接的速度
- HTTP3 将Packet、QUIC Frame、HTTP3 Frame分离,实现了连接迁移功能,降低了5G环境下高速移动设备的连接维护成本
jwt(JSON Web Token)
-
是为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准((RFC 7519).该token被设计为紧凑且安全的,特别适用于分布式站点的单点登录(SSO)场景。
-
服务器采用秘钥签名检验token内部数据是否正确,不再保存session
-
传统session方案,占用内存,不易扩展
sequenceDiagram
actor u as 用户
actor s as 服务器
u->>s: login登陆
s-->>u: form填写用户名密码
u->>s: Post用户名密码
s->>s: 数据库检查,生成并保存session
s-->>u: setcookie sessionID
u->>s: cookies带上sessionID
s->>s: 根据sessionID,获取session
s-->>u: 提供服务
- jwt方案,服务器私用secret,除过期时间之外,token不易作废
sequenceDiagram
actor u as 用户
actor s as 服务器
u->>s: login登陆
s-->>u: form填写用户名密码
u->>s: Post用户名密码
s->>s: 数据库检查,利用secret生成token
s-->>u: Authorization token
u->>s: Authorization token
s->>s: 根据secret,检验token
s-->>u: 提供服务
- jwt-token构成
flowchart LR
subgraph Header
h(json对象base64编码)
end
subgraph Payload
p(json对象base64编码)
end
subgraph Signature
s(加密计算后base64编码)
end
Header--用点号.连接-->Payload--用点号.连接-->Signature
- Header示例
{
"alg": "HS256",
"typ": "JWT"
}
- Payload示例
{
"sub": "1234567890",
"name": "John Doe",
"admin": true
}
- Signature
HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
secret)
- 实例展示
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
系统容错 限流-熔断-降级
- 限流,当核心服务的处理能力不能应对外部请求的突增流量时,必须采取限流的措施。
- 熔断,非核心服务
sequenceDiagram
actor u as 用户
actor l as 断路器
actor s as 服务
u->>l: 请求
l->>s: 转发请求
s-->>l: 成功回包
l-->>u: 转发成功回包
u->>l: 请求
l->>s: 转发请求
s-->>l: 失败
l->>l: 累计失败,达到阀值
l-->>u: 转发失败
u->>l: 请求
l->>l: 检查服务恢复?
l-->>u: 回包失败
-
服务熔断是指调用方访问服务时通过断路器做代理进行访问,断路器会持续观察服务返回的成功、失败的状态,当失败超过设置的阈值时断路器打开,请求就不能真正地访问到服务了。
-
CLOSED:默认状态。断路器观察到请求失败比例没有达到阈值,断路器认为被代理服务状态良好。
-
OPEN:断路器观察到请求失败比例已经达到阈值,断路器认为被代理服务故障,打开开关,请求不再到达被代理的服务,而是快速失败。
-
HALF OPEN:断路器打开后,为了能自动恢复对被代理服务的访问,会切换到半开放状态,去尝试请求被代理服务以查看服务是否已经故障恢复。如果成功,会转成CLOSED状态,否则转到OPEN状态
-
降级-采用预设方案行动,针对非核心,非必要服务
webdav
- WebDAV (Web-based Distributed Authoring and Versioning) 一种基于 HTTP 1.1协议的通信协议。
- 它扩展了HTTP 1.1,在GET、POST、HEAD等几个HTTP标准方法以外添加了一些新的方法,
- 使应用程序可对Web Server直接读写,并支持写文件锁定(Locking)及解锁(Unlock),还可以支持文件的版本控制。
jsonnet
brew install jsonnet
优化方向
-
浏览器处理缓存,如下图所示

-
webpack打包
-
图片换格式WebP
-
浏览器处理HTML


优秀网站
-
Confluence-团队文档,据说现在不能私有部署
国内cdn介绍
- BootCDN: www.bootcdn.cn
- 七牛云: www.staticfile.org
- 360: cdn.baomitu.com
- 字节跳动: cdn.bytedance.com
- 饿了么:github.elemecdn.com npm.elemecdn.com
- 知乎:unpkg.zhimg.com
mac
码农必备
1. iTerm2
-
配置cmd+u切换窗口透明


-
快速ssh
-
创建一个profile脚本
vim aliyun_iterm2_profile #填写模板内容,替换主机地址和密码,有可能第一次需要手动ssh root@xxxx,添加信任主机 #!/usr/bin/expect -f set user root set host ip set password pwd set timeout -1 spawn ssh $user@$host expect "*password:*" send "$password\r" interact expect eof #增加可执行权限 chmod a+x aliyun_iterm2_profile -
增加profile配置

command要从login shell->command,上图中红色圈圈
上图中红色方框填入第一步profile路径
-
选择执行profile

-
-
替代品wrap
- 安装时需要注册帐户,目前采用github授权,最好翻墙,否则会完成不了整个过程
2. brew
![]()
3.oh-my-zsh
-
安装命令
# 如果github访问不了,导致安装不了.则采用国内源安装 # /bin/zsh -c "$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrew.sh)" sh -c "$(curl -fsSL https://raw.github.com/ohmyzsh/ohmyzsh/master/tools/install.sh)" -
常用插件
plugins=( git docker extract dnf colored-man-pages command-not-found zsh-syntax-highlighting zsh-autosuggestions ) 历史记录采用年月日 HIST_STAMPS="yyyy-mm-dd" 在~/.zshrc配置文件里设置ZSH_THEME为你的主题名称 ZSH_THEME="robbyrussell" alias cd="z" alias ping="gping" alias ps="procs -tree" alias du="dust" alias df="duf" alias ls="exa -l --header --git" alias cat="bat" eval "$(mcfly init zsh)" eval "$(zoxide init zsh)"- zsh-syntax-highlighting
- zsh-autosuggestions
- extract 所有类型的文件解压一个命令x全搞定,再也不需要去记tar后面到底是哪几个参数了。
- command-not-found 当你输入一条不存在的命令时,会自动查询这条命令可以如何获得
- zoxide代替cd,可能不用启动z
- 提供一个 z 命令,在常用目录之间跳转。类似 autojump,但是不需要额外安装软件。
- gping图形化显示ping结果
- colored-man-pages 给你带颜色的 man 命令
- docker 自带插件,可以实现docker命令补全和自动提示。
- difft 自带语法比较,可以替代diff
# Set git configuration for the current repository. git config diff.external difft # Set git configuration for all repositories git config --global diff.external difft- 官方还提供了大量插件,大部分是针对某些功能的命令补全,如golang, python, pip, ruby, vagrant等。
# 显示最近10条历史命令 history [start] [end],正数从头,负数从尾 history -E -10- 禁止自动更新
打开ohmyzsh(zsh) 的配置文件: ~/.zshrc 找到DISABLE_AUTO_UPDATE一行,将行首的注释'#'去掉,则可禁用ohmyzsh 自动检查更新。
4. vscode
Visual Studio Code 有一个广泛的扩展市场,可以增加你的便利度。但在安装其中一个之前,最好先看看它是否还没有原生支持。随着时间的推移,包含改进和功能的每月发布更新,越来越多的 Visual Studio Code 扩展将不再需要。“有一堆扩展是 bulitin 的,你可以禁用所有你不需要的。进入扩展面板,搜索 @builtin”
-
优秀插件
-
tabnine 有免费的AI助手编码,必须强赞一下
-
CodeGeex 另一个自动生成代码 https://codegeex.cn/
-
shellman shellcheck shell-format(Alt+Shift+F) Code Runner
-
NGINX Configuration Language Support
-
Go for Visual Studio Code 支持一键生成单元测试
-
Python
-
MongoDB for VS Code
-
Redis For VS Code
-
MySQL
-
vscode-drawio 直接在vscode中画图
-
docker
-
toml
-
yaml
-
vscode-pdf
-
Markdown PDF
-
Markdown Preview Mermaid Support
-
vscode-proto3 在.vscode里面的settings.json设置protoc及相关路径
-
JumpProtobuf 在.proto文件跳转f12键
-
Git History
-
GitLens — Git supercharged
-
indent-rainbow
-
vscode-icons用icon标识不同文件
-
Better Comments用不同色彩展示注释
-
Error Lens加强错误显示
-
Project Dashboard把经常使用project固定到仪盘表中
-
CodeSnap 是一个代码截图插件,只需选中项目中相应的代码段,即可快速创建代码的截图。
-
tabnine-AI写代码帮助https://www.tabnine.com/
-
Copilot-AI写代码帮助https://github.com/features/copilot/,tabnine类似
-
Output Colorizer *.log文件彩色输出
-
vscode-database-client 高级使用需要收费 https://github.com/cweijan/vscode-database-client
-
swagger preview-可以设置端口,直接测试接口
-
Hex Editor 以16进制格式查看文件
-
Rainbow CSV
-
Rainbow Brackets
-
Excel Viewer
-
Prettify JSON
-
Path Autocomplete
-
SQL Formatter
-
Regex Previewer
-
Code Spelling checker
-
English word hint
-
Peacock 自定义标题栏及左侧的颜色,同时打开多个vscode有用
-
vscode-fileheader 插入文件头注释,并且自动更新时间及作者
-
-
自带markdown preview功能,cmd+shift+v
-
tab/shift+tab整体正/反缩进,cmd+click跳进,ctrl+-跳回
-
已知bug
-
vscode打开目录层次不对,应该直接打开工程目录,不能打开父目录,否则报下面错误
could not import github.com/gomodule/redigo/redis (cannot find package "github.com/gomodule/redigo/redis" in any of /usr/local/go/src/github.com/gomodule/redigo/redis (from $GOROOT) /Users/.../gopath/src/github.com/gomodule/redigo/redis (from $GOPATH)) -
自动保存可能会自动插入空格,在生成代码文件,需要注意,可能造成bug.
-
-
修改go test timeout超时
- 点击左下角齿轮->设置 打开用户设置
- 在搜索栏中输入 go test timeout
- 可以找到 go.testTimeout为30s
-
工作空间 workspace多个目录一起打开,组合
-
命令行直接调用
- 命令面板(shift+cmd+p)
- 输入shell command
- 选择Install ‘code’ command in PATH
- 命令行输入code .
-
代码片断
- 打开vscode,file–>preference(首选项)—>user snippets(用户代码片断),输入python回车,添加如下代码:
"Print with space lines": { "prefix": "ppp", "body": [ "print('\\n'*2, $1)", ], "description": "Print with space lines" }

然后在编写python程序 时候,连续按ppp就可以快捷输出打印变量。
5. fig大幅度提高效率

# 下载安装保存位置
~/.local/bin
- 需要填写邮箱用来同步设置,否则没有效果
6. webp converter批量转换webp格式,appstore免费

7. Atomgithub开源免费文本编辑器,已死掉了


- 优秀插件
- simplified-chinese-menu
- go-plus
- markdown-writer
- platformio-ide-terminal
- file-icons
- regex-railroad-diagram
8. sublimetext,闭源可免费使用文本编辑器

-
安装打开终端插件 terminus
-
cmd+shift+p 然后输入 install package 输入 terminus
-
配置key
{ "keys": ["ctrl+`"], "command": "toggle_terminus_panel", }, { "keys": ["ctrl+shift+`"], "command": "terminus_open", "args": { "cwd": "${file_path:${folder}}" } },
-
-
安装语法高亮nginx配置文件插件 sublime-nginx/Nginx Log Highlighter
- cmd+shift+p 然后输入 install package 输入 nginx
-
安装shell脚本语法高亮插件 Pretty Shell
- cmd+shift+p 然后输入 install package 输入 Pretty Shell
-
安装markdown插件 markdown Editing
- cmd+shift+p 然后输入 install package 输入 [markdown Editing]
-
Rainbow Brackets
-
Git
-
GitGutter 更进一步
-
GitSyntaxes
-
tabnine插件
-
AutoFileName
-
Pretty JSON
-
Pretty Protocol buf
-
Protocol Syntax Highlighting
-
FileIcons
-
SQL Formatter
-
advanced CSV
-
Rainbow CSV
-
JsFormat
-
HTMLBeautify
-
docker file lint/ docker high light
-
chinese localization––中文汉化
-
chinese words cutter-中文分词
-
主题及color主题是两种,可以分开选择
-
SideBar Enhancements
vim ~/.zshrc
# Set Sublime Text Alias
alias subl="'/Applications/Sublime Text.app/Contents/SharedSupport/bin/subl'"
# 使配置生效
source ~/.zshrc
# 打开sublime
subl
# 使用sublime打开当前目录
subl .
9. chrome,无google全家桶的chrome
brew install --cask eloston-chromium
10. marktext,开源免费的markdown编辑器
brew install --cask eloston-chromium
利用蓝牙传输文件
-
在“系统偏好设置“->“蓝牙”开启功能
-
等待发现蓝牙设备,连接设备,在设备上同意配对
-
mac向设备传输文件使用“蓝牙文件交换”(位于“应用程序”文件夹的“实用工具”文件夹中)
-
设备向mac传输文件,则mac设置蓝牙共享,“系统偏好设置”->“共享”
-
蓝牙传输超慢,建议采用局域网sftp,mac自带sftp服务
无法验证开发者

解决办法:在Finder中找到应用程序,并找到该程序,右键->打开

“xxx.app”已损坏,无法打开。 你应该将它移到废纸篓
- 终端执行,打开允许任意来源app
sudo spctl --master-disable
- 手动执行相信特定app
sudo xattr -rd com.apple.quarantine /Applications/xxx.app/
- 系统设置–>隐私性及安全–>调回只任信store及开发者,防止其他app误操作
开机启动
-
Login Items
- 在~/Library/Preferences/com.apple.loginitems.plist
- 在系统偏好设置的“用户与群组”下面进行设置,可以删除、添加、开启和关闭;
-
Launchd Daemon,launchd来负责启动
- ~/Library/LaunchAgents
- /Library/LaunchAgents
- /System/Library/LaunchAgents
- ~/Library/LaunchDaemons
- /Library/LaunchDaemons
- /System/Library/LaunchDaemons
-
StartupItems
- /System/Library/StartupItems
- /Library/StartupItems
技巧
- 在命令行打开访达当前目录
open 特定目录
open .
- 截屏 shift+cmd+5 非常不错,谁用知道
- 朗读-读出所选内容(option+ecs),如果没有效果,则可能系统声音选择不对,本机器上反应有点慢,要等几秒才能读。
- mac字体路径 /System/Library/Fonts,/Library/Fonts,ttf是mac和freetype共同推出的字体文件,ttc是ttf的集合文件(https://www.cnblogs.com/fortunely/p/16651504.html)
- 目前苹果有intel和M1芯片两种,软件下载安装时,注意Mac silicon/arm64/aarch指明适用M1芯片
- xcode默认只有英文界面,不支持中文界面
- iphone采用数据线连上mac,在新版的mac上没有iTunes,在访达偏好设置中有一个显示ios设备选项,否则无法显示出来!
- AppleID网络iCloud同步,前面打勾就会自动上传或下载同步iCloud空间中,
- iCloud云盘是iCloud空间一个目录,本地也有一个对应目录
- 照片也是iCloud空间一个目录,本地也有一个对应目录
- 其他华为,小米帐号iCloud空间都是类似的

- 查看端口
lsof -i tcp:8080
- 查看本机地址
# mac把Wi-Fi称为en0
ifconfig en0
-
修改hosts sudo vim /etc/hosts
-
深色模式,保护眼睛
-
删除Microsoft Auto Update,烦人的更新提示
cd /Library/Application Support/Microsoft/MAU2.0 sudo rm -rf Microsoft\ AutoUpdate.app -
树状显示目录tree
brew install tree tree -
十六进制显示文件
# xxd系统自带,-l只显示开头40字节 xxd -l 40 filename -
访达/系统按键
名称 作用 回车键 重命名文件夹或文件 command + o 打开文件 command + ↓ 打开文件 command + ↑ 进入当前目录的上一级目录 空格键 预览 -
imagemagick 图像处理神器
brew install imagemagick
# 注意参数位置density是修饰pdf,否则会采用默认72dpi
magick convert -density 300 enroll-sch.pdf -resize 1330x1900 -quality 100 ./photo/enroll-sch.jpg
- ssh免密登录远程
# 输入密码就能实现远程免密登陆,本质上pub文件内容加到远程机器~/.ssh/authorized_keys文件中
ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.0.104
-
鼠标按windows滚动
- 打开Mac系统偏好设置
- 在系统偏好设置界面,点击“鼠标“
- 进入鼠标的设置窗口,单击“光标与点按“标签
- 在光标与点按设置面板,将“滚动方向:自然“的勾选去掉即可
- 然后在滑动鼠标,即和windows的滚轮一样了
-
替换按键ctrl+alt

-
mac电脑的默认字体-苹方字体,中文就是-苹方-简,有专门的“字体册“app管理
-
编程仅好字体 Menlo, Monaco, ‘Courier New’, monospace 12大小
-
socket: operation not permitted - socket 无权限监听问题,一次性给root权限
sudo chown root:admin xxx
sudo chmod +sx xxx
pip(3)error: externally-managed-environment解决办法,增加参数
pip install websocket
pip install --break-system-packages websocket
pip3 install -U uiautomator2 --break-system-packages
pip3 install -U uiautodev --break-system-packages
AI工具与工作流日常
在日常学习与工作中,习惯使用多种AI工具和自动化命令行工具来提升效率。以下是在不同场景下常用的几款工具。
1. 文心一言
- 用途:主要用于中文内容创作和多模态任务,例如撰写文章、生成文案、图像描述等。
- 特点:百度出品,中文理解能力强,支持图文生成。
- 使用场景:当我需要快速生成高质量的中文文本时,文心一言是我首选的工具之一。
2. 豆包
- 用途:作为多语言助手,豆包在翻译、跨语言沟通和日常问答中表现出色。
- 特点:字节跳动开发,支持多语言切换,界面简洁。
- 使用场景:在处理国际化内容或需要多语言支持时,豆包能提供快速响应。
3. 千问(Qwen)
- 用途:我日常使用千问进行代码生成、逻辑推理和多语言写作。
- 特点:由阿里巴巴开发,训练数据丰富,支持多种编程语言和复杂推理任务。
- 使用场景:在开发和写作中,千问帮助我快速生成代码片段、分析问题和撰写专业内容。
4. 月之暗面
- 用途:主要用于深度对话和推理任务。
- 特点:具备较强的上下文理解和推理能力,适合长时间对话。
- 使用场景:当我需要进行复杂的逻辑推理或长时间的对话交互时,月之暗面是理想选择。
5. iflow cli
- 用途:这是一个命令行自动化工具,用于简化工作流程。
- 特点:支持任务自动化、脚本执行和工作流管理。
- 使用场景:在日常开发和运维中,iflow cli帮助我自动化重复性任务,节省时间。
总结:这些工具各有所长,根据不同的任务需求灵活选择。文心一言和豆包适合语言和内容生成,千问和月之暗面在推理和对话上表现突出,而iflow cli则是自动化工作流的得力助手。
智能体=大模型+SKILL+MCP
如果把智能体(Agent)比作一个**“活生生的人”**,那么你的这个等式可以完美拆解为:
- 大模型 (LLM) = 大脑(思考与决策)
- SKILL = 本事(会开车、会做饭、会修电脑)
- MCP = 神经系统(连接大脑与手脚的通道)
1. 大模型 (LLM):大脑
这是智能体的**“认知核心”**。
- 它负责什么: 理解用户说的话(自然语言理解)、思考怎么解决问题(推理规划)、决定下一步该调用哪个技能(决策)。
- 没有大脑会怎样: 就像植物人,虽然有手有脚(有技能),但动不了。
2. SKILL:本事/手脚
这是智能体的**“能力单元”**。
- 它负责什么: 真正去“干活”。比如“发邮件”是一个 Skill,“画图”是一个 Skill,“查天气”也是一个 Skill。
- 没有 Skill 会怎样: 就像一个只会夸夸其谈的书呆子。你问它“帮我订张机票”,它只能说“好的,正在为您查询…”,但实际根本动不了手。Skill 是具体执行动作的实体。
3. MCP:神经系统/USB接口
这是智能体的**“连接标准”**。
- 它负责什么: 建立大模型和 Skill 之间的通信。它告诉大模型:“外面有这些 Skill 可以用”,并且负责把大模型的指令(“我要用这个 Skill”)翻译成 Skill 能听懂的代码格式(API 调用),再把 Skill 执行的结果传回给大模型。
- 没有 MCP 会怎样: 大脑想动脚,但神经断了,脚根本收不到信号。或者就像你有一个 Type-C 接口的手机(Skill),但充电器是老式圆孔的(不兼容),插不上,没法用。
🚀 举个例子:点外卖
假设用户的指令是:“饿了,帮我点一份麦当劳,送到工位。”
-
大脑(大模型) 开始思考:
- “用户饿了,需要食物。”
- “我需要调用‘点外卖’这个能力。”
- “但我还需要知道他的地址和手机号。”(可能会先调用“获取个人信息”的Skill)
-
神经系统(MCP) 开始工作:
- 大脑通过 MCP 协议喊话:“谁有‘点外卖’这个 Skill?”
- MCP 发现有一个“美团外卖”的 Skill 接在系统上。
- MCP 建立连接通道。
-
本事(SKILL) 开始执行:
- “点外卖 Skill” 接收到参数(麦当劳、地址)。
- 它自动运行代码,打开浏览器,登录账号,搜索店铺,下单支付。
-
反馈:
- Skill 把“下单成功”的消息通过 MCP 传回给大脑。
- 大脑对你说:“老板,饭点好了,预计20分钟后到。”
总结
公式 智能体 = 大模型 + SKILL + MCP 完美概括了现代 AI 智能体的架构:
- 大模型 负责 “想” (策略)
- SKILL 负责 “做” (执行)
- MCP 负责 “连” (通信)
有了这三样,AI 才从一个**“聊天机器人”(只能动嘴),进化成了一个“数字员工”**(能动手、能跑腿)。
最简单的智能体
用 Python 实现一个“最简单”的智能体,核心其实就是搭建一个**“大脑循环”。这个循环非常精简,只做一件事:规划 -> 决策(选动作) -> 执行 -> 输出。 用一个“懒人点餐助手”**为例。这个智能体有两个核心能力(技能):搜索(查餐厅)和 Finish(给出最终回答)。
import os
import json
import requests
# ============ 配置区 ============
# 替换为你的 API Key
API_KEY = "your-api-key-here"
BASE_URL = "https://api.deepseek.com" # DeepSeek 的接口地址
# ============ 工具定义 (你的 Skill 库) ============
# 这是智能体的“技能包”,告诉模型它能做什么
TOOLS = [
{
"type": "function",
"function": {
"name": "search_restaurant",
"description": "根据用户需求搜索附近的餐厅",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "用户想吃的菜系或餐厅名,例如 '川菜'、'火锅'"
}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "final_response",
"description": "当信息收集完毕,用来给用户最终回复",
"parameters": {
"type": "object",
"properties": {
"final_message": {
"type": "string",
"description": "给用户的最终回复内容"
}
},
"required": ["final_message"]
}
}
}
]
# ============ 工具函数 (真正干活的代码) ============
def search_restaurant(query):
"""模拟搜索餐厅的函数"""
print(f"\n[工具调用] 正在搜索: {query}...")
# 这里可以接入真实的高德/美团API,这里用模拟数据
return f"为您找到以下餐厅:1. 老王川菜馆(评分4.8) 2. 麻辣江湖(评分4.6) 3. 川味一绝(评分4.5)"
def final_response(final_message):
"""输出最终结果"""
print(f"\n[结束] 智能体说: {final_message}")
return "任务完成"
# ============ 智能体核心循环 ============
def run_agent(user_input):
# 1. 初始化消息历史
messages = [{"role": "user", "content": user_input}]
print(f"[输入] 用户说: {user_input}")
while True:
try:
# 2. 调用大模型 (大脑)
response = requests.post(
f"{BASE_URL}/chat/completions",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
json={
"model": "deepseek-chat", # 使用 DeepSeek 模型
"messages": messages,
"tools": TOOLS, # 告诉模型有哪些技能
"tool_choice": "auto" # 自动选择技能
}
)
# 3. 解析模型返回
resp_json = response.json()
message = resp_json.choices[0].message
# 4. 判断模型是否想调用工具
if message.tool_calls:
# --- 决策:模型选择了某个 Skill ---
tool_call = message.tool_calls[0]
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
print(f"[思考] 嗯...我需要调用 '{tool_name}' 这个技能来解决。")
# 把模型的回复加到历史里(记录它的思考)
messages.append(message)
# --- 执行:运行具体的 Skill 代码 ---
if tool_name == "search_restaurant":
tool_result = search_restaurant(tool_args["query"])
elif tool_name == "final_response":
final_response(tool_args["final_message"])
break # 结束循环
# --- 反馈:把工具执行的结果告诉模型 ---
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"name": tool_name,
"content": tool_result
})
else:
# 模型直接给出了答案(没有调用工具)
print(f"[结束] 智能体说: {message.content}")
break
except Exception as e:
print(f"发生错误: {e}")
break
# ============ 运行测试 ============
if __name__ == "__main__":
# 测试:用户输入
run_agent("我想吃火锅,帮我推荐几家附近的。")
第三步:代码解析(智能体的四大要素)
运行这段代码,发现它其实就包含了智能体的所有核心要素:
-
大脑(LLM):
requests.post(...)这一部分就是调用大模型。- 它负责思考:是直接回答,还是去查餐厅?
-
技能(Skills/Tools):
TOOLS列表定义了智能体能做什么。search_restaurant是一个 Skill(查餐厅)。final_response是另一个 Skill(结束对话)。
-
规划与决策(The Loop):
while True循环就是智能体的“心跳”。- 它不断检查:“我需要调用工具吗?” -> “调用哪个?” -> “执行结果是什么?” -> “下一步怎么做?”。
-
执行(Function Call):
if tool_name == ...这一段就是真正执行代码的地方。
运行效果
当你运行代码时,输出大概是这样的:
[输入] 用户说: 我想吃火锅,帮我推荐几家附近的。
[思考] 嗯...我需要调用 'search_restaurant' 这个技能来解决。
[工具调用] 正在搜索: 火锅...
[思考] 嗯...我需要调用 'final_response' 这个技能来解决。
[结束] 智能体说: 为您找到以下餐厅:1. 老王川菜馆... (省略)
skill
开发一个 MCP Skill 其实就是编写一个能够响应 MCP 协议请求的程序
第一步:环境准备
你需要安装 MCP 的官方 Python 库。
# 创建项目目录
mkdir mcp-smart-home-skill
cd mcp-smart-home-skill
# 推荐使用虚拟环境
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
# 安装核心库
pip install mcp
第二步:编写 Skill 代码
创建一个 Skill,让它具备“获取天气”和“控制灯光”的能力。
-
创建文件:新建一个文件
smart_home_skill.py。 -
编写代码:
from mcp.server.fastmcp import FastMCP
from mcp.types import TextContent, ImageContent
import requests
import json
# 初始化 MCP Server (也就是你的 Skill)
mcp = FastMCP("SmartHome Skill")
# ==========================================
# Skill 1: 获取天气 (外部 API 调用)
# ==========================================
@mcp.tool()
def get_weather(location: str) -> TextContent:
"""
获取指定城市的天气情况。
注意:这里使用的是模拟数据,实际使用需接入高德/和风等真实API。
"""
# 这里是模拟逻辑,实际开发请替换为真实的 API 调用
# 示例:调用高德地图天气API
# url = f"https://restapi.amap.com/v3/weather/weatherInfo?city={location}&key=你的KEY"
weather_data = {
"city": location,
"weather": "晴",
"temperature": "25°C",
"wind": "微风"
}
result_text = f"【{location}天气】天气:{weather_data['weather']},气温:{weather_data['temperature']},风力:{weather_data['wind']}"
return TextContent(type="text", text=result_text)
# ==========================================
# Skill 2: 控制智能灯 (模拟)
# ==========================================
# 假设我们有一个简单的状态存储
light_status = {"客厅": "关", "卧室": "关"}
@mcp.tool()
def control_light(room: str, action: str) -> TextContent:
"""
控制指定房间的灯光开关。
"""
if room not in light_status:
return TextContent(type="text", text=f"错误:不支持{room}的灯光控制")
# 执行控制逻辑(这里可以替换为发送 MQTT 指令)
if action in ["开", "打开", "on"]:
light_status[room] = "开"
response = f"✅ 已为您打开{room}的灯"
elif action in ["关", "关闭", "off"]:
light_status[room] = "关"
response = f"✅ 已为您关闭{room}的灯"
else:
response = f"❌ 指令错误,不支持的操作:{action}"
# 打印状态用于调试
print(f"灯光状态更新: {light_status}")
return TextContent(type="text", text=response)
# ==========================================
# Skill 3: 查询设备状态
# ==========================================
@mcp.tool()
def get_device_status() -> TextContent:
"""
获取当前所有智能设备的状态。
"""
status_str = "🏠 当前设备状态:\n"
for room, status in light_status.items():
status_str += f" {room}灯:{status}\n"
return TextContent(type="text", text=status_str)
# ==========================================
# 启动入口
# ==========================================
if __name__ == "__main__":
# 运行 MCP Server,等待客户端(如 Cursor)连接
mcp.run(transport='stdio')
第三步:代码解析(Skill 的核心结构)
-
Server 初始化:
mcp = FastMCP("SmartHome Skill"):这行代码定义了你的 Skill 名字。AI 会通过这个名字来识别它能找谁帮忙。 -
Tool 定义(核心能力): 使用
@mcp.tool()装饰器来标记一个函数。每一个被装饰的函数就是一个 Skill。- 函数名:建议使用英文,代表 Skill 的唯一标识。
- 函数文档字符串 (Docstring):极其重要。AI 不读代码,只读注释。它决定了 AI 什么时候会调用这个 Skill。
- 参数:定义好参数类型(str, int),AI 会自动帮你从自然语言中提取参数。
-
返回值格式: MCP 协议要求返回特定的格式(如
TextContent或ImageContent),这样客户端才能正确解析并展示给用户。
第四步:在 Cursor 中配置并测试
-
启动服务: 在终端运行:
python smart_home_skill.py保持这个终端窗口打开。
-
配置 Cursor: 打开 Cursor 设置 -> MCP Servers -> Add Server。
- Name:
SmartHome Skill - Command:
python - Arguments:
/path/to/your/smart_home_skill.py(替换为你的实际路径)
- Name:
-
测试对话: 在 Cursor 聊天框中输入:
“打开客厅的灯,然后查一下北京的天气。”
预期效果: AI 会自动拆解任务,先调用
control_lightSkill,再调用get_weatherSkill,最后把结果整合回复给你。
进阶:Skill 的工程化
如果Skill 变得很复杂(比如包含多个文件、配置文件、甚至前端界面),你可以参考以下结构:
my-mcp-skill/
├── main.py # 入口文件 (启动 Server)
├── skills/ # 技能包
│ ├── __init__.py
│ ├── weather.py # 天气技能模块
│ ├── light.py # 灯光技能模块
│ └── database.py # 数据库查询技能
├── config.py # 配置文件 (API Keys)
├── pyproject.toml # 打包配置
└── README.md
总结
开发一个 MCP Skill 的本质就是:
- 写函数:想让 AI 做的事情写成 Python 函数。
- 写注释:告诉 AI 这个函数是干什么的、什么时候用。
- 加装饰器:加上
@mcp.tool(),把它暴露给 AI。 - 跑起来:配置好客户端,让 AI 来调用它。
mcp
MCP(Model Context Protocol,模型上下文协议)是由Anthropic公司于2024年11月推出的开放标准协议,旨在为AI模型与外部工具、数据源之间建立标准化、安全、高效的交互框架,彻底解决传统AI应用中“数据孤岛“和“工具碎片化“的痛点问题。
一、MCP的核心定位与价值
MCP本质上是AI领域的“USB-C接口标准“,它让AI应用能够像使用通用电源插头一样,轻松连接各种外部系统,无需为每个工具单独开发适配代码。在MCP出现前,AI与外部数据的连接如同“拼布娃娃“般杂乱无章:
- 硬编码逻辑:每个工具需单独适配
- Prompt链脆弱:依赖特定提示词组合
- 厂商锁定:不同平台需重复开发插件
这导致了臭名昭著的M×N集成问题:假设有M个AI应用和N个工具,理论上需开发M×N种定制化集成方案。而MCP通过引入标准中间层,将开发成本从M×N降至M+N,效率提升高达90%以上。
二、MCP的架构设计与核心组件
MCP采用客户端-服务器架构,包含四个关键角色:
-
MCP Host(宿主):运行AI模型的宿主环境,如Claude Desktop、Cursor IDE或Windsurf Editor等应用
-
MCP Client(客户端):内置于Host中的通信模块,负责与MCP Server建立连接、发送请求并处理响应,是主机端与服务器之间的“通信中介“
-
MCP Server(服务器):轻量级服务端程序,提供具体功能的服务端程序,如GitHub MCP Server、Slack MCP Server、本地文件系统Server等
-
Resources/Tools(资源/工具):实际被访问的数据或服务,如Git仓库、Gmail邮箱、本地数据库等
三、MCP的三大核心能力
MCP Server提供三类标准化能力,让AI模型能够安全、高效地与外部世界交互:
-
Tools(工具):可执行函数,用于执行特定任务
- 示例:数据库查询工具、邮件发送工具、API调用工具
- 特点:通常由AI模型选择触发,涉及文件I/O或网络调用等副作用
-
Resources(资源):只读数据源,供模型读取上下文
- 示例:本地文件、API响应内容、数据库记录
- 特点:为模型提供丰富的上下文信息,增强模型理解能力
-
Prompts(提示):预定义的对话模板
- 示例:生成SQL语句的模板、报告格式规范
- 特点:引导LLM完成特定任务,标准化输入输出
四、MCP的通信机制与技术实现
MCP基于JSON-RPC 2.0协议实现通信,支持两种主要传输方式:
-
本地通信:通过**stdio(标准输入/输出)**传输消息
- 适用场景:本地工具调用(如文件系统、本地数据库)
- 特点:轻量、同步、子进程通信
-
远程通信:基于**SSE(Server-Sent Events)**的HTTP长连接
- 适用场景:远程服务(如Slack、GitHub API)
- 特点:异步、事件驱动、支持长连接
消息格式示例:
{
"method": "call_tool",
"params": {
"tool_name": "sql_query",
"args": {
"query": "SELECT * FROM users"
}
}
}
五、MCP的核心优势
-
简化开发:开发者无需适配各种私有协议,只需连接MCP Server即可
-
提高扩展性:AI应用可通过随时“插拔“新的MCP Server来扩展功能
-
促进生态共享:通过MCP Server的共享,新的AI应用可快速获得各种工具
-
安全可控:敏感操作需用户显式授权,API密钥等凭证由MCP服务器本地管理
-
动态发现:AI可实时发现并集成新工具,无需预定义代码
六、MCP与传统API/Function Calling的对比
| 对比维度 | 传统API/Function Calling | MCP |
|---|---|---|
| 协议标准 | 私有协议(各模型自定规则) | 开放协议(JSON-RPC 2.0) |
| 工具发现 | 静态预定义 | 动态获取(initialize请求) |
| 调用方式 | 同进程函数或API | STDIO/SSE/同进程 |
| 扩展成本 | 高(新增工具需重新调试模型) | 低(工具热插拔,模型无需改动) |
| 适用场景 | 简单任务(单次函数调用) | 复杂流程(多工具协同+数据交互) |
| 生态协作 | 工具与大模型强绑定 | 工具开发者与Agent开发者解耦 |
七、MCP的典型应用场景
-
数据库直连:MCP最革命性的应用场景之一
- 传统RAG依赖向量检索,存在精度低、切片局部性强等问题
- MCP通过结构化查询能力,实现自然语言转SQL,显著提升答案可靠性
- 示例:用户提问“商品表中价格最高的车型是什么?“,MCP自动生成并执行SQL查询
-
智能客服系统:
- 集成CRM系统与订单数据库,自动处理工单
- 效率提升3倍,错误率下降70%
-
自动化运维:
- 通过MCP连接监控系统,自动发现并修复异常
- 某车企实践显示,设备故障预测准确率提升至92%,停机时间减少65%
-
多Agent协作:
- 在复杂任务中,多个Agent通过MCP协同工作
- 例如:财务分析师调取实时市场数据进行公司估值
八、MCP的安全机制
MCP内置多层次安全机制,确保数据交互安全:
-
权限控制:敏感操作(如删除文件、发送消息)需用户显式授权
-
凭证管理:API密钥等凭证由MCP服务器本地管理,不暴露给LLM或Host
-
运行模式区分:
- 本地模式:MCP Client和Server位于同一安全域,无授权但作用范围受限
- 远程模式:需授权,应遵循OAuth规范
-
操作透明化:所有请求以JSON-RPC格式记录,关键步骤需人工授权
九、MCP的未来发展趋势
-
多模态扩展:向图像、音频领域延伸,支持医疗影像分析、实时语音交互
-
行业标准化:有望成为AI与物理世界交互的事实标准(如车联网V2X、智能家居)
-
开源生态壮大:GitHub已有超1500个MCP Server,覆盖支付、设计、运维等领域
-
远程连接支持:MCP项目组正在积极推进Remote MCP Connections的实现,拓展应用范围
十、MCP与SKILL的协同关系
MCP与SKILL是AI智能体能力扩展的“左膀右臂“:
- MCP:提供“访问外部资源“的通道,解决“触达“问题
- SKILL:提供“如何执行任务“的方法论,解决“使用“问题
例如,在财务分析场景中:
- MCP连接标普资本智商(S&P Capital IQ)获取实时数据
- SKILL应用估值模型并格式化输出结果
这种“SKILLS定义流程+MCP连接资源“的协同模式,让AI从“能理解“真正走向“会执行“,成为构建专业级AI智能体的核心架构。
MCP协议正在重塑AI与物理世界的连接方式,如同给“AI武将“配备神兵利器,让开发者能够将非技术人员直接操作数据库、将复杂查询响应时间从小时级压缩至秒级、将运维成本降低50%以上。掌握这一技术的开发者,将率先登上AI 2.0时代的浪潮之巅。
最简单的mcp server
from mcp.server.fastmcp import FastMCP
from mcp.types import TextContent
# 1. 初始化服务器
# -------------------------
# 给你的服务器起个名字,这个名字会显示在客户端里
mcp = FastMCP("Reverse Text Server")
# 2. 定义工具 (Tool)
# -------------------------
# 使用 @mcp.tool() 装饰器来注册一个工具
# AI 会读取函数的注释来决定什么时候调用它
@mcp.tool()
def reverse_text(input_text: str) -> TextContent:
"""
将输入的字符串字符顺序完全反转。
例如:输入 "abc",输出 "cba"。
"""
reversed_str = input_text[::-1] # 核心逻辑:反转字符串
return TextContent(type="text", text=reversed_str)
# 3. 运行服务器
# -------------------------
# 这是程序的入口点
if __name__ == "__main__":
# 使用标准输入输出(STDIO)进行通信
# 这是最简单的模式,适合本地调试
mcp.run(transport='stdio')
lstm
在人工神经网络中,理解LSTM单元(尤其是神经元和记忆细胞之间的关系)需要明确几个层级的概念
-
核心构建单元:LSTM单元/模块
- LSTM网络的基本构建块称为一个 LSTM单元 或 LSTM模块。
- 这个单元负责处理一个时间步的输入,并产生该时间步的输出和传递给下一个时间步的隐藏状态。
- 一个LSTM单元整体可以被视为LSTM网络中的一个“神经元节点”, 与传统神经网络中的神经元节点相对应。它接收输入(当前输入
x_t和上一个隐藏状态h_{t-1}),经过内部复杂的计算,产生输出(当前隐藏状态h_t和可选的本层输出y_t)。
-
LSTM单元的内部结构:记忆细胞与门控机制 一个LSTM单元内部包含几个关键组件,共同协作以实现其长短期记忆能力:
-
记忆细胞:
- 这是LSTM单元最核心的部分,负责存储和传递长期的时序信息。
- 可以把它想象成一个“传送带”或“笔记本”,其状态
C_t在时间步之间相对稳定地传递下去。 C_t的值在时间步之间主要通过线性操作(加法)更新,这大大减轻了梯度消失问题,使得网络能够学习跨越长时间步的依赖关系。- 作用: 它是LSTM能够记住长期信息的物理载体。
-
门控机制:
- LSTM单元包含三个关键的门,它们都是向量(每个元素在0到1之间),控制信息如何流入、保留和流出记忆细胞。每个门本身由一个小型神经网络(通常是Sigmoid激活函数)实现:
- 遗忘门: 决定从上一个记忆细胞状态
C_{t-1}中丢弃哪些信息。输出f_t。 - 输入门: 决定当前候选值
\tilde{C}_t中的哪些新信息将被写入记忆细胞。输出i_t。 - 输出门: 决定基于当前更新后的记忆细胞状态
C_t,输出哪些信息到隐藏状态h_t。输出o_t。
- 遗忘门: 决定从上一个记忆细胞状态
- 作用: 门是调控信息流的开关。它们学习在何时、让多少信息通过,从而保护记忆细胞免受无关信息的干扰,并控制何时将记忆细胞中的信息读出来影响当前输出。
- LSTM单元包含三个关键的门,它们都是向量(每个元素在0到1之间),控制信息如何流入、保留和流出记忆细胞。每个门本身由一个小型神经网络(通常是Sigmoid激活函数)实现:
-
候选记忆细胞值:
- 一个临时的、基于当前输入
x_t和前一个隐藏状态h_{t-1}计算出的新值\tilde{C}_t(通常使用Tanh激活函数)。 - 作用: 它代表了在当前时间步,网络考虑要写入记忆细胞的新信息。输入门最终决定这些候选值中有多少实际被写入。
- 一个临时的、基于当前输入
-
隐藏状态:
- 这是LSTM单元对外的输出之一(
h_t),通常也作为单元自身的状态传递给下一个时间步。 - 它是由输出门
o_t对当前记忆细胞状态C_t(经过Tanh缩放)进行门控得到的:h_t = o_t * tanh(C_t)。 - 作用:
h_t包含了LSTM单元基于当前输入、之前所有历史和当前记忆状态选择要输出的信息。它是下游计算(如预测、传递给下一层)的主要依据。
- 这是LSTM单元对外的输出之一(
-
-
神经元、记忆细胞与LSTM单元的关系:一个清晰的总结
-
层级1:整个LSTM层
- 由多个 LSTM单元/模块 并行组成(类似于一层中有多个神经元)。
- 每个单元处理输入序列中的一个特征维度(或向量元素),并维护自己独立的记忆细胞和门控状态。
-
层级2:单个LSTM单元
- 这是LSTM网络中的基本计算节点,可被视为一个“超级神经元”。
- 它内部包含:
- 一个核心的记忆细胞:用于长期信息存储。
- 三个门控结构:用于调节信息流。
- 一个候选值生成器。
- 一个隐藏状态生成器。
- 记忆细胞是这个“超级神经元”(LSTM单元)内部的一个关键组成部分,专门负责记忆功能。 它不是独立的神经元,而是构成LSTM单元核心功能的元件之一。
-
-
关键区别:传统神经元 vs. LSTM单元 vs. 记忆细胞
概念 描述 与传统神经元类比 在LSTM层级中的位置 传统神经元 接收输入加权和,通过激活函数非线性变换,产生单个输出。 基本单位 N/A LSTM单元 一个复杂的处理单元,包含记忆细胞、门控机制等组件。处理序列数据。 ≈ 一个超级神经元 网络层的基本构建节点 记忆细胞 LSTM单元内部的核心组件,负责存储和传递长期状态 ( C_t)。不是独立的神经元 LSTM单元内部的关键子组件 门控结构 LSTM单元内部的组件(遗忘门、输入门、输出门),由小型神经网络实现。 不是独立的神经元 LSTM单元内部的关键子组件 隐藏状态 LSTM单元的输出 ( h_t),基于记忆细胞和输出门计算得到。≈ 神经元的输出 LSTM单元的输出/状态 -
形象比喻
- 想象一个决策室(LSTM单元)。
- 房间里有一个核心记事板(记忆细胞
C_t),上面记录着长期重要的信息。 - 有三个审查员(门控机制):
- 一个负责擦除记事板上过时或无关的信息(遗忘门
f_t)。 - 一个负责审核新收到的信息草稿(候选值
\tilde{C}_t),决定哪些值得写到记事板上(输入门i_t)。 - 一个负责决定记事板上的哪些信息可以对外公布(输出门
o_t)。
- 一个负责擦除记事板上过时或无关的信息(遗忘门
- 新信息草稿(候选值
\tilde{C}_t)由另一个助手基于当前收到的消息和之前公布的摘要草拟。 - 最终对外发布的摘要(隐藏状态
h_t)是审查员(输出门)允许公布的、来自记事板(记忆细胞)的部分信息。
结论:
在LSTM网络中:
- 基本功能节点是LSTM单元。 一个LSTM单元整体上扮演着类似传统神经网络中一个“神经元”的角色。
- 记忆细胞是LSTM单元内部的核心组件。 它不是独立的神经元,而是构成LSTM单元实现其核心功能(长时记忆)的关键部分。它存储着跨越时间步的状态
C_t。 - 门控结构也是LSTM单元内部的组件。 它们同样不是独立的神经元,而是由小型神经网络实现的调控机制,负责学习如何保护、更新和读取记忆细胞中的信息。
- 隐藏状态
h_t是LSTM单元的主要输出。 它代表了单元在当前时间步根据输入和历史“选择”要传递出去的信息。
因此,简单地说:记忆细胞是LSTM单元(这个“超级神经元”)内部专门负责存储长期信息的关键部件。 没有记忆细胞,LSTM就失去了其解决长期依赖问题的核心能力;没有门控机制,记忆细胞就无法被有效保护和管理;没有LSTM单元这个整体结构,这些组件就无法协同工作处理序列数据。
在人工神经网络中,LSTM(长短期记忆网络)、神经元和记忆细胞的关系可以通过以下层次结构理解:
1. 神经元(Neuron)
- 基础单元:神经元是神经网络的基本计算单元,模拟生物神经元的行为。
- 功能:接收输入信号,通过加权求和和非线性激活函数(如Sigmoid、ReLU)产生输出。
- 传统RNN中的神经元:在简单循环神经网络(RNN)中,神经元通过循环连接传递隐藏状态,但长期依赖问题限制了其记忆能力。
2. LSTM:对神经元的改进
- LSTM单元:LSTM是一种特殊的RNN架构,其核心是LSTM单元(可视为一种“增强型神经元”)。
- 解决长期依赖问题:传统RNN神经元在反向传播时梯度易消失或爆炸,LSTM通过引入门控机制和记忆细胞(Memory Cell)解决这一问题。
3. 记忆细胞(Memory Cell)
- 核心组件:记忆细胞是LSTM单元的核心,负责存储长期状态信息。
- 状态更新:通过三个门控机制(输入门、遗忘门、输出门)动态调整记忆内容:
- 遗忘门:决定保留多少历史信息(控制记忆细胞的“遗忘”)。
- 输入门:决定新信息是否加入记忆细胞(控制信息的“写入”)。
- 输出门:决定记忆细胞对当前输出的影响(控制信息的“读取”)。
- 状态传递:记忆细胞的状态((c_t))在时间步间传递,形成长期依赖的“记忆链”。
三者关系总结
-
LSTM单元 = 神经元 + 记忆细胞 + 门控机制
LSTM通过改造传统神经元结构,将记忆细胞和门控逻辑嵌入其中,使其具备长期记忆能力。 -
记忆细胞是LSTM神经元的“长期记忆载体”
传统神经元的隐藏状态((h_t))仅短期传递,而LSTM的记忆细胞((c_t))通过门控机制实现长期状态保持。 -
门控机制由神经网络实现
输入门、遗忘门、输出门本身是神经网络层(如Sigmoid函数),其权重通过训练学习何时保留或遗忘信息。
类比理解
-
传统RNN神经元:像一张便签纸,每次覆盖写入新内容(短期记忆)。
-
LSTM单元:像一个带锁的保险箱,记忆细胞是保险箱内的“核心文档”,门控机制是三把钥匙:
- 遗忘门(删除旧内容)
- 输入门(添加新内容)
- 输出门(决定是否展示内容)
通过这种设计,LSTM在处理序列数据(如语言、时间序列)时,能够更有效地捕捉长期依赖关系。
conv2d
在卷积神经网络(CNN)中,图像通道数是一个关键概念,它决定了卷积层如何处理输入数据。以下是关于通道数在卷积层中处理方式的详细解释:
1. 图像通道的基本概念
- 通道数:表示图像中每个像素的组成维度。
- 常见场景:
- 灰度图像:单通道(通道数=1),每个像素是一个0-255的数值。
- 彩色图像:三通道(通道数=3),每个像素由RGB三个值表示。
- 多光谱图像:可能有更多通道(如卫星图像的10+通道)。
2. 卷积层如何处理多通道输入?
卷积层通过以下步骤处理多通道输入:
步骤1:每个卷积核包含多个通道
- 对于输入图像的每个通道,卷积核都有一个对应的子核。
- 例如:输入为3通道图像,卷积核大小为3×3,则每个卷积核实际包含 3个3×3的子核,总尺寸为 3×3×3。
步骤2:各通道并行卷积后求和
- 每个子核对对应通道进行卷积运算,生成中间特征图。
- 将所有中间特征图逐元素相加,得到一个单通道的输出特征图。
步骤3:多个卷积核生成多个输出通道
- 卷积层中的每个卷积核独立执行上述操作,最终生成的输出通道数等于卷积核的数量。
示例:
输入:32×32×3的RGB图像
卷积层参数:filters=16, kernel_size=(3,3)
处理过程:
- 每个卷积核尺寸为 3×3×3(3个子核,对应3个输入通道)。
- 每个卷积核生成1个单通道的特征图。
- 16个卷积核共生成 16个通道 的输出特征图,尺寸为30×30×16(假设padding=“valid”)。
3. 数学表达式与计算示例
对于输入图像 $X \in \mathbb{R}^{H \times W \times C_{\text{in}}}$ 和卷积核 $K \in \mathbb{R}^{k \times k \times C_{\text{in}}}$,输出特征图 $Y \in \mathbb{R}^{H’ \times W’}$ 的计算过程为:
$$ Y_{i,j} = \sum_{c=1}^{C_{\text{in}}} \sum_{m=1}^{k} \sum_{n=1}^{k} K_{m,n,c} \cdot X_{i+m,j+n,c} + b $$
其中:
- $Y_{i,j}$ 是输出特征图的第 $(i,j)$ 个位置的值。
- $K_{m,n,c}$ 是卷积核在第 $c$ 个通道的 $(m,n)$ 位置的值。
- $b$ 是偏置项。
计算示例:
输入通道数 $C_{\text{in}}=3$,卷积核大小 $k=3$,输出通道数 $C_{\text{out}}=16$,则:
- 每个卷积核的参数数量:$3 \times 3 \times 3 + 1 = 28$(+1为偏置)。
- 整个卷积层的参数数量:$28 \times 16 = 448$。
4. Keras代码示例
from tensorflow.keras import layers, models
# 输入:32×32×3的RGB图像
model = models.Sequential()
model.add(layers.Conv2D(
filters=16, # 16个卷积核 → 输出16个通道
kernel_size=(3, 3), # 卷积核大小3×3
activation='relu',
input_shape=(32, 32, 3) # 输入通道数=3
))
# 查看模型结构
model.summary()
输出分析:
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 16) 448
=================================================================
- 输出形状
(30, 30, 16):每个卷积核生成30×30的特征图,16个卷积核共16个通道。 - 参数数量448:由 $(3 \times 3 \times 3 + 1) \times 16$ 计算得出。
5. 关键要点总结
-
卷积核深度 = 输入通道数:
每个卷积核必须包含与输入通道数相同的子核,以处理多通道数据。 -
输出通道数 = 卷积核数量:
卷积层通过多个卷积核提取不同特征,输出通道数由filters参数决定。 -
通道间信息融合:
通过对各通道的卷积结果求和,卷积层隐式融合了不同通道的信息(例如RGB通道的颜色与纹理特征)。 -
参数效率:
相比全连接层,卷积层通过参数共享大幅减少参数量,适合处理高维图像数据。
常见问题解答
(1) 输入通道数与输出通道数有什么关系?
- 输入通道数决定每个卷积核的深度(子核数量)。
- 输出通道数由卷积核数量独立控制,与输入通道数无关。
(2) 如何处理单通道图像(如灰度图)?
- 输入通道数设为1,卷积核尺寸为 $k \times k \times 1$。
- 例如:
input_shape=(28, 28, 1),卷积核参数为kernel_size=(3, 3)。
(3) 通道数与特征表达能力的关系?
- 更多输出通道(卷积核)可以提取更丰富的特征,但会增加计算量和过拟合风险。
- 通常随着网络加深,通道数逐渐增加(如从32→64→128),以捕获更抽象的特征。
在Keras(TensorFlow的高级API)里,Conv2D 是二维卷积层,主要用于处理具有网格结构的输入数据,像图像数据就是常见的应用场景。它借助卷积操作来提取输入数据的特征,在计算机视觉领域应用十分广泛。下面为你详细剖析 Conv2D 的核心参数和工作机制:
核心参数解读
keras.layers.Conv2D(
filters, # 卷积核数量,决定输出特征图的通道数
kernel_size, # 卷积核大小,例如(3, 3)或5
strides=(1, 1), # 卷积步长
padding="valid", # 填充方式,"valid"(不填充)或"same"(填充使输出尺寸与输入相同)
data_format=None, # 数据格式,"channels_last"(默认)或"channels_first"
dilation_rate=(1, 1), # 空洞卷积扩张率
activation=None, # 激活函数,如"relu"
use_bias=True, # 是否使用偏置项
kernel_initializer="glorot_uniform", # 卷积核权重初始化方法
bias_initializer="zeros", # 偏置项初始化方法
kernel_regularizer=None, # 卷积核权重正则化
bias_regularizer=None, # 偏置项正则化
activity_regularizer=None,# 输出的正则化函数
kernel_constraint=None, # 对卷积核权重的约束
bias_constraint=None # 对偏置项的约束
)
工作机制详解
- 卷积操作: 卷积核在输入数据上进行滑动,对每个局部区域进行逐元素相乘再求和的运算,从而生成特征图。每一个卷积核都会提取一种特定的特征。
- 参数共享: 同一个卷积核在整个输入数据上应用,这使得模型具有平移不变性,同时也大大减少了模型的参数量。
- 多通道处理: 如果输入数据具有多个通道(例如RGB图像有3个通道),卷积核会对所有通道的局部区域进行卷积操作,然后将结果相加。
输出尺寸计算
输出特征图的尺寸由以下因素决定:
- 输入尺寸:
(H, W, C) - 卷积核大小:
(kh, kw) - 步长:
(sh, sw) - 填充方式:
padding
计算公式如下:
H_out = (H + 2*pad_h - kh) // sh + 1
W_out = (W + 2*pad_w - kw) // sw + 1
- 当
padding="same"时,会自动计算填充值,使得输出尺寸与输入尺寸相同。 - 当
padding="valid"时,不进行填充,可能会导致输出尺寸小于输入尺寸。
典型应用场景
- 图像分类:例如在VGG、ResNet等网络中。
- 目标检测:如Faster R-CNN、YOLO等模型会用到。
- 语义分割:像U-Net、DeepLab等网络。
- 特征提取:用于提取图像的纹理、边缘等特征。
示例代码
下面是一个简单的使用 Conv2D 构建小型卷积神经网络的示例:
from tensorflow.keras import layers, models
model = models.Sequential()
# 添加一个卷积层,32个卷积核,每个卷积核大小为3x3,使用ReLU激活函数
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
# 添加最大池化层,池化窗口大小为2x2
model.add(layers.MaxPooling2D((2, 2)))
# 再添加一个卷积层,64个卷积核,每个卷积核大小为3x3,使用ReLU激活函数
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
# 添加最大池化层,池化窗口大小为2x2
model.add(layers.MaxPooling2D((2, 2)))
# 再添加一个卷积层,64个卷积核,每个卷积核大小为3x3,使用ReLU激活函数
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
# 将多维数据展平为一维向量
model.add(layers.Flatten())
# 添加全连接层,64个神经元,使用ReLU激活函数
model.add(layers.Dense(64, activation='relu'))
# 添加输出层,10个神经元,使用softmax激活函数,用于多分类问题
model.add(layers.Dense(10, activation='softmax'))
# 打印模型结构
model.summary()
注意要点
- 数据格式:
- 在TensorFlow中,默认的数据格式是
channels_last,即输入数据的形状为(batch_size, height, width, channels)。 - 若要使用
channels_first格式,输入数据的形状则为(batch_size, channels, height, width),并且需要在模型中进行相应设置。
- 在TensorFlow中,默认的数据格式是
- 卷积核大小:
- 常用的卷积核大小有3×3、5×5等,其中3×3的卷积核最为常用,因为它既能捕获局部特征,又能减少参数量。
- 激活函数:
- 在卷积层之后,通常会使用ReLU激活函数来引入非线性特性,这样可以增强模型的表达能力。
通过合理调整 Conv2D 的参数,你能够构建出适用于不同任务的高性能卷积神经网络。
dense
在Keras中,Dense 层(全连接层)是神经网络的基础组件,用于实现神经元之间的全连接。每个神经元接收上一层所有神经元的输出作为输入,并通过加权求和与激活函数产生输出。这种层广泛应用于各类深度学习模型,尤其是在模型的分类或回归部分。
核心参数解析
keras.layers.Dense(
units, # 神经元数量,决定输出维度
activation=None, # 激活函数,如"relu"、"softmax"
use_bias=True, # 是否使用偏置项
kernel_initializer="glorot_uniform", # 权重初始化方法
bias_initializer="zeros", # 偏置初始化方法
kernel_regularizer=None, # 权重正则化
bias_regularizer=None, # 偏置正则化
activity_regularizer=None,# 输出的正则化函数
kernel_constraint=None, # 对权重的约束
bias_constraint=None # 对偏置的约束
)
工作机制详解
-
线性变换: 对于输入
x,Dense层执行线性变换y = W·x + b,其中:W是权重矩阵(形状为(input_dim, units))b是偏置向量(形状为(units,))·表示矩阵乘法
-
激活函数: 线性变换后可应用激活函数引入非线性:
y = activation(W·x + b)常用激活函数包括:
relu:修正线性单元,max(0, x)sigmoid:将输出压缩到[0, 1]softmax:多分类问题中常用,输出概率分布
-
参数量计算: 总参数量 =
(输入维度 × 输出维度) + 输出维度(偏置项)
典型应用场景
- 图像分类:在卷积神经网络的末尾,将特征图展平后连接多个
Dense层进行分类。 - 回归分析:直接预测连续值,如房价预测。
- 特征组合:对高维特征进行非线性变换,提取更抽象的表示。
示例代码
以下是 Dense 层在不同场景的典型用法:
1. 简单神经网络(MNIST分类)
from tensorflow.keras import layers, models
model = models.Sequential()
model.add(layers.Flatten(input_shape=(28, 28))) # 将28×28图像展平为784维向量
model.add(layers.Dense(128, activation='relu')) # 128个神经元的隐藏层
model.add(layers.Dropout(0.2)) # 防止过拟合
model.add(layers.Dense(10, activation='softmax')) # 10个类别的输出层
model.summary()
2. 多层感知机(MLP)回归
from tensorflow.keras import layers, models
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_dim=100)) # 输入维度为100
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1)) # 无激活函数,用于回归问题
model.compile(optimizer='adam', loss='mse')
3. 与卷积层结合(CIFAR-10分类)
from tensorflow.keras import layers, models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax')) # 10个类别
注意要点
-
输入形状:
- 输入应为二维张量
(batch_size, input_dim) - 若输入为多维数据(如卷积层输出),需先通过
Flatten或GlobalAveragePooling2D进行展平
- 输入应为二维张量
-
激活函数选择:
- 二分类问题:输出层使用
Dense(1, activation='sigmoid') - 多分类问题:输出层使用
Dense(n_classes, activation='softmax') - 回归问题:输出层不使用激活函数或使用
linear
- 二分类问题:输出层使用
-
防止过拟合:
- 可在
Dense层后添加Dropout层 - 使用正则化参数(如
kernel_regularizer='l2')
- 可在
-
初始化策略:
- ReLU激活函数:推荐使用
he_normal初始化 - Sigmoid/tanh激活函数:推荐使用
glorot_uniform(默认)
- ReLU激活函数:推荐使用
通过合理设计 Dense 层的结构和参数,你可以构建出适用于不同任务的神经网络模型。
在Keras中,Dense层(全连接层)和Conv2D层(二维卷积层)是两种核心层类型,分别适用于不同的数据结构和任务场景。以下是它们的主要区别:
1. 连接方式与参数共享
| Dense层 | Conv2D层 |
|---|---|
| 全连接:每个输出神经元与所有输入神经元相连 | 局部连接:每个输出神经元仅与输入的局部区域相连 |
| 无参数共享:每个连接有独立的权重参数 | 参数共享:同一卷积核在整个输入上滑动使用 |
参数量 = 输入维度 × 输出维度 + 输出维度 | 参数量 = 卷积核大小 × 输入通道数 × 输出通道数 + 输出通道数 |
示例:
- 输入为28×28图像(784维),Dense层输出128维:参数量 = 784×128+128 = 100,480
- 输入为32×32×3图像,Conv2D使用3×3卷积核、32个输出通道:参数量 = 3×3×3×32+32 = 896
2. 数据结构与空间关系
| Dense层 | Conv2D层 |
|---|---|
| 输入/输出均为一维向量(忽略数据的空间结构) | 输入/输出为多维张量(保留空间结构,如H×W×C) |
| 适用于无空间关系的数据(如文本、表格) | 适用于有网格结构的数据(如图像、音频) |
| 对输入的空间位置敏感(位置变化会影响结果) | 具有平移不变性(同一特征可在不同位置被检测) |
3. 特征提取能力
| Dense层 | Conv2D层 |
|---|---|
| 通过全连接捕获全局特征关系 | 通过局部卷积捕获局部模式(如边缘、纹理) |
| 需手动设计特征工程(如展平图像) | 自动学习层次化特征(从低级到高级) |
| 易过拟合(参数量大) | 抗过拟合能力强(参数共享+局部连接) |
4. 典型应用场景
| Dense层 | Conv2D层 |
|---|---|
| 分类器(如Softmax层) | 特征提取(如图像卷积网络) |
| 回归任务 | 图像/视频处理 |
| 模型的最后几层(整合全局信息) | 模型的前几层(提取局部特征) |
5. 代码对比
Dense层示例
from tensorflow.keras import layers
model = Sequential()
model.add(layers.Flatten(input_shape=(28, 28))) # 展平图像为一维向量
model.add(layers.Dense(128, activation='relu')) # 全连接层
Conv2D层示例
from tensorflow.keras import layers
model = Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) # 保留空间结构
6. 何时选择哪种层?
-
使用Dense层:
- 输入数据无明显空间结构(如文本、数值特征)。
- 需要整合全局信息(如分类前的特征融合)。
- 模型参数量可控(小数据集)。
-
使用Conv2D层:
- 处理图像、音频等网格结构数据。
- 需要提取局部特征或保持空间关系。
- 参数量需严格控制(大数据集、高分辨率输入)。
总结
| 维度 | Dense层 | Conv2D层 |
|---|---|---|
| 连接方式 | 全连接 | 局部连接+参数共享 |
| 数据结构 | 一维向量 | 多维张量(保留空间) |
| 特征类型 | 全局特征 | 局部特征 |
| 参数量 | 高(易过拟合) | 低(抗过拟合) |
| 典型场景 | 分类器、回归 | 图像/视频处理 |
在实际应用中,两者常结合使用(如CNN中先用Conv2D提取特征,再用Dense层分类)。
pool
在Keras中,MaxPooling2D 是一种二维最大池化层,常用于卷积神经网络(CNN)中对特征图进行下采样。它通过在局部区域内提取最大值来减少数据维度,同时保留重要特征。以下是对 MaxPooling2D 的详细介绍:
核心功能与作用
- 降维:减少特征图的空间尺寸(高度和宽度),降低计算复杂度。
- 特征提取:通过保留最大值,突出最显著的特征(如边缘、纹理)。
- 平移不变性:对输入的微小平移具有鲁棒性,增强模型的泛化能力。
- 防止过拟合:减少参数数量,降低模型对噪声的敏感性。
核心参数
keras.layers.MaxPooling2D(
pool_size=(2, 2), # 池化窗口大小,通常为(2, 2)
strides=None, # 步长,默认等于pool_size
padding="valid", # 填充方式,"valid"(不填充)或"same"(保持输入尺寸)
data_format=None # 数据格式,"channels_last"(默认)或"channels_first"
)
工作机制详解
-
池化窗口滑动:
池化窗口(如2×2)在输入特征图上按指定步长滑动,每次覆盖一个局部区域。 -
最大值提取:
对每个局部区域内的所有值取最大值,作为输出特征图的对应位置的值。 -
输出尺寸计算:
假设输入尺寸为(H, W, C),池化窗口为(p, q),步长为(s_h, s_w),则输出尺寸为:H_out = (H - p) // s_h + 1 W_out = (W - q) // s_w + 1当
padding="same"时,会自动填充使输出尺寸与输入相同。 -
通道数不变:
池化操作不改变特征图的通道数(C),仅对空间维度进行下采样。
典型应用场景
- 图像分类:在卷积层后使用,减少特征图尺寸,如VGG、ResNet。
- 目标检测:提取局部区域的显著特征,如YOLO、Faster R-CNN。
- 语义分割:通过下采样和上采样结合,捕获多尺度特征,如U-Net。
示例代码
1. 基本用法
from tensorflow.keras import layers, models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
# 添加最大池化层,池化窗口2×2
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
# 再次下采样
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.summary()
2. 输出尺寸计算示例
# 输入:32×32×3的图像
# 第一个卷积层:32个3×3卷积核,padding="valid"
# 输出尺寸:(32-3)/1+1 = 30 → (30, 30, 32)
# 第一个池化层:2×2池化窗口,默认步长=2
# 输出尺寸:30/2 = 15 → (15, 15, 32)
# 第二个卷积层:64个3×3卷积核
# 输出尺寸:(15-3)/1+1 = 13 → (13, 13, 64)
# 第二个池化层:2×2池化窗口
# 输出尺寸:13//2 +1 = 7 → (7, 7, 64)
与其他池化方法的对比
| 池化类型 | 核心操作 | 特点与应用场景 |
|---|---|---|
| MaxPooling2D | 取局部区域最大值 | 保留显著特征,最常用 |
| AveragePooling2D | 取局部区域平均值 | 平滑特征,适用于强调整体信息的场景 |
| GlobalMaxPooling2D | 对每个通道全局取最大值 | 大幅降维,常用于分类任务 |
| GlobalAveragePooling2D | 对每个通道全局取平均 | 减少参数量,防止过拟合,如ResNet |
注意要点
-
数据格式:
- 默认
data_format="channels_last",输入形状为(batch_size, height, width, channels)。 - 若使用
channels_first,输入形状为(batch_size, channels, height, width)。
- 默认
-
步长与窗口大小:
- 步长通常设置为与池化窗口大小相同(如
strides=(2, 2)),避免重叠计算。
- 步长通常设置为与池化窗口大小相同(如
-
替代方案:
- 若需保留更多空间信息,可使用
Strided Convolution(卷积步长>1)替代池化。
- 若需保留更多空间信息,可使用
总结
MaxPooling2D 是CNN中不可或缺的组件,通过提取局部最大值实现特征选择和降维,在保持模型性能的同时显著减少计算量。合理使用池化层可以有效提升模型的泛化能力和训练效率。
在深度学习中,池化层(Pooling Layer) 是卷积神经网络(CNN)的关键组件,主要用于对特征图进行下采样(降维)。它通过在局部区域上执行聚合操作,减少数据量的同时保留重要特征。以下是其核心概念、作用和常见类型的详细解释:
1. 核心概念
池化层的工作原理是:
- 滑动窗口:在输入特征图上按固定步长滑动一个窗口(如2×2像素)。
- 聚合操作:对每个窗口内的所有值应用一个固定函数(如最大值、平均值),生成输出值。
- 降低维度:输出特征图的空间尺寸(高、宽)通常会减小,而通道数保持不变。
示例:
输入为4×4的特征图,使用2×2窗口和步长2进行最大池化:
输入特征图:
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]
]
池化过程(2×2窗口):
[1, 2] → max=6 [3, 4] → max=8
[5, 6] [7, 8]
[9, 10] → max=14 [11, 12] → max=16
[13, 14] [15, 16]
输出特征图:
[
[6, 8],
[14, 16]
]
2. 主要作用
-
减少参数数量:
降低后续层的计算复杂度,例如:- 输入100×100×64的特征图,经2×2池化后变为50×50×64,参数减少75%。
-
提取显著特征:
通过保留最大值(或平均值),突出最重要的特征(如边缘、纹理)。 -
增强平移不变性:
对输入的微小位移不敏感,提高模型的鲁棒性。例如,图像中的物体位置稍有变化,池化后的特征保持不变。 -
防止过拟合:
减少模型对细节的依赖,泛化能力更强。
3. 常见池化类型
(1) 最大池化(Max Pooling)
-
操作:取窗口内的最大值。
-
特点:保留最显著特征,抑制噪声,最常用。
-
Keras实现:
from tensorflow.keras.layers import MaxPooling2D model.add(MaxPooling2D(pool_size=(2, 2), strides=2))
(2) 平均池化(Average Pooling)
-
操作:取窗口内的平均值。
-
特点:保留整体特征,避免局部极值影响,适用于强调背景信息的任务(如语义分割)。
-
Keras实现:
from tensorflow.keras.layers import AveragePooling2D model.add(AveragePooling2D(pool_size=(2, 2), strides=2))
(3) 全局池化(Global Pooling)
-
操作:对每个通道的全部值取最大值或平均值。
-
特点:将特征图压缩为一维向量,大幅减少参数量。常用于分类任务的最后一层。
-
Keras实现:
from tensorflow.keras.layers import GlobalMaxPooling2D, GlobalAveragePooling2D model.add(GlobalMaxPooling2D()) # 全局最大池化 model.add(GlobalAveragePooling2D()) # 全局平均池化
4. 参数与计算
(1) 核心参数
- 池化窗口大小(pool_size):通常为2×2或3×3。
- 步长(strides):窗口每次滑动的距离,默认等于窗口大小。
- 填充(padding):通常为“valid“(不填充),保持特征图边缘信息。
(2) 输出尺寸计算
假设输入尺寸为 H × W × C,池化窗口为 p × p,步长为 s,则输出尺寸为:
H_out = (H - p) // s + 1
W_out = (W - p) // s + 1
C_out = C # 通道数不变
例如:
- 输入:28×28×64
- 池化:2×2窗口,步长2
- 输出:14×14×64
5. 应用场景
- 图像分类:如VGG、ResNet中使用最大池化降维。
- 目标检测:如YOLO、Faster R-CNN中提取区域特征。
- 语义分割:结合上采样恢复空间分辨率,如U-Net。
- 语音处理:对音频特征图进行降维。
6. 与卷积层的对比
| 维度 | 卷积层(Conv2D) | 池化层(MaxPooling2D) |
|---|---|---|
| 参数 | 有可学习的权重和偏置 | 无参数,仅固定操作 |
| 特征提取 | 通过卷积核学习局部特征 | 提取/聚合已有特征 |
| 尺寸变化 | 可通过padding控制输出尺寸 | 通常缩小尺寸(如减半) |
| 非线性 | 需通过激活函数引入非线性 | 纯线性操作 |
| 作用 | 提取有意义的特征 | 降维、增强鲁棒性 |
7. 替代方案
- 步长卷积(Strided Convolution):通过卷积层的大步长(如strides=2)直接降维,替代池化层。
- 空洞卷积(Dilated Convolution):在不增加参数的情况下扩大感受野,保留更多细节。
总结
池化层通过下采样和特征聚合,在减少计算量的同时增强模型的鲁棒性,是CNN中不可或缺的组件。最大池化因其简单高效而被广泛使用,而平均池化和全局池化则适用于特定场景。合理设计池化策略是构建高性能深度学习模型的关键。
docker
官网
-
The easiest and recommended way to get Docker Compose is to install Docker Desktop. Docker Desktop includes Docker Compose along with Docker Engine and Docker CLI which are Compose prerequisites.
-
linux服务器单独安装docker,就需要单独安装docker-compose.
dockerfile示意图

containerd示意图
podman集合-开源替代品
阿里云
# 安装docker引擎
yum install docker
# 开机启动
service docker start
# repos地址
vim /etc/docker/daemon.json
{ "registry-mirrors": "https://registry.docker-cn.com", "live-restore": true }
docker run -d -p 8090:80 docker/getting-started
# 容器日志物理目录
/var/lib/docker/containers/ID/ID-json.log
# 设置共享内存
docker --shm-size 256m
# 安装 elasticsearch
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.5.2
# 启动 openjdk 内存空间有要求
docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.5.2
# 在linux至少8G,容易跑起来
# 需要继续 docker kibana rancher
# brancher 集群-多个项目,项目-多个命令空间
# rancher 主界面->右下角有个English,点击选择中文
# 单节点安装,重置密码
docker exec -ti <container_id> reset-password
# 必须带上-v $HOME/rancher:/var/lib/rancher/,否则跑不起来
# 导致https://192.168.8.108:8091,https://127.0.0.1:8091(不能访问)
# rancher启动慢,需要等待片刻就能浏览器访问
# docker logs -f rancher查看容器启动日志
docker run -d --restart=unless-stopped -p 8090:80 -p 8091:443 --privileged -v $HOME/rancher:/var/lib/rancher/ rancher/rancher:latest
rEWlGtFhS52EsKIa
https://127.0.0.1:8091
常用命令
所有images都压缩在Docker.qcow2里
#下载安装gerrit
docker pull gerritcodereview/gerrit
#运行gerrit
docker run -ti -p 8080:8080 -p 29418:29418 gerritcodereview/gerrit
#docker 安装(周编译,较新但可能bug)
docker pull jenkinsci/jenkins
chown -R 1000:1000 /root/jenkins_home
docker run -d -p 8080:8080 --restart=always -v /root/jenkins_home:/var/jenkins_home --name jenkins jenkins/jenkins
# 帮助文档
https://www.w3cschool.cn/jenkins/jenkins-e7bo28ol.html
Blue Ocean值得安装
nohup mdbook serve >~/mdbook.nohup 2>&1 &
docker run --name some-mysql -v /my/own/datadir:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=my-secret-pw -d mysql:tag
#安装gitlab,机器性能要好,否则卡死
docker pull gitlab/gitlab-ce
#gerrit是google开源的代码review工具
docker pull gerritcodereview/gerrit
docker run -ti -p 8080:8080 -p 29418:29418 gerritcodereview/gerrit
# http://localhost:8080
#SonarQube检测代码质量平台
docker pull sonarqube
# Create a tag TARGET_IMAGE that refers to SOURCE_IMAGE
docker tag SOURCE_IMAGE[:TAG] TARGET_IMAGE[:TAG]
# 查看image的产生过程,可以得到dockerfile
docker history --no-trunc alpine
container容器管理
#默认显示运行的容器
docker ps
#显示所有容器
docker ps -a
# attach模式, 类似运行于前台的进程,会占据本地的STDIN和STDOUT
docker run nginx
# 进入容器
docker exec --it containerID/containerName /bash
docker exec --it containerID/containerName redis-cli
# detach模式,可以用docker container attach id改为attach模式,类似于后台运行
docker run -d nginx
# 与容器的交互
docker run -it id(container id) command 当command运行结束之后,container的状态也变成了exited的状态
docker exec -it id command 当command运行结束之后,container的状态保持running状态不变
docker stop $(docker ps -q)
#已经停止的,正在运行的不能删除
docker rm $(docker ps -a -q)
image管理
# 注意images
docker images --help
Usage: docker images [OPTIONS] [REPOSITORY[:TAG]]
List images
Options:
-a, --all Show all images (default hides intermediate images)
--digests Show digests
-f, --filter filter Filter output based on conditions provided
--format string Pretty-print images using a Go template
--no-trunc Donot truncate output
-q, --quiet Only show image IDs
# 删除image为none
docker images|grep none|awk '{print $3 }'|xargs docker rmi
# 注意image
docker image --help
Usage: docker image COMMAND
Manage images
Commands:
build Build an image from a Dockerfile
history Show the history of an image
import Import the contents from a tarball to create a filesystem image
inspect Display detailed information on one or more images
load Load an image from a tar archive or STDIN
ls List images
prune Remove unused images
pull Pull an image or a repository from a registry
push Push an image or a repository to a registry
rm Remove one or more images
save Save one or more images to a tar archive (streamed to STDOUT by default)
tag Create a tag TARGET_IMAGE that refers to SOURCE_IMAGE
volume管理
docker volume --help
Usage: docker volume COMMAND
Manage volumes
Commands:
create Create a volume
inspect Display detailed information on one or more volumes
ls List volumes
prune Remove all unused local volumes
rm Remove one or more volumes
其实VOLUME指令只是起到了声明了容器中的目录作为匿名卷,但是并没有将匿名卷绑定到宿主机指定目录的功能。 当我们生成镜像的Dockerfile中以Volume声明了匿名卷,并且我们以这个镜像run了一个容器的时候,docker会在安装目录下的指定目录下面生成一个目录来绑定容器的匿名卷(这个指定目录不同版本的docker会有所不同),我当前的目录为:/var/lib/docker/volumes/{容器ID}。 volume只是指定了一个目录,用以在用户忘记启动时指定-v参数也可以保证容器的正常运行。 那么如果用户指定了-v,自然而然就不需要volume指定的位置了
network管理
Usage: docker network COMMAND
Manage networks
Commands:
connect Connect a container to a network
create Create a network
disconnect Disconnect a container from a network
inspect Display detailed information on one or more networks
ls List networks
prune Remove all unused networks
rm Remove one or more networks
Run 'docker network COMMAND --help' for more information on a command
其他命令
Management Commands:
builder Manage builds
buildx* Docker Buildx (Docker Inc., v0.8.1)
compose* Docker Compose (Docker Inc., v2.3.3)
config Manage Docker configs
container Manage containers
context Manage contexts
image Manage images
manifest Manage Docker image manifests and manifest lists
network Manage networks
node Manage Swarm nodes
plugin Manage plugins
scan* Docker Scan (Docker Inc., v0.17.0)
secret Manage Docker secrets
service Manage services
stack Manage Docker stacks
swarm Manage Swarm
system Manage Docker
trust Manage trust on Docker images
volume Manage volumes
私有部署dockerhub
# 利用docker公司提供的工具
docker pull registry
# -v 主机目录:容器目录,registry存储仓库中镜像到/var/lib/registry
docker run -d -p 5000:5000 --restart=always -v /opt/dockerhub:/var/lib/registry registry
# 从dockerhub拉取nginx最新版
docker pull nginx
# 打上特定hub的标签
docker tag nginx localhost:5000/nginx
# 推送nginx到目标hub中去
docker push localhost:5000/nginx
# http://主机ip:5000/v2/_catalog 查看信息
# 增加配置,docker默认走https,但是registry默认走http /etc/docker/daemon.json
"insecure-registries":[
"主机:5000"
]
jenkins 另一个开源替代品gocd
-
忘记密码-admin密码未更改情况
- cat ~/.jenkins/secrets/initialAdminPassword 就是初始化密码
- 访问jenkins页面,输入管理员admin,及刚才的密码;
- 进入后可更改其他管理员密码;
-
brew 启动不了
# Bootstrap failed: 5: Input/output error
# Error: Failure while executing; `/bin/launchctl bootstrap gui/503 /Users/zzi/Library/LaunchAgents/homebrew.mxcl.jenkins-lts.plist` exited with 5.
# 试试
brew services restart jenkins-lts
- SSH remote hosts配置中Pty一定不能勾选,否则nohup需要sleep才有效
- 证书是统一管理各种,包括ssh,gitlab等等.
- Multijob插件用来批量构建工程,过时了,改用’parallel’ step along with ‘BlueOcean’ can basical
- Multiple SCMs用来处理多个git/svn仓库构建一个项目
遇到问题
- Docker拉取镜像时出现Error response from daemon: Get https://registry-1.docker.io/v2/: net/http: TLS handshake timeout问题
"registry-mirrors": ["https://bytkgxyr.mirror.aliyuncs.com","https://registry.docker-cn.com","http://hub-mirror.c.163.com"]
golang示例
docker新版本引入多阶段,主要用来优化不同阶段要求不同,例如编译时需要编译工具,但运行时不需要的.运行时只要引入编译产物就可以了.
# syntax=docker/dockerfile:1
## Build
FROM golang:1.16-buster AS build
# 使用 WORKDIR 指令可以来指定工作目录(或者称为当前目录),以后各层的当前目录就被改为指定的目录,如该目录不存在, WORKDIR 会帮你建立目录
WORKDIR /app
# 从构建上下文中复制文件到容器
COPY go.mod ./
COPY go.sum ./
RUN go mod download
COPY *.go ./
RUN go build -o /docker-gs-ping
## Deploy
FROM gcr.io/distroless/base-debian10
WORKDIR /
COPY --from=build /docker-gs-ping /docker-gs-ping
EXPOSE 8080
USER nonroot:nonroot
# 如果设定了ENTRYPOINT,则cmd,和run后面参数都作为entrypoint参数,
# 否则按run后面参数作用cmd运行
# 没有entrypoint,cmd都不存在,则按cmd运行
ENTRYPOINT ["/docker-gs-ping"]
docker build -t docker-gs-ping:multistage -f Dockerfile.multistage .
python示例
# syntax=docker/dockerfile:1
FROM python:3.8-slim-buster
WORKDIR /app
COPY requirements.txt requirements.txt
RUN pip3 install -r requirements.txt
COPY . .
CMD [ "python3", "-m" , "flask", "run", "--host=0.0.0.0"]
docker tag python-docker:latest python-docker:v1.0.0
minikube-单机版精简k8s
你可以使用 kubectl 命令行工具来启用 Dashboard 访问 kubectl 会使得 Dashboard 可以通过 http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/ 访问。
kubectl proxy
docker
docker-compose.yml
# 多个services之间自动创建network,并且用web,redis当作别名,加入同个network
# 并且会默认创建volume共享
docker compose up
version: '3'
services:
web:
#冒号之后一定要空格,否则提示错误
build: .
ports: ["3000:3000"]
redis:
image: "redis:7.0-alpine3.17"
dockerfile
FROM python:3.10-alpine
WORKDIR /app
COPY requirements.txt requirements.txt
COPY main.py main.py
RUN pip3 install -r requirements.txt
CMD ["python3", "main.py"]
main.py
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
# async def app(scope, receive, send):
app = FastAPI()
class Item(BaseModel):
name: str
price: float
is_offer: Union[bool, None] = None
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
async def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
@app.put("/items/{item_id}")
def update_item(item_id: int, item: Item):
return {"item_id": item_id, "item": item}
import redis
client = redis.Redis(host='redis', port=6379, db=0)
@app.get("/hit")
def hit():
val = client.incrby('hit')
return {"hit": val}
if __name__ == "__main__":
import uvicorn
uvicorn.run("main:app", host='0.0.0.0', port=3000)
requirements.txt
fastapi
redis
uvicorn[standard]
nginx
Nginx-中国开源社区
HTTP-V3-Module
brotli-替代gzip压缩算法,更快更省时>
caddy-nginx替代品
可视化配置展示-nginxconfig
动态配置+内置应用支持-nginxunit
动态配置-traefik
openssl爆出各种重大问题,大厂都自已搞了一个分支
源码安装剖析
flowchart LR A(下载) --> B(配置) B --> C(编译) C --> D(安装) D --> E(运行) E --> F(进阶) F --> G(后记)
1.下载
wget https://nginx.org/download/nginx-1.21.6.tar.gz
tar -zxvf nginx-1.21.6.tar.gz
cd nginx-1.21.6
源代码目录,如下图所示:

2. 配置
# prefix参数指定默认路径(安装,配置文件,日志目录, 临时目录等等)
# with-debug参数增加调试日志,正式运行强烈建议不要此参数
./configure --prefix=/Users/Shared/nginx --with-debug
# 更多参数及详细说明见 ./configure --help
- 生成makefile文件,如下图所示:

- 生成objs子目录,如下图所示

- 生成ngx_modules.c文件,如下图所示:

3. 编译
# 实际上执行上一步生成的objs/makefile
make
- 生成启用模块目标文件,如下图所示:

4. 安装
# 实际上执行上一步生成的objs/makefile
make install
- 安装执行代码,如下所示:
install: build
test -d '$(DESTDIR)/Users/Shared/nginx' || mkdir -p '$(DESTDIR)/Users/Shared/nginx'
test -d '$(DESTDIR)/Users/Shared/nginx/sbin' \
|| mkdir -p '$(DESTDIR)/Users/Shared/nginx/sbin'
test ! -f '$(DESTDIR)/Users/Shared/nginx/sbin/nginx' \
|| mv '$(DESTDIR)/Users/Shared/nginx/sbin/nginx' \
'$(DESTDIR)/Users/Shared/nginx/sbin/nginx.old'
cp objs/nginx '$(DESTDIR)/Users/Shared/nginx/sbin/nginx'
test -d '$(DESTDIR)/Users/Shared/nginx/conf' \
|| mkdir -p '$(DESTDIR)/Users/Shared/nginx/conf'
....
test -d '$(DESTDIR)/Users/Shared/nginx/logs' \
|| mkdir -p '$(DESTDIR)/Users/Shared/nginx/logs'
- 安装目录,如下图所示:

5.运行
# /Users/Shared/nginx为configure中prefix参数指定
cd /Users/Shared/nginx/sbin
# -t 表示检查配置文件是否正确
./nginx -t
./nginx
- 日志目录,如下图所示:

- 查看帮助,如下图所示:
./nginx -h

- 查看调试日志,如下图所示:
http {
...
server {
listen 80;
server_name localhost;
# 编译时需要带上--with-debug
# 如果仅看http过程,则指定等级为debug_http
error_log logs/error.log debug;
location / {
root html;
index index.html index.htm;
}
}
...
}

6. 进阶
1. 安装第三方模块及禁/启用自带模块
# ../nginx-party-module/echo-nginx-module是echo-nginx-module模块源代码目录
./configure \
--prefix=/Users/Shared/nginx \
--without-http_empty_gif_module \
--with-stream \
--add-module=../nginx-party-module/echo-nginx-module
- –without参数禁用自带模块
- –with参数启用自带模块
- –add-module参数安装第三方模块
2. 编译安装
make && make install
- make时在objs目录产生一个addon子目录,保存echo-nginx-module模块相关文件,如下图所示:

3. 编辑nginx.conf,运行
cd /Users/Shared/nginx/conf
vim nginx.conf
....
# echo-nginx-module模块详细见项目网址
location /hello {
echo "hello, world!";
}
...
cd ../sbin
./nginx
4. 测试
curl http://localhost/hello
hello,world!
5. 原理分析
-
configure脚本先引用auto目录下的options脚本,如下图所示:

-
options脚本设参数默认值,如下图所示:

-
configure脚本再引用auto目录下的modules脚本,如下图所示:

-
modules脚本如果参数为yes则引入编译,如下图所示:

-
objs目录的ngx_modules.c文件就会增加引入的模块名,如下所示:
...
ngx_module_t *ngx_modules[] = {
&ngx_core_module,
&ngx_errlog_module,
&ngx_conf_module,
&ngx_regex_module,
&ngx_events_module,
&ngx_event_core_module,
&ngx_kqueue_module,
&ngx_http_module,
...
&ngx_stream_upstream_zone_module,
NULL
};
...
-
ngx_modules.h的声明引用ngx_modules.c中ngx_modules,如下图所示:

-
nginx.c的main函数调用nginx_module.c中ngx_preinit_modules函数,如下图所示:

-
nginx_module.c中ngx_preinit_modules函数使用ngx_modules.c中ngx_modules,如下所示:
ngx_int_t
ngx_preinit_modules(void)
{
ngx_uint_t i;
/*
ngx_modules变量为ngx_modules.c中定义
*/
for (i = 0; ngx_modules[i]; i++) {
ngx_modules[i]->index = i;
ngx_modules[i]->name = ngx_module_names[i];
}
ngx_modules_n = i;
ngx_max_module = ngx_modules_n + NGX_MAX_DYNAMIC_MODULES;
return NGX_OK;
}
- 动态配置和静态编译执行在此完美结合起来
7. 后记
-
这里有很多优秀的nginx第三方模块,可供下载使用
-
安装ssl
./configure --prefix=/Users/Shared/nginx \
--add-module=../nginx-party-module/ngx_http_redis-module \
--with-http_v2_module \
--with-http_ssl_module \
--with-openssl=/opt/homebrew/Cellar/openssl@1.1/1.1.1m\
--with-debug
- http_v2_module不一定需要ssl,浏览器一般强制需要
- http_ssl_module需要ssl目录,在linux一般指ssl-devel,需要include/lib目录
- 如果make仍然出错,移除掉路径中.openssl/,默认和系统中路径不同,多了一级.openssl/
HTTP模块
核心模块阶段
flowchart TD
subgraph POST_READ
realip(realip)
end
subgraph SERVER_REWRITE
rewrite(rewrite)
end
subgraph FIND_CONFIG
NULL(NULL)
end
subgraph REWRITE
rewrite2(rewrite)
end
subgraph POST_REWRITE
NULL2(NULL)
end
subgraph PREACCESS
direction LR
degradation(degradation) --> limit_conn(limit_conn)
limit_conn --> limit_req(limit_req)
limit_req --> realip2(realip)
end
subgraph ACCESS
direction LR
access(access) --> auth(auth)
end
subgraph POST_ACCESS
NULL3(NULL)
end
subgraph PRECONTENT
direction LR
mirror(mirror) --> try_files(try_files)
end
subgraph CONTENT
direction LR
static(static) --> gzip_static(gzip_static)
gzip_static --> dav(dav)
dav --> autoindex(autoindex)
autoindex --> index(ndex)
index --> random_index(random_index)
end
subgraph LOG
log(log)
end
POST_READ --> SERVER_REWRITE
SERVER_REWRITE --> FIND_CONFIG
FIND_CONFIG --> REWRITE
REWRITE --> POST_REWRITE
POST_REWRITE --> PREACCESS
PREACCESS --> ACCESS
ACCESS --> POST_ACCESS
POST_ACCESS --> PRECONTENT
PRECONTENT --> CONTENT
CONTENT --> LOG
POST_REWRITE阶段如果有rewrite,则会跳回到FIND_CONFIG阶段
源代码中定义,如下图所示:
FastCGI模块
sequenceDiagram
actor n as nginx进程
actor c as CGI进程
n->>c: begin_request处理开始
n->>c: params请求参数
n->>+c: stdin请求数据内容
c->>c:请求处理
c-->>-n: stdout处理结果
c-->>n: end_request处理结束
static模块
把请求url中path映射本地路径,读取本地文件返回客户端
核心源代码,如下图所示:
index模块
引入配置参数index,如下图所示:

请求url为目录时,把配置参数index值附加在url上,然后内部转跳
static ngx_int_t
ngx_http_index_handler(ngx_http_request_t *r)
{
...
if (index[i].name.data[0] == '/') {
return ngx_http_internal_redirect(r, &index[i].name, &r->args);
}
...
ngx_log_debug1(NGX_LOG_DEBUG_HTTP, r->connection->log, 0,
"open index \"%V\"", &path);
...
return ngx_http_internal_redirect(r, &uri, &r->args);
}
转跳调试日志,如下图所示:

常用技巧
配置片段
-
http转向https
rewrite ^(.*) https://$server_name$1 permanent; rewrite ^(.*) https://$host$1 permanent;- 两种写法,各有适合场合
- $server_name, 由nginx配置决定
- $host,由请求路径决定
-
正向代理
server { listen 80; location / { proxy_pass http://$host$request_uri; } }- 配合日志,可以用来调试
- 可以过滤掉特定请求
- 可以检查http请求是否被拦截
-
解决无法加载样式表
# 否则无法加载样式表 include /etc/nginx/mime.types; default_type application/octet-stream; -
支持http2
-
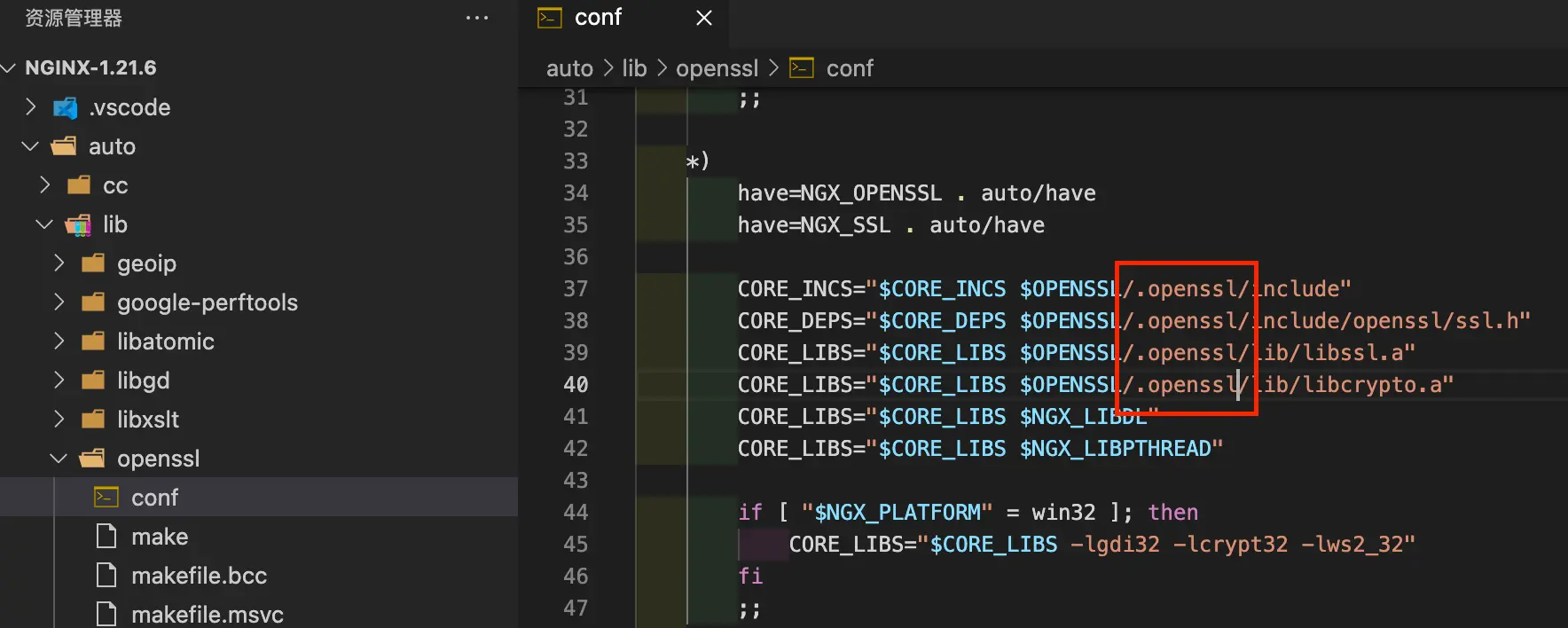
自定义安装带上v2,ssl
./configure --prefix=/Users/Shared/nginx \ --with-http_v2_module \ --with-http_ssl_module \ --with-openssl=/opt/homebrew/Cellar/openssl@1.1/1.1.1m\ --with-debug -
配置增加上http2
... server { # 默认情况http2都走ssl,所以在ssl加上http2 listen 443 ssl http2; ... } ...
-
-
支持http3
-
自定义安装带上v3,ssl,brotli
./auto/configure --with-http_v3_module \ --with-stream_quic_module \ --with-http_ssl_module \ --with-http_v2_module \ --add-module=../ngx_brotli \ --with-cc-opt="-I../libressl/build/include" \ --with-ld-opt="-L../libressl/build/lib" -
配置增加上http3
... http { brotli on; brotli_comp_level 6; brotli_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript image/svg+xml; server { # 默认情况http2都走ssl,所以在ssl加上http2 listen 443 ssl http2; listen 443 http3 reuseport; # UDP listener for QUIC+HTTP/3,在主域名表示reuseport,否则会提示冲突 ssl_protocols TLSv1.3; # QUIC requires TLS 1.3 # 一定要添加头部,否则无法开启 add_header alt-svc 'h3=":443"; ma=86400;quic=":443"; ma=2592000; v="46,43", h3-Q050=":443"; ma=2592000, h3-Q049=":443"; ma=2592000, h3-Q048=":443"; ma=2592000,h3-Q046=":443"; ma=2592000, h3-Q043=":443"; ma=2592000, h3-23=":443"; ma=2592000'; ... } ... } ...
-

-
四层代理-stream
-
自定义安装带上stream
./configure --prefix=/Users/Shared/nginx \ --with-stream \ --with-debug make && make install -
配置增加上stream
... stream { server { listen 8411; proxy_timeout 3s; proxy_pass xxx:8411; } } ...
-
-
gzip-压缩支持
... http { # 打开gzip指令,否则后面不会生效 gzip on; # 回包头部增加content-encoding: gzip gzip_vary on; # 压缩类型 gzip_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript image/svg+xml; } ... -
location / { #可以多次映像/复制,从而起到放大流量功能 #产生一个http subrequest "/mirror?",跳转到相应location #所以mirror结果(包括超时,服务器关闭,50x,40x等等),不影响这个本身速度及结果 #但是占用内存,消费conn连接池之类还是要的 #mirror /mirror; #mirror /mirror; mirror /mirror; #允许丢掉body #mirror_request_body off; proxy_pass http://backend; } location = /mirror { # 判断请求方法,不是GET返回403,用其他类似手段缩小流量规模 # if ($request_method != GET) { # return 403; # } internal; #这里的回包是忽略 proxy_pass http://test_backend$request_uri; #允许丢掉body #proxy_pass_request_body off; #proxy_set_header Content-Length ""; proxy_set_header X-Original-URI $request_uri; } -
利用日志调试
server { ... #降低错误日志等级,例如notice,如果编译带有--with-debug,则可以debug,debug_http error_log logs/error.log info; #不同路径不同access日志文件,确认哪个loc使用 location /hello { ... access_log logs/hello_access.log; ... } location /world { ... access_log logs/world_access.log; ... } ... } -
root与alias区别
# 请求/abc/123 ==> /var/www/app/static/abc/123
location /abc {
# In case of the root directive, full path is appended to the root including the location part
# 请求的path附加上root指定path,组合本地路径
root /var/www/app/static;
autoindex off;
}
# 请求/abc/123 ==> /var/www/app/static/123
location /abc {
# only the portion of the path NOT including the location part is appended to the alias.
# 请求的path移除掉location的path,再附加上alias指定path,组合本地路径
alias /var/www/app/static;
autoindex off;
}
常用模块
-
http_memcached模块
... location /memcached { set $memcached_key "$uri"; memcached_pass 127.0.0.1:11211; #指示返回为html,方便浏览器直接显示 default_type text/html; error_page 404 502 504 = @notexit; } location @notexit { #echo为第三方模块引入指令,方便调试 echo "noexit$uri"; } ...
sequenceDiagram actor u as user actor n as nginx actor m as memcached u->>n: http请求/memcached n->>m: get命令key值为$uri(/memcached) m->>n: 存在则返回值,否则返回空 n->>u: 成功获取,则直接返回,否则转跳notexit
-
ngx_http_redis第三方模块,类似http_memcached
./configure --prefix=/Users/Shared/nginx \ --add-module=../nginx-party-module/ngx_http_redis-module \ ... --with-debug make && make install... location /redis { set $redis_key "$uri"; redis_pass 127.0.0.1:6379; #指示返回为html,方便浏览器直接显示 default_type text/html; error_page 404 502 504 = @notexit; } location @notexit { #echo为第三方模块引入指令,方便调试 echo "noexit$uri"; } ...
sequenceDiagram actor u as user actor n as nginx actor m as redis u->>n: http请求/redis n->>m: get命令key值为$uri(/redis) m->>n: 存在则返回值,否则返回空 n->>u: 成功获取,则直接返回,否则转跳notexit
-
redis2-nginx-module第三方模块,更强大更多操作
./configure --prefix=/Users/Shared/nginx \ --add-module=../nginx-party-module/redis2-nginx-module \ --with-debug make make install... location = /foo { set $value '<html><H1>From Nginx Redis</H1></html>'; redis2_query set one $value; redis2_pass 127.0.0.1:6379; } location = /get { redis2_query get one; redis2_pass 127.0.0.1:6379; } ...
sequenceDiagram actor u as user actor n as nginx actor r as redis u->>n: http请求/get n->>r: get命令key值为one r->>n: 标准命令处理 n->>u: 返回原始键值
常见问题
-
server_names_hash问题
[emerg] could not build server_names_hash, you should increase server_names_hash_bucket_size: 32 -
解决办法
# 如果不够,继续增加,大小必须是32*n server_names_hash_bucket_size 64; -
invalid request问题
# asscess.log 有这种提示 "PRI * HTTP/2.0" 400 157 "-" "-" # error.log 有这种提示 client sent invalid request while reading client request line -
解决办法-客户端没有采用ssl,tls,但访问nginx配置需要ssl
-
php-fpm出现Primary script unknown问题
-
尝试修改nginx配置
# FastCGI sent in stderr: "Primary script unknown" while reading response header from upstream, # fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; -
如果仍然不行,则打开php-fpm.conf日志配置
access.log = /var/log/php-fpm.$pool.access.log -
再打开nginx日志配置
# http log_format scripts '$document_root$fastcgi_script_name > $request'; # server access_log /usr/local/nginx/scripts.log scripts; -
重启nginx,和php-fpm 查看日志,一般是路径不对和权限不对
-
-
php-fpm出现无法连接数库,可能是编译参数不对
./configure --enable-fpm --prefix=/usr/local/php --with-mysqli=mysqlnd --with-pdo-mysql=mysqlnd -
不知道当前nginx所用配置文件
# 获取nginx进程号 ps -ef | grep nginx # 获取nginx路径 cd /proc/pid ls -a # 执行相应路径的语法测试,输出就能看到路径 nginx -t -
不知道当前nginx的编译参数
# 获取nginx进程号 ps -ef | grep nginx # 获取nginx路径 cd /proc/pid ls -a # 执行相应路径的语法测试,输出就能看到路径 nginx -V
rtmp
下载安装rtmp模块
编译
/configure --prefix=/Users/Shared/nginx \
--add-module=../nginx-party-module/nginx-rtmp-module \
--with-http_ssl_module \
--with-openssl=/opt/homebrew/Cellar/openssl@1.1/1.1.1m\
--with-debug
make
make install
修改配置
rtmp {
server {
listen 1935;
application vod {
play /Users/xxx/iCloud-archive/video;
}
}
}
访问
#vlc打开串流地址
rtmp://host/vod/xxx.mp4
附录
-
RTMP、RTSP、HTTP协议理论上都可以用来做视频直播或点播,直播一般用RTMP,RTSP,点播用 HTTP
-
RTMP协议
- 是流媒体协议。
- RTMP协议是 Adobe 的私有协议,未完全公开。
- RTMP协议一般传输的是 flv,f4v 格式流。
- RTMP一般在 TCP 1个通道上传输命令和数据。
-
RTSP协议
- 是流媒体协议。
- RTSP协议是共有协议,并有专门机构做维护
- RTSP协议一般传输的是 ts、mp4 格式的流。
- RTSP传输一般需要 2-3 个通道,命令和数据通道分离。
-
HTTP协议
- 不是是流媒体协议。
- HTTP协议是共有协议,并有专门机构做维护
- HTTP协议没有特定的传输流
- HTTP传输一般需要 2-3 个通道,命令和数据通道分离
golang
官网
-
Go Search Extension浏览器扩展, 地址栏输入go+空格启用
-
golang.org国内经常访问不了
-
通过go bulid -tags 实现编译控制
-
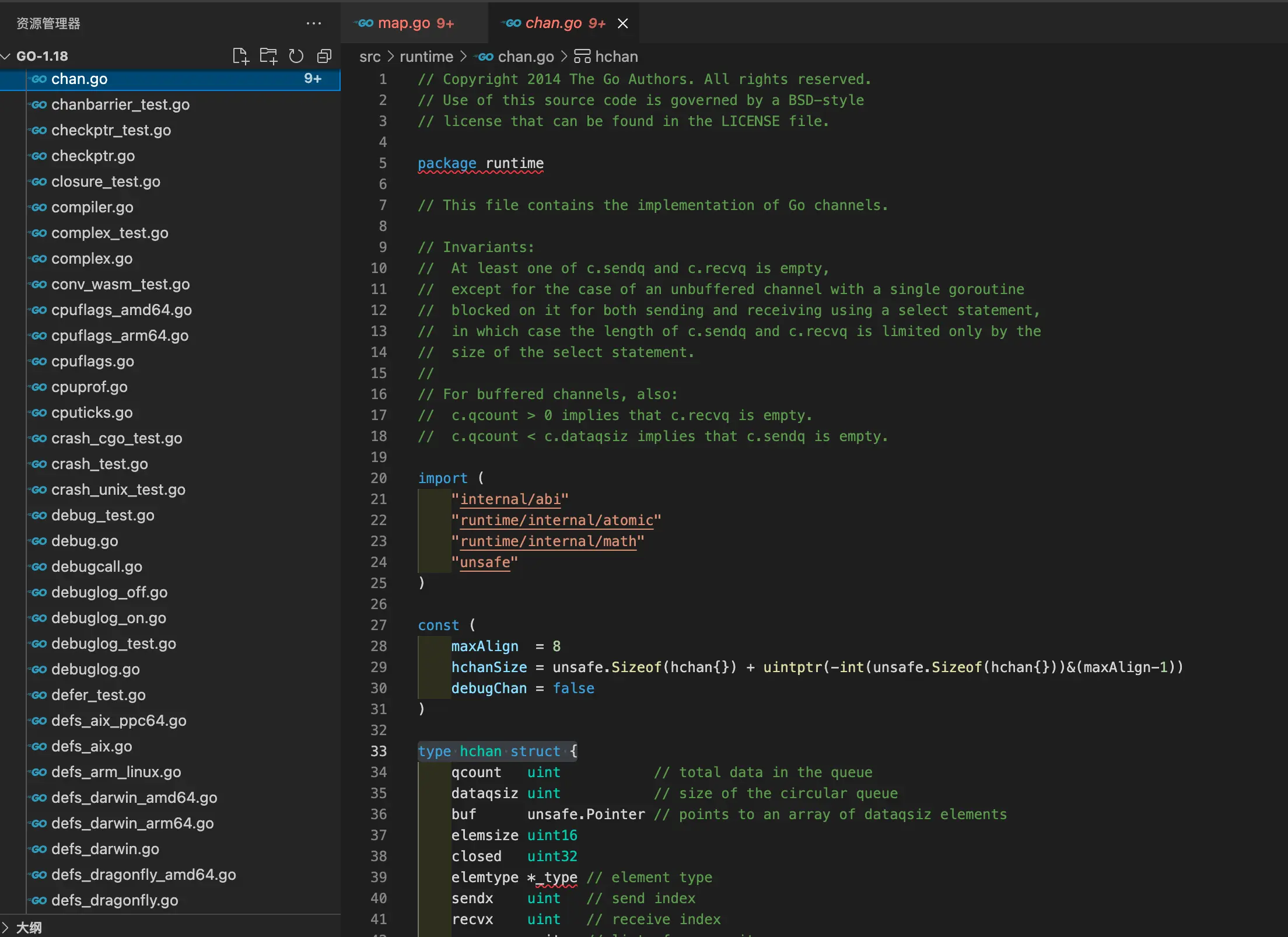
内置数据类型定义在runtime包,如下图所示
-
吐槽一下
- 破坏注释不影响代码的传统,这类//go:注释,有特别含义,会影响代码作用,使用者非常容易误解
- 强制mod方式管理第三方模块
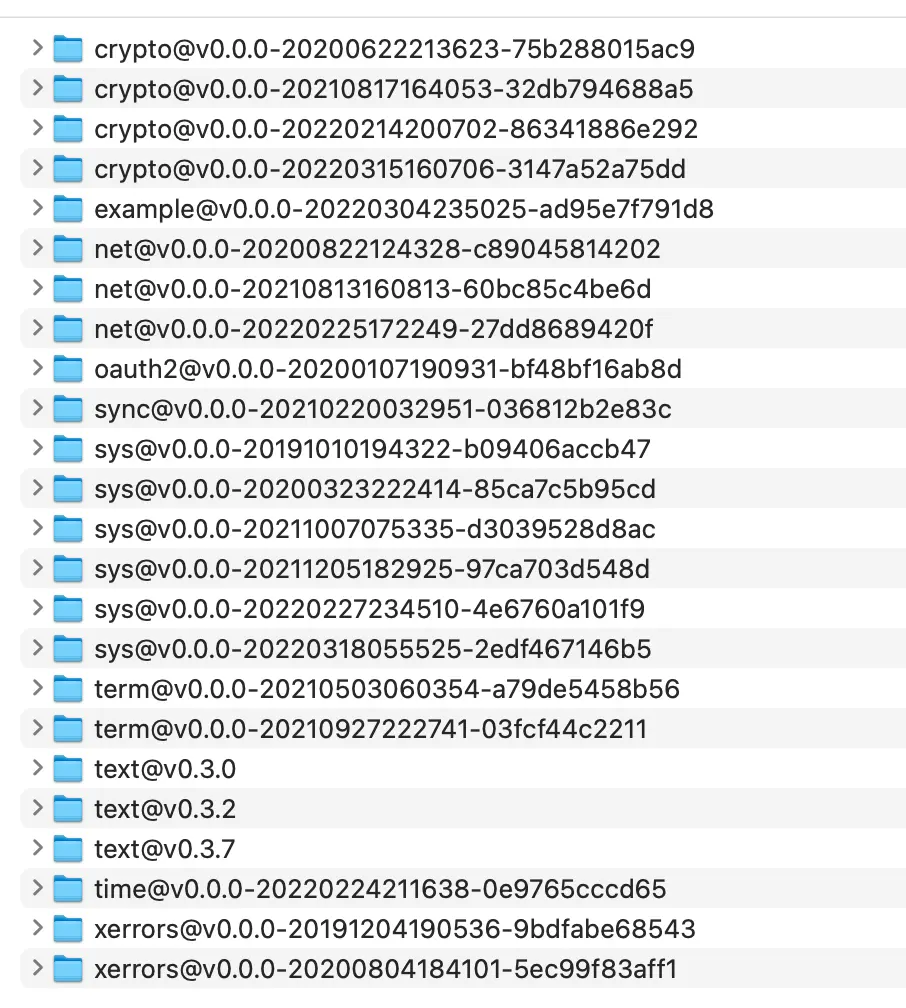
- 用代码库+版本解决依赖
- 带来重大著名库大量重复存在,GOPATH成垃圾桶
- 带来更多名词,增加心智负担,精力分散在语言之外过多
- 严重偏向开源开发模式,对闭源开发不友好
-
Go 生态系统中有着许多中国 Gopher 们无法获取的模块,因此设置 CDN 加速代理就很有必要了,以下是几个速度不错的提供者:
-
go env -w GOPROXY=xxx,direct
-
七牛:Goproxy 中国 (https://goproxy.cn)
-
阿里: (mirrors.aliyun.com/goproxy/)
-
官方: 全球 CDN 加速 (https://goproxy.io/)
-
其他:jfrog 维护 (https://gocenter.io)
环境变量
# 安装到默认目录
rm -rf /usr/local/go && tar -C /usr/local -xzf go1.19.linux-amd64.tar.gz
# 导出环境变量
export PATH=$PATH:/usr/local/go/bin
# 查看安装成功否
go version
#列出环境变量
go env
#GOPATH环境变量,如果没有手动设置,默认为$HOME/go
GOPATH=$HOME/go
#模块缓存是 go 命令存储下载模块文件的目录,默认是$GOPATH/pkg/mod.
GOMODCACHE
#清除mod cache,pkg目录里面全没了
go clean --modcache
#Build Cache意思就是会把编译过程的中间结果cache下来,从而实现增量编译。
#Test cache,在内容没有变化的情况下,对于同样的参数的测试,会直接使用cache的测试结果
#cache默认的存储路径是操作系统所确定的用户缓存目录,但是可以通过GOCACHE环境变量修改
GOCACHE
#清除build cache
go clean -cache
#清除test cache
go clean -testcache
#GOPROXY(公共)修改为国内代理
#全球代理https://proxy.golang.com.cn(https://goproxy.io/)
#阿里云 https://mirrors.aliyun.com/goproxy/
#七牛云 https://goproxy.cn
#direct表示直接从包路径下载
go env -w GOPROXY=https://goproxy.cn,direct
#GOPRIVATE设置私有库
#还可以设置不走 proxy 的私有仓库或组,多个用逗号相隔(可选)
#允许通配符
go env -w GOPRIVATE=git.mycompany.com,github.com/my/private,*.example.com
#GOVCS变量
#可以使用git下载带有 github.com 路径的模块;无法使用任何版本控制命令下载 evil.com上的路径
#使用 git 或 hg 下载所有其他路径(* 匹配所有内容)的模块。
GOVCS=github.com:git,evil.com:off,*:git|hg
#GOSUMDB变量
#默认的GOSUMDB=sum.golang.org验证包的有效性,经常访问不了
go env -w GOSUMDB=off
#使用国内代理
go env -w GOSUMDB=https://goproxy.cn/sumdb/sum.golang.org,sum.golang.org
-
GOPROXY说明
- You can set the variable to URLs for other module proxy servers, separating URLs with either a comma or a pipe.
- When you use a comma, Go tools will try the next URL in the list only if the current URL returns an HTTP 404 or 410.
GOPROXY="https://proxy.example.com,https://proxy2.example.com"- When you use a pipe, Go tools will try the next URL in the list regardless of the HTTP error code.
GOPROXY="https://proxy.example.com|https://proxy2.example.com" -
GOPRIVATE说明
- The GOPRIVATE or GONOPROXY environment variables may be set to lists of glob patterns matching module prefixes that are private and should not be requested from any proxy.
-
GOVCS说明
- 版本控制工具中的错误可能被恶意服务器利用来运行恶意代码
- 如果未设置环境变量GOVCS,或者不匹配,GOVCS的默认处理:允许 git 和 hg 用于公共模块,并且允许所有工具用于私有模块。
go mod命令指南
#最后结果都是写入go.mod文件
go mod init path
go mod edit --replace modulepath=otherpath
go mod edit --exclude modulepath
#tidy整理依赖,增加没有添加或移除未引用等
go mod tidy
#整检依赖是否正解
go mod verify
- 采用mod方式管理依赖,则没有gopath/src,改到gopath/mod
- go.sum不需要手工维护,也不要手工改动
- 所有的子目录里的依赖都组织在根目录的go.mod文件
- replace指令场景
- 替换无法下载的包
- 替换本地自己的包
- 替换 fork 包
- exclude显式的排除某个包的某个版本,例如某个版本有严重bug,如果其他包引用这个版本,就会自动跳过这个版本
- 文章介绍较直白
- 文章介绍retract指令

工作区-多模块
#最后结果都是写入go.work文件
Usage:
go work <command> [arguments]
The commands are:
edit edit go.work from tools or scripts
init initialize workspace file
sync sync workspace build list to modules
use add modules to workspace file
- workspace目录

- go.work内容
#go work use ./hello
#go work use ./example
#./hello,./example是本地路径,不是example,hello的module名
go 1.18
use (
./example
./hello
)
- hello/main.go内容
package main
import (
"fmt"
"golang.org/x/example/stringutil"
)
func main() {
fmt.Println(stringutil.ToUpper("Hello"))
}
- hello/go.mod内容
module example.com/hello
go 1.18
require golang.org/x/example v0.0.0-20220304235025-ad95e7f791d8 // indirect
-
- 在workspace目录下运行go run example.com/hello
-
- 不用改动go.mod,使得golang.org/x/example由本工作区的example替代
-
- 可实现多模块同时开发
相关工具go tools
get/install下载包过程
// import "example.org/pkg/foo"
//
// will result in the following requests:
//
// https://example.org/pkg/foo?go-get=1 (preferred)
// http://example.org/pkg/foo?go-get=1 (fallback, only with use of correctly set GOINSECURE)
//
// If that page contains the meta tag
//
// <meta name="go-import" content="example.org git https://code.org/r/p/exproj">
//
// the go tool will verify that https://example.org/?go-get=1 contains the
// same meta tag and then git clone https://code.org/r/p/exproj into
// GOPATH/src/example.org.
// go get/install当服务器支持多种协议优先使用https://, 然后git+ssh://.

#包括godoc等工具
#./godoc -http :6060
go install golang.org/x/tools/...@latest.
#浏览器本地文档,如果起启目录有go.mod会继续分析提供文档,但是增加启动时间
godoc -http :6060
#安装pprof,如果不在mod目录下运行,就指明@latest最近版本
go install github.com/google/pprof@latest
#下载最新版本
go get example.com/theirmodule@vlatest
#下载指定版本
go get example.com/theirmodule@v1.3.4
go get example.com/theirmodule@4cf76c2
go get example.com/theirmodule@bugfixes
#移除指定版本模块
go get example.com/theirmodule@none
#查看所有依赖模块的最新版本
go list -m -u all
#查看指定模块的最新版本
go list -m -u example.com/theirmodule
#升级后会将新的依赖版本更新到go.mod
go get -u need-upgrade-package
#升级所有依赖
go get -u
go tool pprof
go tool trace
#获取当前git hash
Cgithash=$(git rev-parse --short HEAD)
#获取当前时间
Ctime=$(date '+%Y-%m-%d_%H:%M:%S')
# 交叉编译
# 禁止cgo
# 设置编译目标平台
# 设置编译芯片体系
#-s: 去掉符号表; -w:去掉调试信息,不能gdb调试了;
CGO_ENABLED=0 GOARCH=amd64 GOOS=linux go build -o ${target} -ldflags "-s -w -X main.GitHash=${Cgithash} -X main.CompileTime=${Ctime}" main.go
#获取程序更多信息(包括-ldflags参数设置)
go version -m 二进制可执行文件
#新增inittrace指令, 用于init调试和启动时间的概要分析
GODEBUG=inittrace=1 go run main.go
#简化代码
gofmt -s -w xxx.go
- 文章介绍pprof
- 文章介绍trace
- 创建protoc插件
golangci-lint,替代品lint-静态检查库
#快速安装,会自动下载依赖安装对应的go版本,如果系统安装有go,那么注意搜索PATH
brew install golangci-lint
#手动下载,选择最新及相应的平台,最新版本在go1.18有部分lint不支持,需要适时更新
https://github.com/golangci/golangci-lint/releases
#较大规模项目,或第一次运行应该增加超时选择
#golangci-lint会采用缓存,如果环境变没有设置,则采用系统默认设置
golangci-lint run --timeout=1h
#GolangCI-Lint looks for config files in the following paths from the current working directory:
.golangci.yml
.golangci.yaml
.golangci.toml
.golangci.json
#这几个参数比较有用
skip-dirs:
- src/external_libs
- autogenerated_by_my_lib
# Enables skipping of directories:
# - vendor$, third_party$, testdata$, examples$, Godeps$, builtin$
# Default: true
skip-dirs-use-default: false
# Which files to skip: they will be analyzed, but issues from them won't be reported.
# Default value is empty list,
# but there is no need to include all autogenerated files,
# we confidently recognize autogenerated files.
# If it's not please let us know.
# "/" will be replaced by current OS file path separator to properly work on Windows.
skip-files:
- ".*\\.my\\.go$"
- lib/bad.go
小米出品-Soar-sql优化改写
#手动下载,选择最新及相应的平台,老黄历版本啦!
https://github.com/XiaoMi/soar/releases
#源码安装,报gopath/pkg/mod/github.com/!xiao!mi/soar@v0.8.1/ast/tidb.go:24:2: ambiguous import:
#解决办法:跳过此种方式,估计没有指到最新版本,没心情找原因
go install github.com/XiaoMi/soar/cmd/soar@latest
#最原始办法
git clone https://github.com/XiaoMi/soar.git
cd soar
make
#测试使用
echo 'select * from film' | ./soar
go generate命令
-
当运行go generate时,它将扫描与当前包相关的源代码文件,找出所有包含“//go:generate“的特殊注释
-
提取并执行该特殊注释后面的命令,命令为可执行程序,形同shell下面执行
- 该特殊注释必须在.go源码文件中。
- 每个源码文件可以包含多个generate特殊注释时。
- 显示运行go generate命令时,才会执行特殊注释后面的命令。
- 命令串行执行的,如果出错,就终止后面的执行。
- 特殊注释必须以“//go:generate“开头,双斜线后面没有空格。
-
应用
- yacc:从 .y 文件生成 .go 文件。
- protobufs:从 protocol buffer 定义文件(.proto)生成 .pb.go 文件。
- Unicode:从 UnicodeData.txt 生成 Unicode 表
go generate [-run regexp] [-n] [-v] [-x] [build flags] [file.go... | packages]
-
参数说明如下:
- -run 正则表达式匹配命令行,仅执行匹配的命令;
- -v 输出被处理的包名和源文件名;
- -n 显示不执行命令;
- -x 显示并执行命令;
- command 可以是在环境变量 PATH 中的任何命令。
核心语法
-
逃逸分析
-
目标:减轻堆内存分配开销,减少gc压力,提高运行性能
-
编译器会做逃逸分析(escape analysis),变量的作用域没有跑出函数范围,在栈上,反之在堆上。
-
实践
#输出分析结果 go build -gcflags '-m -l' main.go #反汇编查看,出现runtime.newobject,就发现逃逸行为 go tool compile -S main.go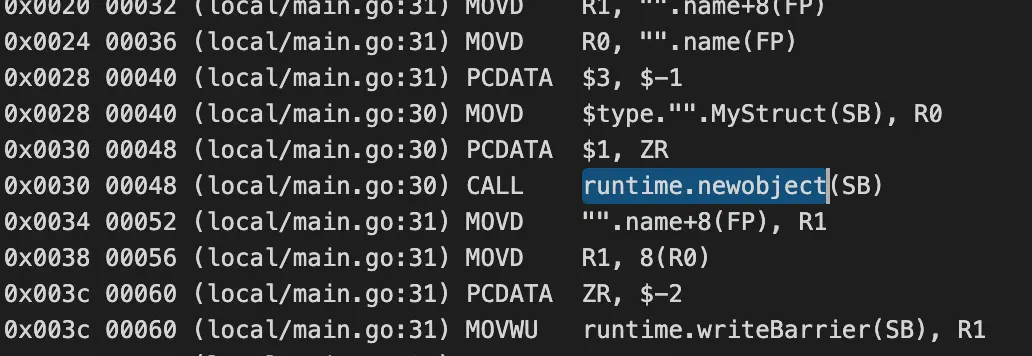
-
结论
-
常见逃逸
-
在某个函数中new或字面量创建出的变量,将其指针作为函数返回值,则该变量一定发生逃逸(构造函数返回的指针变量一定逃逸);
建议:调用方传入参,被调用方直接把结果存进去
比如 read 函数的签名是 read([]byte),而不是 read() []byte,就是为了避免堆分配.
-
被已经逃逸的变量引用的指针,一定发生逃逸;
-
被指针类型的slice、map和chan引用的指针,一定发生逃逸,所以slice,map,chan尽管传值,不使用传指针,除非超大复制量;
-
申请超大容量变量,栈空间是有限的
-
作为fmt.printxxx参数,没事少用点
-
make,new,字面量初始化变量都一样要逃逸分析
-
-
常见不逃逸
- 指针被未发生逃逸的变量引用;
- 仅仅在函数内对变量做取址操作,而未将指针传出;
-
可能发生逃逸
- 将指针作为入参传给别的函数;这里还是要看指针在被传入的函数中的处理过程,如果发生了上边的三种情况,则会逃逸;否则不会逃逸;
-
-
-
泛型
- 类型参数:泛型的抽象数据类型。
TypeParameters = "[" TypeParamList [ "," ] "]" . TypeParamList = TypeParamDecl { "," TypeParamDecl } . TypeParamDecl = IdentifierList TypeConstraint .- 类型约束:确保调用方能够满足接受方的程序诉求。
TypeConstraint = TypeElem . TypeElem = TypeTerm { "|" TypeTerm } . TypeTerm = Type | UnderlyingType . UnderlyingType = "~" Type ./* 内置comparable类型约束 comparable is an interface that is implemented by all comparable types (booleans, numbers, strings, pointers, channels, arrays of comparable types, structs whose fields are all comparable types). The comparable interface may only be used as a type parameter constraint, not as the type of a variable.*/ type comparable interface{ comparable }-
类型推导:避免明确地写出一些或所有的类型参数。
-
为保证GO1兼容性,标准库并没有引入泛型,试验性在golang.org/x/exp里
-
Go 1.15 增加了一个新程序包,time/tzdata。该程序包允许将时区数据库嵌入程序中
-
Go1.16 开始禁止 import 导入的模块以 . 开头,模块路径中也不允许出现任何非 ASCII 字符
-
Go 1.16 新增的 embed 包支持资源嵌入
//把资源文件打包到二进制文件中
import (
"fmt"
//go1.16引入新的标准库
_ "embed"
"runtime/debug"
)
//golang特有编译器指示,类似//go:noinline,go:build
//go:embed hello.txt
var hello string
func main() {
//调试好帮手,打印出调用栈
debug.PrintStack()
fmt.Println("hello:", hello)
}
- 弃用 io/ioutil,已移至其他程序包
- timer性能提升,defer的性能,几乎是零开销
- 合并结构体标签tag设置标识
type MyStruct struct {
Field1 string `json:"field_1,omitempty" bson:"field_1,omitempty" xml:"field_1,omitempty" form:"field_1,omitempty" other:"value"`
}
// 就可以通过合并的
type MyStruct struct {
Field1 string `json,bson,xml,form:"field_1,omitempty" other:"value"`
}
-
context 主要用来在 goroutine 之间传递上下文信息,包括:取消信号、超时时间、截止时间、k-v 等.这篇文章解释清楚.
- 上游的信息共享给下游任务
- 上游可发送取消信号给所有下游任务,不会直接干涉和中断下游任务的执行,下游任务自行决定后续的处理操作.
- 下游任务自行取消不会影响上游任务
- 源码不理解?
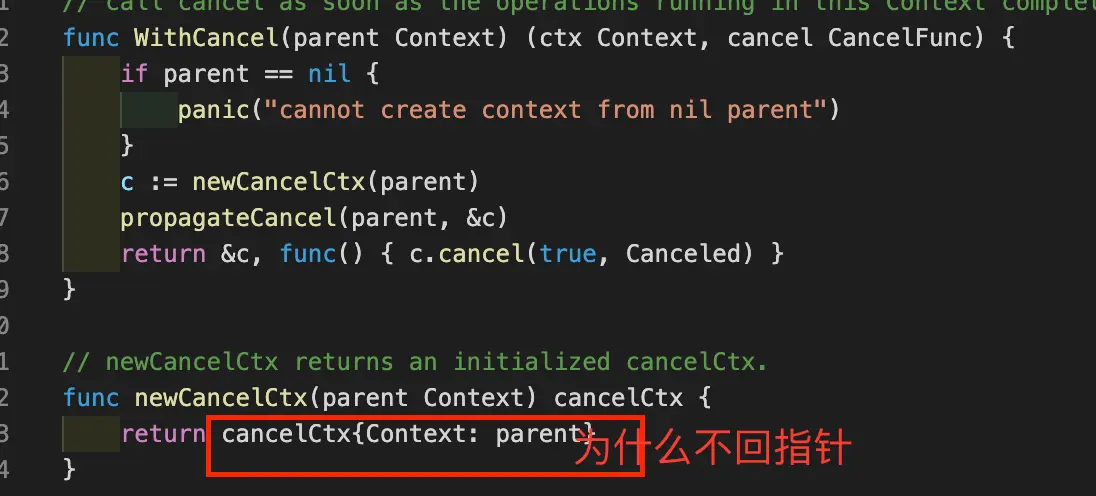
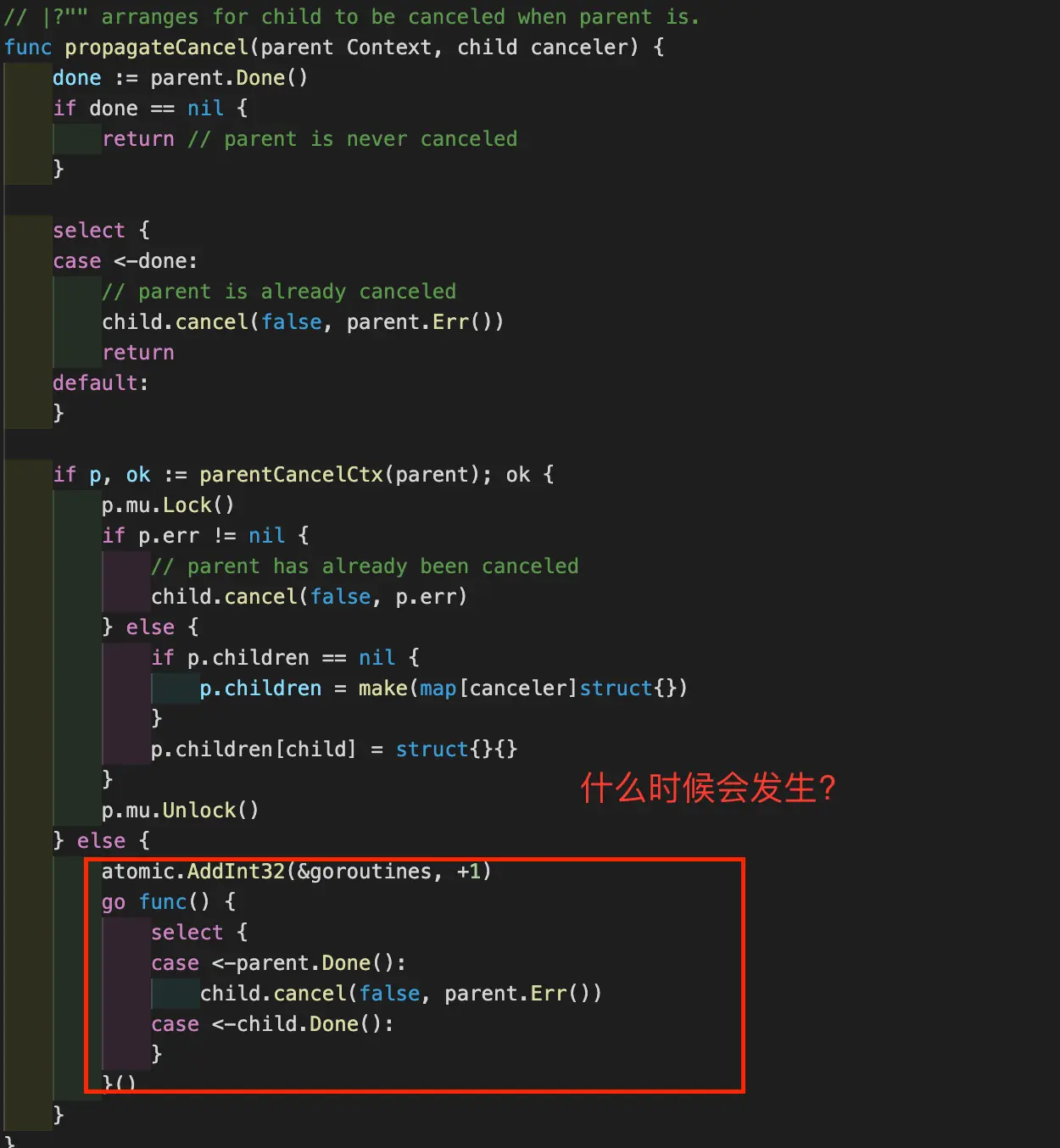
-
字符串,只读的切片,写入操作都是通过拷贝实现的。
// 原始,特别适合不要转义
var rawString = `\n \b \s \u`
// 带转义
normalStr := "aabbcc"
// 从string转[]byte,从[]byte转string,都是拷贝数据
// 而内存拷贝的性能损耗会随着字符串和 []byte 长度的增长而增长。
- 数字字面量,下划线只为美观
// 二进制110
var binary = 0b1_1_0
// 十进制712
var digit = 7_1_2
// 向下取整,div=3
var div = 7 / 2
- 数组
//明确指出
arr1 := [3]int{1, 2, 3}
//编译器推定
arr2 := [...]int{1, 2, 3}
/*
数组元素+数组大小相同才是同一类型,才能相等
*/
- 切片
//使用下标初始化切片不会拷贝原数组或者原切片中的数据,它只会创建一个指向原数组的切片结构体,所以修改新切片的数据也会修改原切片
arr[0:3] or slice[0:3]
//最终转化为上面方式
slice := []int{1, 2, 3}
//如果len/cap较小,最终转化为上面方式,否则运行时处理
slice := make([]int, 10)
/*
make([]type, len) 相当于 make([]type, len, len)
b ;= a[low : high : max]
b[0] = a[low]
len(b) = high-low
cap(b) = max - low
a[low:high] 相当于 a[low : high : cap(a)]
a[:high] 相当于 a[0:high]
a[low:] 相当于 a[low:len(a)]
a[:] 相当于 a[0:len(a)]
*/
- map
- cap理论上都是无穷的,使用自动扩容
- 内置的map多协程操作不安全
- sync.map是多协程安全
//len是0
firstMap := make(map[string]int)
//len是0,10只是帮助初次cap大小
secMap := make(map[string]int, 10)
//len是2,
threeMap := map[string]int{
"one": 1,
"two": 2,
}
// 一般建议这种访问,区别val是否有效
val, exist := threeMap["one"]
delete(threeMap, "two")
-
函数
-
参数的计算是从左到右
-
参数是值传递,返回值也是值传递,影响深远

-
slice,make,chan底层实现struct中包括指针,从而实现引用效果
-
-
接口
- runtime.iface带方法,runtime.eface不带方法,两种不同.
type eface struct { _type *_type data unsafe.Pointer } type iface struct { tab *itab data unsafe.Pointer } type itab struct { inter *interfacetype _type*_type // 类型断言时使用,复制_type中hash hash uint32 ... fun [1]uintptr } type _type struct { ... ptrdata uintptr // 类型断言时使用 hash uint32 ... equal func(unsafe.Pointer, unsafe.Pointer) bool ... }- 隐式实现,区别其他语言
- 接口本身为nil,和接口值为nil是两回事
- 直接调用OR动态派发?编译器优化会把动态派发改为直接调用,以减少性能的额外开销.
type Person interface { Speak() } type Man struct { Voice string } func (m *Man) Speak() { fmt.Println("Voice:", m.Voice) } func main() { m := &Man{Voice: "firstMan"} var p Person = m //直接调用,类型转换是编译期完成 p.(*Man).Speak() //动态派发,比直接调用多取出data和fun两个动作 p.Speak() } -
gc
-
暂停程序(Stop the world,STW),随着程序申请越来越多的内存,系统中的垃圾也逐渐增多;当程序的内存占用达到一定阈值时,整个应用程序就会全部暂停,垃圾收集器会扫描已经分配的所有对象并回收不再使用的内存空间,当这个过程结束后,用户程序才可以继续执行.
-
垃圾收集可以分成清除终止、标记、标记终止和清除
-
用户程序,分配器,gc收集器,head关系图
-
sequenceDiagram
actor m as 用户程序
actor a as 分配器
actor h as heap堆内存
actor c as gc收集器
m->>a: make/new等申请内存
a->>h: malloc申请,初始化
c-->>h: free释放内存
* 栈空间,不用码农操作心, 大致了解连续栈,栈扩容,栈收缩一下
* 反射,影响性能,不必要不使用.
* 第一原则,任意类型变量转换成反射对象
```mermaid
flowchart LR
int(int) --类型转换--> i(interface对象)
float(float) --类型转换--> i
bool(bool) --类型转换--> i
string(string) --类型转换--> i
struct(struct) --类型转换--> i
slice(slice) --类型转换--> i
array(array) --类型转换--> i
subgraph 反射对象
subgraph TypeOf
ri(reflect.Type)
end
subgraph ValueOf
rv(reflect.Value)
end
i --类型转换--> ri
i --类型转换--> rv
end
-
第二原则,反射对象可以获取 interface{} 变量
v := reflect.ValueOf("st") v.Interface().(string)
flowchart LR rv(reflect.Value) --Interface方法--> i(interface对象) i --类型断言--> string(string)
- 第三原则,通过反射对象修改值,要传指针
mystr := "old"
//直接传mystr是不行的
vo := reflect.ValueOf(&mystr)
vo.Elem().SetString("new")
fmt.Println(mystr)
-
for
for { } 相当于 for true { } for cond { } 相当于 for ; cond ; { } // RangeClause = [ ExpressionList "=" | IdentifierList ":=" ] "range" Expression .- for-range
- 遍历之前都有copy数组/切片/map/chan,
- golang里面一切都是值拷贝,注意值拷贝带来的影响
- 循环变量每次都重新copy
- for-range
-
channel
-
只有make一种创建方式,要不为nil,要不为有效chan
-
有无缓冲?
// 无缓冲 make(chan Type) // 有缓冲 make(chan Type, Len(buf))-
读取
- 读取nil channel永远阻塞,Receiving from a nil channel blocks forever.
- 第二值为true,表示第一值为发送值,否则表示第一值zero value,系统构造的,暗示channel已经close
- channel关闭是指不能再写入,不影响读取.已经关闭的channel仍然能被读取
-
先入先出,先写入数据先被读取出来
-
close一个空指针或者已经被关闭channel,运行时都会直接崩溃并抛出异常:
-
-
select
- 每个case一个Channel上非阻塞的收发操作;
- 多个case同时响应时,会随机执行一种情况;
- 如果default存在,则在case不响应时立即执行,否则阻塞等待case响应
-
defer
- 退出函数之前执行
- 多次调用 defer执行顺序:先进后出,后进先出
- defer func参数在调用时求值,仍旧是值传递
-
panic
- panicc后会立刻停止执行当前函数的剩余代码
- 仅执行本Goroutine中的defer
- 如果defer中没有recover处理,则整个程序退出(os.exit)
- 允许多次panic—在执行defer时,还可以再次panic
-
recover
-
只有在 defer 中调用才会生效,其他地方无效
-
可以中止 panic 造成的程序崩溃
-
返回值为最近的panic参数,返回值为nil情况
- panic’s argument was nil;
- the goroutine is not panicking;
- recover was not called directly by a deferred function.
-
一次recover只能恢复一个panic
func main() { defer println("main exit") go func() { defer func() { if reply := recover(); reply != nil { println("recover:", reply.(string)) } }() panic("panic another") }() go func() { defer func() { defer func() { if reply := recover(); reply != nil { println("recover:", reply.(string)) } }() if reply := recover(); reply != nil { println("recover:", reply.(string)) } panic("panic continue") }() panic("panic begin") }() time.Sleep(1 * time.Second) -
sync
- Mutex,RWMutex
-
flowchart LR
l(Locker) --实现接口--> m(Mutex)
m --继承--> rw(RWMutex)
* WaitGroup
* 一些扩展使用
* golang/sync/errgroup.Group带错误传播
* golang/sync/singleflight.Group限制同时产生大量相同请求
* pool临时对象复用池
* Map 多协程安全操作map,对内置map扩展
* Once 保证只执行一次
* Cond 信号量
* 扩展使用
* golang/sync/semaphore.Weighted带权重信号量
-
协程调度
- G-M-P模型
- M是操作系统线程,由操作系统管理,GOMAXPROCS(一般是当前机器的核数)个活跃线程
- G是Go运行时中用户态提供的线程,代表待执行的任务,表现为函数执行
- P是线程和G的中间层,一个线程一个P,一个P一个本地G的队列,优先取本地的运行队列,然后取全局的运行队列
- G-M-P模型
-
time
- Timer–>单次事件,The Timer type represents a single event.
- Ticker–>定时器,A Ticker holds a channel that delivers “ticks” of a clock at intervals.
- Duration–>时间长度,例如:1分钟,10天
- Time–>时间点,例如:2022年1月2日03点4分15秒
- Location–>时区,例如:北京时间
- tzdata–>子包,打包时区数据库到程序,会增加程序二进制大小
- 每个处理器单独管理计时器并通过网络轮询器触发
- golang.org/x/time/rate扩展包带了一个令牌桶限流算法
// token自动按速率产生,通过Wait/Allow消费token // 10是每秒可以向 Token 桶中产生多少 token // 100是 代表 Token 桶的容量大小 limiter := rate.NewLimiter(10, 100); -
json
- JSON 本身就是一种树形的数据结构,无论是序列化还是反序列化,都会遵循自顶向下的编码和解码过程,使用递归的方式处理 JSON 对象。
- 采用反射完成序列化/反序列化逻辑
- struct对象可以tag调整json序列化/反序列化行为
-
net
-
listen(network, address string)
- The network must be “tcp”, “tcp4”, “tcp6”, “unix” or “unixpacket”. For TCP networks, if the host in the address parameter is empty or a literal unspecified IP address, Listen listens on all available unicast and anycast IP addresses of the local system. To only use IPv4, use network “tcp4”. The address can use a host name, but this is not recommended, because it will create a listener for at most one of the host’s IP addresses. If the port in the address parameter is empty or “0”, as in “127.0.0.1:” or “[::1]:0”, a port number is automatically chosen. The Addr method of Listener can be used to discover the chosen port.
-
Dial(network, address string)
- Known networks are “tcp”, “tcp4” (IPv4-only), “tcp6” (IPv6-only), “udp”, “udp4” (IPv4-only), “udp6” (IPv6-only), “ip”, “ip4” (IPv4-only), “ip6” (IPv6-only), “unix”, “unixgram” and “unixpacket”. For TCP and UDP networks, the address has the form “host:port”.
-
扩展包golang.org/x/net有不少好功能实现
-
-
http
-
客户端,核心两个结构-Request,Response
- net/http.Client
- net/http.Transport
- net/http.persistConn
-
flowchart LR
c(Client) --调用--> t(Transport)
t --调用-->c(persistConn)
* 服务端,核心两个结构-Request,ResponseWriter
* net/http.Server
* net/http.ServeMux
* net/http.Handler
flowchart LR
c(Server) --调用--> t(ServeMux)
t --调用-->c(Handler)
* RoundTripper,代表一个http事务,给一个请求返回一个响应,可以自定义功能,例如:缓存responses
````golang
type RoundTripper interface {
RoundTrip(*Request) (*Response, error)
}
````
* net/http/httptrace,net/http/httptrace
-
golang.org/x/image扩展bmp,webp等功能实现
-
golang.org/x/text扩展不少像gbk转utf8,高级文本搜索等功能
-
io.Reader/Writer
- net.Conn: 表示网络连接。
- os.Stdin, os.Stdout, os.Stderr: 标准输入、输出和错误。
- os.File: 网络,标准输入输出,文件的流读取。
- strings.Reader: 字符串抽象成 io.Reader 的实现。
- bytes.Reader: []byte抽象成 io.Reader 的实现。
- bytes.Buffer: []byte抽象成 io.Reader 和 io.Writer 的实现。
- bufio.Reader/Writer: 带缓冲的流读取和写入(比如按行读写)。
-
sql
type Driver interface {
...
}
type Conn interface {
...
}
type DB struct {
// contains filtered or unexported fields
}
type Stmt struct {
// contains filtered or unexported fields
}
type Tx struct {
// contains filtered or unexported fields
}
-
测试
- 功能测试
// 文件名格式xxx_test.go // 函数名格式TestXxx,Test开头,第一个字母必须大写 // 函数参数必须是t *testing.T // 失败采用t.Fatalxxx,t.Errorxx输出 func TestAdd(t *testing.T) { if Add(10, 20) == 12 { t.Fatal("failure") } }# 启动 go test- 压力测试
// 文件名格式xxx_test.go // 函数名格式BenchmarkXxx,Benchmark开头,第一个字母必须大写 // 函数参数必须是b *testing.B // 测试性能前提是功能正确,所以没有失败一说 func BenchmarkAdd(b *testing.B) { for i := 0; i < b.N; i++ { Add(rand.Int(), rand.Int()) } }# 启动, -bench pattern正则表达式,测试目标 go test -bench .- 随机测试
// 文件名格式xxx_test.go // 函数名格式FuzzXxx,Fuzz开头,第一个字母必须大写 // 函数参数必须是f *testing.F // 失败采用t.Fatalxxx,t.Errorxx输出 func FuzzAdd(f *testing.F) { for i := 0; i < 10; i++ { // 随机种子语料 // f.Add参数个数及类型及顺序,必须和后面一样 f.Add(rand.Int(), rand.Int()) } // func(t *testing.T, left, right int), 参数除t之外, 参数个数及类型及顺序,必须和f.Add一样 f.Fuzz(func(t *testing.T, left, right int) { if Add(left, right) != left+right { t.Errorf( "%v+%v=%v, result:%v", left, right, Add(left, right), left+right) } }) }# 启动,会一直执行下去,除非加上 -fuzztime 30s 指定运行时间 go test -fuzz Fuzz
ac_machine
ahocorasick算法,快速在输出文本中查找有没有出现字典中文本
package main
import (
"fmt"
"github.com/cloudflare/ahocorasick"
)
func main() {
strList := []string{
"apple", "banana", "cherry"}
// 构建AC自动机
ac := ahocorasick.NewStringMatcher(strList)
// 在文本中查找匹配项
matches := ac.Match([]byte("I like banana and cherry."))
for _, match := range matches {
fmt.Println("找到了:", strList[match])
}
}
package main
import (
"fmt"
"github.com/anknown/ahocorasick"
)
func main() {
// 构建AC自动机
dict := [][]rune{
[]rune("apple"),
[]rune("banana"),
[]rune("cherry"),
}
content := []rune("your apple text")
m := new(goahocorasick.Machine)
if err := m.Build(dict); err != nil {
fmt.Println(err)
return
}
terms := m.MultiPatternSearch(content, false)
for _, t := range terms {
fmt.Printf("%d %s\n", t.Pos, string(t.Word))
}
}
ast
Go 语言的 ast(Abstract Syntax Tree,抽象语法树)包是标准库中用于代码分析的核心工具,常用于代码检查、格式化、自动化重构等场景。
1. AST 基础概念
- 抽象语法树:将源代码解析为树状数据结构,保留逻辑结构但忽略细节(如空格、注释)。
- 节点类型:所有 AST 节点实现
ast.Node接口,常见类型包括:ast.File: 单个 Go 文件ast.FuncDecl: 函数声明ast.StructType: 结构体定义ast.CallExpr: 函数调用表达式
2. 核心流程
步骤 1:解析源代码
使用 go/parser 将代码转换为 AST:
fset := token.NewFileSet()
node, err := parser.ParseFile(fset, "demo.go", srcCode, parser.ParseComments)
// node 是 *ast.File 类型
步骤 2:遍历 AST
通过 ast.Inspect 或自定义遍历函数递归访问节点:
ast.Inspect(node, func(n ast.Node) bool {
if ident, ok := n.(*ast.Ident); ok {
fmt.Println("Found identifier:", ident.Name)
}
return true // 继续遍历子节点
})
3. 关键结构体
-
ast.File: 文件节点type File struct { Name *Ident // 包名 Decls []Decl // 顶级声明(函数、结构体等) Imports []*ImportSpec // 导入声明 } -
ast.FuncDecl: 函数声明type FuncDecl struct { Recv *FieldList // 接收器(方法) Name *Ident // 函数名 Type *FuncType // 函数签名 Body *BlockStmt // 函数体 } -
ast.StructType: 结构体定义type StructType struct { Fields *FieldList // 字段列表 }
4. 实战示例
示例 1:提取所有函数名
func extractFunctions(node *ast.File) {
for _, decl := range node.Decls {
if fn, ok := decl.(*ast.FuncDecl); ok {
fmt.Println("Function:", fn.Name.Name)
}
}
}
示例 2:查找特定函数调用
func findPrintfCalls(node ast.Node) {
ast.Inspect(node, func(n ast.Node) bool {
if call, ok := n.(*ast.CallExpr); ok {
if ident, ok := call.Fun.(*ast.Ident); ok && ident.Name == "Printf" {
fmt.Printf("Found Printf at %v\n", fset.Position(n.Pos()))
}
}
return true
})
}
5. 高级技巧
修改 AST
使用 astutil 包进行代码修改:
// 重命名变量
newNode := astutil.Apply(node, func(cr *astutil.Cursor) bool {
if ident, ok := cr.Node().(*ast.Ident); ok && ident.Name == "oldVar" {
ident.Name = "newVar"
}
return true
}, nil)
类型检查
结合 go/types 包进行语义分析:
conf := types.Config{Importer: importer.Default()}
info := &types.Info{Types: make(map[ast.Expr]types.TypeAndValue)}
_, err := conf.Check("pkg", fset, []*ast.File{node}, info)
6. 常见问题
- 忽略注释:
parser.ParseFile需设置parser.ParseComments标志。 - 处理作用域:需手动跟踪变量作用域或依赖
go/types。 - 性能优化:避免在大型代码库中频繁解析,可缓存 AST。
7. 工具推荐
astview: 可视化 AST 结构的第三方工具golang.org/x/tools/go/analysis: 官方静态分析框架
通过掌握 ast 包,你可以构建自定义代码分析工具(如 Linter、自动重构工具),深入理解 Go 代码的内在逻辑结构。
Go 语言的 ast(抽象语法树)包在代码分析、生成和转换中有着广泛的应用。以下是一些典型应用场景、实现方法和实战示例:
1. 静态代码分析
场景
- 代码规范检查:检查命名规范、未使用的变量、错误的函数调用等。
- 安全扫描:检测 SQL 注入、硬编码密码等潜在漏洞。
- 依赖分析:统计包或函数的依赖关系。
示例:检测 fmt.Printf 未格式化参数
func CheckPrintfArgs(node *ast.File, fset *token.FileSet) {
ast.Inspect(node, func(n ast.Node) bool {
callExpr, ok := n.(*ast.CallExpr)
if !ok {
return true
}
// 检查是否为 fmt.Printf
if selExpr, ok := callExpr.Fun.(*ast.SelectorExpr); ok {
if pkgIdent, ok := selExpr.X.(*ast.Ident); ok && pkgIdent.Name == "fmt" {
if selExpr.Sel.Name == "Printf" {
// 检查第一个参数是否为格式化字符串
if len(callExpr.Args) == 0 {
pos := fset.Position(callExpr.Pos())
fmt.Printf("错误:%s 处缺少格式化参数\n", pos)
}
}
}
}
return true
})
}
2. 自动生成代码
场景
- 生成序列化/反序列化代码(如 JSON、Protobuf)。
- 生成 API 路由:根据注释自动生成 HTTP 路由。
- 实现依赖注入框架:自动解析结构体依赖。
示例:根据结构体生成 JSON 标签
// 为结构体字段自动添加 JSON 标签
func AddJSONTags(node *ast.File) {
for _, decl := range node.Decls {
genDecl, ok := decl.(*ast.GenDecl)
if !ok || genDecl.Tok != token.TYPE {
continue
}
for _, spec := range genDecl.Specs {
typeSpec, ok := spec.(*ast.TypeSpec)
if !ok {
continue
}
structType, ok := typeSpec.Type.(*ast.StructType)
if !ok {
continue
}
// 遍历结构体字段
for _, field := range structType.Fields.List {
if field.Tag == nil {
field.Tag = &ast.BasicLit{
Kind: token.STRING,
Value: fmt.Sprintf("`json:\"%s\"`", field.Names[0].Name),
}
}
}
}
}
}
3. 代码重构工具
场景
- 变量重命名:安全地替换变量名(避免误改字符串中的内容)。
- 函数提取:将重复代码片段提取为独立函数。
- 接口实现检查:验证结构体是否实现了某个接口。
示例:重命名变量
func RenameVariable(node ast.Node, oldName, newName string) ast.Node {
return astutil.Apply(node, func(cursor *astutil.Cursor) bool {
ident, ok := cursor.Node().(*ast.Ident)
if ok && ident.Name == oldName {
ident.Name = newName
}
return true
}, nil)
}
4. 依赖分析与可视化
场景
- 包依赖图:生成项目的包依赖关系图。
- 函数调用链:分析函数之间的调用关系。
示例:统计函数调用
type CallGraph map[string][]string
func BuildCallGraph(node *ast.File) CallGraph {
graph := make(CallGraph)
currentFunc := ""
ast.Inspect(node, func(n ast.Node) bool {
// 记录当前函数名
if fnDecl, ok := n.(*ast.FuncDecl); ok {
currentFunc = fnDecl.Name.Name
return true
}
// 记录函数调用
if callExpr, ok := n.(*ast.CallExpr); ok {
if ident, ok := callExpr.Fun.(*ast.Ident); ok {
if currentFunc != "" {
graph[currentFunc] = append(graph[currentFunc], ident.Name)
}
}
}
return true
})
return graph
}
5. 实现领域特定语言 (DSL)
场景
- 自定义配置解析:将特定格式的代码转换为配置结构。
- ORM 查询生成器:解析类似 SQL 的链式调用生成真实 SQL。
示例:解析路由定义
// 解析类似以下代码生成路由:
// Route("/user/:id", GetUser)
func ParseRoutes(node *ast.File) map[string]string {
routes := make(map[string]string)
ast.Inspect(node, func(n ast.Node) bool {
callExpr, ok := n.(*ast.CallExpr)
if !ok {
return true
}
// 检查是否为 Route 函数调用
if ident, ok := callExpr.Fun.(*ast.Ident); ok && ident.Name == "Route" {
if len(callExpr.Args) >= 2 {
path := evalStringLiteral(callExpr.Args[0]) // 解析字符串参数
handler := evalFuncName(callExpr.Args[1]) // 解析函数名
routes[path] = handler
}
}
return true
})
return routes
}
6. 结合类型检查(go/types)
场景
- 验证类型安全:检查接口实现、类型转换是否合法。
- 自动补全:为 IDE 提供类型推导支持。
示例:检查接口实现
func CheckInterfaceImpl(fset *token.FileSet, file *ast.File, ifaceName string) {
conf := types.Config{Importer: importer.Default()}
info := &types.Info{
Defs: make(map[*ast.Ident]types.Object),
Uses: make(map[*ast.Ident]types.Object),
}
// 类型检查
_, err := conf.Check("pkg", fset, []*ast.File{file}, info)
if err != nil {
log.Fatal(err)
}
// 遍历结构体,检查是否实现了接口
for _, decl := range file.Decls {
if genDecl, ok := decl.(*ast.GenDecl); ok && genDecl.Tok == token.TYPE {
for _, spec := range genDecl.Specs {
typeSpec := spec.(*ast.TypeSpec)
structType, ok := typeSpec.Type.(*ast.StructType)
if !ok {
continue
}
// 获取结构体类型
structObj := info.Defs[typeSpec.Name].(*types.TypeName)
iface := types.NewInterfaceType(nil, nil).Complete() // 需替换为实际接口
if types.Implements(structObj.Type(), iface) {
fmt.Printf("%s 实现了接口 %s\n", typeSpec.Name.Name, ifaceName)
}
}
}
}
}
7. 性能优化
场景
- 内联优化建议:识别高频调用的小函数,建议内联。
- 内存分配检查:检测不必要的堆内存分配(如返回局部变量指针)。
示例:检测返回局部变量指针
func CheckReturnLocalPointer(node *ast.File) {
ast.Inspect(node, func(n ast.Node) bool {
ret, ok := n.(*ast.ReturnStmt)
if !ok {
return true
}
for _, result := range ret.Results {
unary, ok := result.(*ast.UnaryExpr)
if !ok || unary.Op != token.AND {
continue
}
// 检查是否为局部变量地址
if ident, ok := unary.X.(*ast.Ident); ok {
fmt.Printf("警告:函数返回局部变量 %s 的指针\n", ident.Name)
}
}
return true
})
}
关键工具与库
go/ast:核心 AST 解析库。go/parser:解析源代码生成 AST。go/token:处理代码位置信息。golang.org/x/tools/go/ast/astutil:提供 AST 修改工具。golang.org/x/tools/go/loader:加载完整的包信息。- jennifer-生成ast库
go/printer把ast的node保存为go源代码文件
注意事项
- 作用域处理:AST 不包含作用域信息,需结合
go/types。 - 注释处理:需在
parser.ParseFile时启用ParseComments标志。 - 性能问题:大规模代码库的 AST 遍历可能较慢,需优化遍历逻辑。
通过灵活使用 ast 包,开发者可以构建强大的代码分析、生成和重构工具,深入理解代码的静态结构和逻辑。
ast解析
一、核心概念(基础接口与核心类型)
go/ast 包用于表示 Go 源代码的抽象语法树(AST),是静态分析、代码生成的基础。核心概念可分为“基础接口”和“核心节点类型”两类,所有节点均围绕树形结构组织,File 为 AST 根节点(代表单个 Go 源文件)。
- 基础接口(所有节点的根基)
- Node:顶层接口,所有 AST 节点均实现,提供
Pos()(起始位置)、End()(结束位置)方法,是遍历的基础。 - Expr:继承 Node,标识所有表达式节点(如
a+b、fmt.Println()),无额外方法。 - Stmt:继承 Node,标识所有语句节点(如赋值、if、for、return)。
- Decl:继承 Node,标识所有声明节点(如 var/const/type 声明、函数声明)。
- Spec:继承 Node,标识声明规范节点,是 GenDecl 的 Specs 字段元素类型,核心实现有 ValueSpec(var/const 声明项)、TypeSpec(type 声明项)。
- ExprStmt:继承 Stmt,标识表达式语句(即单独作为语句的表达式,如
fmt.Println()、a++)。
- 核心节点类型(AST 的核心组成)
- AssignStmt:赋值语句(如
sum := a + b)。 - BinaryExpr:二元表达式(如
a + b)。 - CallExpr:函数调用(如
fmt.Println())。 - ReturnStmt:return 语句(如
return sum)。 - BlockStmt:代码块(花括号包裹的语句集合)。
- UnaryExpr:一元表达式(如
!ok、a++、&x),关键字段:Op(操作符)、X(操作数,Expr)。 - SelExpr:选择表达式(如
fmt.Println),前文已详述。 - ExprStmt:表达式语句(如单独一行的
fmt.Println()),前文已详述。 - File:AST 根节点,代表单个 Go 文件。关键字段:
Name(包名,Ident 类型)、Decls(所有声明)、Imports(导入列表)。 - Ident:标识符(变量名、函数名、包名等)。关键字段:
Name(名称字符串)。示例:代码中的a、add、fmt。 - BasicLit:字面量(静态常量值)。关键字段:
Kind(类型,如 INT/STRING)、Value(值字符串)。示例:10、"fmt"、true。 - GenDecl:通用声明(var/const/type)。关键字段:
Tok(声明类型,如 VAR)、Specs(具体声明项,[]Spec 类型)。 - FuncDecl:函数/方法声明。关键字段:
Name(函数名)、Type(函数签名,FuncType 类型)、Body(函数体,BlockStmt 类型)、Recv(接收者,方法特有)。 - FuncType:函数签名,包含
Params(参数列表)、Results(返回值列表),均为 FieldList 类型。 - FieldList:字段/参数列表,关键字段
List([]*Field),用于函数参数、结构体字段等场景。 - ValueSpec:var/const 声明项,实现 Spec 接口。关键字段:
Names(变量/常量名列表,[]*Ident)、Type(类型,可选)、Values(初始值列表,[]Expr)。示例:var x int = 10中的x对应 ValueSpec。 - TypeSpec:type 声明项,实现 Spec 接口。关键字段:
Name(类型名,*Ident)、Type(底层类型,Expr)。示例:type User struct{}中的User对应 TypeSpec。 - StructType:结构体类型,实现 Expr 接口。关键字段:
Fields(结构体字段列表,*FieldList)。示例:struct{ Name string; Age int }。 - InterfaceType:接口类型,实现 Expr 接口。关键字段:
Methods(接口方法列表,*FieldList)。示例:interface{ GetName() string }。 - SelectorExpr:选择表达式,实现 Expr 接口,用于访问结构体/接口成员或包的导出成员。关键字段:
X(接收者/包名,Expr)、Sel(成员名,*Ident)。示例:fmt.Println、u.Name。 - IfStmt:if 语句,实现 Stmt 接口。关键字段:
Cond(条件表达式,Expr)、Body(if 体,*BlockStmt)、Else(else 体,Stmt,可选)。示例:if a > 0 { ... } else { ... }。 - ForStmt:for 语句,实现 Stmt 接口。关键字段:
Init(初始化语句,Stmt)、Cond(条件表达式,Expr)、Post(后置语句,Stmt)、Body(循环体,*BlockStmt)。支持普通 for(for i:=0;i<10;i++)、无限 for(for{})、range for(for k,v:=range arr)。 - RangeStmt:range 循环语句,实现 Stmt 接口(go/ast 中单独划分,非 ForStmt 子类)。关键字段:
Key(键变量,Expr)、Value(值变量,Expr)、X(遍历对象,Expr)、Body(循环体,*BlockStmt)。示例:for k, v := range arr { ... }。 - SwitchStmt:switch 语句,实现 Stmt 接口。关键字段:
Tag(判断表达式,Expr)、Body(switch 体,*BlockStmt)、CaseList(case 列表,[]*CaseClause)。 - CaseClause:case 子句,实现 Stmt 接口,是 SwitchStmt/TypeSwitchStmt 的 CaseList 字段元素。关键字段:
List(case 表达式列表,[]Expr)、Body(case 体,[]Stmt)。
- 辅助类型
- CommentGroup:一组注释(关联到节点,如函数注释、包注释)。
- ImportSpec:单个导入声明(如
import "fmt")。
二、示例解析(代码 ↔ AST 节点对应)
- 示例代码(demo.go)
// 包注释
package main
import "fmt"
// 计算两数之和
func add(a, b int) int {
sum := a + b
fmt.Println("sum =", sum)
return sum
}
func main() {
result := add(10, 20)
println(result)
}
- 代码与 AST 节点对应表
| 代码片段 | 对应 AST 核心类型 | 关键说明 |
|---|---|---|
package main | File + Ident | File.Name 为值为 main 的 Ident |
import "fmt" | ImportSpec | 属于 File.Imports 列表元素 |
// 计算两数之和 | CommentGroup | 关联到 FuncDecl.Doc |
func add(a, b int) int | FuncDecl + FuncType + FieldList | FuncType 包含参数 (a,b int) 和返回值 (int),由 FieldList 描述 |
sum := a + b | AssignStmt + BinaryExpr | 右侧 a+b 是 BinaryExpr(操作符 +) |
fmt.Println(...) | CallExpr + SelectorExpr | fmt.Println 是 SelectorExpr(访问包成员) |
10, 20 | BasicLit | Kind 为 INT,Value 为 “10”、“20” |
return sum | ReturnStmt + Ident | 参数为 sum(Ident) |
- 简单 AST 解析代码(可运行)
通过 go/parser 解析代码为 AST,实现 ast.Visitor 遍历节点,输出关键信息:
package main
import (
"fmt"
"go/ast"
"go/parser"
"go/token"
"os"
)
type visitor struct{}
func (v *visitor) Visit(node ast.Node) ast.Visitor {
if node == nil {
return nil
}
switch n := node.(type) {
case *ast.File:
fmt.Printf("[File] 包名: %s\n", n.Name.Name)
case *ast.ImportSpec:
fmt.Printf("[ImportSpec] 导入路径: %s\n", n.Path.Value)
case *ast.FuncDecl:
fmt.Printf("[FuncDecl] 函数名: %s\n", n.Name.Name)
if n.Type.Params != nil {
fmt.Printf(" [参数列表]: ")
for _, f := range n.Type.Params.List {
for _, name := range f.Names {
fmt.Printf("%s ", name.Name)
}
if ident, ok := f.Type.(*ast.Ident); ok {
fmt.Printf("(%s) ", ident.Name)
}
}
fmt.Println()
}
case *ast.AssignStmt:
fmt.Printf("[AssignStmt] 赋值变量: ")
for _, lhs := range n.Lhs {
if ident, ok := lhs.(*ast.Ident); ok {
fmt.Printf("%s ", ident.Name)
}
}
fmt.Println()
case *ast.BinaryExpr:
if x, ok := n.X.(*ast.Ident); ok && y, ok2 := n.Y.(*ast.Ident); ok2 {
fmt.Printf("[BinaryExpr] 表达式: %s %s %s\n", x.Name, n.Op, y.Name)
}
case *ast.BasicLit:
fmt.Printf("[BasicLit] 字面量: %s (类型: %s)\n", n.Value, n.Kind)
case *ast.CallExpr:
if sel, ok := n.Fun.(*ast.SelectorExpr); ok {
pkg := sel.X.(*ast.Ident).Name
method := sel.Sel.Name
fmt.Printf("[CallExpr] 调用: %s.%s()\n", pkg, method)
} else if ident, ok := n.Fun.(*ast.Ident); ok {
fmt.Printf("[CallExpr] 调用: %s()\n", ident.Name)
}
}
return v
}
func main() {
fset := token.NewFileSet()
file, err := parser.ParseFile(fset, "demo.go", nil, parser.AllErrors)
if err != nil {
fmt.Printf("解析错误: %v\n", err)
os.Exit(1)
}
fmt.Println("=== AST 遍历结果 ===")
ast.Walk(&visitor{}, file)
}
- 运行输出(关键片段)
=== AST 遍历结果 ===
[File] 包名: main
[ImportSpec] 导入路径: "fmt"
[FuncDecl] 函数名: add
[参数列表]: a b (int)
[AssignStmt] 赋值变量: sum
[BinaryExpr] 表达式: a + b
[CallExpr] 调用: fmt.Println()
[FuncDecl] 函数名: main
[AssignStmt] 赋值变量: result
[BasicLit] 字面量: 10 (类型: INT)
[BasicLit] 字面量: 20 (类型: INT)
[CallExpr] 调用: println()
三、核心总结
- AST 结构:以 File 为根,所有代码拆解为 Decl(声明)、Stmt(语句)、Expr(表达式)三级节点。
- 原子节点:Ident(标识符)和 BasicLit(字面量)是构成 AST 的最小单元。
- 核心用法:通过实现 ast.Visitor 接口的 Visit 方法遍历节点,实现代码分析、生成等功能。
bnf
在 Go 语言中,虽然没有直接支持 BNF(巴科斯-诺尔范式)的标准库,但有一些第三方库可以帮助你实现基于 BNF 的语法解析和生成式开发。以下是几个常用的 Go 库:
1. gocc
-
简介:
gocc是一个用于生成词法分析器和语法分析器的工具,支持 BNF 风格的语法定义。 -
特点:
- 支持 LALR(1) 语法。
- 自动生成词法分析器和语法分析器。
- 生成的代码性能高。
-
使用步骤:
- 定义 BNF 语法文件(
.bnf文件)。 - 使用
gocc生成解析器代码。 - 在 Go 项目中使用生成的解析器。
- 定义 BNF 语法文件(
-
示例:
// calc.bnf !whitespace : ' ' | '\t' | '\n' | '\r' ; Expression : Term | Expression "+" Term | Expression "-" Term ; Term : Factor | Term "*" Factor | Term "/" Factor ; Factor : NUMBER | "(" Expression ")" ; NUMBER : "0" | "1" | "2" | "3" | "4" | "5" | "6" | "7" | "8" | "9" ;生成解析器:
gocc calc.bnf
2. participle
-
简介:
participle是一个强大的解析库,支持通过结构体标签定义语法规则。 -
特点:
- 无需生成代码,直接使用 Go 结构体定义语法。
- 支持递归语法和复杂规则。
- 易于集成到现有项目中。
-
示例:
package main import ( "fmt" "github.com/alecthomas/participle/v2" ) type Expression struct { Left *Term `parser:"@@"` Right []*OpTerm `parser:"@@*"` } type OpTerm struct { Op string `parser:"@('+' | '-')"` Term *Term `parser:"@@"` } type Term struct { Left *Factor `parser:"@@"` Right []*OpFactor `parser:"@@*"` } type OpFactor struct { Op string `parser:"@('*' | '/')"` Factor *Factor `parser:"@@"` } type Factor struct { Number *int `parser:"@Int"` Expr *Expression `parser:"| '(' @@ ')'"` } func main() { parser, err := participle.Build[Expression]() if err != nil { panic(err) } expr := &Expression{} err = parser.ParseString("", "3 + 5 * (2 - 8)", expr) if err != nil { panic(err) } fmt.Printf("%+v\n", expr) }
3. go-yacc
- 简介:
go-yacc是 Go 语言的一个 Yacc 实现,用于生成 LALR(1) 语法分析器。 - 特点:
- 类似于传统的 Yacc/Bison 工具。
- 支持 BNF 风格的语法定义。
- 示例:
- 定义语法文件(
.y文件)。 - 使用
go-yacc生成解析器。 - 在 Go 项目中使用生成的解析器。
- 定义语法文件(
4. golang.org/x/tools/cmd/goyacc
- 简介:这是 Go 官方工具链中的 Yacc 实现,用于生成语法分析器。
- 特点:
- 与 Go 语言紧密集成。
- 支持 BNF 风格的语法定义。
- 示例:
- 定义语法文件(
.y文件)。 - 使用
goyacc生成解析器。 - 在 Go 项目中使用生成的解析器。
- 定义语法文件(
5. peg
- 简介:
peg是一个基于 PEG(Parsing Expression Grammar)的解析器生成工具。 - 特点:
- 支持 PEG 语法,类似于 BNF。
- 生成高效的解析器。
- 示例:
- 定义 PEG 语法文件(
.peg文件)。 - 使用
peg生成解析器。 - 在 Go 项目中使用生成的解析器。
- 定义 PEG 语法文件(
6. go-ebnf
-
简介:
go-ebnf是一个用于解析 EBNF(扩展巴科斯-诺尔范式)的库。 -
特点:
- 支持 EBNF 语法。
- 可以用于解析和验证语法规则。
-
示例:
package main import ( "fmt" "github.com/alecthomas/go-ebnf" ) func main() { grammar := ` Expression = Term , { ("+" | "-") , Term } ; Term = Factor , { ("*" | "/") , Factor } ; Factor = NUMBER | "(" , Expression , ")" ; NUMBER = ? [0-9]+ ? ; ` ast, err := ebnf.Parse("", []byte(grammar)) if err != nil { panic(err) } fmt.Printf("%+v\n", ast) }
总结
- 如果你需要生成词法分析器和语法分析器,推荐使用
gocc或go-yacc。 - 如果你希望直接在 Go 代码中定义语法规则,推荐使用
participle。 - 如果你需要解析 EBNF 语法,可以使用
go-ebnf。
根据你的需求选择合适的工具,可以高效地实现基于 BNF 的生成式开发。
build
参数
-n 不执行地打印流程中用到的命令 -x 执行并打印流程中用到的命令,要注意下它与-n选项的区别 -work 打印编译时的临时目录路径,并在结束时保留。默认情况下,编译结束会删除该临时目录。
code
更丰富的errors
import (
"fmt"
"github.com/pkg/errors"
)
func main() {
//%+v格式输出,则带上栈调用,调试好帮手
fmt.Printf("err:%+v", errors.New("mynew"))
}
memcached
package main
import (
"fmt"
//连接memcached
"github.com/bradfitz/gomemcache/memcache"
)
func main() {
key := "/golang"
client := memcache.New("127.0.0.1:11211")
err := client.Set(&memcache.Item{
Key: key,
Flags: 0,
Expiration: 0,
Value: []byte("<HTML><H2>hello,golang</H2></HTML>"),
})
if err != nil {
fmt.Println(err.Error())
return
}
item, err2 := client.Get(key)
if err2 != nil {
fmt.Println(err2.Error())
return
}
fmt.Println(string(item.Value))
}
redis
package main
import (
"fmt"
//连接redis
"github.com/gomodule/redigo/redis"
)
func main() {
conn, err := redis.Dial("tcp", ":6379")
if err != nil {
fmt.Println(err.Error())
return
}
defer conn.Close()
setReply, setReplyErr := redis.String(conn.Do("set", "firstKey", "firstValue"))
if setReplyErr != nil {
fmt.Println(setReplyErr.Error())
return
}
fmt.Println("setReply:", setReply, reflect.TypeOf(setReply))
mgetReplay, mgetReplyErr := redis.Strings(conn.Do("mget", "firstKey", "k1"))
if mgetReplyErr != nil {
fmt.Println(mgetReplyErr.Error())
return
}
fmt.Println("mgetReplay:", mgetReplay, reflect.TypeOf(mgetReplay))
hgetallReply, hgetallReplyErr := redis.StringMap(conn.Do("hgetall", "myhash"))
if hgetallReplyErr != nil {
fmt.Println(hgetallReplyErr.Error())
return
}
fmt.Println("hgetallReply:", hgetallReply, reflect.ValueOf(hgetallReply))
lrangeReply, lrangeReplyErr := redis.Strings(conn.Do("lrange", "mylist", "0", "-1"))
if lrangeReplyErr != nil {
fmt.Println(lrangeReplyErr.Error())
return
}
fmt.Println("lrangeReply:", lrangeReply, reflect.ValueOf(lrangeReply))
smembersReply, smembersReplyErr := redis.Strings(conn.Do("smembers", "myset"))
if smembersReplyErr != nil {
fmt.Println(smembersReplyErr.Error())
return
}
fmt.Println("smembersReply:", smembersReply, reflect.TypeOf(smembersReply))
zrangeReply, zrangeReplyErr := redis.Int64Map(conn.Do("zrange", "mySortedSet", "0", "-1", "withscores"))
if zrangeReplyErr != nil {
fmt.Println(zrangeReplyErr.Error())
return
}
fmt.Println("zrangeReply:", zrangeReply, reflect.TypeOf(zrangeReply))
}

mongodb
package main
import (
"context"
"fmt"
"reflect"
"time"
//连接mongodb
"go.mongodb.org/mongo-driver/bson"
"go.mongodb.org/mongo-driver/mongo"
"go.mongodb.org/mongo-driver/mongo/options"
)
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 20*time.Second)
defer cancel()
client, err := mongo.Connect(ctx, options.Client().ApplyURI("mongodb://localhost:27017"))
if err != nil {
fmt.Println("connect:", err.Error())
return
}
defer client.Disconnect(ctx)
// database,collection不存在,会自动创建,不必事先创建
col := client.Database("firstDB").Collection("firstCol")
reply, err := col.InsertOne(ctx, bson.D{{"name", "pai"}, {"value", 3.14159}})
if err != nil {
fmt.Println("list:", err.Error())
return
}
fmt.Println(reflect.ValueOf(reply))
}
package main
import (
"context"
"database/sql"
"fmt"
"log"
_ "github.com/go-sql-driver/mysql"
)
func main() {
// user:pass@tcp(127.0.0.1:3306)/dbname?charset=utf8mb4&parseTime=True&loc=Local
db, err := sql.Open("mysql", "root:@(127.0.0.1:3306)/mytest?charset=utf8mb4&parseTime=True&loc=Local")
if err != nil {
fmt.Println(err.Error())
return
}
defer db.Close()
ctx, stop := context.WithCancel(context.Background())
defer stop()
rows, err := db.QueryContext(ctx, "SELECT v FROM js")
if err != nil {
log.Fatal(err)
}
defer rows.Close()
names := make([]string, 0)
for rows.Next() {
var name string
if err := rows.Scan(&name); err != nil {
log.Fatal(err)
}
names = append(names, name)
}
// Check for errors from iterating over rows.
if err := rows.Err(); err != nil {
log.Fatal(err)
}
fmt.Println(names)
}
//获取当前git的hash值
gitOut, gitErr := exec.Command("bash", "-c", "git rev-parse --short HEAD").Output()
if gitErr != nil {
fmt.Println(gitErr)
return
}
trace
package main
import (
"os"
"runtime/trace"
)
func main() {
trace.Start(os.Stderr)
defer trace.Stop()
ch := make(chan string)
go func() {
ch <- "hello,world"
}()
<-ch
}
#注意2>trace.out重定向,产生数据文件
go run main.go 2>trace.out
#pprof,trace有些需要graphviz
brew install graphviz
#采用trace工具分析显示数据,
go tool trace trace.out

strings.TrimLeft去掉连续的字符,strings.TrimPerfix只去掉一次
profile
import (
"github.com/pkg/profile"
_ "net/http/pprof"
)
// go http.ListenAndServe("0.0.0.0:8080", nil)
func main() {
// p.Stop() must be called before the program exits to
// ensure profiling information is written to disk.
p := profile.Start(profile.MemProfile, profile.ProfilePath("."), profile.NoShutdownHook)
...
// You can enable different kinds of memory profiling, either Heap or Allocs where Heap
// profiling is the default with profile.MemProfile.
p := profile.Start(profile.MemProfileAllocs, profile.ProfilePath("."), profile.NoShutdownHook)
// 采用web接口提供 http://localhost:8080/debug/profile
go http.ListenAndServe("0.0.0.0:8080", nil)
}
# 等上步生成的的cpu.profile
go tool pprof cpu.profile
# 常见命令 top,前几个费时 web 输出临时svg图片展示
context
未完待续
classDiagram
class Context{
<< interface >>
+Deadline() (deadline time.Time, ok bool)
+Done()
+Err() error
+Value(key any) any
}
Context <|.. emptyCtx
Context <|-- valueCtx
class valueCtx{
+Context
~key any
~val any
}
class canceler{
<< interface >>
~cancel(removeFromParent bool, err error)
+Done()
}
canceler <|.. cancelCtx
Context <|-- cancelCtx
class cancelCtx{
+Context
}
cancelCtx <|-- timerCtx
class timerCtx{
+timer *time.Timer
+deadline time.Time
}
echo
memcached中间件
import (
"bytes"
"net/http"
"sync"
"github.com/bradfitz/gomemcache/memcache"
"github.com/labstack/echo/v4"
)
var memcacheClientMux sync.Mutex
var memcacheClient *memcache.Client
// TODO,要不要带上http头部,例如:数据类型html/json/js,Date,Cache-control等等
type middleResp struct {
http.ResponseWriter
isOK bool
key string
expiration int32
bytes.Buffer
}
var StoreErrHandler func(error)
func (mr *middleResp) writeStore() {
if mr.Buffer.Len() > 0 {
err := memcacheClient.Set(&memcache.Item{
Key: mr.key,
Flags: 0,
Expiration: mr.expiration,
Value: mr.Bytes(),
})
if StoreErrHandler != nil {
StoreErrHandler(err)
}
}
}
func (mr *middleResp) Write(body []byte) (int, error) {
if mr.isOK && memcacheClient != nil {
_, err := mr.Buffer.Write(body)
if StoreErrHandler != nil {
StoreErrHandler(err)
}
}
return mr.ResponseWriter.Write(body)
}
func (mr *middleResp) WriteHeader(statusCode int) {
mr.isOK = statusCode == http.StatusOK
mr.ResponseWriter.WriteHeader(statusCode)
}
func MemcacheStore(server string, expireSecond int32) func(echo.HandlerFunc) echo.HandlerFunc {
memcacheClientMux.Lock()
defer memcacheClientMux.Unlock()
if memcacheClient == nil {
memcacheClient = memcache.New(server)
}
return func(next echo.HandlerFunc) echo.HandlerFunc {
return func(c echo.Context) error {
resp := c.Response()
mr := &middleResp{
ResponseWriter: resp.Writer,
key: c.Request().RequestURI,
expiration: expireSecond,
}
resp.Writer = mr
err := next(c)
mr.writeStore()
return err
}
}
}
func MemcacheWrap(server string, expireSecond int32, handler echo.HandlerFunc) echo.HandlerFunc {
return MemcacheStore(server, expireSecond)(handler)
}
main使用
package main
import (
"fmt"
"math/rand"
"net/http"
"github.com/labstack/echo/v4"
"github.com/labstack/echo/v4/middleware"
)
func main() {
e := echo.New()
// Middleware
e.Use(middleware.Logger())
e.Use(middleware.Recover())
StoreErrHandler = func(err error) {
e.Logger.Error(err)
}
// Routes
e.GET("/echo/string", stringHandler, MemcacheStore("127.0.0.1:11211", 60))
e.GET("/echo/html", MemcacheWrap("127.0.0.1:11211", 60, htmlHandler))
// Start server
e.Logger.Fatal(e.Start(":1323"))
}
// Handler
func stringHandler(c echo.Context) error {
err := c.String(http.StatusOK, fmt.Sprintf("<H1>path:%s</H1>", c.Path()))
if err != nil {
return err
}
return c.String(http.StatusOK, fmt.Sprintf(
"<H2>query:%s,rand:%d</H2>",
c.QueryString(),
rand.Int(),
))
}
// Handler
func htmlHandler(c echo.Context) error {
err := c.HTML(http.StatusOK, fmt.Sprintf("<H1>uri:%s</H1>", c.Request().RequestURI))
if err != nil {
return err
}
return c.HTML(http.StatusOK, fmt.Sprintf(
"<H2>query:%s,rand:%d</H2>",
c.QueryString(),
rand.Int(),
))
}
nginx转发
...
location /echo {
set $memcached_key "$request_uri";
memcached_pass 127.0.0.1:11211;
#指示返回为html,方便浏览器直接显示
default_type text/html;
error_page 404 502 504 = @echoServer;
}
location @echoServer {
proxy_pass http://127.0.0.1:1323;
}
...
embed
在 Go 语言中,embed 是一个用于将静态文件(如文本文件、图片、HTML 模板等)直接嵌入到 Go 二进制文件中的功能。这个功能是通过 Go 1.16 版本引入的 embed 包实现的。通过 embed,开发者可以将外部资源文件与 Go 代码一起编译,生成一个独立的可执行文件,从而简化部署和分发。
以下是对 Go 语言中 embed 功能的详细介绍:
1. 基本用法
embed 功能通过 //go:embed 指令来实现。它可以嵌入单个文件、多个文件或整个目录。
1.1 嵌入单个文件
假设我们有一个文本文件 hello.txt,内容如下:
Hello, World!
我们可以通过以下方式将其嵌入到 Go 程序中:
package main
import (
_ "embed"
"fmt"
)
//go:embed hello.txt
var s string
func main() {
fmt.Println(s) // 输出: Hello, World!
}
//go:embed hello.txt:表示将hello.txt文件的内容嵌入到变量s中。s是一个字符串类型的变量,它会包含文件的内容。
1.2 嵌入二进制文件
如果文件是二进制文件(如图片),可以使用 []byte 类型来嵌入:
package main
import (
_ "embed"
"fmt"
)
//go:embed logo.png
var logo []byte
func main() {
fmt.Println("Logo size:", len(logo), "bytes")
}
1.3 嵌入多个文件
可以使用切片来嵌入多个文件:
package main
import (
_ "embed"
"fmt"
)
//go:embed file1.txt file2.txt
var files []byte
func main() {
fmt.Println(string(files)) // 输出 file1.txt 和 file2.txt 的内容
}
1.4 嵌入整个目录
可以嵌入整个目录及其子目录中的所有文件:
package main
import (
"embed"
"fmt"
)
//go:embed static/*
var staticFiles embed.FS
func main() {
data, _ := staticFiles.ReadFile("static/hello.txt")
fmt.Println(string(data)) // 输出 static/hello.txt 的内容
}
embed.FS是一个文件系统类型,可以用于访问嵌入的文件。staticFiles.ReadFile("static/hello.txt")用于读取嵌入的文件内容。
2. embed.FS 文件系统
embed.FS 是一个实现了 io/fs.FS 接口的文件系统类型,可以像操作普通文件系统一样操作嵌入的文件。
2.1 遍历嵌入的文件
package main
import (
"embed"
"fmt"
"io/fs"
)
//go:embed static/*
var staticFiles embed.FS
func main() {
fs.WalkDir(staticFiles, ".", func(path string, d fs.DirEntry, err error) error {
if err != nil {
return err
}
fmt.Println(path) // 输出嵌入的文件路径
return nil
})
}
2.2 读取嵌入的文件
package main
import (
"embed"
"fmt"
)
//go:embed static/*
var staticFiles embed.FS
func main() {
data, _ := staticFiles.ReadFile("static/hello.txt")
fmt.Println(string(data)) // 输出 static/hello.txt 的内容
}
3. 使用场景
embed 功能在以下场景中非常有用:
- 静态资源嵌入:将 HTML、CSS、JavaScript 等前端资源嵌入到 Go 二进制文件中,方便部署。
- 配置文件嵌入:将配置文件嵌入到程序中,避免外部依赖。
- 模板文件嵌入:将 HTML 模板或其他模板文件嵌入到程序中。
- 二进制资源嵌入:将图片、字体等二进制文件嵌入到程序中。
4. 注意事项
-
路径问题:
//go:embed指令中的路径是相对于 Go 源文件的路径。- 嵌入目录时,路径必须以
*结尾(如static/*)。
-
文件修改:
- 嵌入的文件在编译时被固定,运行时无法修改。
-
文件大小:
- 嵌入的文件会增加二进制文件的大小,因此不适合嵌入非常大的文件。
-
安全性:
- 嵌入的文件是只读的,无法在运行时修改或删除。
5. 示例:嵌入 HTML 模板
以下是一个将 HTML 模板嵌入到 Go 程序中的示例:
package main
import (
"embed"
"html/template"
"net/http"
)
//go:embed templates/*
var templates embed.FS
func main() {
tmpl := template.Must(template.ParseFS(templates, "templates/*.html"))
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
tmpl.ExecuteTemplate(w, "index.html", nil)
})
http.ListenAndServe(":8080", nil)
}
templates/*嵌入了一个包含 HTML 模板的目录。template.ParseFS用于从嵌入的文件系统中解析模板。
6. 总结
embed 是 Go 语言中一个非常实用的功能,能够将静态文件直接嵌入到 Go 二进制文件中,从而简化部署和分发。通过 //go:embed 指令和 embed.FS 文件系统,开发者可以轻松地访问和操作嵌入的文件。无论是嵌入配置文件、静态资源还是模板文件,embed 都能显著提高开发效率和程序的可移植性。
freetype
package main
import (
"fmt"
"image"
"image/draw"
"image/png"
"os"
"github.com/golang/freetype"
)
func DrawText(text string) {
data, err := ioutil.ReadFile("/System/Library/Fonts/STHeiti Medium.ttc")
if err != nil {
panic(err)
}
f, err := freetype.ParseFont(data)
if err != nil {
panic(err)
}
dst := image.NewRGBA(image.Rect(0, 0, 800, 600))
draw.Draw(dst, dst.Bounds(), image.White, image.Point{}, draw.Src)
c := freetype.NewContext()
c.SetDst(dst)
c.SetClip(dst.Bounds())
c.SetSrc(image.Black)
c.SetFont(f)
fontSize := float64(50)
// 字体越大, 显示越大
c.SetFontSize(fontSize)
// Pt是控制起点,Pt{x,y},x表示左起点,y表示下起点,y-fontSize才是上起点
_, err = c.DrawString(text, freetype.Pt(0, int(fontSize)))
if err != nil {
panic(err)
}
pngFile, err := os.Create("draw.png")
if err != nil {
panic(err)
}
defer pngFile.Close()
err = png.Encode(pngFile, dst)
if err != nil {
panic(err)
}
}
func main() {
DrawText("中国人golang语言教程ABC122")
}
泛型
示例
// go 1.18+
package main
import (
"fmt"
)
type SubType interface {
int | string | float32
}
// func Sub[T int | string | float32](array []T, ele T) []T {
func Sub[T SubType](array []T, ele T) []T {
res := make([]T, 0, len(array))
for _, a := range array {
if a == ele {
continue
}
res = append(res, a)
}
return res
}
func main() {
fmt.Println(Sub([]string{"a", "b", "c", "b"}, "b"))
fmt.Println(Sub([]int{10, 20, 30, 10}, 10))
}
在软件开发中,自动生成代码可以显著提高开发效率,减少重复劳动。以下是一些常用的工具和框架,能够自动生成 Go 代码:
1. Protocol Buffers (protobuf)
-
用途:用于定义数据结构并生成序列化代码。
-
工具:
protoc+protoc-gen-go插件。 -
示例:
protoc --go_out=. --go_opt=paths=source_relative your_proto_file.proto -
生成内容:根据
.proto文件生成 Go 结构体和序列化代码。
2. gRPC
-
用途:用于生成 RPC 服务的客户端和服务器端代码。
-
工具:
protoc+protoc-gen-go-grpc插件。 -
示例:
protoc --go-grpc_out=. --go-grpc_opt=paths=source_relative your_proto_file.proto -
生成内容:生成 gRPC 服务的接口和实现代码。
3. Swagger/OpenAPI
-
用途:用于生成 RESTful API 的客户端和服务器端代码。
-
工具:
- oapi-codegen:根据 OpenAPI 规范生成 Go 代码。
- swagger-codegen:生成多种语言的客户端和服务端代码。
-
示例:
oapi-codegen -generate types,server -package myapi myapi.yaml > myapi.gen.go -
生成内容:生成 API 的类型定义、路由和处理函数。
4. SQLBoiler
-
用途:根据数据库表结构生成 Go 模型和 CRUD 代码。
-
工具:
sqlboiler。 -
示例:
sqlboiler psql -
生成内容:生成与数据库表对应的 Go 模型、查询和操作方法。
5. GORM
-
用途:用于生成 ORM 模型代码。
-
工具:
gorm+gorm-gen。 -
示例:
gorm-gen -dsn "user:password@tcp(127.0.0.1:3306)/dbname" -outPath ./models -
生成内容:生成数据库表对应的 ORM 模型代码。
6. Wire
-
用途:用于生成依赖注入代码。
-
工具:
wire。 -
示例:
wire gen ./... -
生成内容:生成依赖注入的初始化代码。
7. Mockery
-
用途:用于生成接口的 Mock 实现。
-
工具:
mockery。 -
示例:
mockery --name=MyInterface --output=mocks -
生成内容:生成接口的 Mock 实现,用于单元测试。
8. Go Generate
-
用途:用于自定义代码生成。
-
工具:
go generate。 -
示例: 在 Go 文件中添加:
//go:generate stringer -type=MyEnum然后运行:
go generate ./... -
生成内容:根据自定义规则生成代码(如枚举的字符串表示)。
9. Ent
-
用途:用于生成实体模型和 CRUD 代码。
-
工具:
ent。 -
示例:
go run entgo.io/ent/cmd/ent generate ./ent/schema -
生成内容:生成实体模型、查询和操作方法。
10. Cobra
-
用途:用于生成命令行应用程序的框架代码。
-
工具:
cobra-cli。 -
示例:
cobra-cli init myapp cobra-cli add mycommand -
生成内容:生成命令行应用程序的框架代码和子命令。
11. Goa
-
用途:用于生成微服务框架代码。
-
工具:
goa。 -
示例:
goa gen myapp/design -
生成内容:生成微服务的 API 定义、路由和处理函数。
12. Gunk
-
用途:用于生成 gRPC 和 RESTful API 代码。
-
工具:
gunk。 -
示例:
gunk generate ./... -
生成内容:生成 gRPC 和 RESTful API 的代码。
13. Go Kit
-
用途:用于生成微服务框架代码。
-
工具:
go-kit。 -
示例:
go-kit addsvc -gen -
生成内容:生成微服务的框架代码。
14. Go-Fuzz
-
用途:用于生成模糊测试代码。
-
工具:
go-fuzz。 -
示例:
go-fuzz-build -o=fuzz.zip . -
生成内容:生成模糊测试的代码。
15. GoReleaser
-
用途:用于生成发布流程的配置文件。
-
工具:
goreleaser。 -
示例:
goreleaser init -
生成内容:生成
.goreleaser.yml配置文件。
总结
以上工具涵盖了从数据结构定义、API 生成、数据库操作到测试和发布的各个方面。根据具体需求选择合适的工具,可以显著提高 Go 开发的效率和质量。
gin
context中断原理
const abortIndex int8 = math.MaxInt8 / 2
// Abort prevents pending handlers from being called. Note that this will not stop the current handler.
// Let's say you have an authorization middleware that validates that the current request is authorized.
// If the authorization fails (ex: the password does not match), call Abort to ensure the remaining handlers
// for this request are not called.
func (c *Context) Abort() {
// c.index赋值很大值,从导致下次Next都不执行,达到阻断执行链目的
c.index = abortIndex
}
// Next should be used only inside middleware.
// It executes the pending handlers in the chain inside the calling handler.
// See example in GitHub.
func (c *Context) Next() {
c.index++
for c.index < int8(len(c.handlers)) {
c.handlers[c.index](c)
c.index++
}
}
memcache中间件
import (
"bytes"
"net/http"
"sync"
"github.com/bradfitz/gomemcache/memcache"
"github.com/gin-gonic/gin"
)
var memcacheClientMux sync.Mutex
var memcacheClient *memcache.Client
// TODO,要不要带上http头部,例如:数据类型html/json/js,Date,Cache-control等等
type middleResp struct {
// 匿名包括,变相继承
gin.ResponseWriter
isOK bool
key string
expiration int32
// 如果匿名包括,变相继承会和ResponseWriter冲突,导致接口重复写
b bytes.Buffer
}
var StoreErrHandler func(error)
func (mr *middleResp) writeStore() {
if mr.b.Len() > 0 {
err := memcacheClient.Set(&memcache.Item{
Key: mr.key,
Flags: 0,
Expiration: mr.expiration,
Value: mr.b.Bytes(),
})
if StoreErrHandler != nil {
StoreErrHandler(err)
}
}
}
func (mr *middleResp) Write(body []byte) (int, error) {
if mr.isOK && memcacheClient != nil {
_, err := mr.b.Write(body)
if StoreErrHandler != nil {
StoreErrHandler(err)
}
}
return mr.ResponseWriter.Write(body)
}
func (mr *middleResp) WriteHeader(statusCode int) {
mr.isOK = statusCode == http.StatusOK
mr.ResponseWriter.WriteHeader(statusCode)
}
// Writes the string into the response body.
func (mr *middleResp) WriteString(s string) (int, error) {
return mr.ResponseWriter.WriteString(s)
}
func MemcacheStore(server string, expireSecond int32) gin.HandlerFunc {
return MemcacheWrap(server, expireSecond, func(c *gin.Context) { c.Next() })
}
func MemcacheWrap(server string, expireSecond int32, handler gin.HandlerFunc) gin.HandlerFunc {
memcacheClientMux.Lock()
defer memcacheClientMux.Unlock()
if memcacheClient == nil {
memcacheClient = memcache.New(server)
}
return func(c *gin.Context) {
mr := &middleResp{
ResponseWriter: c.Writer,
key: c.Request.RequestURI,
expiration: expireSecond,
}
c.Writer = mr
handler(c)
mr.writeStore()
}
}
main使用
import (
"fmt"
"math/rand"
"github.com/gin-gonic/gin"
)
func main() {
r := gin.Default()
r.Use(gin.Logger())
r.GET("/gin/wrap", MemcacheWrap("127.0.0.1:11211", 100, wrap))
group := r.Group("/gin/group")
group.Use(MemcacheStore("127.0.0.1:11211", 100))
group.GET("/ping", func(c *gin.Context) {
c.JSON(200, gin.H{
"message": "pong",
})
})
group.GET("/gin", func(c *gin.Context) {
c.Data(200, "text/html",
[]byte(fmt.Sprintf("<H1>gin,%v</H1>", rand.Int())),
)
})
r.Run("0.0.0.0:5050")
}
func wrap(c *gin.Context) {
c.Data(200, "text/html",
[]byte(fmt.Sprintf("<H1>warp,%v</H1>", rand.Int())),
)
}
go-git
package main
import(
"fmt"
"github.com/go-git/go-git/v5"
"github.com/go-git/go-git/v5/plumbing/object"
)
func gitWork() {
r, err := git.PlainOpen("../wubei/wubei")
if err != nil {
fmt.Println(err)
return
}
fmt.Println("r", r)
// ... retrieves the branch pointed by HEAD
ref, err := r.Head()
if err != nil {
fmt.Println(err)
return
}
fmt.Println("ref", ref)
// ... retrieves the commit history
cIter, err := r.Log(&git.LogOptions{From: ref.Hash()})
if err != nil {
fmt.Println(err)
return
}
var cCount int
err = cIter.ForEach(func(c *object.Commit) error {
cCount++
fmt.Println("Author", c.Author)
fmt.Println("Message", c.Message)
return nil
})
if err != nil {
fmt.Println(err)
return
}
fmt.Println("cCount", cCount)
}
go-tool
golang.org/x/tools/go 是 Go 语言生态中一个功能强大的工具包集合,主要用于代码分析、静态检查、抽象语法树(AST)操作、包加载和代码生成等场景。以下是该包中核心子模块的详细说明及用法示例,结合了相关搜索结果的实践建议和背景知识:
1. go/packages:包加载与依赖分析
功能:动态加载项目的包信息,包括源码、依赖关系和类型信息,适用于构建工具或静态分析工具。
核心用法:
import "golang.org/x/tools/go/packages"
// 加载当前目录下的包
cfg := &packages.Config{Mode: packages.NeedName | packages.NeedFiles}
pkgs, err := packages.Load(cfg, ".")
if err != nil {
log.Fatal(err)
}
// 遍历包信息
for _, pkg := range pkgs {
fmt.Printf("包名: %s, 文件列表: %v\n", pkg.Name, pkg.GoFiles)
}
模式标志:
packages.NeedSyntax:获取 AST 语法树。packages.NeedTypes:获取类型信息。packages.NeedDeps:加载所有依赖包。
应用场景:构建自定义 Linter、依赖可视化工具(如 go-callvis)。
2. go/analysis:静态分析框架
功能:提供统一的静态分析接口,支持编写插件化的代码检查工具(如 staticcheck 和 go vet)。
核心用法:
import (
"golang.org/x/tools/go/analysis"
"golang.org/x/tools/go/analysis/singlechecker"
)
// 定义一个分析器:检测未处理的错误
var Analyzer = &analysis.Analyzer{
Name: "errcheck",
Doc: "检查未处理的错误返回",
Run: run,
}
func run(pass *analysis.Pass) (interface{}, error) {
// 遍历 AST,检查是否存在未处理的错误
for _, file := range pass.Files {
// 实现具体检查逻辑
}
return nil, nil
}
func main() {
singlechecker.Main(Analyzer) // 编译为独立工具
}
集成工具:通过 go vet -vettool=$(which custom_analyzer) 调用自定义分析器。
3. go/ssa:静态单赋值形式(SSA)
功能:将 Go 代码转换为 SSA 中间表示,便于程序分析和优化。
示例:生成函数的 SSA 代码并分析控制流。
import (
"golang.org/x/tools/go/ssa"
"golang.org/x/tools/go/ssa/ssautil"
)
prog := ssautil.CreateProgram(pkgs, ssa.SanityCheckFunctions)
mainPkg := prog.Package(pkgs[0].Types)
mainPkg.Build() // 构建 SSA
// 遍历函数及其基本块
for _, mem := range mainPkg.Members {
if fn, ok := mem.(*ssa.Function); ok {
fmt.Printf("函数名: %s\n", fn.Name())
for _, b := range fn.Blocks {
fmt.Printf("基本块: %v\n", b)
}
}
}
应用场景:程序切片、数据流分析、死代码检测。
4. go/ast 和 go/parser:AST 解析
功能:解析源码生成 AST,支持代码重构和语法分析。
示例:解析文件并遍历 AST 节点。
import (
"go/parser"
"go/ast"
"go/token"
)
fset := token.NewFileSet()
node, err := parser.ParseFile(fset, "example.go", nil, parser.AllErrors)
if err != nil {
log.Fatal(err)
}
// 遍历 AST 查找函数声明
ast.Inspect(node, func(n ast.Node) bool {
if fn, ok := n.(*ast.FuncDecl); ok {
fmt.Printf("函数声明: %s\n", fn.Name.Name)
}
return true
})
应用场景:代码格式化工具(如 goimports)、自动生成代码。
5. go/callgraph:调用图分析
功能:生成函数调用图,用于理解代码执行路径。
示例:
import "golang.org/x/tools/go/callgraph"
prog := ... // 通过 go/ssa 构建程序
cg := callgraph.New(prog)
callgraph.GraphVisitEdges(cg, func(edge *callgraph.Edge) error {
fmt.Printf("调用路径: %s -> %s\n", edge.Caller.Func.Name(), edge.Callee.Func.Name())
return nil
})
应用场景:性能分析、依赖解耦。
6. go/gcexportdata:导出数据解析
功能:读取编译后的 .a 文件中的类型信息,支持跨包分析。
示例:
import "golang.org/x/tools/go/gcexportdata"
// 从文件读取导出数据
f, _ := os.Open("fmt.a")
pkg, err := gcexportdata.Read(f, token.NewFileSet(), make(map[string]*types.Package), "fmt")
if err != nil {
log.Fatal(err)
}
fmt.Printf("包名: %s\n", pkg.Name())
安装与配置
-
安装方式:
go get -u golang.org/x/tools/go/analysis/passes/... # 安装所有分析器若因网络问题无法直接安装,可手动克隆仓库到
$GOPATH/src/golang.org/x/tools。 -
工具链集成:
go vet支持调用自定义分析器。golangci-lint聚合了多种基于go/analysis的检查工具。
总结
golang.org/x/tools/go 是 Go 生态中代码分析和工具开发的核心库,覆盖从 AST 解析到静态检查的完整流程。开发者可通过其构建 Linter、代码生成工具或性能分析器,结合 go/packages 和 go/analysis 可大幅提升工具的专业性和效率。更多实践案例可参考官方文档或社区工具(如 staticcheck 和 golangci-lint)。
泛型切片分组
group
func GroupBy[T any, U comparable](collection []T, iteratee func(T) U) map[U][]T {
result := map[U][]T{}
for _, item := range collection {
key := iteratee(item)
result[key] = append(result[key], item)
}
return result
}
grpc示例
server
| 工具 | 介绍 |
|---|---|
| protobuf protocol | buffer 编译所需的命令行 |
| protoc-gen-go | 从 proto 文件,生成 .go 文件 |
| protoc-gen-go-grpc | 从 proto 文件,生成 GRPC 相关的 .go 文件 |
| protoc-gen-grpc-gateway | 从 proto 文件,生成 grpc-gateway 相关的 .go 文件 |
| protoc-gen-openapiv2 | 从 proto 文件,生成 swagger 界面所需的参数 |
package main
import (
"context"
"flag"
"fmt"
"log"
"net"
"google.golang.org/grpc"
"google.golang.org/grpc/metadata"
"google.golang.org/grpc/peer"
com "xxx.site/myself/grpc-common"
)
var (
GitHash = "Unkown"
CompileTime = "Unkown"
port = flag.Int("port", 8411, "默认端口")
)
// 定义服务端中间件
func middleware(ctx context.Context, req interface{},
info *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (resp interface{}, err error) {
log.Printf("middleware ctx:%v", ctx)
log.Printf("middleware req:%v", req)
log.Printf("middleware info:%v", info)
log.Printf("middleware handler:%v", handler)
resp, err = handler(ctx, req)
log.Printf("middleware resp:%v", resp)
log.Printf("middleware err:%v", err)
return
}
type MathServer struct {
com.UnimplementedMathServer
}
// 各种信息都通过ctx中valueCtx传递进来
// 由不同包获取转换
func (ms *MathServer) Add(ctx context.Context, req *com.AddReq) (*com.AddRsp, error) {
log.Printf("ctx:%v, req:%v", ctx, req)
if client, ok := peer.FromContext(ctx); ok {
log.Printf("client:%v", client)
}
if ic, ok := metadata.FromIncomingContext(ctx); ok {
log.Printf("ic:%v", ic)
}
if oc, ok := metadata.FromOutgoingContext(ctx); ok {
log.Printf("oc:%v", oc)
}
if oc, ok := metadata.FromOutgoingContext(ctx); ok {
log.Printf("oc:%v", oc)
}
sts := grpc.ServerTransportStreamFromContext(ctx)
log.Printf("sts:%v", sts)
return &com.AddRsp{
Result: req.Left + req.Right,
}, nil
}
func main() {
flag.Parse()
// ct, err := credentials.NewServerTLSFromFile(
// "grpc.xxx.site.pem",
// "grpc.xxx.site.key",
// )
// if err != nil {
// log.Fatalf("tls file;%v", err)
// }
// tcp表示优先使用ipv6,其次ipv4,两者都能用
l, err := net.Listen("tcp", fmt.Sprintf(":%d", *port))
if err != nil {
log.Fatalf("fail listen tcp %d", *port)
}
// 安装中间件
s := grpc.NewServer(
// 默认没有采用安全传输ssl,tls
// 增加证书认证
//grpc.Creds(ct),
grpc.UnaryInterceptor(middleware),
)
com.RegisterMathServer(s, &MathServer{})
log.Printf(
"githash:%v, compile:%v,listen:%v",
GitHash,
CompileTime,
l.Addr())
err = s.Serve(l)
if err != nil {
log.Fatalf("fail server:%v", err)
}
}
client
package main
import (
"context"
"flag"
"log"
"time"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/insecure"
com "xxx.site/myself/grpc-common"
)
var (
GitHash = "unknown"
CompileTime = "unknown"
// addr = flag.String("addr", "dns:///grpc.xxx.site", "默认服务端端口")
addr = flag.String("addr", "127.0.0.1:8411", "默认服务端端口")
)
// 定义客户端中间件
func middleware(ctx context.Context, method string,
req, reply interface{}, c *grpc.ClientConn, invoker grpc.UnaryInvoker, opts ...grpc.CallOption) error {
log.Printf("middleware ctx:%v", ctx)
log.Printf("middleware method:%v", method)
log.Printf("middleware req:%v", req)
log.Printf("middleware reply:%v", reply)
log.Printf("middleware conn:%v", c)
log.Printf("middleware invoker:%v", invoker)
for pos, opt := range opts {
log.Printf("middleware pos:%v, opt:%v", pos, opt)
}
err := invoker(ctx, method, req, reply, c, opts...)
log.Printf("middleware err:%v", err)
return err
}
func main() {
flag.Parse()
// ct, err := credentials.NewClientTLSFromFile("grpc.xxx.site.pem", "grpc.xxx.site")
// if err != nil {
// log.Fatalf("err:%v", err)
// }
conn, err := grpc.Dial(
*addr,
// 采用禁用安全传输,即没有ssl/tls
grpc.WithTransportCredentials(insecure.NewCredentials()),
// 采用证书,注意跨平台,linux amd64/apple m1芯片之间可能不能通讯
// grpc.WithTransportCredentials(ct),
// 安装中间件
grpc.WithUnaryInterceptor(middleware),
grpc.WithTimeout(time.Minute),
)
if err != nil {
log.Fatalf("dial:%v, %v", *addr, err)
}
defer conn.Close()
client := com.NewMathClient(conn)
req := com.AddReq{
Left: 10,
Right: 20,
}
resp, err := client.Add(context.Background(), &req)
if err != nil {
log.Fatalf("add fail:%v", err)
}
log.Printf("resp:%v", resp.Result)
}
proto
- proto内容
syntax = "proto3";
option go_package = "./;common";
service Math {
rpc Add(AddReq)returns(AddRsp){}
}
message AddReq {
int64 left = 1;
int64 right = 2;
}
message AddRsp {
int64 result = 1;
}
- 生成脚本
#!/bin/bash
#--go-grpc_out表示启动protoc-gen-go-grpc插件
# --openapiv2_out 表示产生swagger.json
protoc --go_out=. --go-grpc_out=. *.proto
nginx
...
server_names_hash_bucket_size 64;
server {
listen 443 ssl http2;
server_name grpc.xxx.site;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2 TLSv1.3;
ssl_certificate grpc.xxx.site.pem;
ssl_certificate_key grpc.xxx.site.key;
ssl_session_cache shared:SSL:1m;
ssl_session_timeout 5m;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_prefer_server_ciphers on;
location / {
# grpc_pass localhost:9000; 等价于 grpc://127.0.0.1:8411 等价于 [::]:8411;
# To use gRPC over SSL,就要带上grpcs:
grpc_pass grpcs://[xxx]:8411;
client_max_body_size 200M;
}
}
...
扩展工具(https://buf.build/)
buf之于proto,类似go mod之于golang,它通过buf.yaml来声明一个proto的module,作为管理的最小单元,方便其它proto库引用,也可以用来声明对其它库的依赖,包括从远程仓库BSR(全称 Buf Schema Registry)拉取依赖的proto库。它同时提供了代码生成管理工具buf.gen.yaml方便我们指定protoc插件,以及对这些protoc插件的安装和管理,我们不用本地配置protoc工具和各种protoc插件,大大提升了开发效率。
- API 设计通常不一致
- 依赖管理通常是事后才想到的
- 不强制执行向前和向后兼容性
- proto文件分发是一个困难的、未解决的过程
- 工具生态系统是有限的
- 有很多附加工具及插件
io
基础
flowchart TB
subgraph 单接口
direction LR
r1(Reader)---w1(Writer)---c1(Closer)---s1(Seeker)
end
subgraph 双接口
direction LR
rw(ReadWriter)---rc(ReadCloser)---rs(ReadSeeker)---wc(WriteCloser)---ws(WriteSeeker)
end
subgraph 三接口
direction LR
rwc(ReadWriteCloser)---rsc(ReadSeekCloser)---rws(ReadWriteSeeker)
end
单接口 --组合--> 双接口 --组合--> 三接口
- Reader
type Reader interface {
// 读取len(p)字节到p里面
// 返回读取成功字节数
// eof表示正常结束
Read(p []byte) (n int, err error)
}
- Writer
type Writer interface {
// 写入p里面内容,len(p)字节
// 返回写入成功字节数
Write(p []byte) (n int, err error)
}
类型
flowchart TB
subgraph Byte
direction LR
br(ByteReader)---bw(ByteWriter)---bc(ByteScanner)
end
subgraph Rune
direction LR
rr(RuneReader)---rw(ByteWriter)---rc(ByteScanner)
end
subgraph String
direction LR
sw(StringWriter)
end
扩展
flowchart TB
subgraph 附加
direction LR
rf(ReaderFrom)---wt(WriterTo)---ra(ReaderAt)---wa(WriterAt)
end
subgraph 限制
direction LR
lr(LimitedReader)---sr(SectionReader)
end
subgraph 内部
direction LR
d(discard)---nc(nopCloser)---tr(teeReader镜像)
mr(multiReader串联)---mw(multiWriter广播)
pr(PipeReader就地读)--同个pipe,chan实现---pw(PipeWriter就地写)
end
便利函数
WriteString(w Writer, s string) (n int, err error)
ReadAll(r Reader) ([]byte, error)
ReadFull(r Reader, buf []byte) (n int, err error)
ReadAtLeast(r Reader, buf []byte, min int) (n int, err error)
CopyN(dst Writer, src Reader, n int64) (written int64, err error)
Copy(dst Writer, src Reader) (written int64, err error)
CopyBuffer(dst Writer, src Reader, buf []byte) (written int64, err error)
//扩展close接口
NopCloser(r Reader)ReadCloser
//把r读出来内容写一份到w,镜像r到w
TeeReader(r Reader, w Writer) Reader
//最多读n个字节,达到就返回eof
LimitReader(r Reader, n int64) Reader
//串联起多个源头,按顺序依次读完
MultiReader(readers ...Reader) Reader
//把w写入内容广播多个writers中
MultiWriter(writers ...Writer) Writer
//就地成双读写,通过chan []byte实现
Pipe() (*PipeReader, *PipeWriter)
// 切片扩容
if len(b) == cap(b) {
// Add more capacity (let append pick how much).
b = append(b, 0)[:len(b)]
}
iris
context中断原理
// I don't set to a max value because we want to be able to reuse the handlers even if stopped with .Skip
const stopExecutionIndex = -1
// StopExecution if called then the following .Next calls are ignored,
// as a result the next handlers in the chain will not be fire.
func (ctx *context) StopExecution() {
ctx.currentHandlerIndex = stopExecutionIndex
}
// IsStopped checks and returns true if the current position of the context is -1,
// means that the StopExecution() was called.
func (ctx *context) IsStopped() bool {
return ctx.currentHandlerIndex == stopExecutionIndex
}
func DefaultNext(ctx Context) {
if ctx.IsStopped() {
return
}
if n, handlers := ctx.HandlerIndex(-1)+1, ctx.Handlers(); n < len(handlers) {
ctx.HandlerIndex(n)
handlers[n](ctx)
}
}
func (ctx *context) HandlerIndex(n int) (currentIndex int) {
if n < 0 || n > len(ctx.handlers)-1 {
return ctx.currentHandlerIndex
}
ctx.currentHandlerIndex = n
return n
}
memcache中间件
import (
"bytes"
"net/http"
"sync"
"github.com/bradfitz/gomemcache/memcache"
"github.com/kataras/iris/v12/context"
)
var memcacheClientMux sync.Mutex
var memcacheClient *memcache.Client
// TODO,要不要带上http头部,例如:数据类型html/json/js,Date,Cache-control等等
type middleResp struct {
// 匿名包括,变相继承
http.ResponseWriter
isOK bool
key string
expiration int32
// 如果匿名包括,变相继承会和ResponseWriter冲突,导致接口重复写
b bytes.Buffer
}
var StoreErrHandler func(error)
func (mr *middleResp) writeStore() {
if mr.b.Len() > 0 {
err := memcacheClient.Set(&memcache.Item{
Key: mr.key,
Flags: 0,
Expiration: mr.expiration,
Value: mr.b.Bytes(),
})
if StoreErrHandler != nil {
StoreErrHandler(err)
}
}
}
func (mr *middleResp) Write(body []byte) (int, error) {
if mr.isOK && memcacheClient != nil {
_, err := mr.b.Write(body)
if StoreErrHandler != nil {
StoreErrHandler(err)
}
}
return mr.ResponseWriter.Write(body)
}
func (mr *middleResp) WriteHeader(statusCode int) {
mr.isOK = statusCode == http.StatusOK
mr.ResponseWriter.WriteHeader(statusCode)
}
func MemcacheStore(server string, expireSecond int32) context.Handler {
return MemcacheWrap(server, expireSecond, func(c context.Context) { c.Next() })
}
func MemcacheWrap(server string, expireSecond int32, handler context.Handler) context.Handler {
memcacheClientMux.Lock()
defer memcacheClientMux.Unlock()
if memcacheClient == nil {
memcacheClient = memcache.New(server)
}
return func(c context.Context) {
mr := &middleResp{
ResponseWriter: c.ResponseWriter().Naive(),
key: c.Request().RequestURI,
expiration: expireSecond,
}
c.ResponseWriter().BeginResponse(mr)
handler(c)
mr.writeStore()
}
}
main使用
import (
"math/rand"
"github.com/kataras/iris/v12"
"github.com/kataras/iris/v12/middleware/recover"
)
func main() {
app := iris.New()
booksAPI := app.Party(
"/iris/books",
recover.New(),
MemcacheStore("127.0.0.1:11211", 60),
)
{
booksAPI.Get("/", list)
}
app.Get("/iris/other", MemcacheWrap("127.0.0.1:11211", 60, other))
app.Listen(":9090")
}
func other(ctx iris.Context) {
ctx.HTML(
"<H1>%s, %v</H1>",
ctx.Request().RequestURI,
rand.Int(),
)
}
// Book example.
type Book struct {
Title string `json:"title"`
}
func list(ctx iris.Context) {
books := []Book{
{"Mastering Concurrency in Go"},
{"Go Design Patterns"},
{"Black Hat Go"},
}
// ctx.JSON(books)
ctx.HTML("%v", books)
// TIP: negotiate the response between server's prioritizes
// and client's requirements, instead of ctx.JSON:
// ctx.Negotiation().JSON().MsgPack().Protobuf()
// ctx.Negotiate(books)
}
jsontag
源代码
package main
import (
"flag"
"fmt"
"go/ast"
"go/parser"
"go/printer"
"go/token"
"os"
"strings"
)
func main() {
// 解析命令行参数
input := flag.String("input", "", "Go 源文件路径")
output := flag.String("output", "", "输出文件路径(可选)")
flag.Parse()
if *input == "" {
fmt.Println("Usage: jsontagger -input file.go [-output file_generated.go]")
os.Exit(1)
}
// 解析 Go 源文件
fset := token.NewFileSet()
node, err := parser.ParseFile(fset, *input, nil, parser.ParseComments)
if err != nil {
fmt.Printf("Error parsing file: %v\n", err)
os.Exit(1)
}
// 遍历 AST,修改结构体字段
ast.Inspect(node, func(n ast.Node) bool {
if structType, ok := n.(*ast.StructType); ok {
for _, field := range structType.Fields.List {
if field.Names != nil {
fieldName := field.Names[0].Name
// 添加 json 标签(跳过已有标签的字段)
if field.Tag == nil {
field.Tag = &ast.BasicLit{
Kind: token.STRING,
Value: fmt.Sprintf("`json:\"%s\"`", strings.ToLower(fieldName)),
}
}
}
}
}
return true
})
// 输出结果
var out *os.File
if *output != "" {
out, err = os.Create(*output)
if err != nil {
fmt.Printf("Error creating output file: %v\n", err)
os.Exit(1)
}
defer out.Close()
} else {
out = os.Stdout
}
// 使用 go/format 格式化代码
if err := printer.Fprint(out, fset, node); err != nil {
fmt.Printf("Error printing AST: %v\n", err)
os.Exit(1)
}
}
编译安装
go build -o $GOPATH/bin/jsontagger
应用(user.go)–生成前
//go:generate jsontagger -input user.go -output user.go
type User struct {
ID int
Name string
Age int
}
应用(user.go)–生成后
//go:generate jsontagger -input main.go -output main.go
type User struct {
ID int `json:"id"`
Name string `json:"name"`
Age int `json:"age"`
}
log
日志常用示例
package main
import (
"fmt"
"io"
"io/ioutil"
"runtime"
"strings"
"time"
rotatelogs "github.com/lestrrat-go/file-rotatelogs"
"github.com/rifflock/lfshook"
"github.com/sirupsen/logrus"
)
func NewWriter(perfix string) io.Writer {
w, err := rotatelogs.New(
perfix+".%Y%m%d.json",
// 建立软接
rotatelogs.WithLinkName(perfix),
// 最多保存一星期
rotatelogs.WithMaxAge(7*24*time.Hour),
// 一天切割一次
rotatelogs.WithRotationTime(24*time.Hour),
)
if err != nil {
panic(err)
}
return w
}
func InitLog(perfix string) {
wm := lfshook.WriterMap{
logrus.DebugLevel: NewWriter(perfix + "_debug"),
logrus.InfoLevel: NewWriter(perfix + "_info"),
logrus.WarnLevel: NewWriter(perfix + "_warn"),
logrus.ErrorLevel: NewWriter(perfix + "_error"),
logrus.FatalLevel: NewWriter(perfix + "_fatal"),
}
logrus.AddHook(lfshook.NewHook(
wm,
&logrus.JSONFormatter{
CallerPrettyfier: func(f *runtime.Frame) (string, string) {
var callerName, fileName string
names := strings.SplitAfterN(f.File, perfix, 2)
if len(names) > 1 {
fileName = fmt.Sprintf("%v;%v", names[1], f.Line)
}
names = strings.SplitAfterN(f.Function, perfix, 2)
if len(names) > 1 {
callerName = names[1]
} else {
callerName = f.Function
}
return callerName, fileName
},
PrettyPrint: true,
},
))
logrus.SetOutput(ioutil.Discard)
logrus.SetReportCaller(true)
logrus.SetLevel(logrus.InfoLevel)
logrus.WithFields(logrus.Fields{
"perfix": perfix,
"level": logrus.GetLevel(),
}).Warn("日志初始化完成")
}
常用包
-
- chromedp是一个更快、更简单的Golang库用于调用支持Chrome DevTools协议的浏览器,同时不需要额外的依赖(例如Selenium和PhantomJS)
- Chrome DevTools其实就是Chrome浏览器按下F12之后的控制终端
-
xlsx-另一个xlsx库,已知bug,列名不能互相包含,否则出错
检查代码中是否包括密码密钥之类gitleaks
git clone https://github.com/zricethezav/gitleaks.git
cd gitleaks
make build
# 主要可用在阻挡提交
# detect protect
gitleaks detect -s=. -r=out.json
检查代码中sql安全gokart
检查代码安全gosec
检查魔术常量检查go-mnd
获取手机号码归属地phone-location-service
exgexp包
- 正则语法
// 连续的汉字字母数字
var maxHanDigitAlphaReg = regexp.MustCompile(`[\p{Han}[:digit:][:alpha:]]+`)
// 单个汉字字母数字
var minHanDigitAlphaReg = regexp.MustCompile(`[\p{Han}[:digit:][:alpha:]]+?`)
shell
编译常用示例
#! /bin/bash
target=local
set -x #回显执行命令
GOPATH=$(go env GOPATH)
GITVERSION=$(git describe --tags --always)
GITBRANCH=$(git symbolic-ref -q --short HEAD)
DATETIME=$(date "+%Y-%m-%d_%H:%M:%S")
HOSTNAME=$(hostname)
golangci-lint run --timeout=1h
revive -formatter friendly ./...
rm -rf ${target}*
go build -o ${target} -ldflags "-w -s -X main.GitHash=${GITVERSION}-${GITBRANCH} -X main.CompileTime=${DATETIME} -X main.HostName=${HOSTNAME}" .
./${target}
性能调优
win下载graphviz
go tool pprof cpu.profile
# 产生svg图示
svg
help
top10
list xxx
sort包
classDiagram
Interface <|-- IntSlice : 实现
Interface <|-- Float64Slice : 实现
Interface <|-- StringSlice : 实现
class Interface{
+Len() int
+Less(i, j int) bool
+Swap(i, j int)
}
classDiagram Interface <|.. Sort : 依赖 Sort <|-- Ints : []int Sort <|-- Float64s : []float64 Sort <|-- Strings : []string Sort <|-- Slice : []其他类型
classDiagram Search <|-- SearchInts : []int Search <|-- SearchFloat64s : []float64 Search <|-- SearchStrings : []string
type Interface interface {
Len() int
Less(i, j int) bool
Swap(i, j int)
}
// 采用快排/堆排/插排组合
func Sort(data Interface)
func Ints(x []int)
func Float64s(x []float64)
func Strings(x []string)
//采用反射自动实现Swap(i, j int)
func Slice(x any, less func(i, j int) bool)
// 稳排采用分段插排+合并组合
func Stable(data Interface)
func SliceStable(x any, less func(i, j int) bool)
// 二分搜索有序序列
func Search(n int, f func(int) bool) int
func SearchInts(a []int, x int) int
func SearchFloat64s(a []float64, x float64) int
func SearchStrings(a []string, x string) int
// 通用排序函数(支持升序/降序)
func SortMapByValue[K comparable, V Ordered](m map[K]V, ascending bool) []struct {
Key K
Value V
} {
// 创建键值对切片
pairs := make([]struct {
Key K
Value V
}, 0, len(m))
for k, v := range m {
pairs = append(pairs, struct {
Key K
Value V
}{k, v})
}
// 定义排序逻辑
sort.Slice(pairs, func(i, j int) bool {
if ascending {
return pairs[i].Value < pairs[j].Value
}
return pairs[i].Value > pairs[j].Value
})
return pairs
}
// 定义有序类型约束
type Ordered interface {
~int | ~float64 | ~string | ~uint // 可扩展其他数值类型
}
stringer
官方自动生成string
- main.go内容
//go:generate stringer -type=Pill
type Pill int
const (
Placebo Pill = iota
Aspirin
Ibuprofen
Paracetamol
Acetaminophen = Paracetamol
)
- 执行命令
go generate
- 生成的pill_string.go内容
import "strconv"
// 这段防止generate之后,修改后没有再次generate,通过编译错误强制提示
func _() {
// An "invalid array index" compiler error signifies that the constant values have changed.
// Re-run the stringer command to generate them again.
var x [1]struct{}
_ = x[Placebo-0]
_ = x[Aspirin-1]
_ = x[Ibuprofen-2]
_ = x[Paracetamol-3]
}
const _Pill_name = "PlaceboAspirinIbuprofenParacetamol"
var _Pill_index = [...]uint8{0, 7, 14, 23, 34}
func (i Pill) String() string {
if i < 0 || i >= Pill(len(_Pill_index)-1) {
return "Pill(" + strconv.FormatInt(int64(i), 10) + ")"
}
return _Pill_name[_Pill_index[i]:_Pill_index[i+1]]
}
内存泄漏
内存泄漏在Go中表现为:进程的堆内存占用持续增长,即使在业务低峰期也不回落,最终可能导致OOM(内存溢出)。
一、未正确终止的Goroutine(最常见)
核心原因
Goroutine是Go中最主要的内存泄漏来源。只要Goroutine不退出,它占用的栈、堆内存,以及引用的所有变量都无法被GC回收。常见触发场景:
- Goroutine阻塞在
chan的接收/发送操作,且无其他协程唤醒; - Goroutine陷入死循环(无退出条件);
- Goroutine等待一个永远不会触发的锁/条件变量。
代码示例(chan阻塞导致泄漏)
// 错误示例:启动的goroutine阻塞在chan接收,且无发送方,永久无法退出
func leakGoroutine() {
ch := make(chan int)
// 启动协程后,ch永远没有发送方,协程一直阻塞,内存泄漏
go func() {
val := <-ch // 阻塞在此处,协程永不退出
fmt.Println("received:", val)
}()
// 函数返回后,ch无外部引用,但协程仍持有ch的引用,无法回收
}
func main() {
for i := 0; i < 10000; i++ {
leakGoroutine() // 循环调用,创建1万个泄漏的goroutine
}
// 阻塞主线程,观察内存占用
select {}
}
解决方案
- 使用带超时的chan操作:通过
context.WithTimeout或time.After设置超时,避免永久阻塞; - 显式关闭chan:确保发送方/接收方有退出逻辑;
- 使用context传递取消信号:强制终止协程。
修复后的代码
func fixedGoroutine(ctx context.Context) {
ch := make(chan int, 1) // 可选:用缓冲chan减少阻塞概率
go func() {
select {
case val := <-ch:
fmt.Println("received:", val)
case <-ctx.Done(): // 监听取消信号,触发时退出协程
fmt.Println("goroutine exit:", ctx.Err())
return
}
}()
// 业务逻辑:若无需发送,主动取消
ch <- 1 // 可选:发送数据
}
func main() {
ctx, cancel := context.WithCancel(context.Background())
defer cancel() // 函数退出时取消所有协程
for i := 0; i < 10000; i++ {
fixedGoroutine(ctx)
}
time.Sleep(1 * time.Second) // 等待协程退出
fmt.Println("all goroutines exited")
}
二、未停止的time.Ticker/未释放的time.Timer
核心原因
time.Ticker:创建后会启动一个后台协程,持续向C通道发送时间事件,若不调用Stop(),该协程永久运行,内存泄漏;time.Timer:若未触发(Reset)或未停止(Stop),且Timer对象被引用,会导致底层资源无法回收(注:未引用的Timer会被GC回收,但不推荐依赖此行为)。
代码示例(Ticker未Stop导致泄漏)
func leakTicker() {
// 创建Ticker,每100ms触发一次
ticker := time.NewTicker(100 * time.Millisecond)
// 仅读取一次,未调用Stop(),Ticker协程永久运行
<-ticker.C
fmt.Println("ticker once")
// 函数返回后,ticker未Stop,后台协程持续运行
}
func main() {
for i := 0; i < 100; i++ {
leakTicker() // 创建100个未停止的Ticker
}
select {}
}
解决方案
- Ticker必须显式Stop:在不再使用时调用
ticker.Stop(); - Timer使用后及时Stop/Reset:即使Timer已触发,也建议调用
Stop()(无副作用); - 结合context使用:通过context控制Ticker的生命周期。
修复后的代码
func fixedTicker(ctx context.Context) {
ticker := time.NewTicker(100 * time.Millisecond)
defer ticker.Stop() // 延迟调用Stop,确保函数退出时停止Ticker
go func() {
for {
select {
case <-ticker.C:
fmt.Println("ticker tick")
case <-ctx.Done():
return // 监听取消信号,退出协程
}
}
}()
}
三、全局集合(map/slice)无限增长
核心原因
全局的map、slice(或包级别的集合)若只添加元素、不删除/清理,会导致集合占用的内存持续增长,且集合引用的所有元素都无法被GC回收。
代码示例(全局map泄漏)
// 全局map,存储所有请求的日志,永不清理
var globalLogMap = make(map[string]interface{})
// 记录日志,但从不删除
func logRequest(id string, data interface{}) {
globalLogMap[id] = data // 只增不减,map无限膨胀
}
func main() {
// 模拟持续接收请求,向全局map添加数据
for i := 0; ; i++ {
id := fmt.Sprintf("req-%d", i)
// 每个请求存储1KB数据,持续占用内存
data := make([]byte, 1024)
logRequest(id, data)
time.Sleep(1 * time.Millisecond)
}
}
解决方案
- 设置过期策略:定期清理过期元素(如用
time.Ticker定时删除); - 使用带容量限制的集合:当集合大小超过阈值时,触发清理(如LRU缓存);
- 避免全局集合:尽量将集合的生命周期限制在函数/请求内;
- 使用第三方缓存库:如
github.com/hashicorp/golang-lru(LRU缓存),自动淘汰过期数据。
修复后的代码
import (
"sync"
"time"
)
type ExpirableMap struct {
mu sync.RWMutex
data map[string]item
ticker *time.Ticker
}
type item struct {
value interface{}
expireAt time.Time
}
// 初始化带过期清理的map
func NewExpirableMap(cleanupInterval time.Duration) *ExpirableMap {
m := &ExpirableMap{
data: make(map[string]item),
ticker: time.NewTicker(cleanupInterval),
}
// 启动清理协程
go m.cleanup()
return m
}
// 清理过期元素
func (m *ExpirableMap) cleanup() {
for range m.ticker.C {
m.mu.Lock()
now := time.Now()
for id, item := range m.data {
if now.After(item.expireAt) {
delete(m.data, id) // 删除过期元素
}
}
m.mu.Unlock()
}
}
// 添加元素,设置1分钟过期
func (m *ExpirableMap) Set(id string, value interface{}) {
m.mu.Lock()
defer m.mu.Unlock()
m.data[id] = item{
value: value,
expireAt: time.Now().Add(1 * time.Minute),
}
}
// 全局实例
var globalLogMap = NewExpirableMap(30 * time.Second)
四、切片截取导致的底层数组泄漏
核心原因
切片的底层是数组,当你从一个大切片截取一个小切片时,小切片会引用整个底层大数组。即使大切片无其他引用,只要小切片存在,整个大数组就无法被GC回收,导致内存泄漏。
代码示例
func leakSlice() []int {
// 创建一个100MB的大切片(100*1024*1024个int,每个int8字节)
bigSlice := make([]int, 100*1024*1024)
// 截取最后1个元素,返回小切片
smallSlice := bigSlice[len(bigSlice)-1:]
// 函数返回后,bigSlice被销毁,但smallSlice引用底层大数组,100MB内存泄漏
return smallSlice
}
func main() {
// 保存小切片,导致大数组无法回收
leakySlice := leakSlice()
fmt.Println("leaky slice len:", len(leakySlice))
select {}
}
解决方案
- 复制切片:使用
copy创建新切片,切断对原底层数组的引用; - 显式置空原切片:若无需保留原切片,手动将其置为
nil(加速GC)。
修复后的代码
func fixedSlice() []int {
bigSlice := make([]int, 100*1024*1024)
smallSlice := make([]int, 1)
// 复制最后1个元素到新切片,新切片的底层数组仅1个元素
copy(smallSlice, bigSlice[len(bigSlice)-1:])
bigSlice = nil // 显式置空,帮助GC回收大数组
return smallSlice
}
五、闭包引用导致的变量无法回收
核心原因
闭包会捕获外部变量的引用,若闭包的生命周期远长于外部变量的预期生命周期,会导致外部变量(及引用的资源)无法被GC回收。
代码示例
func leakClosure() func() {
// 大对象,预期仅在函数内使用
bigData := make([]byte, 100*1024*1024)
// 闭包引用bigData,即使函数返回,bigData也无法被回收
return func() {
fmt.Println("len of bigData:", len(bigData)) // 仅引用,无实际用途
}
}
func main() {
// 保存闭包,导致bigData持续占用100MB内存
f := leakClosure()
// 即使不调用f,bigData也无法回收
time.Sleep(10 * time.Second)
f() // 调用闭包
select {}
}
解决方案
- 避免闭包引用不必要的大变量:仅引用需要的字段,而非整个大对象;
- 复制变量到闭包内:切断对外部大变量的引用;
- 显式置空引用:在闭包使用完后,将引用置为
nil。
修复后的代码
func fixedClosure() func() {
bigData := make([]byte, 100*1024*1024)
// 复制需要的值到闭包内,不引用整个bigData
dataLen := len(bigData)
// 闭包仅引用dataLen,bigData可被GC回收
return func() {
fmt.Println("len of bigData:", dataLen)
}
}
六、sync.Pool使用不当
核心原因
sync.Pool是Go提供的对象池,用于复用临时对象、减少GC压力,但使用不当会导致泄漏:
- 向Pool中存入大对象/长生命周期对象:Pool的回收策略由GC控制,若对象过大,会导致Pool占用大量内存;
- 依赖Pool存储关键数据:Pool中的对象可能被GC随时清理,但若错误地将Pool作为持久存储,会导致逻辑错误+内存泄漏。
解决方案
- 仅用Pool存储临时、高频创建的小对象(如临时缓冲区、请求上下文);
- 不要存储长生命周期对象:Pool适合“创建成本高、使用频率高”的临时对象;
- 设置对象池的大小限制:自定义Pool的
New函数,避免无限制创建对象。
七、外部资源未关闭
核心原因
Go的GC仅回收内存,不会自动关闭文件句柄、网络连接、数据库连接等外部资源。若这些资源未关闭:
- 操作系统会为每个资源分配文件描述符(FD),FD耗尽会导致进程无法创建新连接/文件;
- 部分资源(如数据库连接)会占用内存,未关闭会导致内存泄漏。
常见未关闭的资源
- 文件/目录:
os.Open/os.Create后未调用Close(); - 网络连接:
net.Dial/http.Client请求后未关闭响应体(resp.Body.Close()); - 数据库连接:未关闭
sql.DB/redis.Client的连接; - 管道/锁:
os/exec的Cmd未关闭Stdout/Stderr。
代码示例(HTTP响应体未关闭)
func leakHTTP() {
resp, err := http.Get("https://example.com")
if err != nil {
fmt.Println(err)
return
}
// 错误:未关闭resp.Body,导致连接/内存泄漏
body, _ := io.ReadAll(resp.Body)
fmt.Println("body len:", len(body))
}
解决方案
- 使用defer关闭资源:遵循“打开即延迟关闭”原则;
- 检查所有分支:确保错误分支也关闭资源;
- 使用
context控制资源生命周期:超时自动关闭资源。
修复后的代码
func fixedHTTP() {
resp, err := http.Get("https://example.com")
if err != nil {
fmt.Println(err)
return
}
defer resp.Body.Close() // 延迟关闭响应体,确保所有分支都执行
body, _ := io.ReadAll(resp.Body)
fmt.Println("body len:", len(body))
}
如何检测Go内存泄漏?
除了代码审查,还可以通过工具快速定位:
-
pprof:Go内置的性能分析工具,通过
go tool pprof分析堆内存(-inuse_space)和goroutine数量;# 启动程序时开启pprof go run main.go -pprof=:6060 # 访问http://localhost:6060/debug/pprof/,查看heap/goroutine/profile -
trace:分析goroutine的生命周期,定位阻塞的goroutine;
-
第三方工具:如
gops(查看进程状态)、go-torch(火焰图)。
总结
- 最核心泄漏源:未终止的Goroutine(尤其是chan阻塞),需通过
context/超时机制确保协程可退出; - 高频场景:未Stop的
time.Ticker、全局集合无限增长、切片截取导致的底层数组泄漏; - 通用避坑原则:
- 所有资源(文件、连接、Ticker)遵循“打开即延迟关闭”;
- 避免全局集合只增不减,设置过期/容量限制;
- 协程必须有明确的退出条件(context/超时/chan关闭)。
oom
Go服务器发生OOM(内存溢出)时的完整排查方向,包括可能的根因、具体排查方法和对应的解决方案,从代码、运行时、系统三个层面定位并解决OOM问题。
OOM的本质是:Go进程占用的内存超过系统/容器的内存限制(如cgroup),或超出物理内存+交换分区总和,被操作系统的OOM Killer强制终止。排查需遵循「先确认现象→再分层定位→最后针对性解决」的思路,以下是核心排查维度:
一、先确认OOM的核心特征(快速定位方向)
首先通过系统日志和监控确认OOM类型,避免盲目排查:
# 1. 查看系统OOM Killer日志(最关键)
dmesg | grep -i oom
# 典型日志示例(说明进程因内存超限被杀死):
# Out of memory: Killed process 12345 (app) total-vm:8192000kB, anon-rss:4096000kB, file-rss:0kB
# 2. 查看Go进程的内存监控(持续增长=泄漏;瞬间冲高=峰值过高)
# 结合pprof/监控平台看内存趋势:
# - 内存持续上涨不回落 → 内存泄漏
# - 内存随QPS冲高后直接OOM → 峰值过高
二、核心排查维度(按优先级排序)
维度1:内存泄漏(最常见,服务器长期运行必现)
内存泄漏表现为堆内存占用随时间持续增长,即使低峰期也不回落,最终触发OOM。核心原因和排查方案如下:
| 具体原因 | 排查方法 | 解决方案 |
|---|---|---|
| 未终止的Goroutine | 1. go tool pprof http://localhost:6060/debug/pprof/goroutine 看协程数;2. 查看阻塞的协程(如chan接收/发送、锁等待) | 1. 所有协程通过context传递取消信号;2. 协程操作加超时( time.After);3. 用worker pool限制协程数 |
| 全局集合(map/slice)无限增长 | 1. pprof堆分析(-inuse_space)看大对象归属;2. 检查全局变量的内存占比 | 1. 给集合加过期策略(LRU缓存); 2. 定时清理无效数据; 3. 避免全局集合存储大对象 |
| 切片截取导致底层数组泄漏 | pprof看切片的底层数组大小(如小切片引用GB级数组) | 1. 使用copy创建新切片;2. 显式置空原大切片( bigSlice = nil) |
| 外部资源未关闭(连接/文件) | 1. lsof -p <pid> 看未关闭的文件/连接;2. 检查数据库/HTTP连接池状态 | 1. 所有资源defer Close();2. 调整连接池大小(如 max_idle_conns);3. 关闭HTTP响应体( resp.Body.Close()) |
维度2:内存峰值过高(瞬间超限,高并发/大请求触发)
内存泄漏是“慢死”,峰值过高是“猝死”——进程内存瞬间超过限制,GC来不及回收,直接OOM。
核心原因
-
大对象一次性加载:
- 示例:服务器一次性从数据库加载100万条数据到内存、读取大文件(GB级)到[]byte;
- 排查:pprof的
alloc_space(看总分配量)、trace工具看内存分配峰值; - 解决:分批处理数据(分页查询)、流式读取(
io.Reader逐行处理)、使用sync.Pool复用大对象。
-
并发请求叠加内存占用:
- 示例:每个请求分配10MB切片,QPS=1000时瞬间占用10GB内存;
- 排查:监控QPS和内存的关联曲线、限制并发数后观察内存变化;
- 解决:设置请求并发上限(如网关层限流)、使用worker pool控制协程数、复用请求级临时对象。
-
临时对象爆炸:
- 示例:高并发下JSON序列化/反序列化产生大量临时对象、反射创建大量对象;
- 排查:pprof看
runtime.mallocgc的调用栈、统计序列化耗时/内存; - 解决:复用JSON编码器(
json.Encoder)、避免反射(预编译结构体)、使用高性能序列化库(如easyjson)。
维度3:GC配置/行为异常(内存回收不及时)
Go的GC是自动的,但配置或行为异常会导致内存堆积,最终OOM:
核心原因
-
GOGC配置过高:
- 默认
GOGC=100(堆内存增长100%触发GC),高负载下堆内存来不及回收,直接超限; - 排查:
GODEBUG=gctrace=1看GC触发频率和回收效率; - 解决:调低GOGC(如
GOGC=50,堆增长50%触发GC),牺牲少量CPU换内存及时回收。
- 默认
-
GC停顿/写屏障开销大:
- 高并发写场景下,写屏障(保证GC正确性)开销大,GC停顿时间长,内存堆积;
- 排查:
go tool trace看GC停顿时间(STW)、写屏障占比; - 解决:减少高并发下的指针修改、拆分大对象、降低写操作的并发度。
-
内存碎片严重:
- 大量小对象分配/释放导致内存碎片,物理内存已用满,但逻辑内存还能分配(虚高);
- 排查:pprof看
heap_inuse(物理内存)和heap_alloc(逻辑内存)的差值; - 解决:减少小对象分配(合并结构体)、使用
sync.Pool复用小对象、调整内存页大小。
维度4:外部依赖/运行时问题
Go的GC仅管理Go堆内存,外部依赖或底层运行时问题也会导致OOM:
| 具体原因 | 排查方法 | 解决方案 |
|---|---|---|
| CGO代码内存泄漏 | 1. 禁用CGO(CGO_ENABLED=0)重新编译,观察内存是否恢复;2. 检查C代码的 malloc/free | 1. 手动管理C内存(C.free);2. 减少CGO调用; 3. 使用Go原生库替代C库 |
| 第三方库内存泄漏 | 1. 逐个禁用第三方库,复现问题; 2. 查看库的issue/文档 | 1. 替换有泄漏的库; 2. 升级库到最新版本; 3. 自行封装并清理资源 |
| 连接池配置过大 | 1. 检查数据库/Redis连接池的max_open_conns/max_idle_conns;2. 监控连接数 | 1. 调低连接池最大数; 2. 设置连接空闲超时( idle_timeout);3. 复用连接 |
维度5:系统层面限制/配置(容易被忽略)
OOM不一定是代码问题,系统层面的限制或配置错误也会触发:
-
容器/宿主机内存限制过低:
- 示例:容器限制2GB,但服务器峰值需要3GB,直接被OOM Killer杀死;
- 排查:
docker inspect <容器ID>看Memory限制、free -m看宿主机内存; - 解决:调高内存限制(如容器设为4GB)、开启交换分区(
swapon)。
-
ulimit限制导致间接泄漏:
- 示例:文件描述符(FD)超限,导致服务器无法关闭连接,连接占用的内存持续增长;
- 排查:
ulimit -n看当前限制、lsof -p <pid> | wc -l看FD数; - 解决:调高ulimit(
ulimit -n 65535)、代码中及时关闭FD。
-
NUMA架构内存分配不均:
- 多CPU节点的服务器,内存分配集中在某一节点,导致单节点内存超限;
- 排查:
numastat -p <pid>看内存分布; - 解决:设置
GODEBUG=madvdontneed=1、调整NUMA绑定(numactl)。
三、Go服务器OOM排查流程(标准化步骤)
-
确认OOM事实:
- 执行
dmesg | grep -i oom,确认进程是被OOM Killer杀死,记录内存使用数据(total-vm/anon-rss)。
- 执行
-
快速定位泄漏/峰值:
- 查看监控平台的内存趋势:持续上涨=泄漏;瞬间冲高=峰值过高。
-
使用pprof深度分析:
# 1. 开启pprof(代码中添加,或启动时加参数) import _ "net/http/pprof" go func() { log.Println(http.ListenAndServe(":6060", nil)) }() # 2. 分析堆内存(看大对象/泄漏点) go tool pprof http://localhost:6060/debug/pprof/heap # 常用命令:top(按内存占比排序)、list <函数名>(看具体代码)、web(生成火焰图) # 3. 分析goroutine(看阻塞/泄漏的协程) go tool pprof http://localhost:6060/debug/pprof/goroutine # 4. 分析内存分配(看临时对象) go tool pprof http://localhost:6060/debug/pprof/alloc_space -
分析GC行为:
# 启动程序时开启GC日志 GODEBUG=gctrace=1 go run main.go # 关键指标解读: # - pause: GC停顿时间(STW),正常<10ms,超过50ms需优化 # - heap_inuse: 占用的物理内存 # - heap_released: 释放回系统的内存 -
复现并验证:
- 用压测工具(如wrk/ab)模拟高并发,复现OOM;
- 逐个修改可疑点(如关闭某库、调整GC配置),验证是否解决。
总结
- Go服务器OOM的核心分两类:内存泄漏(持续增长) 和峰值过高(瞬间超限),优先通过内存趋势区分;
- 排查工具优先级:系统日志(dmesg)> pprof(堆/goroutine)> GC trace > 监控指标;
- 高频根因:未终止的Goroutine、全局集合无限增长、大对象一次性加载、GC配置过高、系统内存限制过低。
通过以上维度逐层排查,90%以上的Go服务器OOM问题都能定位并解决,核心原则是「先定位大方向,再聚焦具体代码/配置」。
panic
Go语言常见panic原因及详解
- 数组/切片索引越界(Index Out of Range) 这是Go中最常见的panic原因。当访问数组/切片的索引超出其长度范围时,运行时会直接触发panic。
避坑建议:访问前检查索引是否满足
0 ≤ idx < len(s),或使用循环遍历(如for range)避免手动指定索引。
- 空指针解引用(Nil Pointer Dereference)
声明指针变量但未初始化(默认值为
nil),却尝试访问其指向的结构体字段/方法,是高频panic场景。
避坑建议:使用指针前先初始化(如
u = &User{Name: "Tom"}),或通过if u != nil做非空检查。
- 类型断言失败(非ok模式) 类型断言时如果不使用ok模式,且断言的类型与实际类型不匹配,会直接触发panic。
避坑建议:始终使用ok模式做类型断言:
if v, ok := i.(MyType); ok {
// 类型断言成功
}
- 通道操作不当
- 重复关闭通道
- 向已关闭的通道发送数据
这两种操作都会触发panic(从已关闭通道接收数据不会panic,会返回零值+false)。
避坑建议:确保通道只关闭一次(如通过逻辑标记控制),发送数据前检查通道状态。
- 除以零(Division by Zero) 数值运算中除数为0,是数学上的非法操作,Go运行时会直接panic。
避坑建议:运算前检查除数是否为0,避免非法运算。
- sync包的误用(互斥锁重复解锁/未加锁解锁)
sync.Mutex/sync.RWMutex的解锁操作必须与加锁成对出现,未加锁解锁、重复解锁都会panic。
避坑建议:加锁后立即用
defer mu.Unlock()确保解锁操作只执行一次,避免手动控制出错。
- 调用nil函数
函数类型的变量如果是
nil,调用它会触发panic。
避坑建议:调用函数前检查
if f != nil,或确保函数变量被正确赋值。
- 修改nil切片的元素 nil切片的长度和容量均为0,直接修改其元素会panic(但append nil切片是安全的,会自动分配内存)。
避坑建议:修改切片元素前先初始化(如
s = make([]int, 1)),或通过append初始化。
总结
- Go中panic的核心根源是非法内存访问(索引越界、空指针解引用等)和资源/运算操作不合法(重复关通道、除以零等)
- 规避panic的关键是:操作前做合法性检查(如非空、索引范围),使用安全模式(如类型断言的ok模式),确保资源操作成对唯一
- 即使无法完全避免panic,也可通过
recover()在defer中捕获panic
内置结构
一、slice(切片)核心结构
slice并非原生数组,而是对底层数组的轻量级封装,本质是“动态数组“,核心由SliceHeader结构体实现,源码定义于runtime/slice.go和reflect/value.go。
1. 核心结构体:SliceHeader
slice的底层是包含三个字段的结构体,reflect包将其暴露为SliceHeader,运行时内部逻辑等价结构体为slice,简化定义如下:
// reflect包暴露的切片头部结构
type SliceHeader struct {
Data uintptr // 指向底层数组的指针(核心:slice是对数组的引用)
Len int // 切片长度(len(s)返回值,当前可访问元素个数)
Cap int // 切片容量(cap(s)返回值,底层数组的可用空间)
}
// 运行时内部slice结构体(与SliceHeader语义一致)
type slice struct {
array unsafe.Pointer // 指向底层数组的指针
len int // 长度
cap int // 容量
}
关键字段解析:
- Data/array:最核心字段,指向底层连续内存数组,slice所有操作最终作用于该数组
- Len:当前可访问元素数量,访问
s[len(s)]会触发越界panic - Cap:底层数组从Data指针开始的总可用空间,恒满足
Cap ≥ Len
2. 核心工作机制
切片操作(s[low:high]):共享底层数组
切片操作不会复制底层数组,仅创建新的slice结构体,新结构体与原slice共享底层数组:
- 新slice的Data指针指向原底层数组的low索引位置
- 新slice的Len = high - low
- 新slice的Cap = 原Cap - low
func main() {
s1 := []int{1,2,3,4,5} // len=5, cap=5,底层数组[1,2,3,4,5]
s2 := s1[1:3] // len=2, cap=4,共享原底层数组
s2[0] = 99 // 修改新切片元素,影响原切片
fmt.Println(s1) // 输出 [1,99,3,4,5]
fmt.Println(s2) // 输出 [99,3]
}
扩容机制(append触发)
当append添加元素导致Len == Cap时,触发扩容,核心逻辑:
- 计算新容量:原容量<1024时翻倍,≥1024时增长25%,最终按元素类型内存对齐微调
- 创建新数组:分配对应新容量的连续内存
- 拷贝数据:将原底层数组元素拷贝至新数组
- 更新结构体:新slice的Data指向新数组,Len为原Len+1,Cap为新容量
⚠️ 陷阱:扩容后原slice仍指向旧数组,新slice指向新数组,二者不再共享数据。
nil slice vs 空slice
二者Len和Cap均为0,但Data指针状态不同:
- nil slice:Data=nil,未指向任何数组(如
var s []int) - 空slice:Data≠nil,指向空底层数组(如
s := []int{}或make([]int, 0))
3. 关键特性
- 引用类型:slice本身是值类型(结构体拷贝),但Data指针共享底层数组,传参时修改元素会影响原切片
- 长度/容量分离:Len限制访问范围,Cap限制扩容基础,append优先使用空闲空间
- 连续内存:底层数组连续,随机访问效率O(1),扩容伴随拷贝开销
- 越界检查:访问index≥Len触发panic,Cap范围内空间可通过
s[:cap(s)]暴露
二、map(哈希表)核心结构
map基于哈希表实现,核心由hmap(顶层管理结构)和bmap(桶结构)组成,源码定义于runtime/map.go。
1. 核心结构体
hmap(哈希表顶层管理结构)
负责管理map元数据和桶数组,简化定义:
type hmap struct {
count int // 实际存储的键值对数量(len(map)返回值)
B uint8 // 桶数组大小指数,桶总数=2^B
hash0 uint32 // 哈希种子,增加哈希值随机性
buckets unsafe.Pointer // 指向正常状态的桶数组
oldbuckets unsafe.Pointer // 扩容时指向旧桶数组(双桶共存)
nevacuate uintptr // 扩容时搬迁进度标记
}
bmap(桶,存储键值对的最小单元)
单个bmap默认存储8个键值对,结构优化内存对齐,简化逻辑结构:
type bmap struct {
tophash [8]uint8 // 存储每个键哈希值的高8位,用于快速匹配
// 内存布局:8个key → 8个value → overflow指针(指向溢出桶)
}
关键字段解析:
- hmap.count:直接对应len(map),O(1)获取
- hmap.B:动态调整,平衡哈希冲突与内存占用
- hmap.oldbuckets:扩容期间临时存储旧桶,搬迁完成后置空
- bmap.tophash:快速过滤不匹配key,减少全量哈希对比
- bmap.overflow:桶满时链接溢出桶,形成链表
2. 核心工作流程(查找/插入)
- 计算哈希值:以hmap.hash0为种子,计算key的64位(32位系统32位)哈希值
- 定位桶:取哈希值低B位计算索引,找到对应bmap
- 匹配key:对比bmap.tophash(哈希高8位),匹配后验证key本身,无匹配则检查溢出桶
- 扩容触发:负载因子(count/2^B)超过6.5,或溢出桶过多时触发,分倍数扩容(桶数翻倍)和等量扩容(仅搬迁数据)
3. 关键特性
- 并发不安全:无锁保护,多协程同时读写会触发panic
- key可比较性:key必须支持哈希和相等判断,slice、map、func不可作为key
- 内存高效:key/value连续存储优化内存对齐,提升CPU缓存命中率
- 渐进式扩容:扩容时逐步搬迁数据,避免单次操作耗时过长
三、channel(通道)核心结构
channel是goroutine间安全通信的同步原语,底层由hchan结构体实现,本质是“带锁的环形队列+等待队列“,源码定义于runtime/chan.go。
1. 核心结构体:hchan
hchan包含类型元数据、缓冲区、同步锁、等待队列四大核心部分,简化定义:
type hchan struct {
elemtype *_type // 元素类型信息,保证类型安全
elemsize uint16 // 单个元素字节大小
closed uint32 // 关闭标记:0未关闭,1已关闭
dataqsiz uint64 // 缓冲区容量(make(chan T, N)中的N)
buf unsafe.Pointer // 指向环形队列的指针
sendx uint64 // 环形队列写指针
recvx uint64 // 环形队列读指针
qcount uint64 // 缓冲区当前元素数量
lock mutex // 互斥锁,保证并发安全
sendq waitq // 发送者等待队列(因满阻塞的goroutine)
recvq waitq // 接收者等待队列(因空阻塞的goroutine)
}
// 等待队列结构
type waitq struct {
first *sudog // 队列头
last *sudog // 队列尾
}
// 封装阻塞的goroutine
type sudog struct {
g *g // 阻塞的goroutine
elem unsafe.Pointer // 元素数据指针
next, prev *sudog // 链表节点指针
}
2. 核心工作流程
无缓冲channel(make(chan T))
dataqsiz=0,无缓冲区,核心是goroutine直接配对:
- 发送流程:检查recvq有接收者则直接拷贝值并唤醒,无则封装发送者加入sendq并挂起
- 接收流程:检查sendq有发送者则直接拷贝值并唤醒,无则封装接收者加入recvq并挂起
有缓冲channel(make(chan T, N))
优先使用环形队列存储数据,仅满/空时阻塞:
- 发送流程:缓冲区未满则写入数据并移动写指针,已满则加入sendq挂起
- 接收流程:缓冲区非空则读取数据并移动读指针,为空则加入recvq挂起
关闭channel(close(ch))
- 加锁并将closed置为1
- 唤醒recvq所有接收者(读到零值+关闭标识)
- 唤醒sendq所有发送者(触发panic)
- 解锁并清理资源
3. 关键特性
- 并发安全:lock互斥锁保证所有操作原子性,多协程读写安全
- 类型安全:elemtype和elemsize确保发送/接收类型一致,编译期校验
- 阻塞特性:无缓冲同步通信,有缓冲异步通信,依赖等待队列实现阻塞唤醒
- 关闭后行为:关闭后发送panic,接收先读缓冲区再返回零值
四、总结
- slice:基于底层数组的轻量封装,核心是SliceHeader三字段,依赖扩容实现动态增长,共享底层数组需注意数据污染
- map:哈希表实现,hmap管理桶数组,bmap存储键值对,通过溢出桶和渐进式扩容平衡性能与内存
- channel:带锁环形队列+等待队列,通过锁保证并发安全,通过等待队列实现goroutine阻塞唤醒,分有缓冲/无缓冲两种通信模式
python
重要网站
python2已死,不要再学再用啦!!!
官方第三方包网站,你绝对值得拥有!
- venv-解决不同项目依赖不同版本包,依赖冲突
# 源码编译安装
# 官网 python.org 下载压缩包,解压
# 然后,在./configure的时候,需要加上 --enable-optimizations参数,这样才能启用很多功能。
# 创建tutorial-env目录,复制一份python相关环境
python3 -m venv tutorial-env
# windows执行,激活虚拟环境
tutorial-env\Scripts\activate.bat
# Macos/unix执行,激活虚拟环境
source tutorial-env/bin/activate
安装pip
#看看pip是否安装,现在一般都安装的,特别是采用brew,安装包之类
python3 -m pip --version
#手动安装,一般不用
python3 -m ensurepip --default-pip
# 升级pip
python3 -m pip install --upgrade pip
# 在某些情况下,我们需要查看第三方包的依赖包和被依赖包
# 命令输出的 Requires 和 Required-by
pip show pkg_name
# 能显示所有的依赖包及其子包,推荐用这个
pip deptree -p pkg_name
# 永久性切换国内清华源
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 换回默认源
pip3 config unset global.index-url
# 本次下载python中的Django包,这里使用的是豆瓣源
pip3 install django -i http://pypi.douban.com/simple
requirements.txt可以通过pip命令自动生成和安装
- 生成requirements.txt文件
# 产生整个python环境的安装依赖,方便移值及复制
pip freeze > requirements.txt
- 安装requirements.txt依赖包:
pip install -r requirements.txt
安装常用库
# pylint执行pep8规范
pip3 install pylint
pylint xxx.py
# 更严格的检测flake8
pip3 install flake8
flake8 xx.py
# 强制统一代码风格
pip install black
black code_dir/xxx.py
# yapf是google开源的格式化代码工具
pip install yapf
# 统一import格式
pip3 install isort
isort xx.py
# 静态检查
pip3 install mypy
mypy xxx.py
# 比内置unittest更好用单元测试
pip3 install pytest
# content of test_sample.py
def inc(x):
return x + 1
def test_answer():
assert inc(3) == 5
pytest
if __name__ == '__main__':
# 我是主模块身份
# 列举任意对象的全部属性
dir(obj)
- fabric
- yagmail-发邮件
- fastui-纯python的ui
- awesome-python
- Selenium是一个用电脑模拟人操作浏览器网页
- nicegui-纯python生成html的gui
- js2py纯python执行js
- supervisor-进程管理
- numpy
- pandas
- PyGithub-封装github的api
- plotnine
- pillow
- xlwings操作excel
- flet-flutter的python包装
- pydantic-类型注解加强版
- anaconda-独立开源包管理器
- spacy-python的自然语言库
- nltk-python的自然语言库
Anaconda包括Conda、Python以及一大堆安装好的工具包,比如:numpy、pandas等 Miniconda包括Conda、Python conda是一个开源的包、环境管理器,可以用于在同一个机器上安装不同版本的软件包及其依赖,并能够在不同的环境之间切换
# settings.py
LANGUAGE_CODE = "zh-hans"
TIME_ZONE = "Asia/Shanghai"
USE_TZ = False
- Flask
- requests
- httpx-异步版requests
- Django-rest-framework
- scrapy-splash-配合scrapy无界面浏览器
- scrapy
- falcon
- odoo以前openERP
- uvicorn-快如闪电的web框架
docker odoo
- frida
- vibora
- web3.py
- pycorrector-中文纠错
- atomicwrites-原子写
- sqlalchemy2.0-sql数据库
- [deepcompare-深度比较]
- [jsonlines-jsonl文件]
- [boltons-常见第三方工具集合]
- fastapi-后起之秀http框架
- sanic-最快的web框架
- office-自动化系列
- Pyodide-浏览器中运行python,采用webasm
from atomicwrites import atomic_write
with atomic_write('foo.txt', overwrite=True) as f:
f.write('Hello world.')
# "foo.txt" doesn't exist yet.
# Now it does.
特别包
# import cv2
pip3 install opencv-python
pip3 install numpy
# import PIL
pip3 install pillow
pip3 install image
# No matching distribution found for onnxruntime
# 暂时不支持m1芯片
pip3 install onnxruntime
浏览器本地文档
#更多命令 pydoc3 -help
pydoc3 -p 7070

说明requirement.txt
- 通常我们会在项目的根目录下放置一个 requirement.txt 文件,用于记录所有依赖包和它的确切版本号。
- 每行一个依赖包,可以指定包的具体版本
web服务器与app协议之WSGI、ASGI
-
WSGI-同步web应用
- python-web-app,也就是web应用层,实现WSGI接口,用作web请求的handler
- 用户向python-web-server发送web请求
- python-web-server,又称作WSGI Server,解析请求数据,整理当前session的环境信息
- python-web-server加载python-web-app,调用python-web-app实例的WSGI接口,处理请求
- python-web-app处理完请求,返回结果给到python-web-server
- python-web-server写回返回结果,给回用户
def application(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/plain')])
return [b'Greetings universe']
-
ASGI-异步web应用
- 一方面是支持asyncio的机制
- 另一方面也能够解决WSGI难以支持WebSocket之类长连接模式的问题
- 执行流程和wsgi差不多
async def application(scope, receive, send):
event = await receive()
...
await send({"type": "websocket.send", ...})
# 直接下载whl文件,本地安装
pip3 install xxx.whl
- 另一个神经网络模型可视化-Netron
wheel(轮子),wheel是一个zip压缩文件,将.whl扩展名替换为.zip
-
wheel是python新的发行标准,旨在替代传统的egg,pip >=1.4的版本均支持wheel, 使用wheel作为你python库的发行文件,有如下好处:
- 纯Python和本机C扩展软件包的安装速度更快
- 避免执行任意代码进行安装。
- (避免setup.py)C扩展的安装不需要在Linux,Windows或macOS上进行编译
- 允许更好地缓存以进行测试和持续集成
- 在安装过程中创建.pyc文件,以确保它们与使用的Python解释器匹配跨平台和机器的安装更加一致
# 制作wheel安装包-方式1 python setup.py bdist_wheel # 制作wheel安装包-方式2 pip wheel --wheel-dir=/root/whl ./
注解解释
-
在 Python 3.5 中,Python PEP 484 引入了类型注解(type hints)
-
在 Python 3.6 中,PEP 526 又进一步引入了变量注解(Variable Annotations)。
-
具体的变量注解语法可以归纳为两点:
- 在声明变量时,变量的后面可以加一个冒号,后面再写上变量的类型,如 int、list 等等。
- 在声明方法返回值的时候,可以在方法的后面加一个箭头,后面加上返回值的类型,如 int、list 等等。
-
在PEP 8 中,具体的格式是这样规定的:
- 在声明变量类型时,变量后方紧跟一个冒号,冒号后面跟一个空格,再跟上变量的类型。
- 在声明方法返回值的时候,箭头左边是方法定义,箭头右边是返回值的类型,箭头左右两边都要留有空格。
-
值得注意的是,这种类型和变量注解实际上只是一种类型提示,对运行实际上是没有影响的。
opencv,python绑定
# OpenCV-Python接口中使用cv2.findContours ()函数来查找检测物体的轮廓。
contours, hierarchy = cv2.findContours (image,mode,method)
# mask是与iamge一样大小的矩阵,其中的数值为0或者1,为1的地方,计算出image中所有元素的均值,为0 的地方,不计算
cv::Scalar mean = cv2.mean (image, mask)
应用cv2.warpPerspective()前需先使用cv2.getPerspectiveTransform()得到转换矩阵
cv2.warpPerspective() 叫做透视变换。
# 以彩色模式加载图片
img = cv2.imdecode(np_arr, cv2.IMREAD_COLOR)
paddleocr
self.input_tensor.copy_from_cpu(norm_img_batch)
self.predictor.run()
outputs = []
for output_tensor in self.output_tensors:
output = output_tensor.copy_to_cpu()
outputs.append(output)
if len(outputs) != 1:
preds = outputs
else:
preds = outputs[0]
- Tensor 是 Paddle Inference 的数据组织形式,用于对底层数据进行封装并提供接口对数据进行操作,包括设置 Shape、数据、LoD 信息等。 注意: 应使用 Predictor 的 get_input_handle 和 get_output_handle 接口获取输入输出 Tensor
ipynb文件格式-Jupyter Notebook产生的
fabric示例
#!python3
# -*- coding:utf8 -*-
# fab默认采用fabfile.py作为入口代码脚本,否则就要指定 -f xxx.py
# task函数名不要用下划线,否则task名称会改变
# pip3 install fabric2
# pip3 install pyyaml
from fabric import task
from fabric import Connection
cur_remote_data_path = "/root/"
cur_remote_conn = Connection(
"root@ip",
)
def upload(file_list):
global cur_remote_conn, cur_remote_data_path
assert cur_remote_conn, "远程主机为空"
assert cur_remote_data_path, "远程数据路径为空"
for file in file_list:
print(file, "put over")
for file in file_list:
cur_remote_conn.put(file, cur_remote_data_path)
print(file, "put over")
@task
def download(c):
global cur_remote_conn
assert cur_remote_conn, "远程主机为空"
# 下载日志
cur_remote_conn.get("index.html")
fastapi示例
from typing import Union
from fastapi import FastAPI
from pydantic import BaseModel
# async def app(scope, receive, send):
app = FastAPI()
class Item(BaseModel):
name: str
price: float
is_offer: Union[bool, None] = None
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
async def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
@app.put("/items/{item_id}")
def update_item(item_id: int, item: Item):
return {"item_id": item_id, "item": item}
if __name__ == "__main__":
import uvicorn
uvicorn.run("main:app", reload=True)
memcached示例
pip3 install pymemcache
#!python3
from pymemcache.client.base import Client
client = Client('localhost')
memKey = '/memcached'
client.set(memKey, '<HTML><H1>Hi, Memcached!</H1></HTML>')
result = client.get(memKey)
print(result)
numpy示例
#!python3
# -*- coding:utf8 -*-
import numpy as np
b = np.ones((3, 4), dtype=np.int64)
# [[1 1 1 1]
# [1 1 1 1]
# [1 1 1 1]]
print(b)
print("b shape:", b.shape)
a = np.array([[1, 5, 5, 2],
[9, 6, 2, 8],
[3, 7, 9, 1]])
print("a shape:", a.shape)
# 每列最大值下标,[1 2 2 1]
print("argmax axis=0", np.argmax(a, axis=0))
# 每列最大值下标,[9 7 9 8]
print("max axis=0", np.max(a, axis=0))
# 每行最大值下标,[1 0 2]
print("argmax axis=1", np.argmax(a, axis=1))
# 每行最大值下标,[5 9 9]
print("max axis=1", np.max(a, axis=1))
a = np.array([1, 2, 3])
b = np.array([11, 22, 33])
c = np.array([44, 55, 66])
# 有效的数组拼接
abc = np.concatenate((a, b, c), axis=0)
print("abc shape:", abc)
a = np.array([[1, 5, 5, 2],
[9, 6, 2, 8],
[3, 7, 9, 1]])
# 用于将数组的元素沿指定的轴旋转90度
a_rot = np.rot90(a)
print("a_rot:", a_rot)
大厂提供ocr接口
阿里
# -*- coding: utf-8 -*-
# pip install -r requirement.txt
# pip install alibabacloud_ocr_api20210707==1.1.8
import json
from logging import exception
from alibabacloud_ocr_api20210707.client import Client as ocr_api20210707Client
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_ocr_api20210707 import models as ocr_api_20210707_models
from alibabacloud_tea_util import models as util_models
# https://help.aliyun.com/document_detail/331008.html
# https://ocr.console.aliyun.com/overview?spm=5176.12127803.J_5253785160.2.4f767813QmL9ES
# 每个月免费200次,后付费类型
def aliyun(img_url):
config = open_api_models.Config(
# 您的 AccessKey ID,
access_key_id="xxxx",
# 您的 AccessKey Secret,
access_key_secret="yyyy",
)
# 访问的域名
config.endpoint = "ocr-api.cn-hangzhou.aliyuncs.com"
client = ocr_api20210707Client(config)
recognize_general_request = ocr_api_20210707_models.RecognizeGeneralRequest(
url=img_url
)
runtime = util_models.RuntimeOptions()
try:
# 复制代码运行请自行打印 API 的返回值
resp = client.recognize_general_with_options(
recognize_general_request, runtime
).to_map()
data_json = json.loads(resp["body"]["Data"])
return data_json["content"]
except Exception as error:
return str(error)
tencent
tencentcloud-sdk-python=3.0.720
# pip install tencentcloud-sdk-python=3.0.720
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.common.exception.tencent_cloud_sdk_exception import (
TencentCloudSDKException,
)
from tencentcloud.ocr.v20181119 import ocr_client, models
# 免费额度,每月1000次
# https://console.cloud.tencent.com/ocr/stats
def tencent(img_url):
try:
# 实例化一个认证对象,入参需要传入腾讯云账户secretId,secretKey,此处还需注意密钥对的保密
# 密钥可前往https://console.cloud.tencent.com/cam/capi网站进行获取
cred = credential.Credential(
"aaaa",
"vvvvv",
)
# 实例化一个http选项,可选的,没有特殊需求可以跳过
httpProfile = HttpProfile()
httpProfile.endpoint = "ocr.tencentcloudapi.com"
# 实例化一个client选项,可选的,没有特殊需求可以跳过
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
# 实例化要请求产品的client对象,clientProfile是可选的
client = ocr_client.OcrClient(cred, "ap-hongkong", clientProfile)
# 实例化一个请求对象,每个接口都会对应一个request对象
req = models.GeneralBasicOCRRequest()
params = {"ImageUrl": img_url}
req.from_json_string(json.dumps(params))
# 返回的resp是一个GeneralBasicOCRResponse的实例,与请求对象对应
resp = client.GeneralBasicOCR(req)
text_list = []
for td in resp.TextDetections:
text_list.append(td.DetectedText)
return "".join(text_list)
except TencentCloudSDKException as err:
return str(err)
调用
import _thread
import random
def img_to_text(img_url):
handle = aliyun
if random.randint(0, 3) > 0:
handle = tencent
try:
_thread.start_new_thread(handle, (img_url))
return handle.__name__
except exception as e:
print(str(e))
if __name__ == "__main__":
img_to_text("abc")
# tencent(
# "http://mmbiz.qpic.cn/mmbiz_jpg/orWialEIuwfvLgnHX8t8sXpMqWlsvsSW5E8KtF985vlVxRfFX5aq0ckQnWOAeYMF1Oo7wUMqfu7oCe76v3zT2kw/0"
# )
paddleocr示例
百度开源Paddle
- 安装框架
python3 -m pip install paddlepaddle==2.4.2 -i https://mirror.baidu.com/pypi/simple
- 安装ocr
pip3 install "paddleocr>=2.0.1" -i https://mirror.baidu.com/pypi/simple
-
- Download source code locally
- In requirements.txt, update to opencv-contrib-python==4.6.0.66
- Pip install - r requirements.txt
- python setup.py install
- ppadleocr 安装在/opt/homebrew/opt/python@3.9/Frameworks/Python.framework/Versions/3.9/bin
- 第一次运行会下载训练好的模型到~/.paddleocr目录
- ln -s /opt/homebrew/opt/python@3.9/Frameworks/Python.framework/Versions/3.9/bin/paddleocr paddleocr
-
安装paddleocrlabel
-
[m1芯片源码安装]
- 下载源码
git clone git@github.com:PaddlePaddle/PaddleOCR.git cd PPOCRLabel python setup.py install # 如果出现安装pyqt5失败,则采用brew install pyqt5 Installing PPOCRLabel script to /opt/homebrew/opt/python@3.9/Frameworks/Python.framework/Versions/3.9/bin cd /opt/homebrew/bin ln -s /opt/homebrew/opt/python@3.9/Frameworks/Python.framework/Versions/3.9/bin/PPOCRLabel PPOCRLabel # 运行,第一运行会下载必要东西~/.paddleocr目录 PPOCRLabel --lang ch # 针对特别业务,可以事先处理图片,再传入自动标注
# applie m1 芯片安装,会有问题,因为没有直接aarch64.whl,需要重头编译,但目前没有办法成功
pip3 install pyqt5
# 幸好brew可以帮忙编译
brew install pyqt5
- 模型结构可视化VisualDL
python3 -m pip install visualdl -i https://mirror.baidu.com/pypi/simple
# Running VisualDL at http://localhost:8040/ (Press CTRL+C to quit)
./visualdl
# 网络结构-静态,把模型文件拖进去<https://www.paddlepaddle.org.cn/inference/master/guides/export_model/visual_model.html>
#!python3
import re
from PIL import Image
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
# need to run only once to download and load model into memory
ocr = PaddleOCR(use_angle_cls=False, lang="ch", show_log=False)
img_path = '01.jpg'
result = ocr.ocr(img_path, cls=False)
# for line in result:
# for box in line:
# print(type(box), box)
# break
result = result[0]
# 显示结果
image = Image.open(img_path).convert('RGB')
# boxes = [line[0] for line in result]
# txts = [line[1][0] for line in result]
# scores = [line[1][1] for line in result]
boxes = [result[0]]
txts = [result[1][0]]
scores = [result[1][1]]
im_show = draw_ocr(image, boxes, txts, scores, font_path='simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
运行 Dynamic shape
当模型的输入 shape 不固定的话(如 OCR,NLP 的相关模型),需要推理框架提供动态 shape 的支持。 从1.8 版本开始, Paddle Inference 对 TensorRT 子图进行了 Dynamic shape 的支持。 使用接口如下:
config.enable_tensorrt_engine(
workspace_size = 1<<30,
max_batch_size=1, min_subgraph_size=5,
precision_mode=paddle_infer.PrecisionType.Float32,
use_static=False, use_calib_mode=False)
min_input_shape = {"image":[1,3, 10, 10]}
max_input_shape = {"image":[1,3, 224, 224]}
opt_input_shape = {"image":[1,3, 100, 100]}
config.set_trt_dynamic_shape_info(min_input_shape, max_input_shape, opt_input_shape)
从上述使用方式来看,在 config.enable_tensorrt_engine 接口的基础上,新加了一个 config.set_trt_dynamic_shape_info 的接口。 “image” 对应模型文件中输入的名称。 该接口用来设置模型输入的最小、最大、以及最优的输入 shape。 其中,最优的 shape 处于最小最大 shape 之间,在推理初始化期间,会根据opt shape对 Op 选择最优的 Kernel 。 调用了 config.set_trt_dynamic_shape_info 接口,推理器会运行 TensorRT 子图的动态输入模式,运行期间可以接受最小、最大 shape 间的任意 shape 的输入数据。
redis示例
pip3 install redis
#!python3
import redis
client = redis.Redis(host="localhost", port=6379, db=0)
key = "/redis"
client.set(key, "<HTML><H1>Hi, Redis!</H1></HTML>")
resp = client.get(key)
print(resp)
requests示例
#!python3
# -*- coding:utf8 -*-
# pip3 install requests
import requests
r = requests.get("https://www.baidu.com/")
print(r.headers)
print(r.text)
httpx示例
import httpx
r = httpx.get('https://www.baidu.com/')
print(r.headers['content-type'])
print(r.text)
opencv示例
透视
#!python3
# -*- coding:utf8 -*-
import cv2
import numpy as np
img = cv2.imread("01.jpg", cv2.IMREAD_COLOR)
img_org = img.copy()
print("img shape", img.shape, cv2.IMREAD_COLOR, cv2.COLOR_GRAY2BGR)
# 得到图片的高和宽
img_height, img_width = img.shape[:2]
# 定义对应的点
points1 = np.float32([[75, 55], [340, 55], [33, 435], [400, 433]])
points2 = np.float32([[0, 0], [360, 0], [0, 420], [360, 420]])
# 计算得到转换矩阵
M = cv2.getPerspectiveTransform(points1, points2)
# 实现透视变换转换
processed = cv2.warpPerspective(img, M, (360, 420))
# 读取灰度图片,转彩色
img_gray = cv2.imread("01.jpg", 0)
img_gray_rgb = cv2.cvtColor(img_gray, cv2.COLOR_GRAY2BGR)
# 显示原图和处理后的图像
cv2.imshow("org", img_org)
cv2.imshow("processed", processed)
cv2.imshow("img_gray_rgb", img_gray_rgb)
cv2.waitKey(0)
旋转
import cv2
img = cv2.imread("rotate.png")
h, w = img.shape[:2]
center = (w / 2, h)
angle = 2.0
scale = 1.0
m = cv2.getRotationMatrix2D(center,angle,scale)
r = cv2.warpAffine(img, m,(w, h))
cv2.imwrite("result.png", r)
# cv2.imshow("rate",r)
# cv2.waitKey()
js2py示例
import js2py
# 超级慢,需要改写成python
js_code = """
function Add(x, y) {
return x + y;
}
"""
js_add = js2py.eval_js(js_code)
if __name__ == "__main__":
print(js_add(1, 3))
woff字体转png
from fontTools.ttLib import TTFont
import os
import shutil
from fontTools.pens.svgPathPen import SVGPathPen
from svglib.svglib import svg2rlg
from reportlab.graphics import renderPM
import io
def woff_to_pngdir(woff_file):
base_file_name = os.path.splitext(woff_file)[0]
if os.path.exists(base_file_name):
# 删除非空目录
shutil.rmtree(base_file_name, ignore_errors=True)
try:
os.mkdir(base_file_name)
except Exception as e:
print(e)
# 读取woff文件
font = TTFont(woff_file)
charsdict = font.getBestCmap()
for key, value in charsdict.items():
# 产生svg
pen = SVGPathPen(font.getGlyphSet())
font.getGlyphSet()[value].draw(pen)
xMin, xMax, yMin, yMax = (
font["head"].xMin,
font["head"].xMax,
font["head"].yMin,
font["head"].yMax,
)
height = yMax - yMin
width = xMax - xMin
# r=width/100
svg_xml = f'<svg version="1.1" xmlns="http://www.w3.org/2000/svg" viewBox="{xMin} {yMin} {width} {height}"><g transform="matrix(0.6 0 0 -0.6 {xMin+width*0.2} {yMin+yMax-height*0.2})"><path stroke = "black" fill = "black" d="{pen.getCommands()}"/></g></svg>'
# 内存png
drawing = svg2rlg(io.StringIO(svg_xml))
# 保存识别结果
renderPM.drawToFile(drawing, rf"{key}-{value}.png")
if __name__ == "__main__":
woff_to_pngdir("abc.woff")
生成svg图片
import sys
import os
from PIL import Image
def convertPixel(r, g, b, a=1):
color = "#%02X%02X%02X" % (r, g, b)
opacity = a
return (color, opacity)
for r in sys.argv[1:]:
root, ext = os.path.splitext(r)
image = Image.open(r)
mode = image.mode
pixels = image.load()
width, height = image.size
print(image.mode)
if "RGB" in mode:
output = f'<svg width="{width}" height="{height}" viewBox="0 0 {width} {height}" xmlns="http://www.w3.org/2000/svg">'
for r in range(height):
for c in range(width):
color, opacity = convertPixel(*pixels[c, r])
output += f'<rect x="{c}" y="{r}" width="1" height="1" fill="{color}" fill-opacity="{opacity}"/>'
output += "</svg>"
with open(root + ".svg", "w") as f:
f.write(output)
c++
LZ78算法
压缩
#include "Dictionary.h"
#include <iostream>
#include <fstream>
#include <string>
int main(int argc, char* argv[])
{
std::ifstream file("test.txt");
std::ofstream out("test2.lzw");
char ch;
std::string perfix = "";
Dictionary dict;
while (!file.eof())
{
file>>ch;
if (dict.is_exist(perfix+ch))
{
perfix += ch;
}
else
{
out<<dict.get_mask(perfix)<<ch;
dict.add(perfix+ch);
perfix = "";
}
}
if (perfix != "")
{
out<<dict.get_mask(perfix);
}
file.close();
out.close();
std::cout<<"conpress success!"<<std::endl;
return 0;
}
解压
#include <fstream>
#include <string>
#include "Dictionary.h"
int main(int argc, char* argv[])
{
std::ifstream file("test2.lzw");
std::ofstream out("test2.txt");
std::string prefix = "";
char ch;
long mask;
Dictionary dict;
while (!file.eof())
{
file>>mask>>ch;
std::string temp = dict.get_perfix(mask)+ch;
out<<temp;
dict.add(temp);
}
std::cout<<"decompress success"<<std::endl;
return 0;
}
字典实现
#include <map>
#include <string>
class Dictionary
{
public:
std::string get_perfix(long mask);
long get_mask(const std::string perfix);
bool is_exist(const std::string member);
void add(const std::string word);
Dictionary();
virtual ~Dictionary();
private:
long index;
std::map<std::string, long> store;
};
Dictionary::Dictionary()
{
index = 0;
}
Dictionary::~Dictionary()
{
}
void Dictionary::add(const std::string word)
{
this->store[word] = ++index;
}
bool Dictionary::is_exist(const std::string member)
{
std::map<std::string, long>::iterator pos;
pos = this->store.find(member);
if (pos != store.end())
{
return true;
}
else
{
return false;
}
}
long Dictionary::get_mask(const std::string perfix)
{
if ((index==0) || (perfix==""))
{
return 0;
}
else
{
std::map<std::string, long>::iterator pos;
pos = this->store.find(perfix);
if (pos != store.end())
{
return pos->second;
}
else
{
return 0;
}
}
}
std::string Dictionary::get_perfix(long mask)
{
if (mask != 0)
{
std::map<std::string, long>::iterator pos;
for (pos = this->store.begin(); pos != store.end(); pos++)
{
if (pos->second == mask)
{
return pos->first;
}
}
}
return "";
}
检验比较
#include <iostream>
#include <fstream>
int main(int argc, char* argv[])
{
std::ifstream file_first("test.txt");
std::ifstream file_second("test2.txt");
char ch_first;
char ch_second;
while (!file_first.eof() && !file_second.eof())
{
file_first>>ch_first;
file_second>>ch_second;
if (ch_first != ch_second)
{
std::cout<<"do not complete "<<std::endl;
return 0;
}
}
std::cout<<"complete"<<std::endl;
return 0;
}
perm
换位法生成全排列
#include <iostream>
#include <string>
#include <bitset>
#include <fstream>
#include <stdio.h>
const int array_length = 30;
template <typename T>
int get_max_active(const int* ptr_array,
int length,
const T& ptr_array_flag)
{
int max_index = -1;
for (int i=0; i<length; i++)
{
int j;
if (ptr_array_flag[i])//from left to right
{
j = i+1;
while (j<length)
{
if (ptr_array[i] > ptr_array[j++])// has active state data
{
if ((max_index == -1) || (ptr_array[max_index] < ptr_array[i]))
{
max_index = i;
}
break;
}
}
}
else// from right to left
{
j = i-1;
while (j >= 0)
{
if (ptr_array[i] > ptr_array[j--])
{
if ((max_index == -1) || (ptr_array[max_index] < ptr_array[i]))
{
max_index = i;
}
break;
}
}// end of while
}// end of if
}// end of for
return max_index;
}
template <typename T>
void gen_arrange(int* ptr_array, int length, T& ptr_array_flag)
{
std::ofstream out_file("arrange.txt");
int max_index = -1;// -1 is no active data
int max_data;
while ( (max_index = get_max_active(ptr_array, length, ptr_array_flag)) != -1)
{
for (int k=0; k<length; k++)
{
out_file<<ptr_array[k]<<"|";
}
out_file<<std::endl;
max_data = ptr_array[max_index];
//change heig
if (ptr_array_flag[max_index])//from left to right
{
//change flag
if (!ptr_array_flag[max_index+1])
{
ptr_array_flag.flip(max_index+1);
ptr_array_flag.flip(max_index);
}
//change value
ptr_array[max_index] += ptr_array[max_index+1];
ptr_array[max_index+1] = ptr_array[max_index] - ptr_array[max_index+1];
ptr_array[max_index] -= ptr_array[max_index+1];
}
else//from right to left
{
//change flag
if (ptr_array_flag[max_index+1])
{
ptr_array_flag.flip(max_index);
ptr_array_flag.flip(max_index+1);
}
//change value
ptr_array[max_index] += ptr_array[max_index-1];
ptr_array[max_index-1] = ptr_array[max_index] - ptr_array[max_index-1];
ptr_array[max_index] -= ptr_array[max_index-1];
}//end of if
//change better than max_data flag
for (int j=0; j<length; j++)
{
if (ptr_array[j] > max_data)
{
ptr_array_flag.flip(j);//change flag
}
}
}//end of while
for (int k=0; k<length; k++)
{
out_file<<ptr_array[k]<<"|";
}
out_file<<std::endl;
}
int main(int argc, char* argv[])
{
int array[array_length];
//init array data
for (int i=0; i<array_length; i++)
{
array[i] = i+1;
}
std::string str_flag;
//init array flag from right to left
for (int i=0; i<array_length; i++)
{
str_flag +='0';
}
std::bitset<array_length> array_flag(str_flag);
gen_arrange(array, array_length, array_flag);
return 0;
}
random
利用费根鲍姆迭代模型产生随机数
#include <iostream>
#include <fstream>
using namespace std;
int main(int argc, char* argv[])
{
ofstream of("rand.txt");
double init_seed = 0.990976548;
double last = init_seed;
for (int i=0; i<1000; i++)
{
last = 4*last*(1-last);//Xn+1 = CXn(1-Xn)其中c=4
of<<last<<endl;
}
cout<<"create over"<<endl;
of.close();
return 0;
}
常见文件
YAML文件
- YAML(YAML Ain’t Markup Language)是人类可读的数据序列化格式
- 用于配置文件(Docker Compose/K8s/CI/CD),依赖缩进、换行和简单符号定义结构。
一、核心格式规则
1. 基础文件标识(可选)
-
文档开始:
--- -
文档结束:
... -
单文件多文档必须用
---分隔
# 单文档
---
name: Alice; age: 28
...
# 多文档
---
doc1: "First";
---
doc2: "Second"
2. 缩进规则(核心)
-
禁用 Tab,必须用空格(推荐 2/4 空格,统一即可)
-
同一层级缩进一致,子元素比父元素多一级
user:
name: Bob
age: 30
address:
city: Beijing
street: Main Rd
3. 注释语法
- 单行注释:
#开头(无多行注释,每行加#)
# 用户信息
user:
name: Charlie
二、核心数据类型
1. 键值对(Map)
- 语法:
key: value(冒号后必须空格),支持嵌套
# 单层
title: YAML Guide
version: 1.0
is_active: true
# 嵌套
config:
server: {host: localhost; port:8080}
database: {name: test_db; username:root}
2. 列表(List)
- 语法:
- 列表项(短横线后必须空格),支持嵌套 / 紧凑写法
# 紧凑写法
colors: [red, green, blue]
# 基础列表
fruits: [- apple; - banana; - orange]
# 嵌套列表
students:
- name: Alice; age:20; courses: [- Math; - English]
- name: Bob; age:21; courses: [- Physics; - Chemistry]
3. 字符串(String)
| 类型 | 特点 | 示例 |
|---|---|---|
| 无引号 | 自动转义\n | simple_str: hello yaml |
单引号' | 不转义,原样保留 | ‘He said: “Hello\nWorld”’ |
双引号" | 支持转义(\n/\t) | “Line1\nLine2” |
| 多行字符串 | ` | 保留换行,>` 折叠 |
multi1: |
Line1; Line2
multi2: >
Line1 Line2(换行变空格)
4. 其他常用类型
- 数值:无需引号(整数 / 浮点数 / 科学计数)
count: 100
pi: 3.14
float: 2.5e3
- 布尔:
true/false(不区分大小写)
is_enabled:true
is_deleted:FALSE
- 空值:
null/~(或仅冒号无值)
empty1: null
empty2: ~;
empty3:
- 日期时间(ISO 8601)
birth: 2000-01-01
time: 14:30:00
create: 2024-05-20T10:00:00+08:00
四、常见错误 & 注意事项
-
缩进错误:混合 Tab / 空格、缩进不统一
-
符号缺空格:
key:value(错)、-item(错) -
特殊字符未引:含
:/#/[]的字符串需加引号 -
结构混用:同一层级同时用
-和key:
五、完整示例(综合版)
---
application: {name:YAML Demo; ver:2.1.0; is_prod:false; date:2024-05-01}
service_config:
base_port: &p 9000; timeout:&t 15s
services:
- name:api-service; port:*p; timeout:*t
endpoints: [/api/v1/users, /api/v1/orders]
logs: |
/var/log/api/error.log
/var/log/api/access.log
- name:web-service; port:9001; timeout:30s
env: [DB_HOST=localhost, DB_PORT=3306]
backup_config: {last_backup:null; path:~}
...
TOML文件
- 一种简洁、易读、面向配置文件的标记语言
- 设计目标是平衡“人类可读性”与“机器可解析性”
- 避免 YAML 的缩进陷阱和 JSON 对注释的缺失。。
一、基础规则
在学习具体语法前,需掌握所有 TOML 文档的通用规则:
- 编码格式:必须使用 UTF-8 编码(无 BOM)。
- 大小写敏感:键名、类型(如
true/false)、日期格式等均区分大小写(例如True不是有效的布尔值)。 - 注释:
- 单行注释:使用
#,从#到行尾的内容均为注释(示例:# 这是一条注释)。 - 无多行注释:需每行单独加
#。
- 单行注释:使用
- 空白字符:
- 空格(
\t)可作为分隔符或缩进(缩进仅为可读性,无语法意义)。 - 空行(仅含空白字符的行)会被忽略。
- 空格(
- 换行符:支持
\n(Unix/Linux)、\r\n(Windows)、\r(旧 Mac),推荐使用\n。
二、核心数据类型
TOML 支持 8 种基础数据类型,每种类型有明确的语法规则,以下按使用频率排序:
1. 字符串(String)
字符串是最常用的类型,支持 4 种写法,满足不同场景需求:
| 类型 | 语法格式 | 特点 | 示例 |
|---|---|---|---|
| 基本字符串 | 用双引号 " 包裹 | 支持转义字符(如 \n、\") | "Hello\nWorld" → 解析后含换行 |
| 多行基本字符串 | 用 """"""(6个双引号)包裹 | 保留换行和空格,支持转义 | """"""Line 1\nLine 2"""""" |
| 字面字符串 | 用单引号 ' 包裹 | 不支持转义,原样保留内容 | 'C:\Users\Tom' → 无需转义 \ |
| 多行字面字符串 | 用 ''''''(6个单引号)包裹 | 保留所有内容(含换行、空格、特殊字符) | ''''''He said "Hi!"'''''' |
-
特殊说明:多行字符串的起始
""""""/''''''可单独占一行(推荐,增强可读性),例如:multi_line = """ 这是第一行 这是第二行(末尾的换行也会被保留) """
2. 整数(Integer)
表示无小数部分的数值,支持多种进制和格式:
- 十进制:直接写数字(可带正负号),示例:
age = 25、temperature = -10。 - 二进制:前缀
0b,示例:binary = 0b1010(等于十进制 10)。 - 八进制:前缀
0o,示例:octal = 0o12(等于十进制 10)。 - 十六进制:前缀
0x,支持大小写字母,示例:hex = 0xA(等于十进制 10)、hex2 = 0xff(等于十进制 255)。 - 下划线分隔:可在数字中插入
_提升可读性(仅用于分隔,不影响数值),示例:population = 7_800_000_000。
3. 浮点数(Float)
表示带小数部分的数值,支持科学计数法:
- 标准格式:
整数部分.小数部分,示例:pi = 3.14159、weight = 62.5。 - 科学计数法:用
e或E表示指数(指数部分可带正负号),示例:speed = 3e8(等于 300000000)、tiny = 1.23e-4(等于 0.000123)。 - 特殊浮点数:
- 正无穷:
inf或+inf - 负无穷:
-inf - 非数(NaN):
nan或+nan/-nan(大小写不敏感,如NaN也有效)
- 正无穷:
- 下划线分隔:同整数,示例:
distance = 1_234.567_89。
4. 布尔值(Boolean)
表示“真”或“假”,必须小写:
- 真值:
true - 假值:
false - 错误示例:
True、FALSE均无效。
5. 日期时间(Date & Time)
TOML 严格遵循 ISO 8601 标准,支持 4 种时间精度,格式固定(不可随意修改):
| 类型 | 语法格式 | 示例 |
|---|---|---|
| 日期(Date) | YYYY-MM-DD | birthday = 1990-01-01 |
| 时间(Time) | HH:MM:SS 或 HH:MM:SS.sss(毫秒) | start_time = 08:30:00、precise = 14:59:59.999 |
| 日期时间(本地) | YYYY-MM-DDTHH:MM:SS(T 分隔) | meeting = 2024-05-20T14:30:00 |
| 日期时间(UTC) | 本地格式 + Z 后缀 | deadline = 2024-05-31T23:59:59Z |
- 注意:
T是日期和时间的强制分隔符,不可用空格代替;UTC 时间的Z后缀必须大写。
6. 数组(Array)
有序的同类型(推荐)或不同类型元素集合,用方括号 [] 包裹:
-
基础语法:元素用逗号
,分隔,末尾可加逗号(允许 trailing comma)。fruits = ["apple", "banana", "orange"] # 字符串数组 numbers = [1, 2, 3, 4] # 整数数组 mixed = [1, "two", true] # 混合类型数组(语法允许,但不推荐) -
多行数组:可换行书写,缩进不影响语法,示例:
colors = [ "red", "green", "blue", # 末尾逗号允许 ] -
嵌套数组:数组内可包含其他数组(多维数组),示例:
matrix = [ [1, 2, 3], [4, 5, 6], ]
三、结构类型(组织数据的方式)
TOML 通过“表”和“数组表”实现层级结构,替代 JSON 的“对象”和“对象数组”。
1. 表(Table):对应 JSON 对象
表是 键值对的集合,用 [表名] 定义(称为“表头”),作用是将相关键值对分组,避免键名冲突。
1.1 基础表(单层表)
语法:[表名],表名由字母、数字、下划线、连字符(-)组成,示例:
# 基础表:存储用户信息
[user]
name = "Alice"
age = 30
email = "alice@example.com"
# 基础表:存储配置信息
[config]
theme = "dark"
notifications = true
-
解析为 JSON 等价于:
{ "user": { "name": "Alice", "age": 30, "email": "alice@example.com" }, "config": { "theme": "dark", "notifications": true } }
1.2 嵌套表(多层表)
有两种写法,用于表示多层级结构:
-
显式嵌套:通过
.分隔表名,示例:# 嵌套表:user 的地址信息(等价于 user.address) [user.address] city = "Beijing" street = "Main Street" zipcode = "100000" -
隐式嵌套:先定义父表,再定义子表(与显式效果一致),示例:
[user] name = "Bob" [user.address] # 隐
markdown
以下是常用的 Markdown 语法,按功能分类整理,方便快速查阅和使用:
一、标题
使用 # 表示,# 数量对应标题级别(1-6级),# 后需加空格。
# 一级标题
## 二级标题
### 三级标题
#### 四级标题
##### 五级标题
###### 六级标题
二、文本格式
-
加粗:用
**或__包裹文本**这是加粗文本** __这也是加粗文本__ -
斜体:用
*或_包裹文本*这是斜体文本* _这也是斜体文本_ -
加粗+斜体:用
***包裹文本***这是加粗且斜体的文本*** -
删除线:用
~~包裹文本~~这是带删除线的文本~~ -
下划线:用
<u>标签(部分编辑器支持)<u>这是带下划线的文本</u> -
高亮:用
==包裹(部分编辑器支持,如 Typora)==这是高亮文本==
三、列表
有序列表
用数字 + 英文句号 + 空格 表示
1. 第一项
2. 第二项
3. 第三项
无序列表
用 -、* 或 + + 空格 表示(可混用)
- 项目一
* 项目二
+ 项目三
嵌套列表
子列表前加 4 个空格或 1 个制表符(Tab)
- 父项 1
- 子项 1.1
- 子项 1.2
- 父项 2
1. 子项 2.1
2. 子项 2.2
四、链接
基础链接
格式:[显示文本](链接地址 "可选标题")(标题 hover 时显示)
[百度](https://www.baidu.com "访问百度")
引用链接
先定义链接标识,再引用(适合重复使用同一链接)
[谷歌][g]
[必应][b]
[g]: https://www.google.com
[b]: https://www.bing.com
自动链接
用 <> 包裹网址或邮箱,自动识别为链接
<https://www.github.com>
<example@mail.com>
五、图片
格式与链接类似,前缀加 !:

引用式图片:
![风景图][img1]
[img1]: https://picsum.photos/400/200
六、引用
用 > 表示,可嵌套(多组 >)
> 这是一级引用
>> 这是二级引用(嵌套在一级内)
> 回到一级引用
七、代码
行内代码
用 `(反引号)包裹
使用 `print()` 函数输出内容
代码块
用 3 个反引号 ``` 包裹,可指定语言(实现语法高亮)
```python
def hello():
print("Hello, Markdown!")
也可用 4 个空格或 1 个制表符缩进(不支持指定语言):
# 这是 Python 代码
x = 10
print(x)
### 八、表格
用 `|` 分隔列,`-` 分隔表头和内容,`:` 控制对齐方式(左对齐 `:-`、右对齐 `-:`、居中 `:-:`)
```markdown
| 姓名 | 年龄 | 职业 |
| :--- | ---: | :----: |
| 张三 | 25 | 工程师 |
| 李四 | 30 | 设计师 |
效果:
| 姓名 | 年龄 | 职业 |
|---|---|---|
| 张三 | 25 | 工程师 |
| 李四 | 30 | 设计师 |
九、分隔线
用 3 个及以上 -、* 或 _(可加空格)
---
***
___
十、脚注
用 [^标识] 定义,文末说明内容
这是一段需要注释的文本[^1]
[^1]: 这里是脚注的具体内容
十一、任务列表
用 - [ ] 表示未完成,- [x] 表示已完成(x 不区分大小写)
- [x] 完成 Markdown 语法学习
- [ ] 练习实际应用
- [ ] 总结技巧
十二、数学公式(部分编辑器支持,如 Typora、GitHub)
行内公式
用 $ 包裹
勾股定理:$a^2 + b^2 = c^2$
块级公式
用 $$ 包裹(自动居中)
$$
\sum_{i=1}^n i = \frac{n(n+1)}{2}
$$
注意事项
- 语法后建议加空格(如标题、列表),增强兼容性。
- 不同编辑器对部分语法(如高亮、数学公式)支持有差异,需根据工具调整。
标准化语法
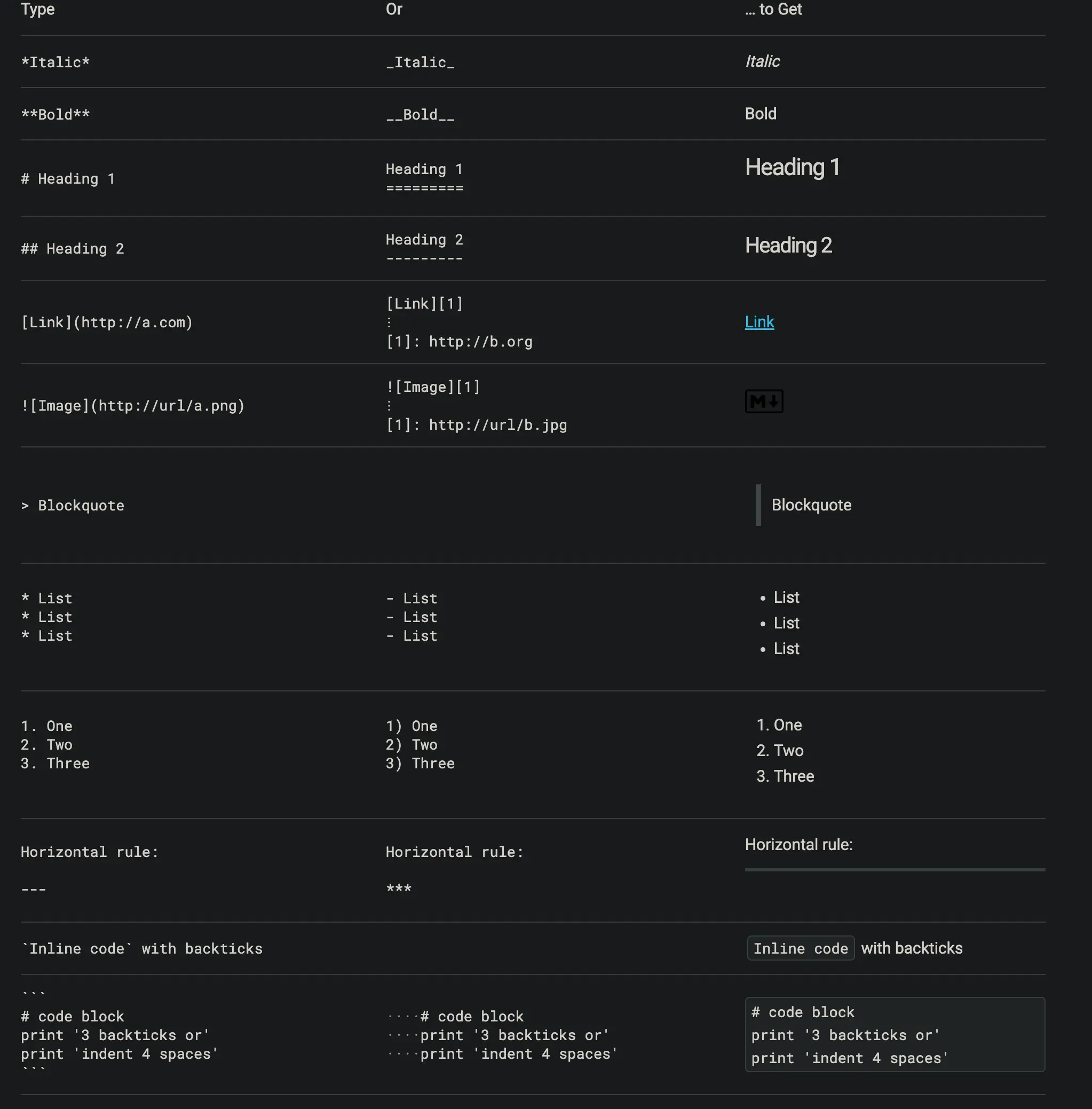
github的扩展GFM
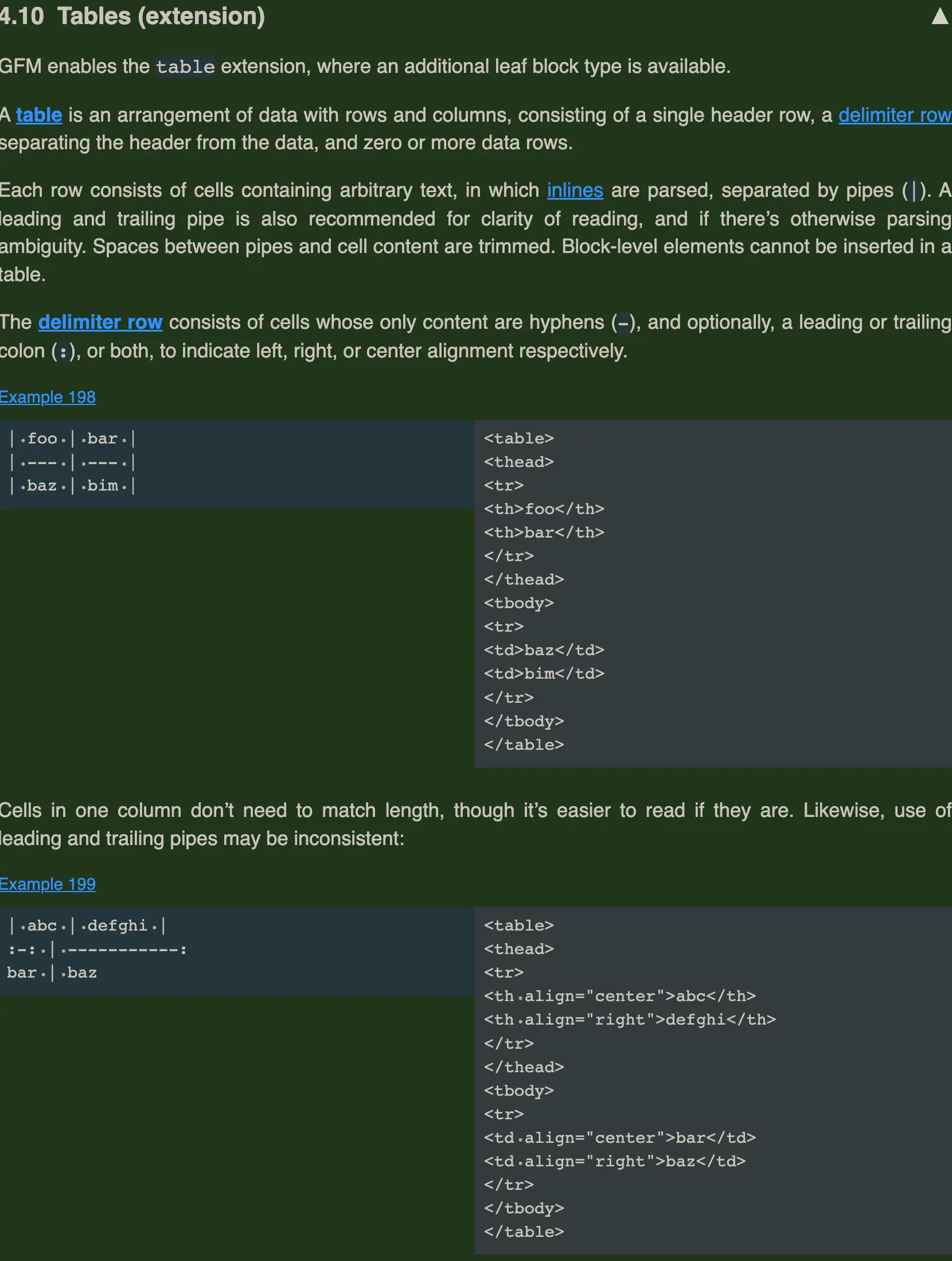
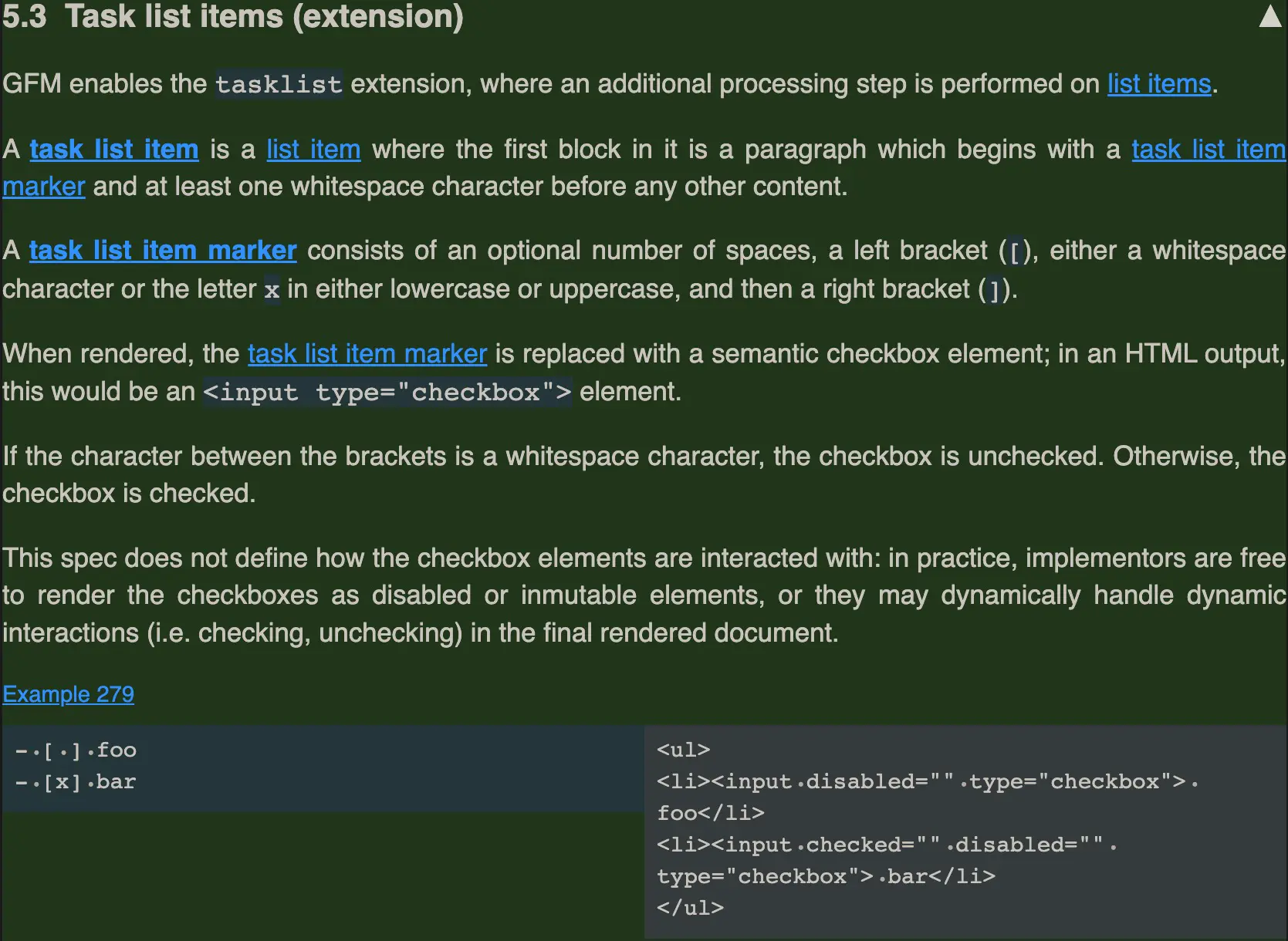
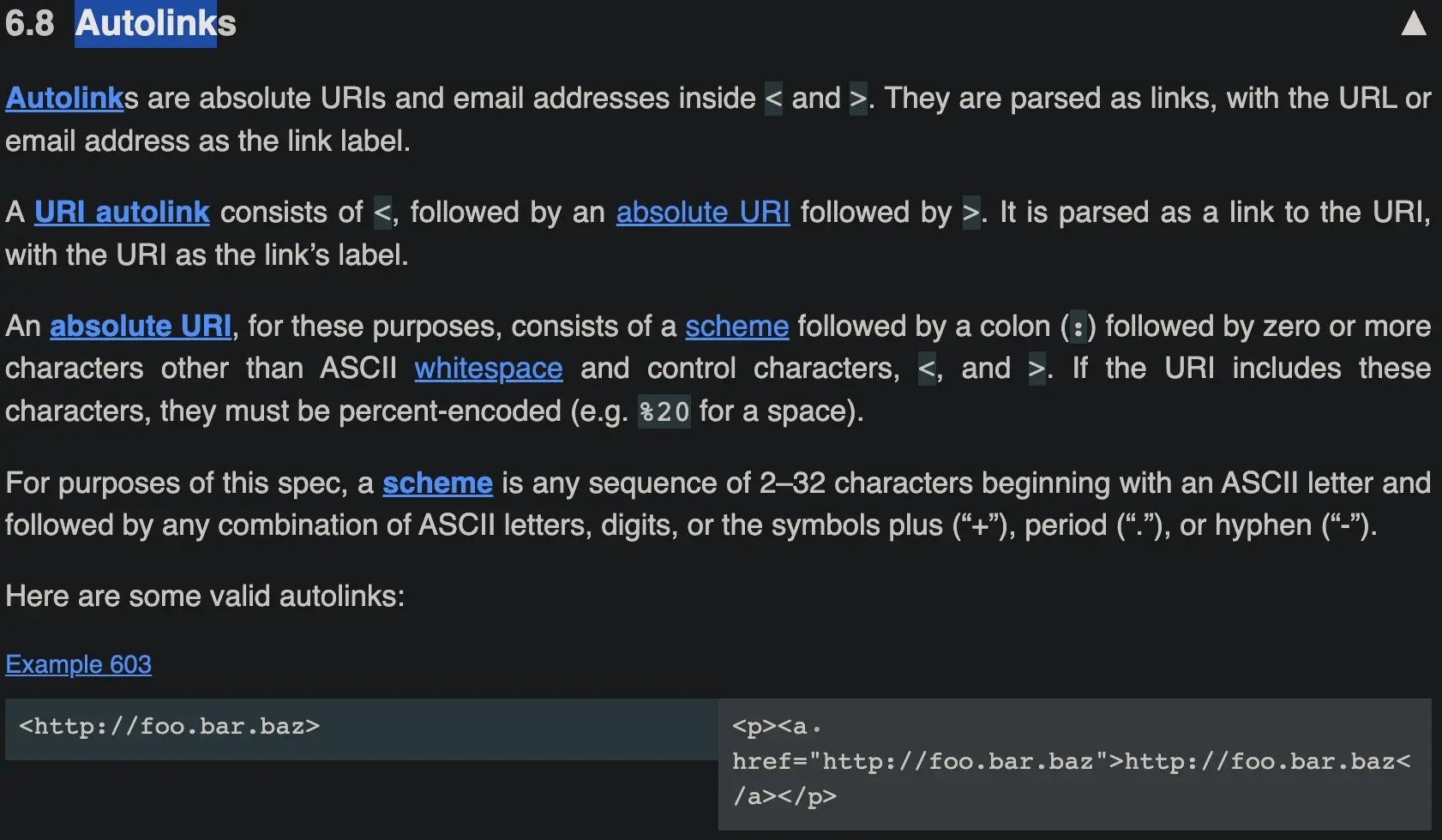
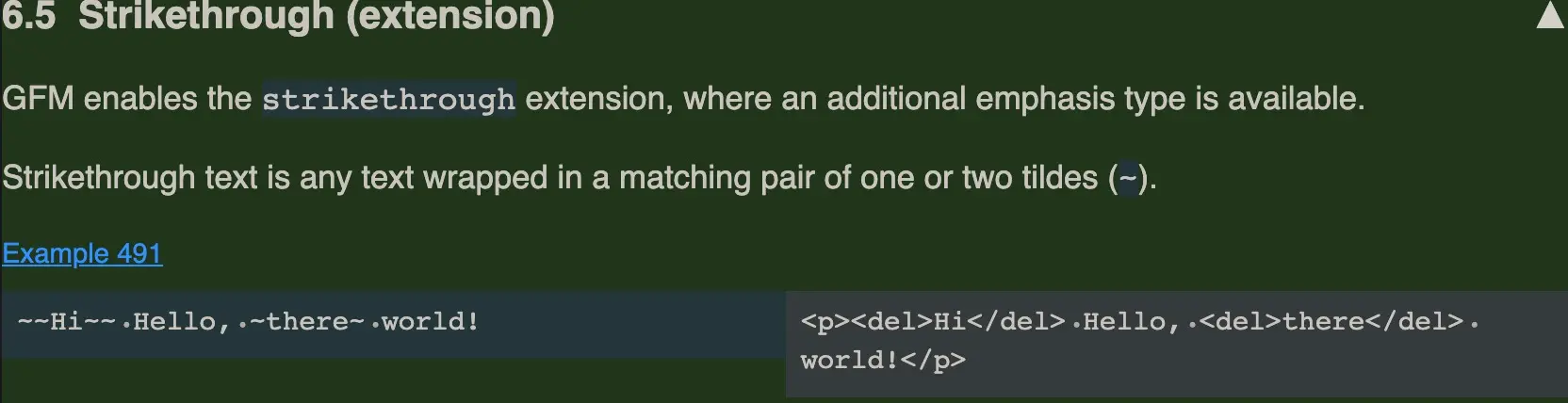
表情符号网站
笔记
- emoji表情符号
:smile:
-
+1 -
🍎
-
<www.baidu.com>
-
gitbook写书工具,有各种插件
-
markdown here写邮件
-
pandoc 不同标记语言间格式转换工具
-
markdown有工具直接生成ppt
-
有工具可以把markdown转成微信公众号需要的格式
-
石墨文档,腾讯文档,语雀文档在线多人协作工具
-
gitbook写书工具,有各种插件
-
mkdocs,python开发的静态站点生成器
PDF 文件结构详解与示例
一、PDF 文件的核心结构
PDF(Portable Document Format,便携文档格式)是跨平台结构化二进制格式,核心目标是 “保持文档原始排版不变”,其结构由顶层四大组件和内容层级体系构成,解析器按固定逻辑读取。
(一)顶层结构:解析器的 “导航地图”
graph LR;
A(文件头 Header)-->B(文件体 Body);
B-->C(交叉引用表 XRef);
C-->D(文件尾 Trailer);
D-->E(EOF标记);
1. 文件头(Header):身份标识
-
作用:声明 PDF 版本、区分文本文件,避免解析器误判。
-
格式:首行
%PDF-版本号(如%PDF-1.7,主流版本 1.7/2.0),后接 1-4 个非 ASCII 字符(如%âãÏÓ)验证二进制解析支持。 -
版本兼容性:高版本(如 1.7)可能含低版本(如 1.5)不支持特性(如透明图层),解析器依版本启用兼容模式。
2. 文件体(Body):内容核心
存储所有文档内容(文本、图像、字体等),最小单元为 “对象”,结构 =“多个对象 + 自由对象链表”。
(1)对象分类:间接对象与直接对象
| 类型 | 定义 | 结构特征 | 用途 |
|---|---|---|---|
| 间接对象 | 可全局引用的独立对象 | 对象号 生成号 obj ... endobj | 存储页面、字体等核心资源 |
| 直接对象 | 嵌入其他对象,不可单独引用 | 无固定标记,直接作为值存在 | 字典键值、数组元素(如页面大小) |
- 间接对象示例(页面对象):
3 0 obj % 对象号=3,生成号=0(未修改)
<< /Type /Page % 类型为“页面”
  /Parent 2 0 R % 引用对象2(Pages节点)
  /MediaBox \[0 0 612 792] % A4尺寸(8.5×11英寸,1英寸=72点)
  /Contents 4 0 R % 引用对象4(内容流)
  /Resources << /Font << /F1 5 0 R >> >> % 引用对象5(字体)
\>>
endobj
注:2 0 R为间接引用格式(对象号 生成号 R,R=Reference)。
(2)核心对象类型(8 种)
| 对象类型 | 格式示例 | 用途说明 |
|---|---|---|
| 字典(Dict) | << /Key1 Value1 /Key2 Value2 >> | 存储结构化数据(页面属性、资源列表) |
| 数组(Array) | [1 2 3 /Name (String)] | 存储有序集合(页面列表、坐标) |
| 流(Stream) | << /Length 100 >> stream ... endstream | 存储二进制数据(图像、字体) |
| 字符串(String) | (Hello PDF) 或 <48656C6C6F> | 存储文本(括号明文,尖括号十六进制) |
| 名称(Name) | /Type 或 /Font | 标识字典键(/ 开头,区分大小写) |
| 数字(Number) | 123 或 -45.6 | 存储数值(坐标、字体大小) |
| 布尔值(Boolean) | true 或 false | 存储逻辑值(是否显示注释) |
| 空值(Null) | null | 表示无值(未定义资源) |
- 流对象特殊说明:需与字典配合,字典含
/Length(流字节数)和/Filter(压缩算法,如/FlateDecode)。
3. 交叉引用表(XRef):快速定位工具
记录所有间接对象的 “文件偏移量”(字节位置),避免解析器逐行扫描,格式如下:
xref
0 6 % 段1:起始对象号=0,条目数=6(对象0\~5)
0000000000 65535 f % 对象0:偏移0,生成号65535,f=自由对象
0000000010 00000 n % 对象1:偏移10,生成号0,n=已使用对象
-
对象号 0:特殊条目,指向自由对象链表,供修改时复用。
-
偏移量:对象在文件中的字节位置,解析器可直接跳转。
4. 文件尾(Trailer)与 EOF 标记:解析入口
解析器优先读取文件末尾的 EOF 标记,再通过 Trailer 找到核心信息。
- Trailer 格式:
trailer
<< /Size 6 % XRef总条目数
  /Root 1 0 R % 文档根对象(Catalog)引用
  /Info 6 0 R % 元数据引用(可选)
  /Encrypt null % 加密信息(null=未加密,可选)
\>>
startxref
512 % XRef偏移量(文件中XRef的字节位置)
%%EOF % EOF标记(必选,缺失则文件损坏)
- 核心关键字:
/Size(XRef 条目数)、/Root(Catalog 引用,内容入口)、/Encrypt(加密开关)。
(二)内容层级结构:从根到页面
解析器通过 Trailer 找到/Root(Catalog)后,按Catalog → Pages Tree → Page → Contents/Resources读取内容,高效管理页面。
1. 文档目录(Catalog):内容总入口
字典对象,含所有顶级内容引用,核心关键字:
| 关键字 | 用途 | 示例值 |
|---|---|---|
/Type | 声明类型为 Catalog | /Catalog |
/Pages | 指向 Pages Tree 根节点 | 2 0 R |
/Outlines | 指向文档大纲(可选) | 7 0 R |
/AcroForm | 指向表单(可选) | 8 0 R |
2. 页面树(Pages Tree):页面管理体系
树形结构(Pages节点→Page节点),高效处理多页面:
- Pages 节点:页面组,含子 Pages/Page 节点,关键字
/Kids(子节点列表)、/Count(子节点总数),示例:
2 0 obj
<< /Type /Pages
  /Kids \[3 0 R 10 0 R] % 2个子Page节点(对象3、10)
  /Count 2 % 总页数2
\>>
endobj
-
Page 节点:具体页面,含大小、内容流、资源(见前文间接对象示例)。
-
优势:插入 / 删除页面仅修改
/Kids列表,无需移动所有页面对象。
3. 页面内容(Contents):文本与图形指令
Page 节点的/Contents指向内容流(Stream 对象),含 PostScript 风格指令,示例(文本绘制):
4 0 obj
<< /Length 128 /Filter /FlateDecode >>
stream
BT % 开始文本模式(Begin Text)
/F1 12 Tf % 字体F1,字号12
100 700 Td % 文本位置(X=100,Y=700,左下角为原点)
(Hello, PDF!) Tj % 绘制文本(Tj=Text Show)
ET % 结束文本模式
endstream
endobj
- 指令规则:操作数 + 运算符(如
12 Tf,12 = 操作数,Tf = 运算符)。
4. 页面资源(Resources):依赖 “素材库”
Page 节点的/Resources字典存储字体、图像等资源,避免重复,示例:
<< /Font << /F1 5 0 R >> % 字体F1引用对象5
  /XObject << /Img1 11 0 R >> % 图像Img1引用对象11
\>>
-
字体资源:存储字体描述和字形数据,确保跨平台一致(如
TrueTypeFont含/FontFile2)。 -
图像资源:
XObject形式,含尺寸(/Width//Height)、压缩算法(如 JPEG 用/DCTDecode)。
(三)PDF 关键特性与结构关联
-
跨平台兼容性:依赖 “资源内嵌” 和 “设备无关坐标系”(点为单位,1 点 = 1/72 英寸)。
-
增量更新:修改时追加新对象、XRef 段和 Trailer,旧对象标记为自由,体积可能增大。
-
损坏修复:XRef/Trailer 损坏时,工具可扫描
obj/endobj重建,核心是找到 Catalog 和 Pages 节点。 -
加密保护:
/Encrypt字典存储算法(如 AES-256)和权限(禁止打印 / 修改),解密后可读内容。
二、简单 PDF 文件结构示例与拆解
以下为合法极简 PDF 示例,可保存为.pdf文件直接打开,结构完整且适合打印参考。
(一)完整示例代码
%PDF-1.7
%âãÏÓ
% 对象1:文档信息字典
1 0 obj
<< /Title (Simple PDF Example) /Author (PDF Learner) /CreationDate (D:20240501120000+08'00') >>
endobj
% 对象2:Pages节点(页面树父节点)
2 0 obj
<< /Type /Pages /Count 1 /Kids \[3 0 R] >>
endobj
% 对象3:Page节点(第1页)
3 0 obj
<< /Type /Page /Parent 2 0 R /MediaBox \[0 0 612 792]
  /Resources << /Font << /F1 << /Type /Font /Subtype /Type1 /BaseFont /Helvetica >> >> >>
  /Contents 5 0 R >>
endobj
% 对象4:内容流长度字典
4 0 obj
<< /Length 88 >>
endobj
% 对象5:内容流(绘制文本)
5 0 obj
<< /Filter /FlateDecode /Length 4 0 R >>
stream
1 0 0 1 100 600 cm /F1 24 Tf (Hello, Simple PDF!) Tj
endstream
endobj
% 交叉引用表
xref
0 6
0000000000 65535 f
0000000015 00000 n
0000000173 00000 n
0000000279 00000 n
0000000625 00000 n
0000000666 00000 n
% 文件尾与EOF
trailer
<< /Size 6 /Root 2 0 R /Info 1 0 R >>
startxref
786
%%EOF
(二)示例结构拆解
| 组成部分 | 核心作用 | 示例关键内容 |
|---|---|---|
| 文件头 | 声明版本 + 校验,识别 PDF 文件 | %PDF-1.7 + %âãÏÓ |
| 文件体 | 存储对象(元数据、页面树、页面、资源、内容流) | 5 个对象:信息字典(1)、Pages 节点(2)、Page 节点(3)、长度字典(4)、内容流(5) |
| 交叉引用表 | 记录对象偏移量,快速定位 | xref下条目(如对象 1 偏移 15 字节,对象 5 偏移 666 字节) |
| 文件尾 | 定义解析入口(根对象) | Root 2 0 R(加载 Pages 节点 2)、Info 1 0 R(关联元数据) |
| EOF 标记 | 标记文件结束,避免无效读取 | %%EOF(必选,无则损坏) |
(三)关键注意事项
-
对象引用格式:统一为
对象号 版本号 R(如3 0 R,版本 0 为默认)。 -
内容流匹配:
/Length需与实际内容字节数一致,否则内容损坏。 -
页面树必需:PDF 需通过
Pages→Page树形管理页面,不可直接罗列页面。
原生与扫描件
- 原生PDF是指由可编辑文档( Word、Txt等格式)创建的PDF,只要有权限是能转为可编辑文字的。
- 扫描件是通过扫描的方式把文档扫描成图片格式后保存为PDF格式,扫描PDF本质上属于图像PDF,无法直接提取其中的文字。
mermaid-美人鱼示例
Flowchart
graph TD;
A-->B;
A-->C;
B-->D;
C-->D;
graph TD;
A-->B;
A-->C;
B-->D;
C-->D;
Sequence diagram
sequenceDiagram
participant Alice
participant Bob
Alice->>John: Hello John, how are you?
loop Healthcheck
John->>John: Fight against hypochondria
end
Note right of John: Rational thoughts <br/>prevail!
John-->>Alice: Great!
John->>Bob: How about you?
Bob-->>John: Jolly good!
sequenceDiagram
participant Alice
participant Bob
Alice->>John: Hello John, how are you?
loop Healthcheck
John->>John: Fight against hypochondria
end
Note right of John: Rational thoughts <br/>prevail!
John-->>Alice: Great!
John->>Bob: How about you?
Bob-->>John: Jolly good!
pie
pie
title Key elements in Product X
"Calcium" : 42.96
"Potassium" : 50.05
"Magnesium" : 10.01
"Iron" : 5
pie
title Key elements in Product X
"Calcium" : 42.96
"Potassium" : 50.05
"Magnesium" : 10.01
"Iron" : 5
mindmap
mindmap
Root
A
B
C
mindmap
Root
A
B
C
mindmap
root((mindmap))
Origins
Long history
::icon(fa fa-book)
Popularisation
British popular psychology author Tony Buzan
Research
On effectiveness<br/>and features
On Automatic creation
Uses
Creative techniques
Strategic planning
Argument mapping
Tools
Pen and paper
Mermaid
mindmap
root((mindmap))
Origins
Long history
::icon(fa fa-book)
Popularisation
British popular psychology author Tony Buzan
Research
On effectiveness<br/>and features
On Automatic creation
Uses
Creative techniques
Strategic planning
Argument mapping
Tools
Pen and paper
Mermaid
timeline
timeline
title 时间图
2002 : LinkedIn
2004 : Facebook
: Google
2005 : Youtube
2006 : Twitter
timeline
title 时间图
2002 : LinkedIn
2004 : Facebook
: Google
2005 : Youtube
2006 : Twitter
timeline
title MermaidChart 2023 Timeline
section 2023 Q1 <br> Release Personal Tier
Buttet 1 : sub-point 1a : sub-point 1b
: sub-point 1c
Bullet 2 : sub-point 2a : sub-point 2b
section 2023 Q2 <br> Release XYZ Tier
Buttet 3 : sub-point <br> 3a : sub-point 3b
: sub-point 3c
Bullet 4 : sub-point 4a : sub-point 4b
timeline
title MermaidChart 2023 Timeline
section 2023 Q1 <br> Release Personal Tier
Buttet 1 : sub-point 1a : sub-point 1b
: sub-point 1c
Bullet 2 : sub-point 2a : sub-point 2b
section 2023 Q2 <br> Release XYZ Tier
Buttet 3 : sub-point <br> 3a : sub-point 3b
: sub-point 3c
Bullet 4 : sub-point 4a : sub-point 4b
journey
journey
title My working day
section Go to work
Make tea: 5: Me
Go upstairs: 3: Me
Do work: 1: Me, Cat
section Go home
Go downstairs: 5: Me
Sit down: 5: Me
journey
title My working day
section Go to work
Make tea: 5: Me
Go upstairs: 3: Me
Do work: 1: Me, Cat
section Go home
Go downstairs: 5: Me
Sit down: 5: Me
Gantt diagram
gantt
dateFormat YYYY-MM-DD
title Adding GANTT diagram to mermaid
excludes weekdays 2014-01-10
section A section
Completed task :done, des1, 2014-01-06,2014-01-08
Active task :active, des2, 2014-01-09, 3d
Future task : des3, after des2, 5d
Future task2 : des4, after des3, 5d
gantt dateFormat YYYY-MM-DD title Adding GANTT diagram to mermaid excludes weekdays 2014-01-10 section A section Completed task :done, des1, 2014-01-06,2014-01-08 Active task :active, des2, 2014-01-09, 3d Future task : des3, after des2, 5d Future task2 : des4, after des3, 5d
Git graph
gitGraph:
options
{
"nodeSpacing": 150,
"nodeRadius": 10
}
end
commit
branch newbranch
checkout newbranch
commit
commit
checkout main
commit
commit
merge newbranch
gitGraph:
options
{
"nodeSpacing": 150,
"nodeRadius": 10
}
end
commit
branch newbranch
checkout newbranch
commit
commit
checkout main
commit
commit
merge newbranch
Class diagram
classDiagram
Class01 <|-- AveryLongClass : Cool
Class03 *-- Class04
Class05 o-- Class06
Class07 .. Class08
Class09 --> C2 : Where am i?
Class09 --* C3
Class09 --|> Class07
Class07 : equals()
Class07 : Object[] elementData
Class01 : size()
Class01 : int chimp
Class01 : int gorilla
Class08 <--> C2: Cool label
classDiagram Class01 <|-- AveryLongClass : Cool Class03 *-- Class04 Class05 o-- Class06 Class07 .. Class08 Class09 --> C2 : Where am i? Class09 --* C3 Class09 --|> Class07 Class07 : equals() Class07 : Object[] elementData Class01 : size() Class01 : int chimp Class01 : int gorilla Class08 <--> C2: Cool label
Entity Relationship Diagram
erDiagram
CUSTOMER ||--o{ ORDER : places
ORDER ||--|{ LINE-ITEM : contains
CUSTOMER }|..|{ DELIVERY-ADDRESS : uses
erDiagram
CUSTOMER ||--o{ ORDER : places
ORDER ||--|{ LINE-ITEM : contains
CUSTOMER }|..|{ DELIVERY-ADDRESS : uses
User Journey Diagram
journey
title My working day
section Go to work
Make tea: 5: Me
Go upstairs: 3: Me
Do work: 1: Me, Cat
section Go home
Go downstairs: 5: Me
Sit down: 5: Me
journey
title My working day
section Go to work
Make tea: 5: Me
Go upstairs: 3: Me
Do work: 1: Me, Cat
section Go home
Go downstairs: 5: Me
Sit down: 5: Me
State diagrams
stateDiagram-v2
[*] --> Still
Still --> [*]
Still --> Moving
Moving --> Still
Moving --> Crash
Crash --> [*]
stateDiagram-v2
[*] --> Still
Still --> [*]
Still --> Moving
Moving --> Still
Moving --> Crash
Crash --> [*]
Kubernetes
1. YAML 文件基础结构
Kubernetes YAML文件通常包含以下顶级字段:
apiVersion: <版本> # 指定API版本
kind: <资源类型> # 指定资源类型(Pod, Deployment, Service等)
metadata: # 元数据
name: <名称>
labels: # 标签
key: value
spec: # 资源规格定义
# 资源特定配置
2. 核心组件详解
2.1 apiVersion
指定Kubernetes API版本,常见值包括:
v1- 核心API组(Pod, Service, Node等)apps/v1- 工作负载API组(Deployment, StatefulSet等)networking.k8s.io/v1- 网络API组(Ingress等)batch/v1- 批处理API组(Job, CronJob等)
2.2 kind
定义资源类型,常见类型包括:
- 工作负载资源:Pod, Deployment, StatefulSet, DaemonSet, Job, CronJob
- 服务发现:Service, Ingress
- 配置与存储:ConfigMap, Secret, PersistentVolume, PersistentVolumeClaim
- 策略:ResourceQuota, LimitRange
- 元数据:Namespace, Node
2.3 metadata
包含资源的元数据:
name: 资源名称(在namespace内唯一)namespace: 命名空间(默认为default)labels: 键值对标签,用于选择器annotations: 键值对注释,用于非标识性元数据
2.4 spec
定义资源的期望状态,具体内容因资源类型而异。
3. 常见资源类型示例
3.1 Pod 示例
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
resources:
requests:
cpu: "100m"
memory: "128Mi"
limits:
cpu: "500m"
memory: "512Mi"
3.2 Deployment 示例
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 30
periodSeconds: 10
3.3 Service 示例
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: ClusterIP # 或 NodePort, LoadBalancer
3.4 ConfigMap 示例
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
data:
APP_COLOR: blue
APP_MODE: production
config.json: |
{
"debug": false,
"logging": "info"
}
3.5 Secret 示例 (base64编码)
apiVersion: v1
kind: Secret
metadata:
name: db-secret
type: Opaque
data:
username: dXNlcm5hbWU= # "username"的base64编码
password: cGFzc3dvcmQ= # "password"的base64编码
4. 高级特性
4.1 探针(Probes)
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
4.2 资源限制与请求
resources:
requests:
cpu: "500m"
memory: "512Mi"
limits:
cpu: "1"
memory: "1Gi"
4.3 卷挂载
volumes:
- name: config-volume
configMap:
name: app-config
- name: secret-volume
secret:
secretName: db-secret
containers:
- name: app
volumeMounts:
- name: config-volume
mountPath: /etc/config
- name: secret-volume
mountPath: /etc/secrets
readOnly: true
4.4 环境变量
env:
- name: ENV_VAR
value: "value"
- name: CONFIG_VAR
valueFrom:
configMapKeyRef:
name: app-config
key: APP_COLOR
- name: SECRET_VAR
valueFrom:
secretKeyRef:
name: db-secret
key: username
5. 最佳实践
- 使用标签和选择器:合理使用标签组织资源,便于管理和选择
- 资源限制:始终为容器设置资源请求和限制
- 探针配置:配置适当的存活和就绪探针
- 配置与代码分离:使用ConfigMap和Secret管理配置
- 版本控制:将YAML文件纳入版本控制系统
- 模板化:使用Helm或Kustomize管理复杂配置
- 命名约定:采用一致的命名约定(如
<应用名>-<环境>-<组件>) - 最小权限:遵循最小权限原则配置RBAC
6. 常见问题排查
- 格式错误:确保YAML格式正确(缩进、引号等)
- API版本不匹配:检查集群支持的API版本
- 资源不足:检查节点资源是否足够
- 镜像拉取失败:检查镜像名称和拉取策略
- 权限问题:检查ServiceAccount和RBAC配置
- 端口冲突:确保服务端口不冲突
- 选择器不匹配:检查Deployment和Service的选择器是否一致
7. 工具推荐
- kubectl apply:部署和更新资源
- kubectl diff:查看变更差异
- kubeval:验证YAML语法
- Helm:包管理工具
- Kustomize:原生Kubernetes配置管理
- yq:YAML处理工具(类似jq)
通过合理编写和管理Kubernetes YAML文件,可以高效地部署和管理容器化应用,实现基础设施即代码(IaC)的实践。
dot简介
- 需要mdbook-graphviz插件支持
- 必须带上process参数,否则原样输出
docx文件
概念
docx 文件本质上是一个包含多个 XML 文件的 ZIP 压缩包
1. 顶层结构:文档包(Package)
- docx 逻辑结构:整个
.docx文件是一个「文档包」,包含所有组成文档的资源(XML 文件、图片、样式定义等),通过 ZIP 压缩格式存储。 - python-docx 对应:
Document对象
是操作的入口,代表整个文档。通过docx.Document()创建或打开文档,封装了对底层包的所有操作。
2. 内容容器:节(Section)
- docx 逻辑结构:文档包内的内容被划分为「节」(Section),每个节可以独立设置页面格式(如页边距、纸张大小、方向等)。默认情况下,文档至少包含 1 个节。
- python-docx 对应:
Section对象
通过doc.sections访问所有节(列表形式),例如doc.sections[0]获取第一个节。
3. 块级元素(Block-Level Elements)
节内包含的「块级元素」是文档的核心内容,按顺序排列,占据一整块区域(如段落、表格等)。
| docx 逻辑结构 | 说明 | python-docx 对应对象 | 访问方式示例 |
|---|---|---|---|
| 段落(Paragraph) | 文本内容的基本单元,可包含多个文本片段 | Paragraph | doc.paragraphs(所有段落) |
| 表格(Table) | 由行和列组成的结构化数据容器 | Table | doc.tables(所有表格) |
| 图片(Picture) | 嵌入文档的图像资源(本质上包含在段落中) | 无单独对象,通过段落插入 | doc.add_picture() |
| 分页符(Page Break) | 强制分页的标记 | 无单独对象,通过 Run 插入 | run.add_break(WD_BREAK.PAGE) |
4. 段落内部结构:运行(Run)
- docx 逻辑结构:段落(Paragraph)由一个或多个「运行」(Run)组成。每个 Run 是一段连续的、具有相同格式(字体、大小、颜色等)的文本。
- python-docx 对应:
Run对象
通过paragraph.runs访问段落内的所有 Run,例如para.runs[0]获取段落的第一个文本片段。
5. 表格内部结构
- docx 逻辑结构:表格(Table)由「行(Row)」和「单元格(Cell)」组成,单元格内可包含段落、文本等内容。
- python-docx 对应:
Table:表格对象,通过doc.add_table()创建。Row:表格行对象,通过table.rows访问。Cell:单元格对象,通过table.cell(row_idx, col_idx)或row.cells访问。
单元格内的内容通过cell.paragraphs访问(单元格本质上是段落的容器)。
6. 样式系统(Styles)
- docx 逻辑结构:包含「段落样式」「字符样式」等,用于统一文档格式,定义在
styles.xml中。 - python-docx 对应:
Style对象
通过doc.styles访问所有样式(列表形式),例如doc.styles['Heading 1']获取一级标题样式。
7. 页眉页脚(Header/Footer)
- docx 逻辑结构:每个节(Section)可包含独立的「页眉」和「页脚」,定义在
header.xml和footer.xml中,用于存放每页顶部/底部的固定内容(如页码、标题)。 - python-docx 对应:
Header和Footer对象
通过节对象访问:section.header(页眉)、section.footer(页脚),其内部内容通过header.paragraphs或footer.paragraphs操作。
8. 页面设置(Page Settings)
- docx 逻辑结构:定义节的页面属性(如页边距、纸张大小、方向等),存储在
settings.xml中。 - python-docx 对应:
Section对象的属性
例如:section.left_margin(左页边距)、section.page_width(页面宽度)、section.orientation(页面方向)等。
代码
一、基础操作:创建与保存文档
from docx import Document
# 1. 创建新文档
doc = Document()
# 2. 打开已有文档
doc = Document("existing.docx") # 仅支持 .docx 格式
# 3. 保存文档
doc.save("output.docx")
二、文本内容操作
1. 添加标题
# 添加标题(level:0-9,0 为最高级标题,1-9 逐级降低)
doc.add_heading("主标题", level=0)
doc.add_heading("一级标题", level=1)
doc.add_heading("二级标题", level=2)
2. 添加段落与文本片段
# 添加普通段落
para = doc.add_paragraph("这是一个普通段落。")
# 向段落添加带格式的文本片段(Run)
para = doc.add_paragraph("我是")
run = para.add_run("加粗文本")
run.bold = True # 加粗
para.add_run(",我是")
run = para.add_run("斜体文本")
run.italic = True # 斜体
para.add_run("。")
3. 设置文本格式(字体、大小、颜色等)
from docx.shared import Pt, RGBColor
para = doc.add_paragraph()
run = para.add_run("自定义格式文本")
run.font.name = "微软雅黑" # 字体
run.font.size = Pt(14) # 字号(14磅)
run.font.color.rgb = RGBColor(255, 0, 0) # 红色(RGB值)
run.underline = True # 下划线
run.font.bold = True # 加粗
三、段落格式设置
from docx.enum.text import WD_ALIGN_PARAGRAPH
from docx.shared import Inches
para = doc.add_paragraph("设置段落格式的示例文本")
# 1. 对齐方式(左对齐、居中、右对齐、两端对齐)
para.alignment = WD_ALIGN_PARAGRAPH.CENTER # 居中对齐
# 2. 缩进(左缩进、右缩进、首行缩进)
para.paragraph_format.left_indent = Inches(0.5) # 左缩进0.5英寸
para.paragraph_format.first_line_indent = Inches(0.3) # 首行缩进0.3英寸
# 3. 行间距与段间距
para.paragraph_format.line_spacing = 1.5 # 1.5倍行间距
para.paragraph_format.space_before = Pt(12) # 段前间距12磅
para.paragraph_format.space_after = Pt(6) # 段后间距6磅
四、列表操作
# 1. 无序列表(项目符号)
doc.add_paragraph("项目1", style="List Bullet")
doc.add_paragraph("项目2", style="List Bullet")
# 2. 有序列表(编号)
doc.add_paragraph("步骤1", style="List Number")
doc.add_paragraph("步骤2", style="List Number")
# 3. 嵌套列表(通过缩进实现)
para = doc.add_paragraph("主项目", style="List Bullet")
para = doc.add_paragraph("子项目", style="List Bullet 2") # 二级列表
para.paragraph_format.left_indent = Inches(0.5) # 缩进增强嵌套效果
五、表格操作
1. 创建表格并填充内容
# 创建3行2列的表格(可选指定样式)
table = doc.add_table(rows=3, cols=2, style="Table Grid")
# 填充表头
table.cell(0, 0).text = "姓名"
table.cell(0, 1).text = "年龄"
# 填充内容
table.cell(1, 0).text = "张三"
table.cell(1, 1).text = "25"
table.cell(2, 0).text = "李四"
table.cell(2, 1).text = "30"
2. 表格进阶操作
# 新增行/列
table.add_row() # 末尾新增一行
table.add_column(Inches(1.5)) # 新增一列(指定宽度)
# 合并单元格(合并第一行前两列)
cell1 = table.cell(0, 0)
cell2 = table.cell(0, 1)
cell1.merge(cell2)
# 单元格内设置文本格式(通过段落和Run)
cell = table.cell(1, 0)
run = cell.paragraphs[0].add_run("带格式的单元格文本")
run.bold = True
run.font.color.rgb = RGBColor(0, 0, 255) # 蓝色
六、插入图片
from docx.shared import Inches, Cm
# 插入图片(指定路径,可选宽度/高度,避免变形)
doc.add_picture("image.png", width=Inches(3)) # 宽度3英寸(高度自动按比例)
doc.add_picture("photo.jpg", height=Cm(5)) # 高度5厘米(宽度自动按比例)
七、页面设置
from docx.enum.section import WD_ORIENT
from docx.shared import Inches
# 获取第一个节(默认文档至少有一个节)
section = doc.sections[0]
# 1. 页边距(上、下、左、右)
section.top_margin = Inches(1.0)
section.bottom_margin = Inches(1.0)
section.left_margin = Inches(1.25)
section.right_margin = Inches(1.25)
# 2. 纸张大小(例如:A4纸 21cm×29.7cm)
section.page_width = Inches(8.27) # A4宽度(约8.27英寸)
section.page_height = Inches(11.69) # A4高度(约11.69英寸)
# 3. 页面方向(横向/纵向)
section.orientation = WD_ORIENT.LANDSCAPE # 横向(默认纵向:PORTRAIT)
八、页眉页脚与页码
# 获取页眉/页脚(基于当前节)
header = section.header
footer = section.footer
# 页眉添加内容
header.paragraphs[0].text = "这是文档页眉 - 机密"
# 页脚添加页码(使用域代码)
from docx.oxml.ns import qn
from docx.oxml import OxmlElement
p = footer.add_paragraph()
run = p.add_run()
fldChar = OxmlElement('w:fldChar') # 域字符
fldChar.set(qn('w:fldCharType'), 'begin')
run._r.append(fldChar)
instrText = OxmlElement('w:instrText')
instrText.text = 'PAGE' # 页码域代码
run._r.append(instrText)
fldChar = OxmlElement('w:fldChar')
fldChar.set(qn('w:fldCharType'), 'end')
run._r.append(fldChar)
p.alignment = WD_ALIGN_PARAGRAPH.CENTER # 页码居中
九、处理已有文档
# 1. 读取文档内容(遍历段落)
doc = Document("existing.docx")
for para in doc.paragraphs:
print(para.text) # 打印所有段落文本
# 2. 修改已有段落
if len(doc.paragraphs) > 0:
doc.paragraphs[0].text = "修改后的第一段内容" # 替换第一段文本
# 3. 读取表格内容
for table in doc.tables:
for row in table.rows:
row_text = [cell.text for cell in row.cells]
print("行内容:", row_text)
PEG
PEG 解析示例
下面为你提供一些 PEG(解析表达式文法)规范的具体实例,帮助你理解其语法和应用场景。
一、简单算术表达式解析
这个例子展示了如何用 PEG 解析包含加减乘除和括号的算术表达式,同时处理运算符优先级。
# 算术表达式语法
Expression <- Term (AddOp Term)\*
Term <- Factor (MulOp Factor)\*
Factor <- Number / '(' Expression ')'
Number <- \[0-9]+ / '-' \[0-9]+
AddOp <- '+' / '-'
MulOp <- '\*' / '/'
解释:
-
Expression由Term后跟零个或多个AddOp Term组成(加法 / 减法)。 -
Term由Factor后跟零个或多个MulOp Factor组成(乘法 / 除法)。 -
Factor可以是数字或括号内的表达式。 -
Number支持整数和负数(如123或-456)。 -
优先级:通过规则嵌套实现(
MulOp在Term中,比AddOp优先级高)。
二、JSON 格式解析(简化版)
PEG 非常适合解析 JSON 这种无歧义的数据格式。
JSONValue <- JSONObject / JSONArray / JSONString / JSONNumber / "true" / "false" / "null"
JSONObject <- '{' (JSONPair (',' JSONPair)\*)? '}'
JSONPair <- JSONString ':' JSONValue
JSONArray <- '\[' (JSONValue (',' JSONValue)\*)? ']'
JSONString <- '"' \[^"]\* '"'
JSONNumber <- \[0-9]+ ('.' \[0-9]+)? (\[eE] \[+-]? \[0-9]+)?
解释:
-
JSONValue可以是对象、数组、字符串、数字或字面量(true/false/null)。 -
JSONObject是键值对的集合,用逗号分隔。 -
JSONArray是值的有序列表,用逗号分隔。 -
JSONString是双引号包裹的任意字符(简化版,实际需处理转义)。 -
JSONNumber支持整数、小数和科学计数法(如123、3.14、1e-10)。
三、CSV 格式解析
CSV(逗号分隔值)是一种简单的表格数据格式。
CSVFile <- Row ('\n' Row)\*
Row <- Value (',' Value)\* '\n'?
Value <- QuotedValue / UnquotedValue
QuotedValue <- '"' ('""' / \[^"])\* '"'
UnquotedValue <- \[^",\n]\*
解释:
-
CSVFile由多行Row组成,行之间用换行符分隔。 -
Row由多个Value组成,用逗号分隔,行末可选换行符。 -
Value可以是带引号的值或不带引号的值。 -
QuotedValue支持双引号转义(如"a""b"表示a"b)。
四、标识符和关键字解析
这个例子展示了如何区分关键字和普通标识符,避免匹配冲突。
Identifier <- !Keyword \[a-zA-Z\_] \[a-zA-Z0-9\_]\*
Keyword <- "if" / "else" / "while" / "function"
解释:
-
!Keyword是负向断言,确保当前位置不会匹配关键字。 -
例如,
if会匹配Keyword,而if_else会匹配Identifier。
五、HTML 标签解析(简化版)
解析 HTML 标签结构,处理嵌套关系。
HTML <- Element\*
Element <- OpenTag Content CloseTag
OpenTag <- '<' TagName Attribute\* '>'
CloseTag <- '\</' TagName '>'
TagName <- \[a-zA-Z]+
Attribute <- ' ' AttrName '=' '"' AttrValue '"'
AttrName <- \[a-zA-Z]+
AttrValue <- \[^"]\*
Content <- Text / Element
Text <- \[^<]\*
解释:
-
Element由开始标签、内容和结束标签组成。 -
Attribute是键值对(如id="main")。 -
Content可以是文本或嵌套的元素。 -
注意:这是简化版,实际 HTML 解析需处理自闭合标签(如
<br>)和更多复杂情况。
六、使用正向断言和负向断言
PEG 的断言运算符 & 和 ! 允许在不消耗输入的情况下检查匹配。
// 匹配以 "http" 开头的 URL
URL <- &"http" "http" ("s" / "") "://" Domain Path?
// 匹配非空行(至少包含一个非空白字符)
NonEmptyLine <- !'\n' \[^\n]\* '\n'
// 匹配非零数字
NonZeroDigit <- !'0' \[0-9]
解释:
-
&"http"确保后续字符是http,但不消耗输入。 -
!'0'排除0,只允许1-9。
七、PEG.js 中的实际应用
如果你使用 JavaScript 的 PEG.js 库,可以这样定义语法:
// PEG.js 语法文件示例
start = expression
expression
  \= additive
additive
  \= left:multiplicative "+" right:additive { return left + right; }
  / multiplicative
multiplicative
  \= left:primary "\*" right:multiplicative { return left \* right; }
  / primary
primary
  \= integer
  / "(" expr:expression ")" { return expr; }
integer "integer"
  \= digits:\[0-9]+ { return parseInt(digits.join(""), 10); }
解释:
-
这是一个可执行的 PEG 语法,包含动作代码(大括号内的 JavaScript)。
-
解析时会自动生成抽象语法树(AST)节点。
总结
PEG 的核心优势在于:
-
无歧义性:规则顺序决定匹配优先级,无需额外优先级规则。
-
高效解析:无回溯,适合处理复杂语法。
-
灵活断言:通过
&和!实现预检查,不消耗输入。
以上实例覆盖了常见场景,你可以根据需要调整规则或添加新的运算符 / 结构。
robots.txt
简介
-
网站告知搜索引擎爬虫哪些页面可以抓取、哪些页面禁止抓取的协议文件
-
放网站的根目录下
-
纯文本形式编写,每行一条指令,不区分大小写
-
主要部分:
- 用户代理(User - agent)
- 允许指令(Allow)
- 禁止指令(Disallow)
- 站点地图(Sitemap)
User - agent(用户代理)
-
作用:指定该规则适用的搜索引擎爬虫(如百度蜘蛛、谷歌爬虫等)。
-
格式:
User - agent: [爬虫名称] -
说明:
- 若使用
User - agent: *,表示该规则适用于所有未被单独指定的爬虫。 - 常见爬虫名称:
Baiduspider(百度)、Googlebot(谷歌)、360spider(360)等。 示例:
User - agent: Baiduspider # 仅适用于百度爬虫 User - agent: * # 适用于其他所有爬虫 - 若使用
Disallow(禁止抓取)
-
作用:指定禁止爬虫抓取的URL路径。
-
格式:
Disallow: [路径] -
说明:
- 路径支持通配符(部分爬虫支持,如谷歌):
*代表任意字符,$代表URL结尾。 - 若
Disallow: /,表示禁止抓取网站所有内容;若Disallow:(空值),表示允许抓取所有内容。 示例:
Disallow: /admin/ # 禁止抓取/admin/目录下的所有内容 Disallow: /private$ # 禁止抓取以/private结尾的URL(如https://example.com/private) Disallow: /*.pdf$ # 禁止抓取所有PDF文件(部分爬虫支持) - 路径支持通配符(部分爬虫支持,如谷歌):
Allow(允许抓取)
- 作用:在
Disallow的基础上,指定允许抓取的子路径(优先级高于Disallow)。 - 格式:
Allow: [路径] - 示例:
User - agent: * Disallow: /admin/ # 禁止抓取/admin/目录 Allow: /admin/public/ # 但允许抓取/admin/public/子目录
Sitemap(站点地图)
- 作用:告知爬虫网站的站点地图(sitemap)位置,帮助爬虫更高效地抓取内容。
- 格式:
Sitemap: [sitemap的URL] - 示例:
Sitemap: https://example.com/sitemap.xml Sitemap: https://example.com/sitemap_news.xml # 可指定多个站点地图
完整示例
# 禁止百度爬虫抓取/admin/和/user/目录
User - agent: Baiduspider
Disallow: /admin/
Disallow: /user/
# 允许谷歌爬虫抓取所有内容,但禁止PDF文件
User - agent: Googlebot
Allow: /
Disallow: /*.pdf$
# 对其他所有爬虫,仅禁止抓取/private/目录
User - agent: *
Disallow: /private/
# 站点地图位置
Sitemap: https://example.com/sitemap.xml
四、注意事项
- 优先级:同一
User - agent下,Allow指令优先级高于Disallow;不同User - agent规则独立生效。 - 通配符支持:并非所有爬虫都支持
*和$(如百度对通配符支持有限),需参考对应搜索引擎的文档。 - 注释:以
#开头的内容为注释,不影响规则执行。 - 权限限制:robots.txt 仅为“协议”,恶意爬虫可能无视规则,敏感内容需通过登录验证等方式保护。
五、常见错误格式
- 错误使用大小写混合(如
User - Agent: *,虽不报错,但不规范)。 - 路径格式错误(如遗漏
/,Disallow: admin可能被解析为禁止抓取包含“admin”字符的任意URL)。 - 多个
User - agent共用同一组规则时未正确分组(需每组规则前单独指定User - agent)。
css
1. 掌握基础语法与核心概念
CSS 的基础包括:
-
选择器(元素选择器、类选择器、ID 选择器、属性选择器)
-
盒模型(width/height、padding、border、margin)
-
定位(static、relative、absolute、fixed、sticky)
-
布局(display 属性:block、inline、inline-block、flex、grid)
-
浮动与清除浮动
-
颜色与单位(RGB、RGBA、HSL、rem、em、vh/vw)
建议通过 MDN 文档或在线教程(如 W3Schools)快速熟悉这些概念。
2. 深入学习现代布局技术
-
Flexbox:一维布局模型,适合对齐、分配空间和排列元素。
-
Grid:二维布局系统,可同时处理行和列,适合复杂布局。
-
响应式设计:使用媒体查询(
@media)和弹性单位(如%、rem)适配不同屏幕尺寸。
示例代码:
/* Flexbox 水平居中 */
.container {
display: flex;
justify-content: center;
align-items: center;
}
/* Grid 网格布局 */
.grid-container {
display: grid;
grid-template-columns: repeat(auto-fill, minmax(200px, 1fr));
gap: 1rem;
}
/* 响应式媒体查询 */
@media (max-width: 768px) {
.sidebar {
display: none;
}
}
3. 理解层叠与优先级
CSS 的优先级规则(内联样式 > ID 选择器 > 类选择器 > 元素选择器)和层叠机制(后面的样式覆盖前面的)是核心难点,建议通过练习加深理解。
4. 掌握动画与交互
-
过渡(transition):平滑改变属性值。
-
动画(animation):通过
@keyframes创建复杂动画。 -
伪类(:hover、:active、:focus):实现交互效果。
示例代码:
/* 按钮悬停效果 */
.button {
transition: background-color 0.3s ease;
}
.button:hover {
background-color: #ff0000;
}
/* 元素淡入动画 */
@keyframes fadeIn {
from { opacity: 0; }
to { opacity: 1; }
}
.fade-in {
animation: fadeIn 1s forwards;
}
5. 使用工具与框架提高效率
-
预处理器:Sass/SCSS(变量、嵌套、混合器)。
-
CSS 框架:Tailwind CSS(原子类)、Bootstrap(组件库)。
-
浏览器工具:Chrome DevTools 的 Elements 面板调试布局和样式。
6. 实战项目
通过模仿知名网站(如 GitHub、Twitter)或完成在线挑战(如CSS Battle)来巩固技能。例如:
-
制作响应式导航栏。
-
实现卡片式布局。
-
设计轮播图或模态框。
7. 避免常见误区
-
过度使用内联样式或
!important。 -
忽略浏览器兼容性(使用 Can I Use 查询特性支持)。
-
不使用语义化 HTML 标签(如用
div代替header)。
推荐资源
-
文档:MDN CSS 文档(https://developer.mozilla.org/en-US/docs/Web/CSS)
-
书籍:《CSS 权威指南》《CSS 揭秘》
-
网站:CSS-Tricks(技巧与教程)、Codepen(案例参考)
盒模型在 CSS 布局中的应用
盒模型(Box Model)是 CSS 布局的基础概念,描述了元素在页面中所占的空间大小及相互关系。理解盒模型是掌握 CSS 布局的关键。
核心组成部分
盒模型由内向外包含四个部分:
- 内容区(Content)
-
元素实际显示的内容(文本、图片等)。
-
由
width和height属性定义大小。
- 内边距(Padding)
-
内容区与边框之间的距离。
-
可通过
padding-top/bottom/left/right或简写属性(如padding: 10px 20px)设置。
- 边框(Border)
-
围绕内边距和内容区的线条。
-
由
border-width、border-style(如实线、虚线)和border-color控制。
- 外边距(Margin)
-
元素与其他元素之间的距离。
-
可通过
margin-top/bottom/left/right或简写属性设置。
盒模型尺寸计算
元素的总宽度 = width + 左右padding + 左右border + 左右margin
元素的总高度 = height + 上下padding + 上下border + 上下margin
示例:
.box {
width: 200px; /* 内容区宽度 */
padding: 10px; /* 内边距:上下左右各10px */
border: 2px solid #000; /* 边框:2px宽 */
margin: 15px; /* 外边距:上下左右各15px */
}
/* 总宽度 = 200 + (10*2) + (2*2) + (15*2) = 254px */
标准盒模型 vs. 怪异盒模型
盒模型的计算方式由 box-sizing 属性控制:
- 标准盒模型(默认值:
content-box)
-
width/height仅包含内容区,不包含padding、border和margin。 -
总尺寸 =
width/height+padding+border+margin。
- 怪异盒模型(
border-box)
-
width/height包含内容区、padding和border,但不包含margin。 -
总尺寸 =
width/height+margin。
示例:
/* 标准盒模型 */
.box1 {
width: 200px;
padding: 10px;
border: 2px solid #000;
/* 内容区宽度200px,总宽度224px */
}
/* 怪异盒模型 */
.box2 {
box-sizing: border-box;
width: 200px;
padding: 10px;
border: 2px solid #000;
/* 内容区宽度 = 200 - (10*2) - (2*2) = 176px,总宽度200px */
}
关键特性
- 外边距合并(Margin Collapsing)
-
相邻元素的垂直外边距会合并为较大的一个(水平外边距不会合并)。
-
父子元素之间也可能发生合并(如父元素无
padding/border时)。
- 负外边距
- 设置负值可使元素与其他元素重叠或扩展布局。
- 内边距和边框的透明性
padding和border区域可显示背景色 / 图片,而margin始终透明。
常见应用场景
-
创建等高列布局
使用
padding和负margin抵消内容差异。 -
响应式设计
使用
box-sizing: border-box避免因内边距导致布局溢出。 -
居中元素
使用
margin: 0 auto水平居中块级元素。
总结
盒模型是 CSS 布局的基石,掌握它能帮助你:
-
精确控制元素尺寸和间距。
-
解决布局中的意外空白或溢出问题。
-
灵活运用
box-sizing优化响应式设计。
建议通过 Chrome DevTools 的 Elements 面板实时观察盒模型(选中元素后查看右侧 Styles 面板中的 “Box Model” 区域),加深理解。
Cypher
简介
- 属性图
- 节点
- 关系(边)
- 路径
基础语法结构
-
节点表示
- 基础格式:
(变量:标签 {属性键:属性值})- 变量:可选,用于后续引用(如
n)。 - 标签:可选,用于对节点进行分类(如
User)。 - 属性:可选,键值对(如
{name: "Alice"})。
- 变量:可选,用于后续引用(如
- 示例:
(:Person):匿名Person节点。(p:Employee):别名为p的Employee节点。(:Book {title:"Neo4j Guide"}):带属性的匿名节点。
- 基础格式:
-
关系表示
- 基础格式:
[变量:类型 {属性键:属性值}] - 方向:
-->(出边)或<--(入边)。 - 示例:
(a)-[:FRIEND]->(b):无属性关系。(a)-[r:FOLLOWS {since:2020}]->(b):带属性和变量的关系。
- 基础格式:
核心命令详解
-
MATCH(模式匹配)
- 功能:定位图中的节点/关系。
- 示例:
- 查找
Alice的朋友:MATCH (a:User {name:"Alice"})-[:FRIEND]->(friend) RETURN friend.name。 - 查找所有电影及其导演:
MATCH (d:Director)-[:DIRECTED]->(m:Movie) RETURN d.name, m.title。
- 查找
-
WHERE(条件过滤)
- 支持运算符:
=、>、<、<>、CONTAINS、STARTS WITH、IS NULL、IS NOT NULL等。 - 示例:
- 查找年龄大于 30 的用户:
MATCH(u:User) WHERE u.age>30 RETURN u。 - 查找名字以 “A” 开头的用户:
MATCH(u:User) WHERE u.name=~'A.*' RETURN u。
- 查找年龄大于 30 的用户:
- 支持运算符:
-
RETURN(结果返回)
- 支持聚合函数:
COUNT()、SUM()、AVG()、COLLECT()等。 - 示例:
- 返回节点和标签:
MATCH (n {name:"zhangsan"}) RETURN n, labels(n)。 - 统计每种职业的平均年龄:
MATCH (n:Person) RETURN n.profession, avg(n.age)。
- 返回节点和标签:
- 支持聚合函数:
-
CREATE(数据创建)
- 创建节点:
CREATE (n:Person {name: "Alice", age: 30})。 - 创建关系:
CREATE (a:User {name: "Alice"}), (b:User {name: "Bob"}) CREATE (a)-[:FRIEND]->(b)。 - 节点与关系同步创建:
CREATE (a:User {name:"Bob"})-[:WORKS_AT]->(c:Company {name:"Neo4j"})。
- 创建节点:
-
SET(属性更新)
- 修改属性:
MATCH (u:User {name:"Alice"}) SET u.age = 31。 - 添加新属性:
MATCH (n:Person {name: 'Alice'}) SET n.email = 'alice@example.com'。 - 更新关系属性:
MATCH (a:Person {name: 'Alice'})-[r:KNOWS]->(b:Person {name: 'Bob'}) SET r.since = 2022。 - 添加标签:
MATCH (u:User {name:"Bob"}) SET u:VIP。
- 修改属性:
-
DELETE(数据删除)
- 删除节点:需先删除关联关系,
MATCH (u:User)-[r]-() DELETE r, u或MATCH (u:User {name:"Bob"}) DETACH DELETE u。 - 删除关系:
MATCH (a:Person {name: 'Alice'})-[r:KNOWS]->(b:Person {name: 'Bob'}) DELETE r。 - 删除属性:
MATCH (u:User {name:"Alice"}) REMOVE u.age。
- 删除节点:需先删除关联关系,
高级查询功能
-
路径查询
- 多跳关系:使用
*n..m指定跳数范围,如MATCH (a:User)-[:FRIEND*2]->(c:User) WHERE a.id=123 RETURN c.name(查找朋友的朋友)。 - 最短路径:使用
shortestPath函数,如MATCH path = shortestPath((a:User)-[:FRIEND*..5]-(b:User)) WHERE a.id=1 AND b.id=100 RETURN path。
- 多跳关系:使用
-
聚合与分组
- 统计数量:
MATCH (u:User)-[:BOUGHT]->(p:Product) RETURN u.name, COUNT(p) AS purchase_count。 - 分组统计:
MATCH (p:Person)-[:WORKS_AT]->(c:Company) RETURN c.name, COUNT(p) AS employeeCount。
- 统计数量:
-
分页与排序
- 分页查询:
MATCH (p:Person) RETURN p.name ORDER BY p.age DESC SKIP 10 LIMIT 5(跳过前 10 条结果,返回接下来的 5 条)。 - 动态分页:
MATCH (p:Person) RETURN p.name ORDER BY p.age DESC SKIP $offset LIMIT $limit(使用参数$offset和$limit控制分页)。
- 分页查询:
-
WITH 子句
- 功能:将查询结果传递给下一个部分,允许在查询中进行聚合、排序、分页等操作。
- 示例:
- 过滤聚合函数的结果:
MATCH (n {name: "zhangsan" })--(m)-->(s) WITH m, COUNT(*) AS m_count WHERE m_count>1 RETURN m。 - 限制路径搜索的分支:
MATCH (n {name: "zhangsan"})--(m) WITH m ORDER BY m.name DESC LIMIT 1 MATCH (m)--(o) RETURN o.name。
- 过滤聚合函数的结果:
-
UNION 和 UNION ALL
- 功能:将多个查询结果组合起来。
UNION会移除重复的行,UNION ALL会包含所有的结果不会移除重复的行。 - 示例:
- 去重:
MATCH (n:Person) RETURN n.name AS name UNION MATCH(n:Movie) RETURN b.title AS name。 - 不去重:
MATCH (n:Person) RETURN n.name AS name UNION ALL MATCH(n:Movie) RETURN b.title AS name。
- 去重:
- 功能:将多个查询结果组合起来。
-
CALL 子句
- 功能:调用数据库中的内置过程(Procedure),内置过程类似于关系型数据库中的存储过程,是一组完成特定功能的方法。
- 示例:
- 调用数据库内置过程查询数据库中所有的点类型:
CALL db.labels()。 - 调用内置过程并将结果绑定变量或过滤:
CALL db.labels() yield label return count(type) as numTypes。
- 调用数据库内置过程查询数据库中所有的点类型:
性能优化技巧
-
使用索引
- 为属性创建索引加速查询:
CREATE INDEX FOR (p:Person) ON (p.name)。
- 为属性创建索引加速查询:
-
标签限定
- 在 MATCH 中优先使用标签缩小搜索范围,避免全图扫描
MATCH (a:User)
WHERE a.name STARTS WITH 'A'
RETURN a;
-
执行计划分析
- 使用
EXPLAIN查看查询的执行计划,避免全图扫描:EXPLAIN MATCH (p:Person {name: "Alice"}) RETURN p。
- 使用
-
参数化查询
- 防止注入攻击:
MATCH (p:Person {name: $name}) RETURN p。使用$name替代直接拼接参数。
- 防止注入攻击:
注释与参数化查询
-
注释
- 单行注释:使用
//进行单行注释,如// 这是一个单行注释 MATCH (n:Person) RETURN n。 - 多行注释:使用
/* ... */进行多行注释,如/* 这是一个多行注释 */ MATCH (n:Person) RETURN n。
- 单行注释:使用
-
参数化查询
- Cypher 支持通过参数化查询来提高性能和安全性,通常用于防止 SQL 注入攻击。例如:
MATCH (n:Person {name: $name}) RETURN n。
- Cypher 支持通过参数化查询来提高性能和安全性,通常用于防止 SQL 注入攻击。例如:
实际场景示例:社交网络分析
场景:查找与 Alice 有共同兴趣且购买过高价商品的朋友。
查询:
MATCH
(a:Person {name: 'Alice'})-[:FRIEND]->(b:Person),
(b)-[:INTEREST]->(i:Interest),
(a)-[:INTEREST]->(i),
(b)-[:BUY]->(p:Product)
WHERE p.price > 1000
RETURN DISTINCT b.name, i.name, p.name;
- 步骤解析:
- 匹配
Alice的朋友b(FRIEND关系)。 - 匹配
b和Alice的共同兴趣i(INTEREST关系)。 - 匹配
b购买的高价商品p(BUY关系且价格 > 1000)。 - 返回去重后的结果:朋友姓名、共同兴趣、购买商品。
- 匹配
proto3
一、基础语法与文件结构
-
文件声明
- 所有proto3文件需以
syntax = "proto3";开头,明确指定版本(若省略,默认按proto2解析)。 - 文件命名通常为
.proto后缀(如message.proto)。
- 所有proto3文件需以
-
包声明
- 使用
package关键字指定命名空间,避免消息类型冲突,例如:package example; // 生成代码时会映射为对应语言的包(如Java的package、Go的package)
- 使用
-
导入其他proto文件
- 通过
import导入外部定义,支持相对路径或绝对路径:import "other.proto"; // 导入同目录下的proto文件
- 通过
二、数据类型
proto3定义了一套跨语言的基础类型,映射到不同编程语言的原生类型(如Java的int32对应int,Go的int32对应int32等)。
-
标量类型
proto3类型 说明 对应Java类型 对应Go类型 int3232位有符号整数(可变长度编码,负数效率低) intint32int6464位有符号整数 longint64uint3232位无符号整数 int(非负)uint32uint6464位无符号整数 long(非负)uint64sint3232位有符号整数(优化负数编码,比int32高效) intint32sint6464位有符号整数(优化负数编码) longint64fixed3232位无符号整数(固定4字节,适合大数值) intuint32fixed6464位无符号整数(固定8字节) longuint64sfixed3232位有符号整数(固定4字节) intint32sfixed6464位有符号整数(固定8字节) longint64float32位浮点数 floatfloat32double64位浮点数 doublefloat64bool布尔值 booleanboolstringUTF-8编码字符串(长度不超过2^32) Stringstringbytes二进制数据(长度不超过2^32) ByteString[]byte -
复合类型
- 消息(
message):自定义结构化数据(见下文)。 - 枚举(
enum):预定义的离散值集合。 - 映射(
map):键值对集合(map<key_type, value_type> map_name = field_number;)。 - 嵌套类型:消息或枚举可嵌套在其他消息中。
- 消息(
三、消息定义(Message)
消息是proto3的核心,用于描述结构化数据,类似类或结构体。
-
基本格式
message Person { string name = 1; // 字段名:类型 + 名称 + 字段编号 int32 age = 2; bool is_student = 3; }- 字段编号:1-15占用1字节编码,16-2047占用2字节,建议高频字段用1-15。
- 编号一旦使用,不可随意修改(影响序列化兼容性)。
-
字段规则
proto3移除了proto2的required和optional,所有字段默认为“可选”,但有以下规则:- ** singular :默认规则,字段可出现0次或1次(序列化时可省略)。
- repeated **:字段可出现0次或多次(类似数组),默认使用打包编码(高效)。message Group { repeated Person members = 1; // 重复字段(成员列表) }
- ** singular :默认规则,字段可出现0次或1次(序列化时可省略)。
-
嵌套消息消息可嵌套在其他消息中,支持多层嵌套:
message Student { message Address { // 嵌套消息 string street = 1; string city = 2; } Address home_address = 1; // 使用嵌套消息作为字段类型 }
** 四、枚举(Enum)**用于定义离散的可选值,字段类型可指定为枚举类型。
- 基本格式
enum Gender {
GENDER_UNSPECIFIED = 0; // 必须包含0值(默认值),否则序列化可能出错
MALE = 1;
FEMALE = 2;
}
message Person {
Gender gender = 1; // 使用枚举作为字段类型
}
- 枚举值必须从0开始,0值为默认值(未设置时的默认)。
- 允许不同枚举值指定相同编号(需用
allow_alias = true声明):enum Status { allow_alias = true; DEFAULT = 0; NONE = 0; // 与DEFAULT别名 SUCCESS = 1; }
- 嵌套枚举枚举可嵌套在消息中:
message Person {
enum Role {
ROLE_UNKNOWN = 0;
ADMIN = 1;
USER = 2;
}
Role role = 1;
}
** 五、映射(Map)**用于定义键值对集合,语法为map<key_type, value_type> map_name = field_number;。
-
限制:
- 键类型只能是标量类型(
int32、string等),不能是消息或枚举。 - 值类型可以是任意类型(标量、消息、枚举等)。
- 映射是无序的,序列化/反序列化后顺序可能变化。
- 键类型只能是标量类型(
-
示例:
message Config {
map<string, int32> params = 1; // 字符串键 -> 整数值
map<int64, Person> users = 2; // 64位整数键 -> Person消息值
}
** 六、默认值**当字段未显式设置时,会使用默认值(序列化时默认值不写入,节省空间)。
-
** 标量类型默认值 **:
- 数值类型(
int32、float等):0 bool:falsestring:空字符串("")bytes:空字节数组([])。
- 数值类型(
-
** 复合类型默认值 **:
- 枚举:0值(第一个定义的枚举值)。
- 消息:默认实例(所有字段为默认值的对象)。
repeated:空列表。map:空映射。
** 七、服务定义(Service)**用于定义RPC服务接口,配合gRPC等框架实现跨语言远程调用。
- ** 基本格式 **:
service UserService { // 简单RPC:客户端发送请求,服务端返回响应 rpc GetUser(GetUserRequest) returns (UserResponse); // 服务端流式RPC:客户端发请求,服务端返回流式响应 rpc ListUsers(ListUsersRequest) returns (stream UserResponse); // 客户端流式RPC:客户端发流式请求,服务端返回单个响应 rpc BatchUpdate(stream UpdateRequest) returns (BatchResponse); // 双向流式RPC:双方都可发送流 rpc Chat(stream ChatMessage) returns (stream ChatMessage); } // 请求/响应消息定义 message GetUserRequest { int32 user_id = 1; } message UserResponse { Person user = 1; }
** 八、选项(Options)**用于为文件、消息、字段等添加元数据,影响代码生成或序列化行为。
-
** 常用选项 **:
-
java_package:指定生成Java类的包名(覆盖package):option java_package = "com.example.proto"; -
java_outer_classname:指定生成的Java外部类名(默认用文件名):option java_outer_classname = "UserProto"; -
go_package:指定生成Go代码的包路径:option go_package = "./pb;pb"; // 路径;包名 -
deprecated:标记字段/枚举值为已废弃(生成代码时会添加废弃注解):int32 old_field = 1 [deprecated = true]; // 字段废弃
-
-
** 范围 **:选项可作用于文件(
option)、消息(message内的option)、字段(字段后[option])等。
** 九、兼容性规则**proto3设计为向前/向后兼容,修改消息定义时需遵循以下原则:
-
兼容修改(推荐):
- 新增字段:旧版本可忽略新增字段,新版本可读取旧数据(新增字段用默认值)。
- 字段编号复用:删除字段后,其编号不可再用(避免新旧数据冲突)。
- 枚举新增值:旧版本会将未识别的枚举值视为0值(需确保0值安全)。
-
不兼容修改(禁止):
- 修改已有字段的编号或类型。
- 删除必填字段(proto3无
required,但逻辑上的必填字段删除会出错)。
Proto3 Golang 插件汇总
| 分类 | 插件名称 | 核心功能 | 适用场景 |
|---|---|---|---|
| 数据校验 | protoc-gen-go-validator | 基于注释生成数据校验逻辑(非空、格式等) | 接口参数校验、数据入库前校验 |
| 数据校验 | protoc-gen-validate | 官方校验插件,支持复杂规则(跨字段依赖、正则等) | 多语言通用校验、复杂业务规则校验 |
| 数据校验 | protoc-gen-go-validator-custom | 支持自定义校验函数(如手机号、身份证验证) | 业务特异性校验逻辑 |
| HTTP 接口 | protoc-gen-go-http | 将 gRPC 服务转换为 HTTP 接口(绑定方法、路径) | RESTful API 自动生成 |
| HTTP 接口 | protoc-gen-go-grpc-gateway | gRPC 转 HTTP 网关,支持 REST 与 gRPC 映射 | 同时提供 gRPC 和 HTTP 接口 |
| HTTP 接口 | protoc-gen-go-http-client | 生成 HTTP 客户端代码,自动处理参数与签名 | 调用远程 HTTP 接口 |
| 代码增强 | protoc-gen-go-tag | 自定义 Go 结构体标签(json、db 等) | 覆盖默认标签,适配 JSON / 数据库字段名 |
| 代码增强 | protoc-gen-go-enum | 生成枚举的 String ()、Parse () 等方法 | 枚举值与字符串双向转换 |
| 代码增强 | protoc-gen-go-setters | 生成链式 Setter 方法(如 SetId (1).SetName (“a”)) | 简化消息初始化代码 |
| 代码增强 | protoc-gen-go-deepcopy | 生成深度拷贝方法,优化嵌套结构拷贝 | 复杂消息的高效拷贝 |
| 序列化 | protoc-gen-go-json | 生成高效 JSON 序列化代码,替代 jsonpb | 高性能 JSON 数据交换 |
| 序列化 | protoc-gen-go-msgp | 基于 msgp 库生成二进制序列化代码 | 高频通信、内存数据库等高性能场景 |
| 序列化 | protoc-gen-go-msgpack | 生成 MsgPack 格式序列化代码 | 需减少传输体积的场景(如游戏服务器) |
| 数据库 | protoc-gen-go-sql | 生成 SQL 表结构和 CRUD 代码 | 数据模型与数据库表结构同步 |
| 数据库 | protoc-gen-go-gorm | 生成 GORM 模型和操作代码,支持索引、主键等 | ORM 框架集成,简化数据库操作 |
| 数据库 | protoc-gen-go-sqlite | 针对 SQLite 生成表结构和适配代码 | 轻量级数据库场景 |
| 数据库 | protoc-gen-go-query | 将消息转换为 SQL/MongoDB 查询条件 | 自动生成查询语句,避免手动拼接 SQL |
| 数据库 | protoc-gen-go-mongodb | 生成 MongoDB 文档操作代码,支持 BSON 与 proto 消息的自动转换 | 文档型数据库集成,简化复杂查询与更新操作 |
| 缓存 | protoc-gen-go-cache | 生成缓存操作代码(Redis/Memcached),处理键生成与过期策略 | 数据缓存逻辑开发 |
| 缓存 | protoc-gen-go-redis | 生成 Redis 数据结构操作代码(Hash、String 等) | proto 消息与 Redis 存储映射 |
| 测试工具 | protoc-gen-go-mock | 生成 gRPC 服务的 Mock 实现(基于 GoMock) | 单元测试中模拟服务端 / 客户端 |
| 测试工具 | protoc-gen-go-assert | 生成消息比较断言方法(Equal ()、NotEqual ()) | 测试中验证消息实例一致性 |
| 测试工具 | protoc-gen-go-faker | 生成伪造测试数据,支持自定义规则 | 单元测试 / 集成测试数据集准备 |
| 测试工具 | protoc-gen-go-benchmark | 为 proto 消息生成基准测试代码,自动测试序列化 / 反序列化性能 | 性能优化场景,对比不同序列化方式的效率 |
| 测试工具 | protoc-gen-go-fuzz | 生成模糊测试代码,自动生成异常输入验证 proto 消息处理逻辑 | 健壮性测试,发现边界条件与异常处理漏洞 |
| 文档生成 | protoc-gen-doc | 生成 API 文档(Markdown/HTML/Swagger) | 接口文档自动同步,避免手动维护 |
| 文档生成 | protoc-gen-go-swagger | 转换为 Swagger/OpenAPI 文档 | 前端接口调试与文档查阅 |
| 文档生成 | protoc-gen-go-wiki | 生成 Wiki 文档(如 Confluence 格式),从 proto 提取服务与消息说明 | 团队知识库建设,自动同步接口文档到 Wiki 系统 |
| 文档生成 | protoc-gen-go-pdf | 生成 PDF 格式接口文档,支持自定义模板与样式 | 对外接口文档交付,生成标准化 PDF 文档 |
| 消息队列 | protoc-gen-go-kafka | 生成 Kafka 生产者 / 消费者代码,绑定消息与主题 | 消息队列集成,简化消息收发逻辑 |
| 消息队列 | protoc-gen-go-amqp | 生成 AMQP 协议(如 RabbitMQ)的生产者 / 消费者代码,绑定 proto 消息 | 基于 AMQP 的消息队列集成 |
| 消息队列 | protoc-gen-go-mqtt | 生成 MQTT 客户端代码,支持 proto 消息与 MQTT 主题的绑定 | IoT 设备通信、实时消息推送场景 |
| 监控与日志 | protoc-gen-go-metrics | 生成 Prometheus 监控指标代码(调用次数、耗时等) | 服务性能监控与告警 |
| 监控与日志 | protoc-gen-go-log | 生成结构化日志输出方法(基于 zap/logrus) | 消息字段自动转换为日志键值对 |
| 监控与日志 | protoc-gen-go-logfmt | 生成 logfmt 格式的日志输出代码,将 proto 消息字段转为 key=value 格式 | 结构化日志场景,适配 logfmt 格式的日志收集系统 |
| 监控与日志 | protoc-gen-go-fluentd | 生成 Fluentd 日志发送代码,自动将 proto 消息转为 Fluentd 可接收格式 | 日志集中收集场景,对接 Fluentd 生态 |
| 监控与日志 | protoc-gen-go-trace | 生成分布式追踪代码(基于 OpenTelemetry),自动注入 span 与标签 | 微服务调用链追踪,记录接口耗时与参数 |
| 配置管理 | protoc-gen-go-env | 从环境变量加载数据到 proto 消息 | 环境变量配置解析 |
| 配置管理 | protoc-gen-go-toml | 生成 proto 与 TOML 格式互转代码 | TOML 配置文件读写 |
| 配置管理 | protoc-gen-go-config | 生成配置管理代码,支持从多种源(文件、环境变量、etcd)加载 proto 配置 | 复杂配置场景,统一配置加载与更新逻辑 |
| 配置管理 | protoc-gen-go-flagset | 生成基于 flagset 的配置解析代码,支持 proto 消息字段与命令行 flag 绑定 | 命令行工具配置解析,兼容标准库 flag 包 |
| 服务治理 | protoc-gen-go-grpc-middleware | 生成 gRPC 中间件框架(日志、认证、限流等) | 服务通用功能注入 |
| 服务治理 | protoc-gen-go-proxy | 生成 gRPC 服务代理代码,支持转发、负载均衡 | 服务网关开发,后端服务动态路由 |
| 服务治理 | protoc-gen-go-etcd | 生成 etcd 操作代码,将 proto 消息与 etcd 键值存储映射 | 分布式配置中心、服务注册与发现场景 |
| 服务治理 | protoc-gen-go-consul | 生成 Consul 服务注册 / 发现代码,基于 proto 定义服务元数据 | 微服务架构中的服务治理 |
| 类型转换 | protoc-gen-go-structpb | 生成 proto 与 structpb.Struct 互转代码 | 静态消息与动态结构(如 JSON 任意字段)适配 |
| 类型转换 | protoc-gen-go-mapper | 生成不同 proto 消息的字段映射代码 | 服务间数据格式转换 |
| 类型转换 | protoc-gen-go-transform | 定义转换规则,生成消息互转代码(支持嵌套结构、默认值) | 复杂消息结构的自动映射 |
| 类型转换 | protoc-gen-go-xml | 生成 proto 消息与 XML 格式的互转代码,支持自定义标签映射 | 需要处理 XML 格式数据的场景(如传统接口对接) |
| 类型转换 | protoc-gen-go-csv | 生成 proto 消息与 CSV 文件的读写代码,支持字段映射与类型转换 | 批量数据导入导出(如报表生成、数据迁移) |
| 安全相关 | protoc-gen-go-jwt | 生成 JWT 令牌生成与验证代码,支持从 proto 消息提取 claims | 接口认证授权,基于 proto 定义的用户信息生成令牌 |
| 安全相关 | protoc-gen-go-encrypt | 为 proto 消息字段生成加密 / 解密方法(支持 AES、RSA 等算法) | 敏感字段(如手机号、身份证)的安全存储与传输 |
| 分布式系统 | protoc-gen-go-replication | 生成数据同步代码,支持 proto 消息的增量同步与冲突解决 | 分布式系统数据一致性保障,跨服务 / 跨库数据同步 |
| 分布式系统 | protoc-gen-go-cdc | 生成变更数据捕获(CDC)代码,监听 proto 消息对应表的变更并触发事件 | 基于数据库变更的实时通知,如订单更新后自动推送消息 |
| 命令行工具 | protoc-gen-go-flags | 生成命令行参数解析代码(基于 cobra/pflag) | CLI 工具开发,参数自动绑定 |
| 命令行工具 | protoc-gen-go-cli | 基于 proto 消息生成完整 CLI 工具框架(包含子命令、帮助信息) | 快速开发命令行工具,参数解析与业务逻辑分离 |
| 命令行工具 | protoc-gen-go-completion | 为 CLI 工具生成自动补全代码(支持 bash/zsh),基于 proto 消息字段 | 提升 CLI 工具易用性,自动补全命令与参数 |
| 算法与计算 | protoc-gen-go-math | 为数值型 proto 字段生成数学运算代码(如求和、平均值、方差) | 统计分析场景,自动处理批量数据的数学计算 |
| 算法与计算 | protoc-gen-go-geo | 生成地理信息(经纬度)处理代码,支持距离计算、区域判断等 | LBS 服务,如附近的人、区域配送范围判断 |
| 网络工具 | protoc-gen-go-ip | 生成 IP 地址(v4/v6)处理代码,支持解析、验证与 proto 字段绑定 | 网络服务,如 IP 黑白名单、地理位置解析 |
| 网络工具 | protoc-gen-go-url | 生成 URL 解析与构建代码,支持 proto 消息字段与 URL 参数的互转 | HTTP 服务,自动处理 URL 路径与查询参数的解析 |
| 跨境与本地化 | protoc-gen-go-i18n | 生成国际化(i18n)相关代码,将 proto 消息字段与多语言文案映射 | 多语言应用,自动处理不同语言的文案替换与格式化 |
| 跨境与本地化 | protoc-gen-go-currency | 生成货币格式化与转换代码,支持从 proto 定义币种与精度 | 跨境支付、电商价格展示,自动处理汇率转换与格式规范 |
| 图形与媒体 | protoc-gen-go-image | 生成图像元数据(如尺寸、格式)与 proto 消息的互转代码 | 图片处理服务,解析图片信息到 proto 结构或生成图片处理参数 |
| 图形与媒体 | protoc-gen-go-video | 生成视频元数据(时长、分辨率)与 proto 消息的转换代码 | 视频处理服务,同步视频信息与业务数据模型 |
| 图形与媒体 | protoc-gen-go-audio | 生成音频元数据(采样率、时长)与 proto 消息的互转代码 | 音频处理服务,同步音频文件信息与业务数据 |
| 图形与媒体 | protoc-gen-go-speech | 生成语音识别结果(如文字转语音、语音转文字)与 proto 消息的转换代码 | 语音交互应用,统一语音数据与业务模型的格式 |
| 边缘计算 | protoc-gen-go-edge | 生成边缘设备数据处理代码,优化 proto 消息在资源受限设备上的序列化效率 | 物联网边缘节点,低功耗设备数据采集与传输 |
| 边缘计算 | protoc-gen-go-mqtt-edge | 为边缘设备生成轻量 MQTT 客户端代码,压缩 proto 消息传输体积 | 边缘设备与云端通信,减少网络带宽占用 |
| 实时通信 | protoc-gen-go-websocket | 生成 WebSocket 消息处理代码,自动将 proto 消息与 WebSocket 帧互转 | 实时 Web 应用(如聊天、协作工具),复用 proto 定义的消息结构 |
| 实时通信 | protoc-gen-go-socketio | 生成 Socket.IO 协议适配代码,支持 proto 消息与 Socket.IO 事件绑定 | 浏览器与服务器实时通信,兼容前端 Socket.IO 客户端 |
| 数据可视化 | protoc-gen-go-chart | 生成数据可视化代码(基于 go-echarts),将 proto 消息转换为图表数据 | 监控面板、报表系统,自动将业务数据转换为可视化图表 |
| 数据可视化 | protoc-gen-go-plot | 生成绘图代码(基于 gonum/plot),支持从 proto 消息提取数据绘制图形 | 科学计算、数据分析场景,自动生成趋势图、分布图等 |
| 区块链集成 | protoc-gen-go-blockchain | 生成区块链(如以太坊)数据交互代码,将 proto 消息映射为智能合约接口 | 区块链应用,统一链上数据与业务层 proto 模型 |
| 区块链集成 | protoc-gen-go-tx | 生成交易签名与验证代码,支持从 proto 消息提取交易信息生成区块链交易 | 链下业务系统与区块链交互,确保交易数据一致性 |
| 工作流引擎 | protoc-gen-go-workflow | 基于 proto 定义工作流节点与规则,生成状态机与流转逻辑代码 | 业务流程自动化(如订单状态流转、审批流程) |
| 工作流引擎 | protoc-gen-go-rule | 生成规则引擎代码,支持从 proto 定义条件判断与执行逻辑 | 复杂业务规则的动态配置与执行(如优惠活动规则、风控策略) |
| 工作流引擎 | protoc-gen-go-camunda | 生成与 Camunda 工作流引擎交互的代码,将 proto 消息映射为流程变量 | 企业级工作流系统,用 proto 定义流程参数与结果 |
| 工作流引擎 | protoc-gen-go-flow | 基于 proto 定义简易工作流规则,生成状态流转与条件判断代码 | 轻量级工作流场景(如审批流程、任务状态变更) |
| 搜索集成 | protoc-gen-go-elasticsearch | 生成 Elasticsearch 操作代码,将 proto 消息转换为 ES 文档与查询条件 | 全文搜索场景,自动同步业务数据到 ES 并生成查询逻辑 |
| 搜索集成 | protoc-gen-go-solr | 生成 Solr 索引与查询代码,支持 proto 消息字段与 Solr 文档字段映射 | 企业级搜索应用,统一数据模型与搜索索引结构 |
| 容器化工具 | protoc-gen-go-docker | 生成 Dockerfile 与容器配置代码,基于 proto 定义服务依赖与资源需求 | 微服务容器化,自动生成符合服务特性的容器配置 |
| 容器化工具 | protoc-gen-go-k8s | 生成 Kubernetes 资源配置(如 Deployment、Service)代码,基于 proto 定义 | 云原生部署,用 proto 统一服务定义与 K8s 配置 |
| DevOps 工具 | protoc-gen-go-ansible | 生成 Ansible Playbook 代码,将 proto 消息映射为 Ansible 任务参数 | 自动化部署场景,用 proto 定义部署配置与执行步骤 |
| DevOps 工具 | protoc-gen-go-pipeline | 生成 CI/CD 流水线配置(如 GitLab CI、GitHub Actions),基于 proto 定义流程 | 持续集成 / 部署,自动生成符合项目规范的流水线配置 |
| 人工智能 | protoc-gen-go-tensorflow | 生成 TensorFlow 模型输入 / 输出与 proto 消息的转换代码 | 机器学习服务,统一模型数据与业务数据格式 |
| 人工智能 | protoc-gen-go-ml | 生成机器学习特征工程代码,从 proto 消息提取特征并转换为模型输入格式 | 算法工程化,自动处理特征提取与格式转换 |
| 低代码平台 | protoc-gen-go-form | 生成表单 UI 代码(如 HTML/React 组件),基于 proto 消息字段定义表单元素 | 低代码平台,自动生成数据录入表单 |
| 低代码平台 | protoc-gen-go-table | 生成表格 UI 代码,将 proto 消息列表转换为可交互表格(支持排序、筛选) | 后台管理系统,自动生成数据展示表格 |
| 游戏开发 | protoc-gen-go-game | 生成游戏协议处理代码,优化 proto 消息在游戏帧同步 / 状态同步中的序列化效率 | 网络游戏开发,适配高频率消息传输场景 |
| 游戏开发 | protoc-gen-go-lua | 生成 Lua 与 Go 的 proto 消息互转代码,方便游戏客户端(Lua)与服务端通信 | 跨语言游戏开发,统一客户端与服务端数据格式 |
| 消息协议 | protoc-gen-go-mpeg | 生成 MPEG 协议(如视频流)与 proto 消息的转换代码 | 音视频流处理,解析协议数据到业务模型 |
| 消息协议 | protoc-gen-go-coap | 生成 CoAP 协议(物联网常用)与 proto 消息的互转代码 | 物联网设备通信,适配受限网络环境的协议转换 |
| 数据备份 | protoc-gen-go-backup | 生成数据备份 / 恢复代码,支持 proto 消息批量序列化到存储介质(文件 / 对象存储) | 数据容灾场景,自动处理业务数据的备份与恢复逻辑 |
| 数据备份 | protoc-gen-go-snapshot | 生成数据快照代码,记录 proto 消息的版本变化并支持回滚 | 版本管理场景,如配置变更历史、文档修订记录 |
| 权限管理 | protoc-gen-go-rbac | 生成 RBAC 权限模型代码,基于 proto 定义角色、资源与权限关系 | 权限系统开发,自动生成权限校验与资源访问控制逻辑 |
| 权限管理 | protoc-gen-go-acl | 生成 ACL 访问控制列表代码,将 proto 消息字段与访问权限规则绑定 | 细粒度权限控制,如数据行级权限、字段级权限 |
| 代码生成工具 | protoc-gen-go-template | 基于自定义模板生成任意代码(支持 Go 模板语法),灵活扩展生成逻辑 | 需定制化代码生成场景(如自定义文档、配置文件) |
| 存储扩展 | protoc-gen-go-leveldb | 生成 LevelDB 操作代码,将 proto 消息映射为键值对存储 | 轻量级嵌入式数据库场景,适合读写频繁的小数据 |
二、Proto 插件开发
1. 插件概述
(1)作用
扩展 protoc 的功能,将 Proto 文件解析后的抽象语法树(AST)转化为任意自定义内容(如 Markdown 文档、SQL 创建语句、TypeScript 类型定义等)。
(2)工作原理
protoc 与插件通过标准输入(stdin)/标准输出(stdout) 通信,遵循固定协议(基于 plugin.proto 定义的 CodeGeneratorRequest/CodeGeneratorResponse):
protoc解析 Proto 文件,生成CodeGeneratorRequest(包含所有 Proto 文件的 AST 信息);protoc将CodeGeneratorRequest以二进制形式通过 stdin 传给插件;- 插件解析
CodeGeneratorRequest,生成自定义内容,封装为CodeGeneratorResponse; - 插件将
CodeGeneratorResponse以二进制形式通过 stdout 返回给protoc; protoc输出插件生成的文件到指定目录。
2. 开发前提
(1)环境准备
- 安装
protoc:从 Protobuf Releases 下载对应系统的编译器,添加到环境变量; - 选择开发语言:推荐 Go(官方提供完善的
pluginpb库,且protoc插件生态以 Go 为主); - 安装依赖库(以 Go 为例):
go get google.golang.org/protobuf go get google.golang.org/protobuf/compiler/pluginpb # 插件协议定义 go get google.golang.org/protobuf/proto # Proto 序列化/反序列化
(2)核心概念
插件开发的核心是处理 pluginpb 定义的两个结构体:
CodeGeneratorRequest:protoc传给插件的请求,包含:FileToGenerate:需要处理的 Proto 文件列表;ProtoFile:所有导入的 Proto 文件的 AST(FileDescriptorProto);Parameter:插件的自定义参数(如--xxx_out=param1=value1:./out中的参数)。
CodeGeneratorResponse:插件返回给protoc的响应,包含:File:生成的文件列表(每个文件需指定Name(文件名)和Content(文件内容));Error:错误信息(若插件执行失败,需填充此字段)。
3. 开发步骤(以 Go 为例)
以开发一个生成 Markdown 文档的插件(protoc-gen-protomd) 为例,步骤如下:
步骤 1:初始化项目与目录结构
protoc-gen-protomd/
├── go.mod
├── go.sum
└── main.go # 插件核心逻辑
初始化 Go 模块:
go mod init github.com/your/repo/protoc-gen-protomd
步骤 2:实现插件核心逻辑
插件的入口是 main 函数,需完成 3 件事:
- 从 stdin 读取
CodeGeneratorRequest; - 解析请求中的 Proto 信息,生成 Markdown 内容;
- 构造
CodeGeneratorResponse,写入 stdout。
核心代码(main.go):
package main
import (
"os"
"text/template"
"google.golang.org/protobuf/compiler/pluginpb"
"google.golang.org/protobuf/proto"
"google.golang.org/protobuf/types/descriptorpb"
)
// 生成 Markdown 文档的模板
const mdTemplate = `# Proto 文档:{{.FileName}}
## 消息定义
{{range .Messages}}
### {{.Name}}
| 字段名 | 类型 | 编号 | 说明 |
|--------|------|------|------|
{{range .Fields}}| {{.Name}} | {{.Type}} | {{.Comment}} |
{{end}}
{{end}}
## 枚举定义
{{range .Enums}}
### {{.Name}}
| 枚举值 | 编号 | 说明 |
|--------|------|------|
{{range .Values}}| {{.Name}} | {{.Number}} | {{.Comment}} |
{{end}}
{{end}}
`
// 模板数据结构
type TemplateData struct {
FileName string
Messages []MessageData
Enums []EnumData
}
type MessageData struct {
Name string
Fields []FieldData
}
type FieldData struct {
Name string
Type string
Number int32
Comment string
}
type EnumData struct {
Name string
Values []EnumValueData
}
type EnumValueData struct {
Name string
Number int32
Comment string
}
func main() {
// 1. 读取 CodeGeneratorRequest(从 stdin 读取二进制)
reqBytes, err := os.ReadFile(os.Stdin.Name())
if err != nil {
panic("failed to read request: " + err.Error())
}
req := &pluginpb.CodeGeneratorRequest{}
if err := proto.Unmarshal(reqBytes, req); err != nil {
panic("failed to unmarshal request: " + err.Error())
}
// 2. 处理每个需要生成的 Proto 文件
var responseFiles []*pluginpb.CodeGeneratorResponse_File
for _, fileName := range req.FileToGenerate {
// 找到当前 Proto 文件的 FileDescriptorProto(AST)
var file *descriptorpb.FileDescriptorProto
for _, f := range req.ProtoFile {
if f.GetName() == fileName {
file = f
break
}
}
if file == nil {
panic("file not found: " + fileName)
}
// 解析消息和枚举,构造模板数据
templateData := TemplateData{FileName: fileName}
// 处理消息
for _, msg := range file.MessageType {
msgData := MessageData{Name: msg.GetName()}
// 处理消息的字段
for _, field := range msg.Field {
// 解析字段类型(简化处理,实际需处理嵌套类型、枚举类型等)
fieldType := getFieldTypeName(field, file, req.ProtoFile)
msgData.Fields = append(msgData.Fields, FieldData{
Name: field.GetName(),
Type: fieldType,
Number: field.GetNumber(),
Comment: getComment(field.GetComments()),
})
}
templateData.Messages = append(templateData.Messages, msgData)
}
// 处理枚举
for _, enum := range file.EnumType {
enumData := EnumData{Name: enum.GetName()}
for _, value := range enum.Value {
enumData.Values = append(enumData.Values, EnumValueData{
Name: value.GetName(),
Number: value.GetNumber(),
Comment: getComment(value.GetComments()),
})
}
templateData.Enums = append(templateData.Enums, enumData)
}
// 渲染 Markdown 模板
tpl, err := template.New("protomd").Parse(mdTemplate)
if err != nil {
panic("failed to parse template: " + err.Error())
}
var mdContent []byte
err = tpl.Execute(&mdContent, templateData)
if err != nil {
panic("failed to execute template: " + err.Error())
}
// 构造响应文件(生成的文件名:xxx.proto -> xxx.md)
outputFileName := fileName[:len(fileName)-len(".proto")] + ".md"
responseFiles = append(responseFiles, &pluginpb.CodeGeneratorResponse_File{
Name: proto.String(outputFileName),
Content: proto.String(string(mdContent)),
})
}
// 3. 构造 CodeGeneratorResponse 并写入 stdout
resp := &pluginpb.CodeGeneratorResponse{
File: responseFiles,
}
respBytes, err := proto.Marshal(resp)
if err != nil {
panic("failed to marshal response: " + err.Error())
}
_, err = os.Stdout.Write(respBytes)
if err != nil {
panic("failed to write response: " + err.Error())
}
}
// 辅助函数:获取字段类型名(简化版,实际需处理更多类型)
func getFieldTypeName(field *descriptorpb.FieldDescriptorProto, file *descriptorpb.FileDescriptorProto, allFiles []*descriptorpb.FileDescriptorProto) string {
switch field.GetType() {
case descriptorpb.FieldDescriptorProto_TYPE_INT32:
return "int32"
case descriptorpb.FieldDescriptorProto_TYPE_STRING:
return "string"
case descriptorpb.FieldDescriptorProto_TYPE_BOOL:
return "bool"
case descriptorpb.FieldDescriptorProto_TYPE_ENUM:
// 解析枚举类型(需处理导入的枚举)
enumName := field.GetTypeName() // 格式如 ".package.EnumName"
return enumName[1:] // 去掉开头的 "."
default:
return field.GetType().String()
}
}
// 辅助函数:获取字段/枚举的注释
func getComment(comments *descriptorpb.SourceCodeInfo_Comment) string {
if comments == nil {
return ""
}
return comments.GetLeadingComment() + comments.GetTrailingComment()
}
步骤 3:编译插件
插件必须命名为 protoc-gen-xxx(xxx 为插件名,如本例的 protomd),protoc 会通过 --xxx_out 自动查找该插件。
编译 Go 插件为可执行文件:
# 编译为 protoc-gen-protomd(Windows 为 protoc-gen-protomd.exe)
go build -o protoc-gen-protomd main.go
将插件添加到环境变量(或放在 protoc 可执行文件所在目录),确保 protoc 能找到。
步骤 4:测试插件
创建一个测试用的 Proto 文件(user.proto):
syntax = "proto3";
option go_package = "./userpb;userpb";
// 用户枚举:角色
enum UserRole {
USER_ROLE_UNSPECIFIED = 0; // 未指定角色
USER_ROLE_NORMAL = 1; // 普通用户
USER_ROLE_ADMIN = 2; // 管理员
}
// 用户消息
message User {
int32 id = 1; // 用户ID
string name = 2; // 用户名
optional string email = 3; // 邮箱(可选)
UserRole role = 4; // 用户角色
}
调用 protoc 执行插件,生成 Markdown 文档:
# --protomd_out=./out:使用 protoc-gen-protomd 插件,输出到 ./out 目录
protoc --protomd_out=./out user.proto
执行后,./out 目录下会生成 user.md,内容为自动生成的 Markdown 文档。
4. 常见应用场景
- 生成API 文档(如 Markdown、Swagger);
- 生成数据库操作代码(如 SQL 创建语句、ORM 模型);
- 生成跨语言类型定义(如 TypeScript、Rust);
- 生成验证逻辑代码(如字段非空、长度校验);
- 生成消息转发代码(如 Kafka、RabbitMQ 生产者/消费者)。
5. 开发注意事项
- 命名规范:插件必须命名为
protoc-gen-xxx,否则protoc无法识别; - AST 解析:需正确处理嵌套消息、导入的 Proto 文件、枚举类型等复杂场景,可借助
descriptorpb的字段(如TypeName、NestedType); - 错误处理:插件执行失败时,必须通过
CodeGeneratorResponse.Error返回错误信息,避免protoc崩溃; - 性能优化:对于大型 Proto 文件(如包含数百个消息),需避免重复解析 AST,减少内存占用;
- 兼容性:需兼容 Proto3 和 Proto2 的语法差异(如
required字段、默认值)。
总结
Proto3 的核心是简洁的语法、灵活的数据类型和可扩展的字段规则,适用于构建跨语言的通信协议或数据存储格式;而 Proto 插件开发则是基于 protoc 的 AST 解析能力,扩展自定义代码生成逻辑,大幅提升开发效率。掌握两者可轻松应对复杂的分布式系统或多语言项目需求。这条消息已经在编辑器中准备就绪。你想如何调整这篇文档?请随时告诉我。
数据库
memcached
官方文档
![]()
安装运行
#memcached依赖libevent
brew install memcached
brew services start memcached
启动选项:
- -d是启动一个守护进程;
- -m是分配给Memcache使用的内存数量,单位是MB;
- -u是运行Memcache的用户;
- -l是监听的服务器IP地址,可以有多个地址;
- -p是设置Memcache监听的端口,默认11211;
- -c是最大运行的并发连接数,默认是1024;
- -P是设置保存Memcache的pid文件。
- -h是显示帮助
使用
telnet localhost 11211
存储命令
command <key> <flags> <expiration time> <bytes>
<value>
参数说明如下:
- command set|add|replace|append|prepend
- key key 用于查找缓存值
- flags 可以包括键值对的整型参数,客户机使用它存储关于键值对的额外信息
- expiration time 在缓存中保存键值对的时间长度(以秒为单位,0 表示永远)
- bytes 在缓存中存储的字节数
- value 存储的值(始终位于第二行)
expiration time设置影响
-
缓存雪崩:短时间内大量键超时失效
-
缓存击穿:缓存中没有键值
- 确实不存在:用布隆过滤器优化
- 键超时:设置永不超时,受最大内存限制
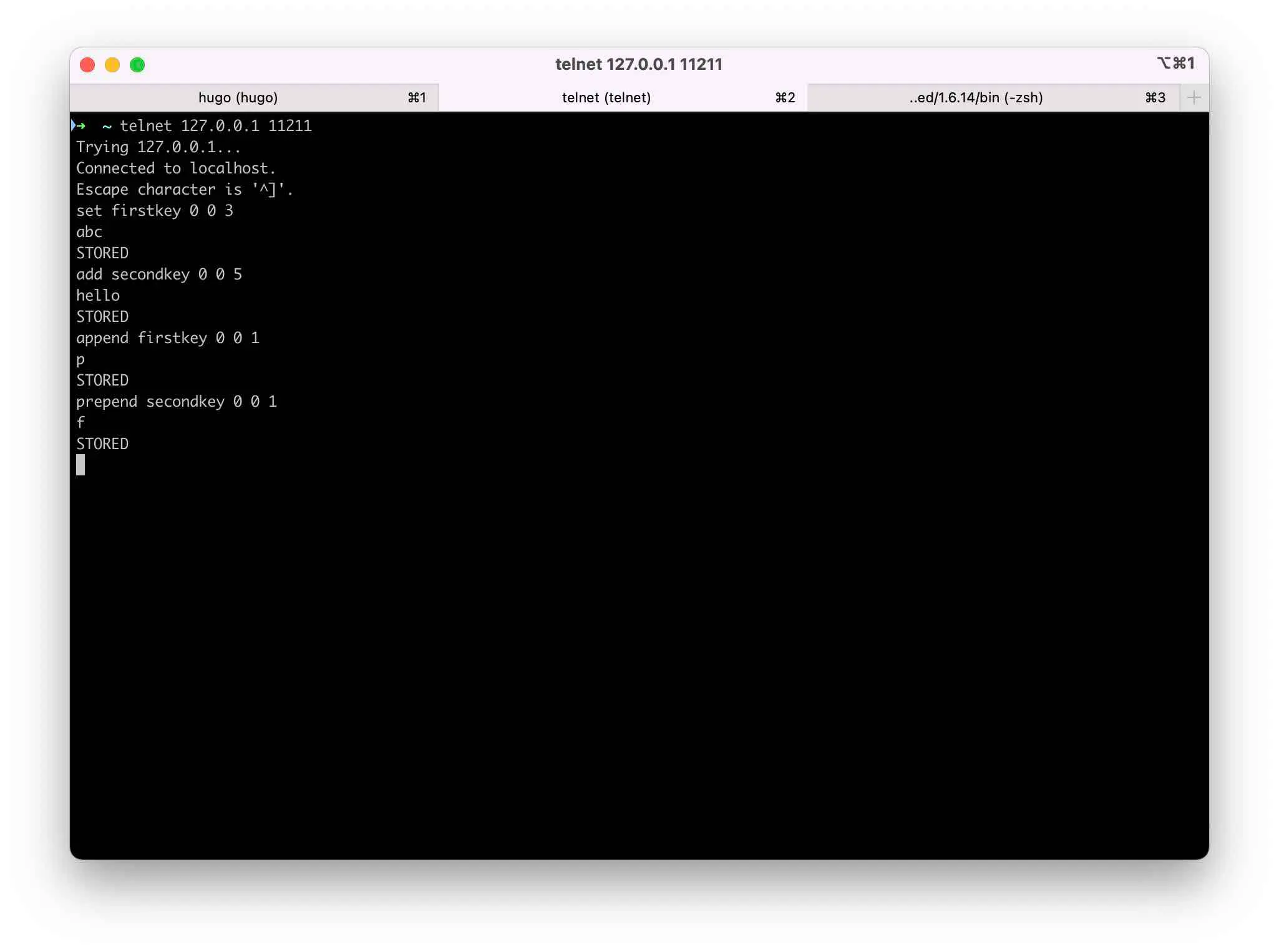
| 命令 | 功能 |
|---|---|
| set | 没有则新增,有则更新,相当于add+replace |
| add | 新增键值,有则不操作 |
| replace | 替换存在键值,没有则不操作 |
| append | 向存在键值后面追加数据,不存在则不操作 |
| prepend | 向存在键值前面追加数据,不存在则不操作 |
查找命令
#多个key用空格隔开
command key key key
| 命令 | 功能 |
|---|---|
| get | 如果不存在,则返回空 |
| gets | 返回值增加CAS令牌 |
删除命令
delete key
增加减少命令
#decr incr
command key value
已存在的 key(键) 的数字值进行自增或自减操作
清空命令
flush_all [time]
可选参数 time,用于在指定的时间后执行清理缓存操作。
源代码proto_proxy.c部分代码
static int process_request(mcp_parser_t *pr, const char *command, size_t cmdlen) {
...
case 4:
if (strncmp(cm, "gets", 4) == 0) {
cmd = CMD_GETS;
type = CMD_TYPE_GET;
token_max = 2; // don't chew through multigets.
ret = _process_request_simple(pr, 2);
} else if (strncmp(cm, "incr", 4) == 0) {
cmd = CMD_INCR;
ret = _process_request_simple(pr, 4);
} else if (strncmp(cm, "decr", 4) == 0) {
cmd = CMD_DECR;
ret = _process_request_simple(pr, 4);
} else if (strncmp(cm, "gats", 4) == 0) {
cmd = CMD_GATS;
type = CMD_TYPE_GET;
ret = _process_request_gat(pr);
} else if (strncmp(cm, "quit", 4) == 0) {
cmd = CMD_QUIT;
}
break;
case 5:
if (strncmp(cm, "touch", 5) == 0) {
cmd = CMD_TOUCH;
ret = _process_request_simple(pr, 4);
} else if (strncmp(cm, "stats", 5) == 0) {
cmd = CMD_STATS;
// Don't process a key; fetch via arguments.
_process_tokenize(pr, token_max);
} else if (strncmp(cm, "watch", 5) == 0) {
cmd = CMD_WATCH;
_process_tokenize(pr, token_max);
}
break;
case 6:
if (strncmp(cm, "delete", 6) == 0) {
cmd = CMD_DELETE;
ret = _process_request_simple(pr, 4);
} else if (strncmp(cm, "append", 6) == 0) {
cmd = CMD_APPEND;
ret = _process_request_storage(pr, token_max);
}
break;
case 7:
if (strncmp(cm, "replace", 7) == 0) {
cmd = CMD_REPLACE;
ret = _process_request_storage(pr, token_max);
} else if (strncmp(cm, "prepend", 7) == 0) {
cmd = CMD_PREPEND;
ret = _process_request_storage(pr, token_max);
} else if (strncmp(cm, "version", 7) == 0) {
cmd = CMD_VERSION;
_process_tokenize(pr, token_max);
}
break;
...
}
集群
-
多个节点,依赖代码库配合实现集群
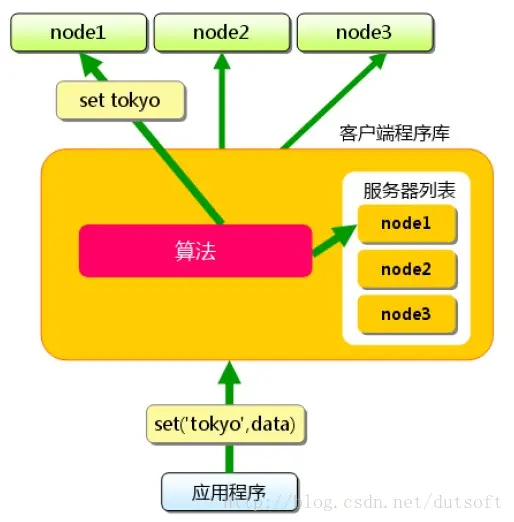
-
减少扩容缩小节点影响,代码算法优化
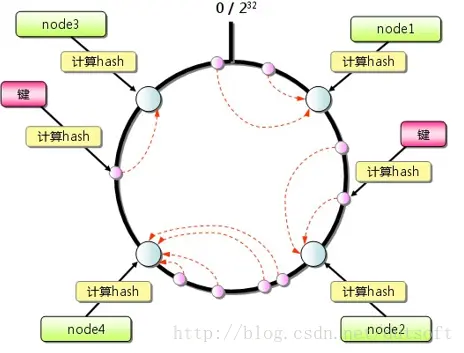
内部结构
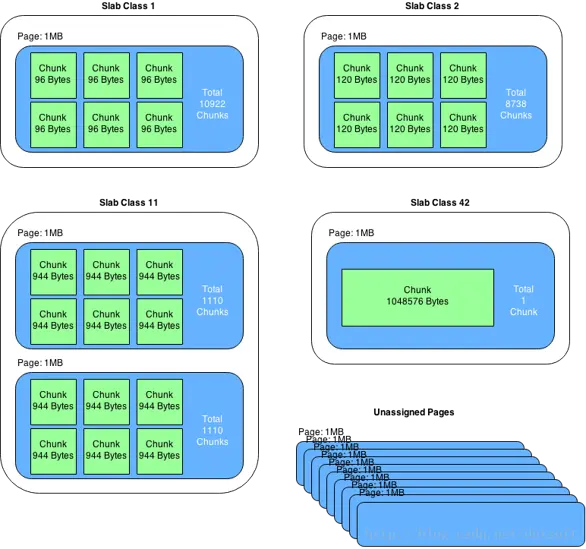
Slab Allocator解决了内存碎片,但由于分配的是特定长度的内存,因此浪费内存
通讯协议
- 文本协议
直接用telnet,nc等工具都可以发送,\r\n表示换行,[]表示可选,会影响回包内容
#存储类命令(set,add等)
<command_name> <key> <flags> <exptime> <bytes>\r\n
#存储内容
<data_block>\r\n
#服务端回包,STORED成功,NOT_STORED失败
STORED\r\n
NOT_STORED\r\n
#删除
delete <key> [<time>] [noreply]\r\n
#服务端回包
DELETED\r\n :表明执行成功
NOT_FOUND\r\n :表明这个键没有找到
#自增减命令(incr,decr)
<command_name> <key> <value> [noreply]\r\n
#服务端回包
NOT_FOUND\r\n :没有找到数据项
<value>\r\n :数据项的新数值,自增或自减以后的值
- 二进制协议
redis
安装运行
brew install redis
brew services start redis
wget https://download.redis.io/redis-stable.tar.gz
tar -xzvf redis-stable.tar.gz
cd redis-stable
make
# If the compile succeeds, you'll find several Redis binaries in the src directory, including:
# redis-server: the Redis Server itself
# redis-cli is the command line interface utility to talk with Redis.
# To install these binaries in /usr/local/bin, run:
make install
自带客户端
#Usage: redis-cli [OPTIONS] [cmd [arg [arg ...]]]
#Examples:
# cat /etc/passwd | redis-cli -x set mypasswd
# redis-cli get mypasswd
# redis-cli -r 100 lpush mylist x
# redis-cli -r 100 -i 1 info | grep used_memory_human:
# redis-cli --quoted-input set '"null-\x00-separated"' value
# redis-cli --eval myscript.lua key1 key2 , arg1 arg2 arg3
# redis-cli --scan --pattern '*:12345*'
#When no command is given, redis-cli starts in interactive mode
#redis-cli的命令提示非常有帮助,比其他终端好用的多
redis-cli
RedisInsight是Redis官方出品的可视化管理工具,可用于设计、开发、优化你的Redis应用
redis4引入自动内存碎片整理
# 开启自动内存碎片整理(总开关),默认no
activedefrag yes
# 当碎片达到 100mb 时,开启内存碎片整理
active-defrag-ignore-bytes 100mb
# 当碎片超过 10% 时,开启内存碎片整理
active-defrag-threshold-lower 10
# 内存碎片超过 100%,则尽最大努力整理
active-defrag-threshold-upper 100
# 内存自动整理占用资源最小百分比
active-defrag-cycle-min 1
# 内存自动整理占用资源最大百分比
active-defrag-cycle-max 25
Notice:开启后,可能特定时间影响redis响应速度
redis5带来了Stream
Redis对消息队列(MQ,Message Queue)的完善实现
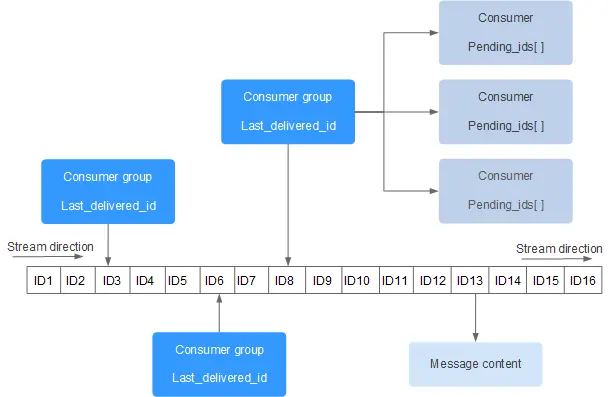
redis6增加了多线程
# io-threads 4
# Setting io-threads to 1 will just use the main thread as usual.
# io-threads-do-reads no
# Note that Gopher is not currently supported when 'io-threads-do-reads'
Redis实例占用相当大的CPU耗时的时候才建议采用,否则使用多线程没有意义。基本上我们都是观众!!!
常用功能
| 功能 | 命令 | 备注 |
|---|---|---|
| String | set,get,setnx,mget,mset,msetnx | 最大512MB,可存任何数据 |
| List | lpush,lpop,rpush,rpop,blpop,brpop,llen,lpushx,lrem,lrange | 超过40亿个元素 |
| Hash | hget,hset,hdel,hgetall,hkeys,hvals,hlen,hmset,hmget | 超过40亿个元素 |
| Set | sadd,spop,srem,scard,smembers,sismember,sdiff,sinter,sunion | 超过40亿个成员 |
| SortedSet | zadd,zrem,zcard,zcount,zscore,zrange | 超过40亿个成员 |
| Pub/Sub | subscribe,publish,unsubscribe | 消息不会保存,广播型 |
| Stream | xadd,xdel,xlen,xread,xgroup,xreadgroup,xinfo,xtrim | 消息会保存,每个消息都是一组键值对,同组竞争,组间广播 |
| Key | del,keys,type,object,ttl,persist,randomkey,rename | 针对键操作 |
| Pipelining | 优点:减少RTT(往返时间),多次网络IO,系统调用的消耗 | 缺点:独占链接,占用redis内存缓存命令结果 |
| Auth | auth password | 验证密码 |
| HyperLogLog | pfadd,pfcount | 基数估计 |


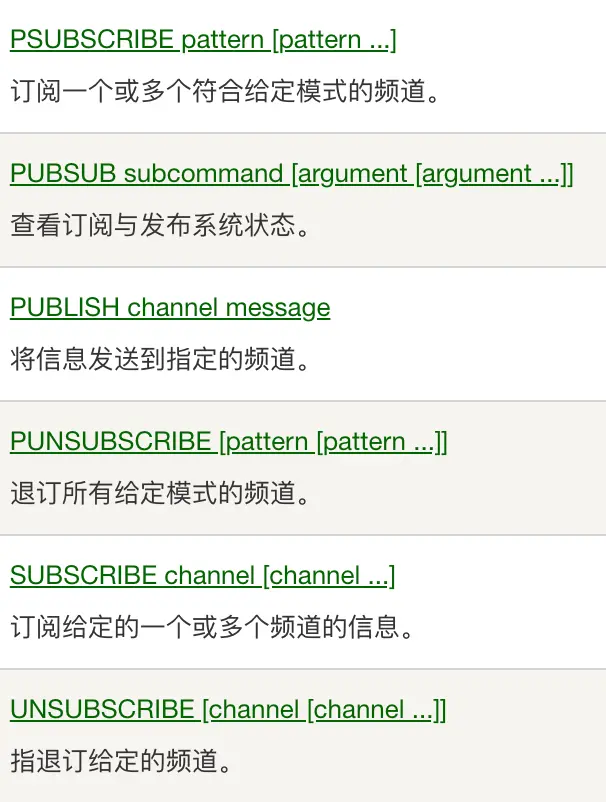

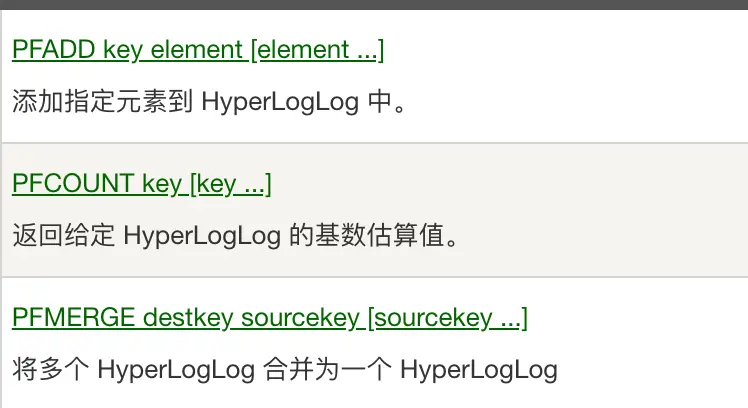
- xreadgroup和xack配合使用
WHILE true
entries = XREADGROUP $GroupName $ConsumerName BLOCK 2000 COUNT 10 STREAMS mystream >
if entries == nil
puts "Timeout... try again"
CONTINUE
end
FOREACH entries AS stream_entries
FOREACH stream_entries as message
process_message(message.id,message.fields)
# ACK the message as processed
XACK mystream $GroupName message.id
END
END
END
常见问题
-
缓存雪崩:短时间内大量键超时失效
-
缓存击穿:缓存中没有键值
- 确实不存在:用布隆过滤器优化
- 键超时:设置永不超时,受最大内存限制
批量删除
--批量删除msg开始的键值
EVAL "return redis.call('del', unpack(redis.call('keys', ARGV[1])))" 0 'msg*'
redis通讯协议-RESP
- 请求协议
- *后面数量表示存在几个$
- $后面数量表示字符串的长度
- 每项用\r\n分隔
*3\r\n$3\r\nSET\r\n$5\r\nmykey\r\n$7\r\nmyvalue\r\n
pipeline实现就是连接发送命令,不用每个都等
常见Redis模块
| 模块名称 | 核心特性 | 适用场景 | 关键命令示例 |
|---|---|---|---|
| RedisJSON | 原生支持 JSON 数据类型,支持 JSONPath 语法,可直接修改 JSON 内部字段 | 存储结构化 JSON 数据(用户信息、配置文件)、需要嵌套数据的场景 | JSON.SET、JSON.GET、JSON.ARRAPPEND |
| RediSearch | 提供全文搜索和次级索引,支持模糊匹配、分词、排序、聚合,可与 RedisJSON 结合 | 实时搜索(商品搜索、日志检索)、多维度数据过滤和排序 | FT.CREATE(建索引)、FT.SEARCH |
| RedisGraph | 基于属性图模型,支持 Cypher 查询语言,高效处理节点与边的关系 | 社交网络关系(好友推荐)、知识图谱、路径分析(如供应链溯源) | GRAPH.QUERY、GRAPH.DELETE |
| RedisTimeSeries | 优化时序数据存储,自动压缩、降采样,支持时间范围查询和聚合(均值、最大值) | 物联网传感器数据、系统监控指标(CPU / 内存)、金融高频交易记录 | TS.CREATE、TS.ADD、TS.RANGE |
| RedisBloom | 包含布隆过滤器、计数布隆过滤器、布谷鸟过滤器,高效判断元素存在性(低内存) | 缓存穿透防护、大数据去重(爬虫 URL)、黑名单 / 白名单判断 | BF.ADD、BF.EXISTS、CF.ADD |
| RedisGears | 服务器端 Python 脚本执行,支持 Map/Reduce、事件触发(如键过期时处理) | 实时数据清洗、分布式任务调度、复杂业务规则计算(如促销价格实时计算) | RG.PYEXECUTE(执行脚本) |
| RedisAI | 加载 TensorFlow/PyTorch 模型,在 Redis 内部执行实时推理,减少数据传输开销 | 实时推荐系统、图像识别、NLP 情感分析(如评论实时分类) | AI.MODELSET、AI.TENSORSET、AI.RUN |
| RedisCell | 基于令牌桶算法的分布式限流,支持突发流量处理,确保多节点规则一致性 | API 接口限流、防止恶意请求(如爬虫)、游戏防作弊(限制操作频率) | CL.THROTTLE(设置限流规则) |
| RedisSQL | 支持 SQL 语法(SELECT/INSERT/UPDATE),映射 Redis 哈希表为 SQL 表 | 从关系型数据库迁移过渡、需要混合使用 SQL 与 Redis 的场景 | SQL SELECT * FROM users |
| HyperLogLog | 估算集合基数(不重复元素数),占用内存极小(约 12KB / 千万级数据) | 统计独立访客(UV)、页面浏览去重、活动参与人数估算 | PFADD、PFCOUNT、PFMERGE |
| Streams | 持久化消息队列,支持发布 - 订阅、消息分组消费,替代 Kafka/RabbitMQ 轻量场景 | 微服务间事件传递(如订单创建)、实时日志收集、游戏服务器消息同步 | XADD(发消息)、XREAD(读消息) |
一、Redis常见用途
1. 核心用途:缓存
应用场景:缓存电商商品详情、用户信息、首页热点数据、复杂查询结果,减轻数据库压力,提升系统响应速度。
常用数据结构:String(缓存单个对象)、Hash(缓存结构化对象,避免序列化开销)。
最佳实践:采用Cache Aside策略保证缓存与数据库一致性;设置随机过期时间避免缓存雪崩。
2. 计数器/限流器
应用场景:视频播放量、文章阅读量、点赞数、商品库存扣减、接口限流(单用户时间窗口内请求控制)、秒杀防超卖。
核心优势:INCR/DECR命令原子性,无并发计数错误;支持过期时间,适配时间窗口统计。
常用命令:INCR/DECR(增减计数)、EXPIRE(设置时间窗口)、SET key value NX(限流判断)。
3. 分布式锁
应用场景:秒杀超卖防护、订单重复生成、分布式系统多节点资源竞争、数据同步一致性保障。
核心原理:获取锁用SET key 唯一值 NX PX 过期时间(NX保证独占,PX防死锁);释放锁用Lua脚本原子操作(校验唯一值后删除,避免误删)。
进阶方案:Redisson框架(自带Watch Dog自动续期);多节点场景用Redlock算法规避单点故障。
4. 消息队列(轻量级场景)
应用场景:异步任务(注册短信/邮件发送)、系统解耦(订单-库存联动)、延迟队列(订单30分钟未支付取消、优惠券过期提醒)。
实现方式:
-
List:LPUSH生产消息,RPOP/BRPOP阻塞消费(避免轮询);
-
Pub/Sub:一对多广播,适用于实时通知、聊天室;
-
Sorted Set:以过期时间为score,ZRANGEBYSCORE获取到期消息,实现延迟队列。
5. 数据去重与统计
| 场景 | 数据结构 | 核心优势 |
|---|---|---|
| 共同好友、抽奖去重、标签交集 | Set | 支持SINTER(交集)、SUNION(并集)、SDIFF(差集) |
| 独立UV统计(日活、页面访问人数) | HyperLogLog | 仅占12KB内存,支持亿级数据基数估算 |
| 签到统计、用户在线状态 | Bitmap | 按位存储,1字节存8个状态,高效节省内存 |
6. 分布式会话存储
应用场景:分布式系统中解决Session共享问题(替代Tomcat本地会话,避免请求跨节点会话丢失)。
核心优势:支持过期时间配置,会话有效期可控;高性能,支撑高并发访问。
7. 排行榜系统
应用场景:游戏积分榜、商品销量榜、直播礼物榜、用户贡献榜。
核心优势:Sorted Set自动按score排序,支持实时更新;ZREVRANGE查前N名、ZRANK查用户排名,百万级数据毫秒级响应。
二、Redis高频问题及核心答案
(一)基础概念类
-
Redis是什么?核心特点? 答:开源基于内存的Key-Value NoSQL数据库,支持持久化、高可用和分布式扩展。核心特点:内存操作快、丰富数据结构、RDB/AOF持久化、主从/哨兵/集群高可用、单线程模型(IO阶段)、支持Lua脚本/发布订阅。
-
Redis与Memcached的区别? 答:数据结构上Redis支持多类型,Memcached仅String;持久化上Redis支持,Memcached不支持;高可用上Redis有原生方案,Memcached需第三方;内存管理Redis淘汰策略更优,Memcached碎片率高。
-
Redis为什么快? 答:① 基于内存,无磁盘IO瓶颈;② 单线程模型,无线程切换和锁竞争;③ IO多路复用技术,高效处理多连接;④ 高效数据结构(SDS、跳表等);⑤ 无上下文切换开销。
(二)核心数据结构类
-
**Redis支持的核心数据结构及底层实现、场景?**数据结构底层实现典型场景StringSDS(简单动态字符串)缓存、计数器、分布式锁Hashziplist→hashtable缓存结构化对象(用户信息)Listziplist→quicklist消息队列、最新列表Setintset→hashtable去重、交集/并集计算Sorted Setziplist→跳表+hashtable排行榜、延迟队列
-
Sorted Set分数范围及注意事项? 答:分数为double类型,范围±1.7976931348623157×10³⁰⁸;有效精度15-17位,整数超9×10¹⁵会丢失精度;相同分数按member字典序排序。
-
跳表原理?Sorted Set为何选跳表而非红黑树? 答:跳表通过多级索引快速定位,查询O(logN);优势:范围查询更高效、实现简单、插入/删除性能稳定(红黑树需维护平衡)。
(三)持久化机制类
-
**RDB与AOF的区别、优缺点?**特性RDB(快照)AOF(追加日志)原理定期将全量数据写入磁盘记录每一条写命令,重启重放优点文件小、恢复快、性能影响小数据安全高、日志可读缺点数据一致性差,易丢失中间数据文件大、恢复慢、写操作有开销
-
混合持久化是什么?优势? 答:Redis4.0+支持,AOF重写时将内存数据以RDB格式写入AOF开头,后续命令以AOF追加;结合RDB恢复快和AOF数据全的优点。
(四)高可用架构类
-
主从复制原理? 答:分三阶段:① 全量复制:从库发SYNC,主库BGSAVE生成RDB并缓存写命令,同步给从库;② 增量复制:全量后主库实时同步写命令;③ 断线重连:通过偏移量和积压缓冲区增量同步。
-
哨兵模式的作用及工作流程? 答:作用:监控主从健康,自动故障转移。流程:① 监控(PING检测节点);② 主观下线(单哨兵判定主库宕机);③ 客观下线(多哨兵共识);④ 选举领头哨兵;⑤ 故障转移(从库升主、同步地址)。
-
Redis Cluster槽位分配规则? 答:共16384个哈希槽;Key通过CRC16(key)%16384计算槽位;槽位分配给节点,通过Gossip协议同步槽位信息;客户端按槽位映射表访问节点。
(五)缓存问题与解决方案类
-
缓存穿透、击穿、雪崩的定义及解决方案?
-
穿透:查缓存和DB都不存在的Key→缓存空值、布隆过滤器、接口校验;
-
击穿:热点Key过期,大量请求穿透→热点Key永不过期、互斥锁、提前预热;
-
雪崩:大量Key同时过期或Redis宕机→过期时间随机化、多级缓存、Redis高可用、限流降级。
-
-
如何保证缓存与数据库一致性? 答:推荐Cache Aside策略:读(缓存→DB→写缓存);写(更DB→删缓存);删除失败用重试机制或消息队列保证最终一致。
(六)高级特性与性能优化类
-
过期策略与内存淘汰机制? 答:过期策略:惰性删除(访问时检查)+定期删除(随机抽样删除);内存淘汰机制(maxmemory-policy):volatile-lru(过期Key中LRU)、allkeys-lru(所有Key中LRU,生产常用)、noeviction(默认,拒绝写)。
-
Redis性能优化手段?
- 避免大Key,拆分结构化数据;
- 用Pipeline减少网络往返;
- AOF刷盘策略设为everysec;
- 合理配置LRU淘汰策略;
- 禁用KEYS、FLUSHDB,用SCAN遍历;
- 优化连接参数(tcp-backlog等)。
mysql
SQL
-
mysql没有完全实现sql标准
-
不区分大小写,一般内置关键词,函数等采用大写,用户表,列,参数采用小写
-
用分号作为结束语句标识,允许一行多条语句,一条语句多行.
-
有不同模式,建议采用strict mode
-
默认autocommit,除非显式取消
-
注释
- 单行: 以#开头,到行结束
- 单行: 以– 开头,到行结束
- 多行: /开头,/结束,c风格
-
字符集(Character)与校对规则(Collation)
- 字符集都对应着一个默认的校对规则,也可以对应多个规则
- 变量character_set_server记录服务器默认值,mysql8.0默认是utf8mb4(可储各种表情符号,最长4字节)
- 每个库/表/字段可单独指定,库不指定则用服务器,表不指定则用库,字段不指定则用表
- character_set_client服务器认为客户端发送过来的sql语句的编码
- character_set_conneciton执行sql内部编码,所以服务器把客户端发送的sql从character_set_client转为character_set_conneciton
- character_set_results 返回结果集
- 客户端用连接参数一次性指定这三个值character_set_client, character_set_results, character_set_connection
-
自带4个数据库
- information_schema 保存所有数据库/表/列/索引/权限等信息
- performance_schema 收集数据库服务器性能参数,资源消息,资源等待
- sys 存储来自performance_schema,简化说明,易于DBA理解
- mysql 存储库用户,权限,关键字等mysql自已需要必要信息
-
程序表
名称 作用 mysqld 服务器 mysqld_safe 用来启动mysqld的脚本 mysql.server 系统启动脚本,调用mysqld_safe脚本 mysqld_multi 允许同时多个mysqld进程 mysql 客户端 mysqladmin 客户端管理数据库 mysqldump 客户端导出数据 mysqlimport 客户端导入数据 -
联表
...
joined_table: {
table_reference {[INNER | CROSS] JOIN | STRAIGHT_JOIN} table_factor [join_specification]
| table_reference {LEFT|RIGHT} [OUTER] JOIN table_reference join_specification
| table_reference NATURAL [INNER | {LEFT|RIGHT} [OUTER]] JOIN table_factor
}
join_specification: {
ON search_condition
| USING (join_column_list) }
...
-
JOIN, CROSS JOIN, and INNER JOIN等价,和sql标准不相同
// 简化翻译sql逻辑 // select tbl1.col1, tbl2.col2 from tbl1 inner join tbl2 using(col3) where tbl1.col1 in (5, 6); // 内联没有指明驱动表,优化器会根据过滤行数少作为驱动表,这里假设选择tbl1作为驱动表 // STRAIGHT_JOIN用来指定哪个表作为驱动表,示例如下: // select tbl1.col1, tbl2.col2 from tbl1 STRAIGHT_JOIN tbl2 using(col3) where tbl1.col1 in (5, 6); outer_iter = iterator over tbl1 where col1 in (5, 6) outer_row = outer_iter.next while outer_row inner_iter = iterator over tbl2 where col3 = outer_row.col3 inner_row = inner_iter.next while inner_row output [ outer_row.col1, inner_row.col2] inner_row = inner_iter.next end outer_row = outer_iter.next end -
LEFT, RIGHT [OUTER] JOIN,外连关键词(outer)可省略,写不写都是一样功能
// 简化翻译sql逻辑 // select tbl1.col1, tbl2.col2 from tbl1 left outer join tbl2 using(col3) where tbl1.col1 in (5, 6); // left,right表明了哪个表作为驱动表 outer_iter = iterator over tbl1 where col1 in (5, 6) outer_row = outer_iter.next while outer_row inner_iter = iterator over tbl2 where col3 = outer_row.col3 inner_row = inner_iter.next if inner_row while inner_row output [ outer_row.col1, inner_row.col2] inner_row = inner_iter.next end else output [ outer_row.col1, null] end outer_row = outer_iter.next end -
FULL OUTER JOIN暂不支持
-
NATURAL表示join_specification采用USING(join_column_list),不用手动写出来,join_column_list选取两个表都有的列名
-
EXPLAIN/DESCRIBE/DESC 作用一样的
-- 获取表结构/信息 {EXPLAIN | DESCRIBE | DESC} tbl_name [col_name | wild] -- 获取执行计划信息 {EXPLAIN | DESCRIBE | DESC} [explain_type] {explainable_stmt | FOR CONNECTION connection_id} -- 获取更详执行计划细信息 {EXPLAIN | DESCRIBE | DESC} ANALYZE [FORMAT = TREE] select_statement explain_type: { FORMAT = format_name } format_name: { TRADITIONAL | JSON | TREE } explainable_stmt: { SELECT statement | TABLE statement | DELETE statement | INSERT statement | REPLACE statement | UPDATE statement } -
help语句
-- 显示select语句语法,较便利
HELP 'select'
数据类型
-
数字,默认是有符号(SIGNED),无符号(UNSIGNED)要特别指定
类型 字节数 TINYINT 1 SMALLINT 2 MEDIUMINT 3 INT 4 BIGINT 8 FLOAT 4 DOUBLE 8 DECIMAL 二进制存储 - 其他有一些别名
- All arithmetic is done using signed BIGINT or DOUBLE values
-
时间
类型 范围 零值 说明 DATE ‘1000-01-01’到’9999-12-31’ ‘0000-00-00’ 年月日 TIME ‘-838:59:59.000000’到’838:59:59.000000’ ‘00:00:00’ 时分秒 DATETIME ‘1000-01-01 00:00:00’到’9999-12-31 23:59:59’ 0000-00-00 00:00:00 年月日时分秒 TIMESTAMP ‘1970-01-01 00:00:01.000000’到’2038-01-19 03:14:07.999999’ 0000-00-00 00:00:00 时间戳 YEAR 别用 ‘0000’ 别用,有坑 - TIME,DATETIME,TIMESTAMP默认精确到秒,增加参数指定精确小数,最多到6位
create table mytime ( id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY, -- '00:00:00.000000' t TIME(6) not null, -- '1000-01-01 00:00:00.00000' dt DATETIME(5) not null, ts TIMESTAMP(4) not null, t2 TIME(3) not null, dt2 DATETIME(2) not null, ts2 TIMESTAMP(1) not null );- DATETIME,TIMESTAMP都可以用DEFAULT CURRENT_TIMESTAMP指定默认值
-
字符串
-
char
- CHAR(len),VARCHAR(len)最多储存len个char字符,储存占用字节由字符集处理
- char固定大小,varchar变化大小,指消费储存占用字节
- varchar默认去尾空格空白
-
binary
- BINARY(len),VARCHAR(len)最多储存len个字节,字符集转化字符后字节
-
短字符串 | 字符存储 | 字节存储 | | – | – | | char | binary | | varchar | varbinary |
-
长字符串 | text(字符存储,类似char) | blob(字节存储,类似binary) | | – | – | | tinytext | tinyblob | | mediumtext | mediumblob | | text | blob | | longtext | longblob |
-
-
json
create table js(v json); insert into js(v) values('[10, 20, 30]'); insert into js(v) values('{"a":10}');
分区表
-
分类类型
- RANGE,分区必须指定范围
CREATE TABLE employees ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job_code INT NOT NULL, store_id INT NOT NULL ) PARTITION BY RANGE (store_id) ( PARTITION p0 VALUES LESS THAN (6), PARTITION p1 VALUES LESS THAN (11), PARTITION p2 VALUES LESS THAN (16), PARTITION p3 VALUES LESS THAN MAXVALUE );- LIST,分区必须指定集合,每条记录只能属于其中一个集合
CREATE TABLE person ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job_code INT, store_id INT ) PARTITION BY LIST(store_id) ( PARTITION pNorth VALUES IN (3, 5, 6, 9, 17), PARTITION pEast VALUES IN (1, 2, 10, 11, 19, 20), PARTITION pWest VALUES IN (4, 12, 13, 14, 18), PARTITION pCentral VALUES IN (7, 8, 15, 16) );- HASH,注意hash分布,造成热点分区
CREATE TABLE worker ( id INT NOT NULL, fname VARCHAR(30), lname VARCHAR(30), hired DATE NOT NULL DEFAULT '1970-01-01', separated DATE NOT NULL DEFAULT '9999-12-31', job_code INT, store_id INT ) PARTITION BY [LINEAR] HASH(store_id) PARTITIONS 4; -- LINEAR 带上则指定hash算法- KEY,隐式hash,服务器采用hash(key)实现,可任意类型
CREATE TABLE tm1 (s1 CHAR(32) PRIMARY KEY) PARTITION BY KEY(s1) PARTITIONS 10; -
分区pruning
# where子句能够转化为下面两种,optimizer优化器就能选定分区,省去不必要查找
partition_column = constant
partition_column IN (constant1, constant2, ..., constantN)
# select update delete 都需要注意
# insert 只会影响一个分区,不必考虑分区修剪
-
Subpartitioning 子分区
-
select语法
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr] ...
[into_option]
[FROM table_references
[PARTITION partition_list]]
[WHERE where_condition]
[GROUP BY {col_name | expr | position}, ... [WITH ROLLUP]]
[HAVING where_condition]
[WINDOW window_name AS (window_spec)
[, window_name AS (window_spec)] ...]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
[into_option]
[FOR {UPDATE | SHARE}
[OF tbl_name [, tbl_name] ...]
[NOWAIT | SKIP LOCKED]
| LOCK IN SHARE MODE]
[into_option]
into_option: {
INTO OUTFILE 'file_name'
[CHARACTER SET charset_name]
export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name] ...
}
- insert
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[(col_name [, col_name] ...)]
{ {VALUES | VALUE} (value_list) [, (value_list)] ... }
[AS row_alias[(col_alias [, col_alias] ...)]]
[ON DUPLICATE KEY UPDATE assignment_list]
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[AS row_alias[(col_alias [, col_alias] ...)]]
SET assignment_list
[ON DUPLICATE KEY UPDATE assignment_list]
INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[(col_name [, col_name] ...)]
[AS row_alias[(col_alias [, col_alias] ...)]]
{SELECT ...
| TABLE table_name
| VALUES row_constructor_list
}
[ON DUPLICATE KEY UPDATE assignment_list]
-
实例解释
-- 每列采用默认值插入 INSERT INTO tbl_name () VALUES(); -- 允许后面出现的列引用前面列值 -- AUTO_INCREMENT在列赋值之后,所以引用此列值会为0 INSERT INTO tbl_name (col1,col2) VALUES(15,col1*2); -- With INSERT ... SELECT插入多行,速度较快,ta表中AUTO_INCREMENT仍然自增,先赋值才执行AUTO_INCREMENT -- 等价于 INSERT INTO ta SELECT * FROM tb INSERT INTO ta TABLE tb; -- 附上DUPLICATE,要求a,b,c至少一个是唯一或主键 -- 当多个是唯一或主键时,任选一个执行 -- UPDATE t1 SET c=c+1 WHERE a=1 OR b=2 LIMIT 1; INSERT INTO t1 (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=c+1; -- VALUES(colname)用来引用指定列插入值,相当于下面两句结果 -- INSERT INTO t1 (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=3; -- INSERT INTO t1 (a,b,c) VALUES (4,5,6) ON DUPLICATE KEY UPDATE c=9; INSERT INTO t1 (a,b,c) VALUES (1,2,3),(4,5,6) ON DUPLICATE KEY UPDATE c=VALUES(a)+VALUES(b); -
delete
-
删除自增字段不会重用
-
单表
DELETE [LOW_PRIORITY] [QUICK] [IGNORE] FROM tbl_name [[AS] tbl_alias] [PARTITION (partition_name [, partition_name] ...)] [WHERE where_condition] -- 删除顺序,配合limit可用来分段删除 [ORDER BY ...] -- 限制删除行数,通常用来防止删除影响其他业务,每次只删除部分,多次删除 [LIMIT row_count]- 多表
DELETE [LOW_PRIORITY] [QUICK] [IGNORE] -- 删除在from之前的表中行 tbl_name[.*] [, tbl_name[.*]] ... FROM table_references [WHERE where_condition] DELETE [LOW_PRIORITY] [QUICK] [IGNORE] -- 删除在from子句中表的行 FROM tbl_name[.*] [, tbl_name[.*]] ... USING table_references [WHERE where_condition]- 大表删除多行,InnoDB引擎优化
-- 把不删除数据插入一张新表中 INSERT INTO t_copy SELECT * FROM t WHERE ... ; -- 新表,老表互换名字 RENAME TABLE t TO t_old, t_copy TO t; -- 删除老表,但名字为改名后 DROP TABLE t_old; -
-
replace
REPLACE [LOW_PRIORITY | DELAYED]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[(col_name [, col_name] ...)]
{ {VALUES | VALUE} (value_list) [, (value_list)] ...
|
VALUES row_constructor_list
}
REPLACE [LOW_PRIORITY | DELAYED]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
SET assignment_list
REPLACE [LOW_PRIORITY | DELAYED]
[INTO] tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[(col_name [, col_name] ...)]
{SELECT ... | TABLE table_name}
- update
UPDATE [LOW_PRIORITY] [IGNORE] table_reference
SET assignment_list
[WHERE where_condition]
[ORDER BY ...]
[LIMIT row_count]
特有功能
show databases;
use databasename;
show tables;
describe tablename;
#从本地导入数据
#windows用\r\n,mac用\r,linux用\n
LOAD DATA LOCAL INFILE '/path/pet.txt' INTO TABLE tablename LINES TERMINATED BY '\r\n';
#mysql查变量,获取mysql默认行为,各种参数值
SHOW VARIABLES;
#只关注想要的
SHOW VARIABLES LIKE '%timeout%'
# 查看客户端连接详情,用来检查执行客户端的sql情况,特别慢查询,多连接
show full processlist;
#客户端连接数
select client_ip,count(client_ip) as client_num
from (select substring_index(host,':' ,1) as client_ip from information_schema.processlist ) as connect_info
group by client_ip order by client_num desc;
#执行sql时间倒序
select * from information_schema.processlist where Command != 'Sleep' order by Time desc;
# 查看表创建语句
show create table xx;
#mysql关闭安全模式
show variables like 'SQL_SAFE_UPDATES';
SET SQL_SAFE_UPDATES = 0;
#通用日志,调试好帮手,需要root权限
show variables like '%general%';
set @@global.general_log=1;
set @@global.general_log=0;
# 设置连接超时时间,下次登陆有效
show variables like '%timeout%';
--604800=60*60*24
set @@GLOBAL.interactive_timeout=604800;
set @@GLOBAL.wait_timeout=604800;
# 查看默认引擎
show engines;
# 查询表中重复数据
select col from table group by col having count(col) > 1;
# 带忽略重复的插入
insert ignore into table(name) value('xx')
# 常用时间函数
FROM_UNIXTIME(unix_timestamp)是MySQL里的时间函数。
UNIX_TIMESTAMP('2018-09-17') 是与之相对正好相反的时间函数 。
# IF条件表达式
IF(expr1,expr2,expr3)
--如果 expr1 为真(expr1 <> 0 以及 expr1 <> NULL),那么 IF() 返回 expr2,否则返回 expr3。IF() 返回一个数字或字符串,这取决于它被使用的语境:
#concat把int转varchar类型
update user set nickname = concat(id,'号') where id > 0;
# 字符串替换
update user set nickname = REPLACE(id,'old', 'now') where id > 0
# 查询数据库占用空间及索引空间
# Binlog,阿里云的rds默认把它也计算在内,要手动设置控制大小.大量数据删除时,会突然增加Binlog文件
select TABLE_NAME, concat(truncate(data_length/1024/1024,2),' MB') as data_size,
concat(truncate(index_length/1024/1024,2),' MB') as index_size
from information_schema.tables where TABLE_SCHEMA = 'databaseName'
# 修改root密码
killall mysqld
mysqld_safe --skip-grant-tables &
update mysql.user set password=PASSWORD('newpassword') where user='root';
flush privileges;
mysqld_safe &
# 设置默认字符集
mysql -u user -D db --default-character-set=utf8 -p
explain优化sql
explain select col from table where con group by xx order by yy;
输出说明:
- table 显示该语句涉及的表
- type 这列很重要,显示了连接使用了哪种类别,有无使用索引,反映语句的质量。
- possible_keys 列指出MySQL能使用哪个索引在该表中找到行
- key 显示MySQL实际使用的键(索引)。如果没有选择索引,键是NULL。
- key_len 显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。使用的索引的长度。在不损失精确性的情况下,长度越短越好
- ref 显示使用哪个列或常数与key一起从表中选择行。
- rows 显示MySQL认为它执行查询时必须检查的行数。
- extra 包含MySQL解决查询的详细信息。
- 其中:Explain的type显示的是访问类型,是较为重要的一个指标,结果值从好到坏依次是: system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL(优–>差) 一般来说,得保证查询至少达到range级别,最好能达到ref,否则就可能会出现性能问题
碎片产生的原因
- 表的存储会出现碎片化,每当删除了一行内容,该段空间就会变为空白、被留空,而在一段时间内的大量删除操作,会使这种留空的空间变得比存储列表内容所使用的空间更大;
- 当执行插入操作时,MySQL会尝试使用空白空间,但如果某个空白空间一直没有被大小合适的数据占用,仍然无法将其彻底占用,就形成了碎片;
- 当MySQL对数据进行扫描时,它扫描的对象实际是列表的容量需求上限,也就是数据被写入的区域中处于峰值位置的部分;
- 清除不要数据,记得要optimize table xx;不然空间仍旧占用.
例如: 一个表有1万行,每行10字节,会占用10万字节存储空间,执行删除操作,只留一行,实际内容只剩下10字节,但MySQL在读取时,仍看做是10万字节的表进行处理,所以,碎片越多,就会越来越影响查询性能。
免密码登陆
-
利用.my.cnf
vi ~/.my.cnf [client] # 注意mysql的库中user表,localhost和127.0.0.1区别 host = "127.0.0.1" user = "user" password = "pwd" database = "xx" -
利用命令行参数,或者别名
mysql -h localhost -u root -p xxx
小知识
- 哪个是JOIN,哪个是过滤器?
-- 隐式内联,不好理解容易出错,不建议
-- a,b ==> inner join 简写
-- a.ID = b.ID ==> 用来关联,不是过滤,
SELECT * FROM a,b WHERE a.ID = b.ID
-- 显示内联,建议这种
-- a JOIN b ==> inner join
SELECT * FROM a JOIN b ON a.ID = b.ID
-- USING(ID) == > ON a.ID = b.ID
-- 要求两个表都存在ID列
SELECT * FROM a JOIN b USING(ID)
- 分组连接
select sch_id, count(sch_id) as c, GROUP_CONCAT(sch_name) from sch_basic_info sbi group by sch_id HAVING count(sch_id) > 1 order by c desc;
select GROUP_CONCAT(sch_name) from sch_basic_info sbi group by sch_id HAVING count(sch_id) > 1;
- 支持opengis,geometry
- Geometry (noninstantiable)
- Point (instantiable)
- Curve (noninstantiable)
- LineString (instantiable)
- Line
- LinearRing
- Surface (noninstantiable)
- Polygon (instantiable)
- GeometryCollection (instantiable)
- MultiPoint (instantiable)
- MultiCurve (noninstantiable)
- MultiLineString (instantiable)
- MultiSurface (noninstantiable)
- MultiPolygon (instantiable)
附录
MySQL慢SQL优化
graph LR 定位问题 --> 分析原因 --> 优化 --> 验证 --> 预防
定位问题
开启慢查询日志
慢查询日志是MySQL记录执行时间超过阈值的SQL的专用日志,是定位慢SQL的基础
临时开启(重启失效)
-- 开启慢查询日志
SET GLOBAL slow_query_log = 1;
-- 设置慢查询阈值(单位:秒,建议设1秒,捕捉临界慢SQL)
SET GLOBAL long_query_time = 1;
-- 指定日志文件路径(可选)
SET GLOBAL slow_query_log_file = '/var/lib/mysql/slow.log';
-- 记录未使用索引的SQL(即使执行快,也建议开启,提前发现索引问题)
SET GLOBAL log_queries_not_using_indexes = 1;
永久开启(修改配置文件my.cnf/my.ini)
[mysqld]
slow_query_log = 1
long_query_time = 1
slow_query_log_file = /var/lib/mysql/slow.log
log_queries_not_using_indexes = 1
修改后重启MySQL生效:
systemctl restart mysqld
分析慢查询日志
直接看日志文件内容杂乱,推荐用MySQL自带的mysqldumpslow工具分析:
# 按执行时间排序,取前10条慢SQL
mysqldumpslow -s t -t 10 /var/lib/mysql/slow.log
# 按查询次数排序,取前10条高频慢SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/slow.log
• 补充:实时排查可使用show processlist;关注Time(执行时间)、State(状态,如Sending data/Creating tmp table表示执行慢)、Info(SQL内容)字段。
注意点
• 把long_query_time设得太大,漏掉“临界慢SQL”,这些SQL高并发下会放大性能问题;
• 只看日志不结合业务,比如把“凌晨批量统计SQL”当成常规慢SQL优化,忽略业务场景。
分析原因
用explain分析执行计划,定位到底是“没走索引”“扫描行数多”还是“排序/临时表导致慢”
示例语句
EXPLAIN SELECT * FROM `order` WHERE user_id = xx AND create_time >= 'xxxx-yy-dd';
核心字段
| 字段 | 核心含义 | 优化目标 |
|---|---|---|
| type | 访问类型(从优到差:system>const>eq_ref>ref>range>index>ALL) | 至少达到range,避免ALL(全表扫描) |
| key | 实际使用的索引(NULL表示未走索引) | 非NULL,且是最优索引 |
| rows | 预估扫描行数(越接近实际结果越准) | 越小越好 |
| Extra | 额外信息(核心标识) | 避免Using filesort/Using temporary |
常见案例
• 案例1:type=ALL + key=NULL → 全表扫描,未走索引,核心优化方向是加索引;
• 案例2:Extra=Using filesort → SQL需要排序但未走索引排序,需优化排序字段的索引;
• 案例3:Extra=Using temporary → SQL用到临时表(如group by/join),需优化关联/分组逻辑。
易犯错误
• 只关注type字段,忽略Extra(比如type=ref但Extra=Using filesort,依然是慢SQL);
• 认为rows是“实际扫描行数”,其实是预估值,需结合业务数据量判断。
优化
graph LR sql写法 --> 索引 --> 表结构 --> 服务器配置
SQL写法
| 错误写法(慢) | 正确写法(快) | 优化原因 |
|---|---|---|
| SELECT * FROM user WHERE id IN (a,b,c) | SELECT id, name, phone FROM user WHERE id IN (a,b,c) | 避免查询无用字段,减少IO/内存消耗 |
| SELECT * FROM order WHERE DATE(create_time) = ‘xxxx-yy-dd’ | SELECT * FROM order WHERE create_time >= ‘xxxx-yy-dd’ AND create_time < ‘xxxx-yy-dd’ | 索引字段做函数操作会导致索引失效 |
| SELECT * FROM order WHERE user_id IN (SELECT id FROM user WHERE age>x) | SELECT o.* FROM order o JOIN user u ON o.user_id=u.id WHERE u.age>x | 子查询会创建临时表,JOIN效率更高 |
| SELECT * FROM goods WHERE name LIKE ‘%xxx%’ | SELECT * FROM goods WHERE name LIKE ‘xx%’(业务允许)或用全文索引 | %xxx会导致索引失效,xxx%不会 |
索引
索引是解决慢SQL的核心,但“不是建越多越好”,需精准建、合理删。
几个方向
-
按“最左前缀原则”建联合索引:比如查询WHERE a=1 AND b=2 AND c=3,建(a,b,c)而非单独的a/b/c索引;
-
用覆盖索引减少回表:查询的字段都在索引里(Extra=Using index),比如SELECT id, name FROM user WHERE code=‘xxxxx’,建(code, name)索引;
-
删除无用索引:单表索引控制在5个以内,避免写操作(INSERT/UPDATE/DELETE)维护索引的开销;
-
避免索引失效场景:如隐式类型转换(字符串字段用数字查)、OR连接无索引字段等。
表结构
适合表数据量大(百万/千万级)或字段设计不合理的场景:
-
反范式设计:比如订单表存user(而非每次关联用户表),减少JOIN次数;
-
水平分表:按时间/用户ID拆分大表(如order_xxx/order_yy);
-
垂直分表:拆分大字段(如把商品表的desc拆到另外表);
• 字段类型优化:用更小的类型(如tinyint存性别、datetime存时间,而非varchar)。
服务器
调整MySQL配置参数:
-
innodb_buffer_pool_size:建议设为物理内存的60%,让更多数据缓存在内存,减少磁盘IO;
-
sort_buffer_size:调整排序缓存,避免排序时使用临时文件;
-
max_connections:合理设置最大连接数,避免连接数不足导致SQL阻塞。
架构优化
适合单库单表支撑不了的场景
- 读写分离:主库写、从库读,读写分流
- 缓存:用Redis,Memcached缓存热点数据(如商品详情、用户信息)
- 分库分表:用中间服务转发,综合数据
- 拆分业务:引入其他类型数据库,例如es做多条件分页查询
注意点
- 过早做架构优化(比如小表也分库分表),增加系统复杂度;
- 盲目加索引,导致写操作性能暴跌
- 调大所有配置参数,导致服务器内存溢出。
验证
优化后必须验证,避免“越改越慢”:
-
重新执行EXPLAIN,检查type/key/Extra是否改善;
-
统计执行时间:
SET profiling = 1;
SELECT id, name FROM user WHERE code='xxx';
SHOW PROFILES;
- 对比优化前后的“执行时间”“扫描行数”“CPU/IO占用”
预防
-
制定SQL规范:禁止SELECT *、禁止大表全表扫描、禁止在索引字段做函数操作;
-
定期审计:每周用mysqldumpslow分析慢查询日志,提前发现问题;
-
压测:压测工具模拟高并发,验证SQL性能;
-
监控告警:对接监控平台,慢SQL触发时及时告警。
GQL
- 一种专为属性图模型设计的图查询语言
- 这是继SQL之后第二个数据库查询语言标准
二、GQL的核心数据模型:属性图(Property Graph)
GQL的所有操作都基于属性图模型,这是图数据的“基本结构单元”,需明确其四大核心元素:
| 元素 | 定义与特点 | 示例 |
|---|---|---|
| 节点(Node) | 表示“实体”(如人、商品、订单),可携带属性(键值对),并可被标签(Label) 分类。 | 节点(u:User {id: 1, name: "Alice"}),标签为User,属性为id和name。 |
| 关系(Relationship) | 表示节点间的“关联”(如“关注”“购买”“属于”),有方向(体现关系的语义,如“A关注B”≠“B关注A”),可携带属性,且有唯一类型(Type) 。 | 关系(u)-[r:FOLLOWS {since: 2023}]->(v),类型为FOLLOWS,属性为since。 |
| 属性(Property) | 附着于节点或关系的“键值对数据”,支持多种数据类型(字符串、数字、布尔、列表、结构等)。 | 节点属性age: 30、关系属性weight: 0.8(表示关系权重)。 |
| 路径(Path) | 由“节点-关系”交替组成的序列(如u->v->w),表示多实体间的间接关联,是图查询的核心对象之一。 | 路径(u:User)-[:FOLLOWS]->(v:User)-[:POSTED]->(p:Post)(Alice关注的用户发布的帖子)。 |
三、GQL的核心查询能力(核心语法模块)
GQL的查询语法围绕“模式匹配”(图查询的灵魂)展开,同时支持传统数据库的过滤、聚合等能力,核心模块如下:
1. 模式匹配(Pattern Matching):图查询的核心
模式匹配是GQL区别于SQL的核心能力,通过“描述图的结构模式”来定位数据,语法与Cypher类似,支持节点模式、关系模式和复合模式。
-
基础语法:用
()表示节点,用-[]->表示有向关系,组合成“模式”后用MATCH关键字匹配。 -
示例1:匹配单个节点
查找所有标签为User、且age > 25的用户:MATCH (u:User) WHERE u.age > 25 RETURN u.name, u.age; -
示例2:匹配节点+关系的复合模式
查找“Alice关注的用户发布的帖子”:MATCH (alice:User {name: "Alice"})-[:FOLLOWS]->(friend:User)-[:POSTED]->(post:Post) RETURN post.title, post.createTime; -
关键特性:支持“可选匹配”(
OPTIONAL MATCH),即模式中部分结构不存在时仍返回结果(类似SQL的LEFT JOIN)。
2. 路径查询(Path Query):遍历多步关联
路径是GQL的核心返回对象,支持查询“节点间的所有路径”“最短路径”“指定长度的路径”,解决层级/网状结构的遍历问题(如族谱、供应链溯源)。
-
核心语法:通过
MATCH匹配路径模式,用PATH关键字显式定义路径变量,或直接返回路径。 -
示例1:查询指定长度的路径
查找“Alice到Bob的2~3步间接关系路径”(如Alice→C→Bob,Alice→C→D→Bob):MATCH path = (alice:User {name: "Alice"})-[*2..3]->(bob:User {name: "Bob"}) RETURN path; -
示例2:查询最短路径
GQL内置shortestPath()函数,查找两节点间的最短关联:MATCH shortestPath(path = (a:City {name: "Beijing"})-[*]->(b:City {name: "Shanghai"})) RETURN path;
3. 数据操纵(Data Manipulation):增删改
GQL标准化了图数据的全生命周期操作,语法简洁且与查询逻辑一致:
| 操作类型 | 关键字 | 功能描述 | 示例 |
|---|---|---|---|
| 新增 | CREATE | 创建节点、关系或路径 | CREATE (u:User {id: 2, name: "Bob"}) |
| 删除 | DELETE | 删除节点或关系(删除节点前需先删除关联关系) | MATCH (u:User {name: "Bob"}) DELETE u |
| 更新 | SET/REMOVE | 新增/修改属性(SET)、删除属性/标签(REMOVE) | MATCH (u:User {name: "Bob"}) SET u.age = 28 REMOVE u.id |
| 合并 | MERGE | 若模式不存在则创建,存在则匹配(避免重复创建) | MERGE (u:User {name: "Charlie"}) ON CREATE SET u.age = 30 |
4. 过滤、排序与聚合(Filtering, Sorting & Aggregation)
GQL支持传统数据库的“筛选-排序-聚合”流程,且适配图结构的特性(如按关系数量聚合):
- 过滤(
WHERE):支持属性条件(u.age > 25)、结构条件(EXISTS((u)-[:FOLLOWS]->()),判断用户是否有关注关系)、列表条件(u.tags CONTAINS "tech")。 - 排序(
ORDER BY):按属性升序(ASC)或降序(DESC)排序,支持多字段排序。 - 聚合(
AGGREGATION FUNCTIONS):内置常用聚合函数,部分函数专为图设计:|聚合函数|功能描述|示例| |––|––|–| |COUNT()|统计节点/关系/路径数量|MATCH (u:User)-[:FOLLOWS]->() RETURN u.name, COUNT(*)(统计每个用户的关注数)| |SUM()/AVG()|求和/求平均值(属性需为数值类型)|MATCH (p:Post) RETURN AVG(p.likes)(统计帖子平均点赞数)| |COLLECT()|将结果聚合为列表|MATCH (u:User)-[:POSTED]->(p:Post) RETURN u.name, COLLECT(p.title)(聚合每个用户的帖子标题)|
5. 递归查询(Recursive Query):处理深层层级结构
GQL通过WITH RECURSIVE语法支持递归查询,解决“无限层级”场景(如组织结构树、分类目录树),无需手动写多步匹配。
- 示例:查询“Alice所在部门的所有下属(含多级)”
WITH RECURSIVE // 基础 case:Alice的直接下属 direct_subordinates AS ( MATCH (alice:User {name: "Alice"})-[:MANAGES]->(sub:User) RETURN sub.name AS username ), // 递归 case:下属的下属(循环直到无更多层级) all_subordinates AS ( SELECT username FROM direct_subordinates UNION ALL MATCH (s:User {name: all_subordinates.username})-[:MANAGES]->(ss:User) RETURN ss.name AS username ) // 返回所有下属 SELECT username FROM all_subordinates;
二、数据定义语言(DDL):定义图结构
GQL 支持对图的元数据(如标签、关系类型、属性类型)进行定义,确保数据一致性(类似 SQL 的CREATE TABLE)。
1. 定义标签(节点类型)
// 定义标签User,并指定其属性及类型(可选,增强类型校验)
CREATE TAG User (
id INT REQUIRED, // 必选属性,整数类型
name STRING REQUIRED, // 必选属性,字符串类型
age INT, // 可选属性
active BOOLEAN DEFAULT true // 可选属性,默认值为true
);
2. 定义关系类型
// 定义关系类型FOLLOWS,指定属性及类型
CREATE RELATIONSHIP FOLLOWS (
since DATE REQUIRED, // 必选属性,日期类型
weight FLOAT DEFAULT 0.5 // 可选属性,浮点类型
);
3. 创建图(数据库)
// 创建一个名为"social_network"的图数据库
CREATE GRAPH social_network;
// 切换到指定图
USE GRAPH social_network;
三、数据操纵语言(DML):增删改图数据
GQL 提供直观的语法用于操作节点、关系和属性,覆盖数据全生命周期。
1. 创建数据(CREATE)
- 创建节点
// 创建单个节点(可省略标签定义时的类型校验,直接动态添加属性)
CREATE (u:User {id: 2, name: "Bob", age: 28, city: "London"});
// 同时创建多个节点
CREATE (p1:Product {id: 101, name: "Laptop", price: 9999}),
(p2:Product {id: 102, name: "Phone", price: 5999});
- 创建关系(需关联已有节点)
// 先匹配两个节点,再创建它们之间的关系
MATCH (u:User {name: "Alice"}), (p:Product {name: "Phone"})
CREATE (u)-\[b:BOUGHT {time: "2024-03-15", amount: 5999}]->(p);
- 创建路径(节点 + 关系一次性创建)
// 创建"Charlie"→关注→"Bob"→购买→"Laptop"的完整路径
CREATE (c:User {name: "Charlie"})-\[f:FOLLOWS]->(b:User {name: "Bob"})-\[b2:BOUGHT]->(l:Product {name: "Laptop"});
2. 更新数据(SET/REMOVE)
- 更新属性(
SET)
// 修改Alice的年龄,新增city属性
MATCH (u:User {name: "Alice"})
SET u.age = 31, u.city = "Paris";
- 删除属性或标签(
REMOVE)
// 移除Bob的city属性,移除User标签(需谨慎,可能影响查询)
MATCH (u:User {name: "Bob"})
REMOVE u.city, u:User;
- 批量更新(基于条件)
// 给所有age>30的User添加"Senior"标签
MATCH (u:User)
WHERE u.age > 30
SET u:Senior;
3. 删除数据(DELETE/DETACH DELETE)
- 删除关系
// 删除Alice购买Phone的关系
MATCH (u:User {name: "Alice"})-\[b:BOUGHT]->(p:Product {name: "Phone"})
DELETE b;
- 删除节点(需先删除关联关系,否则报错)
// 方法1:先删关系,再删节点
MATCH (u:User {name: "Charlie"})-\[r]->()
DELETE r; // 删除所有出向关系
MATCH (u:User {name: "Charlie"})
DELETE u; // 删除节点
// 方法2:用DETACH DELETE一键删除节点及所有关联关系(推荐)
MATCH (u:User {name: "Charlie"})
DETACH DELETE u;
4. 合并数据(MERGE:避免重复创建)
MERGE 用于 “若模式存在则匹配,不存在则创建”,适合防止重复数据:
// 若"Dave"用户存在则匹配,不存在则创建并设置age=25
MERGE (u:User {name: "Dave"})
ON CREATE SET u.age = 25 // 仅在创建时执行
ON MATCH SET u.lastSeen = CURRENT_DATE(); // 仅在匹配时执行(更新最后访问时间)
四、数据查询语言(DQL):查询图数据
查询是 GQL 的核心能力,通过 “模式匹配” 定位数据,支持过滤、排序、聚合等操作。
1. 基础查询(MATCH+RETURN)
// 查询所有User节点的name和age
MATCH (u:User)
RETURN u.name, u.age;
// 给结果起别名
MATCH (u:User)
RETURN u.name AS username, u.age AS user_age;
2. 条件过滤(WHERE)
支持属性条件、结构条件、逻辑运算(AND/OR/NOT):
// 条件1:属性过滤(age>25且city为"Paris")
MATCH (u:User)
WHERE u.age > 25 AND u.city = "Paris"
RETURN u.name;
// 条件2:结构过滤(存在关注关系的用户)
MATCH (u:User)
WHERE EXISTS((u)-\[:FOLLOWS]->()) // 检查u是否有出向的FOLLOWS关系
RETURN u.name;
// 条件3:列表包含(tags属性包含"tech")
MATCH (p:Post)
WHERE "tech" IN p.tags
RETURN p.title;
3. 关系模式匹配(核心能力)
通过描述 “节点 - 关系” 模式查询关联数据:
// 查询所有购买了Product的User,返回用户名和商品名
MATCH (u:User)-\[b:BOUGHT]->(p:Product)
RETURN u.name, p.name, b.time;
// 查询Alice的直接好友(1度关系)
MATCH (alice:User {name: "Alice"})-\[f:FOLLOWS]->(friend:User)
RETURN friend.name;
// 查询Alice的好友购买的商品(2度关系)
MATCH (alice:User {name: "Alice"})-\[:FOLLOWS]->(friend:User)-\[b:BOUGHT]->(p:Product)
RETURN friend.name, p.name;
4. 路径查询(多跳关系)
用*n表示关系的长度(n为数字或范围),支持灵活的多跳遍历:
// 查询Alice的1\~3度好友(1到3跳FOLLOWS关系)
MATCH (alice:User {name: "Alice"})-\[f:FOLLOWS\*1..3]->(friend:User)
RETURN friend.name, LENGTH(f) AS degree; // LENGTH(f)返回路径长度
// 查询Alice到Bob的所有路径(不限长度)
MATCH path = (alice:User {name: "Alice"})-\[\*]->(bob:User {name: "Bob"})
RETURN path;
5. 可选匹配(OPTIONAL MATCH:类似左连接)
当模式中部分结构不存在时,仍返回已有部分(避免数据丢失):
// 查询所有User及其购买的商品,没有购买记录的User也会返回(商品字段为NULL)
MATCH (u:User)
OPTIONAL MATCH (u)-\[b:BOUGHT]->(p:Product)
RETURN u.name, p.name;
6. 排序与限制(ORDER BY/LIMIT/SKIP)
// 查询所有Product,按价格降序排列,返回前3个(分页:跳过前2个,取3个)
MATCH (p:Product)
RETURN p.name, p.price
ORDER BY p.price DESC
SKIP 2 // 跳过前2条
LIMIT 3; // 最多返回3条
五、聚合查询(AGGREGATION)
GQL 提供丰富的聚合函数,支持对节点、关系或路径的统计分析:
| 函数 | 功能 | 示例 |
|---|---|---|
COUNT() | 统计数量 | MATCH (u:User)-[b:BOUGHT]->() RETURN u.name, COUNT(b) AS buy_count(统计用户购买次数) |
SUM() | 求和 | MATCH (p:Product) RETURN SUM(p.price) AS total_value(统计所有商品总价) |
AVG() | 平均值 | MATCH (u:User) RETURN AVG(u.age) AS avg_age(统计用户平均年龄) |
MIN()/MAX() | 最小值 / 最大值 | MATCH (p:Product) RETURN MIN(p.price) AS cheapest(最便宜的商品价格) |
COLLECT() | 聚合为列表 | MATCH (u:User)-[:POSTED]->(p:Post) RETURN u.name, COLLECT(p.title) AS posts(聚合用户发布的所有帖子标题) |
示例:按标签分组统计节点数量
// 统计每个标签的节点数量(如User、Product各有多少节点)
MATCH (n)
RETURN LABELS(n) AS tags, COUNT(n) AS node_count
ORDER BY node_count DESC;
六、递归查询(WITH RECURSIVE)
处理无限层级结构(如组织结构、分类树),通过递归遍历所有层级:
// 查询"Alice"管理的所有下属(含多级:直接下属→下属的下属→...)
WITH RECURSIVE
// 基础case:直接下属
direct_subs AS (
MATCH (alice:User {name: "Alice"})-\[:MANAGES]->(sub:User)
RETURN sub.id AS sub_id, sub.name AS sub_name, 1 AS level // level=1表示直接下属
),
// 递归case:下属的下属(循环直到无更多层级)
all_subs AS (
SELECT sub_id, sub_name, level FROM direct_subs
UNION ALL // 合并结果(保留重复,若去重用UNION)
MATCH (s:User {id: all_subs.sub_id})-\[:MANAGES]->(ss:User)
RETURN ss.id AS sub_id, ss.name AS sub_name, all_subs.level + 1 AS level // 层级+1
)
// 返回所有下属及层级
SELECT sub_name, level FROM all_subs
ORDER BY level;
七、事务(TRANSACTION)
GQL 支持 ACID 事务,确保多操作的原子性(要么全成功,要么全失败):
// 开始事务
BEGIN TRANSACTION;
// 事务内操作:创建用户并创建其部门关系
CREATE (u:User {id: 5, name: "Eve"});
MATCH (u:User {name: "Eve"}), (d:Dept {name: "Engineering"})
CREATE (u)-\[:WORKS_IN]->(d);
// 提交事务(所有操作生效)
COMMIT;
// 若操作有误,回滚事务(所有操作取消)
// ROLLBACK;
八、视图与片段(复用查询逻辑)
1. 视图(VIEW:虚拟图)
将常用查询结果定义为视图,后续可直接引用:
// 创建"高价值用户"视图(购买金额>10000的用户)
CREATE VIEW HighValueUser AS
MATCH (u:User)-\[b:BOUGHT]->()
WITH u, SUM(b.amount) AS total_spent
WHERE total_spent > 10000
RETURN u;
// 查询视图
MATCH (hvu:HighValueUser)
RETURN hvu.name, hvu.city;
2. 片段(FRAGMENT:复用模式)
定义重复使用的模式片段,减少代码冗余:
// 定义"用户发布帖子"的模式片段
DEFINE FRAGMENT UserPost AS (u:User)-\[:POSTED]->(p:Post);
// 引用片段查询(查找发布了"tech"标签帖子的用户)
MATCH UserPost
WHERE "tech" IN p.tags
RETURN u.name, p.title;
Rust
官网
Rustup metadata and toolchains will be installed into the Rustup
home directory, located at:
$HOME/.rustup
This can be modified with the RUSTUP_HOME environment variable.
The Cargo home directory located at:
$HOME/.cargo
This can be modified with the CARGO_HOME environment variable.
The cargo, rustc, rustup and other commands will be added to
Cargo s bin directory, located at:
$HOME/.cargo/bin
This path will then be added to your PATH environment variable by
modifying the profile files located at:
$HOME/.profile
$HOME/.bashrc
$HOME/.zshenv
You can uninstall at any time with rustup self uninstall and
these changes will be reverted.
-
小知识
- 升级rust及相关工具链
rustup update- 本地查看文档
rustup doc- 每隔一段时间就发布一个版次,主要有2015,2018,2021,主程序和库代码可以依赖不同版次的.
mdbook-快速安心写书
- 安装
cargo install mdbook
cargo install mdbook-pdf
cargo install mdbook-mermaid
cargo install mdbook-toc
相关资源
unity
清除启动界面工程
cd /Users/<yourUserName>/Library/Preferences/
cat com.unity3d.UnityEditor5.x.plist
defaults read com.unity3d.UnityEditor5.x.plist
defaults delete com.unity3d.UnityEditor5.x "RecentlyUsedProjectPaths-0"
打印调用堆栈
string trackStr = new System.Diagnostics.StackTrace().ToString();
Debug.Log ("Stack Info:" + trackStr);
积累
- Unity是单线程设计的游戏引擎,子线程中无法运行Unity SDK
- Unity主循环是单线程,游戏脚本MonoBehavior有着严格的生命周期
- 倾向使用time slicing(时间分片)的协程(coroutine)去完成异步任务
组件图

常见热更方案
利用c#反射,动态加载程序集,实现代码更新
// 从指定网址下载
Assembly assembly = Assembly.LoadFile(assemblyFile);
创建Lua虚拟机,动态加载Lua脚本
-
XLua.LuaEnv luaenv = new XLua.LuaEnv(); luaenv.DoString("CS.UnityEngine.Debug.Log('hello world')"); luaenv.Dispose(); -
LuaState lua = new LuaState(); lua.Start(); lua.DoString("print('hello world')"); lua.Dispose();
ET框架
游戏热更目前主流的解决方案
-
分Lua(ulua/slua/xlua/tolua)系
-
ILRuntime代表的c#系
ET框架介绍
-
热更采用了基于C#的ILRuntime

-
客户端目录结构

常见工具
git
优秀文档
- [git-scm]https://git-scm.com/book/zh/)
文件状态变迁图
flowchart LR
subgraph WorkDirectory
ut(Untracked)
um(Unmodified)--编辑修改-->md(Modified)
end
subgraph Staged
s(Staged/Index)
end
subgraph Repo
r(Commit对象)
end
WorkDirectory --add--> Staged
Staged --restore或checkout--> WorkDirectory
Staged --commit--> Repo
Repo --restore或reset或checkout--> Staged
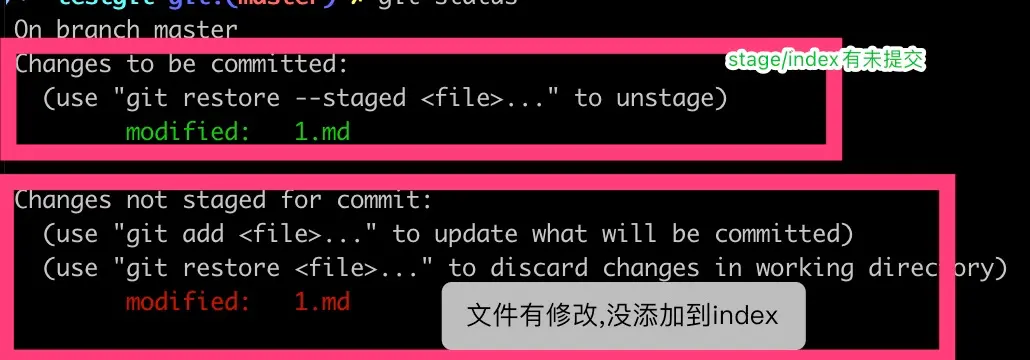
sequenceDiagram
actor ut as Untracked
actor um as Unmodified
actor m as Modified
actor s as Staged/Index
actor r as Repo
opt 未跟踪新文件
ut->>s: add 跟踪
ut-->>um: 自动转为
r-->>s: 放弃跟踪 restore --staged或rm --cached
um-->>ut: 放弃跟踪后自动转为
end
opt 已跟踪
opt 已跟踪编辑
um->>m: 编辑
s-->>um: 放弃编辑 restore或checkout
end
opt 提交到stage/index
m->>s: add
r-->>s: 放弃add restore --staged或reset
end
r-->>um: 放弃add和编辑 restore --staged --worktree或checkout head
end
opt 提交repo
s->>r: commit
r-->>s: 放弃commit restore --source=HEAD~1 --staged或reset head~1
end
r-->>um: 放弃commit和add和编辑 restore --source=HEAD~1 --staged --worktree或checkout head~1或reset --hard head~1
命令介绍
-
git rm, 删除WorkDictory,Staged/Index的文件
- 命令快照
git rm [--cached] <pathspec>...- 带上–cached,则只删除Staged/Index,否则WorkDictory也删除
-
restore,从指定源恢复
- 命令快照
git restore [<options>] [--source=<tree>] [--staged] [--worktree] [--] <pathspec>...- 没有带上–staged,则直接从Staged/Index恢复到WorkDictory
- 带上–staged,则从repo(head或者source指定commit或tag)恢复到Staged/Index.如果同时要恢复WorkDictory,则带上–worktree
- –source默认值为head
- 命令是试验性的,行为可能会改变.THIS COMMAND IS EXPERIMENTAL. THE BEHAVIOR MAY CHANGE.
-
reset,设置head,Reset current HEAD to the specified state
- 命令快照-格式1
git reset [-q] [<tree-ish>] [--] <pathspec>-
从指定的tree-ish恢复到staged/index,tree-ish不指定就采用head
-
命令快照-格式2
git reset [<mode>] [<commit>] This form resets the current branch head to <commit> and possibly updates the index (resetting it to the tree of <commit>) and the working tree depending on <mode>. If <mode> is omitted, defaults to --mixed. The <mode> must be one of the following:- 把head指向tree-ish
- mode不同值不同含义
- –soft,仅改动head
- –mixed(默认值),改动head并且staged/index恢复为指定tree-ish里面,workdictory不改
- –herd,改动head并且staged/index,workdictory恢复为指定tree-ish里面
-
checkout,切换分支或恢复出指定文件
- 命令快照-格式1
git checkout [-f|--ours|--theirs|-m|--conflict=<style>] [<tree-ish>] [--] <pathspec>-
没有带上tree-ish,则直接从Staged/Index恢复到WorkDictory
-
带上tree-ish,则从repo(tree-ish)恢复到Staged/Index和WorkDictory
-
tree-ish 通常是head,commit值或tag之类
-
命令快照-格式2
git checkout [-q] [-f] [-m] [[-b|-B|--orphan] <new_branch>]-
没有带上-b,则直接切换指定分支,分支必须存在
-
带上-b,则创建新分支,并且立即切换过去
-
命令快照-格式3
#从远程仓库/分支,创建本地分支,分支名同远程分支一样,两者建立跟踪关系 #切换到新分支,简化操作 git checkout --track remoteRepo/repoBranch -
revert返祖,产生新的提交commit来返回过去的特定提交
- 命令快照
git revert [--[no-]edit] [-n] [-m parent-number] [-s] [-S[<keyid>]] <commit> git rever -m 1 head
flowchart LR m1(commitXXXX) --commit--> m2(commitYYYY) m2 --commit--> m3(commitZZZZ) m3 --rever -m 1 head--> m4(commitNNNN,但内容和commitYYYY一样)
-
标签
#列出标签 git tag #查看指定标签 git show vxxx #打轻量标签 git tag v1.0 #打附注标签 git tag -a v2.0 -m "附加信息" #把标签vxxx推送到远程 git push origin vxxx -
commit对象
flowchart LR
subgraph commitXXXX
direction TB
cx(CommitXXXX)--包含-->tx(Tree对象)
tx--包含-->bxa(Blob对象A)
tx--包含-->bxb(Blob对象b)
tx--包含-->bxc(Blob对象c)
end
subgraph commitYYYY
direction TB
cy(commitYYYY)--包含-->ty(Tree对象)
ty--包含-->by1(Blob对象1)
ty--包含-->by2(Blob对象2)
end
subgraph commitZZZZ
direction TB
cz(commitZZZZ)--包含-->tz(Tree对象)
tz--包含-->bzl(Blob对象l)
tz--包含-->bzm(Blob对象m)
tz--包含-->bzn(Blob对象n)
tz--包含-->bzo(Blob对象o)
end
commitXXXX --父对象--> commitYYYY
commitYYYY --父对象--> commitZZZZ
- 分支
#列出分支
git branch
#查看分支详情
git branch -vv
#创建分支issue100
git branch issue100
#跳到分支issue100
git checkout issue100
#创建hotfix并且立即切过去
git checkout -b hotfix
#删除分支issue100
git branch -d issue100
#指定分支的跟踪远程分支
git branch --set-upstream-to=remote/branch branch
#基于远程分支创建新分支并设置跟踪关系
git checkout --trace -b feature origin/feature
#把hotfix分支合并到当前分支里
git merge hotfix
# 合并没有历史交并的分支
git merge gitee master --allow-unrelated-histories
#如果合并冲突,则编辑修改冲突文件,再提交
git commit -am "人工修改冲突"
#变基是改变-指定分支(不指出则采用当前分支)的起点,并且起点后的提交重播一次
#以hotfix分支为起点,本分支已有提交重播一次,达到合并目的
git rebase hotfix
#如果重播冲突,则编辑修改冲突文件,再提交
git commit -am "人工修改冲突"
#解决冲突后提交,再继续完成变基操作
git rebase --continue

-
rebase变基原则
- 只对尚未推送或分享给别人的本地修改执行变基操作清理历史.
- 从不对已推送至别处的提交执行变基操作.
-
合并提交
git commit -am "first"
# 编辑修改...
git commit -am "second"
# 编辑修改...
git commit -am "three"
# 交互式合并最近三个提交,如下图所示
# 默认从上到下,从旧到新列出来,可以编辑顺序
# 合并时从上到下执行,第一个一般是pack(基础),其他的为s(合并到基础去,pack改为s)
# 退出保存后,会继续编辑合并信息.
git rebase -i head~3
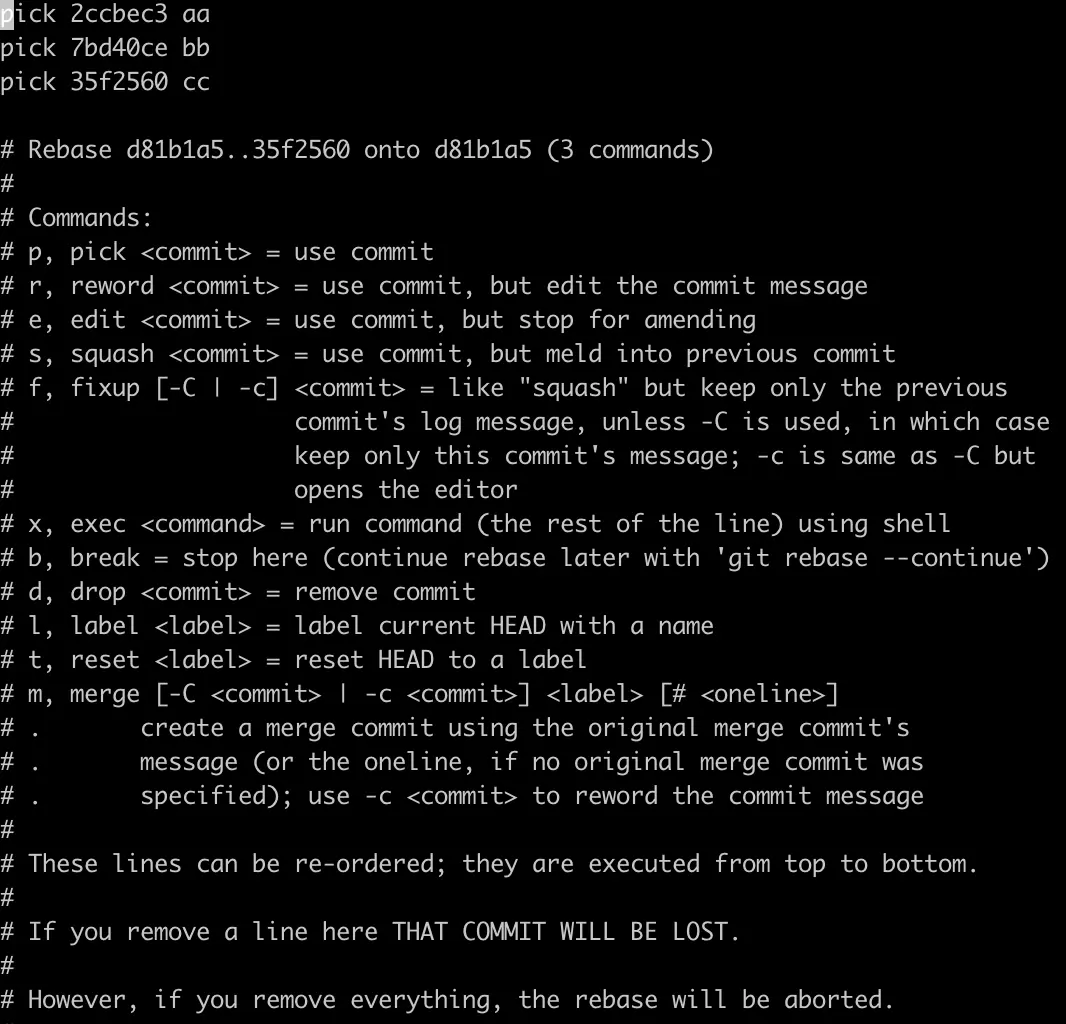
git commit
git branch dev
git checkout dev
git commit
git commit
git checkout master
git commit
git commit
git commit
git merge dev
gitGraph commit branch dev checkout dev commit commit # 默认master不存在,现在都采用main checkout main commit commit commit merge dev
- 远程仓库
flowchart LR
subgraph 本地仓库前
lm(master)
ld(dev)
end
subgraph 远程仓库
rm(master)
rd(dev)
rh(hotfix)
end
subgraph 本地仓库后
am(master)
ad(dev)
arm(origin/master)
ard(origin/dev)
arh(origin/hotfix)
end
本地仓库前 --remote add orgin--> 远程仓库
本地仓库前 --fetch origin--> 本地仓库后
#添加远程库
git remote add name url
# 如果远程库有意外提交,可以强行合并进来,再推上去
git pull origin master --allow-unrelated-histories
#拉取远程库内容
git fetch name
#查看远程分支日志
git log name/branch
#创建本地分支branch并且跟踪到远程分支
git checkout --track name/branch
#推送到远程
git push
#删除远程分支
git push name -d branch
#查看本地分支与远程分支设置
git branch -vv
- 集中式工作流程
sequenceDiagram
actor da as 开发者A
actor r as 仓库
actor db as 开发者B
da->>r: clone
db->>r: clone
da->>da: commit
db->>db: commit
da->>r: push
db->>r: pull
db->>r: push
- pull-request工作流程,同一个仓库用不同分支替代仓库,类似流程
sequenceDiagram
actor da as 开发者A
actor dar as 开发者A仓库
actor r as 仓库
actor rw as 仓库维护者
actor db as 开发者B
actor dbr as 开发者B仓库
opt 开发者A流程
da->>r: fork
r-->>dar: 自动创建
da->>dar: clone
da->>da: commit
da-->>dar: push
dar-->>r: pull requestA
dar-->>rw: 通知
end
opt 开发者B流程
db->>r: fork
r-->>dbr: 自动创建
db->>dbr: clone
db->>db: commit
db-->>dbr: push
dbr-->>r: pull requestB
dbr-->>rw: 通知
end
opt 仓库维护者流程
rw->>r: merge pull requestA
rw->>r: merge pull requestB
end
- 储存栈
#把workdirectory已跟踪修改+staged/index储存到一个栈上,
git stash
#可以在任何一个干净状态恢复出来,不一定需要原来保存的分支里
#不带上--index,则只恢复workdirectory已跟踪修改,
#带上--index,则staged/index也一起恢复
git stash apply [--index]
#apply可以多次重复
#删除就用drop
git stash drop
- 杂项
#配置本项目用户
git config user.name 'username'
git config user.email 'username@xx.com'
# 配置默认的分支名称
git config --global init.defaultBranch master
#修改最近提交的author
#amend纠正最近一次提交
#此次也会提交stage/index内容,如果stage/index没有修改,则直修改提交信息
git commit --amend --reset-author
# 查看最近3次提交文件变化情况
git log -3 --stat
#查看指定文件提交记录
git log -p filename
# 查看该文件的相关commit
git log -- filename
# 查看指定提交特定文件的变化
git show commit_id filename
# 查看指定提交的变化
git show commit_id
#比较两次提交之间指定目录的区别
git diff 26be34b 934d76fd flow/proto_file
# 有时候git status显示有变化,但是git diff没有,可能是文件换行符及文件权限属性变化了
git diff --cached filename
#当前指定提交commit值
rem 'git rev-parse --short HEAD'
#记录本项目git版本,获取当前git版本值
Cgithash=`git rev-parse --short HEAD`
#获取当前时间
Ctime=`date '+%Y-%m-%d_%H:%M:%S'`
# 强制退回指定commit
#fa2850...是commit的hash值
git reset --hard fa285014d635190e74cd40fc798ce26243766a09
#带用户名及密码的git clone
git clone http://uer:pwd@xxx.git
# 本地修改不提交到远程仓库
git update-index --skip-worktree filePath
# post-receive钩子
# git pull引入$GIT_DIR变量,因此需要取消变量
unset $(git rev-parse --local-env-vars);
git pull
# 查看特定提交在哪里分支
git branch --contains xxxx -all
# 创建一个空分支,没有任何父节点
git checkout --orphan newBranch
git rm -rf .
# 如何没有任何文件提交,看不到新建的分支
git commit -am "newBranch"
积累
-
Git gc一般情况不用手动,gc主要把无用的内部对象回收,一般都自动处理
-
Git钩子都被存储在 Git 目录下的 hooks 子目录中.
-
.git目录内容

-
git引用
-
查看项目本地仓库,远程仓库,标签等
tree .git/refs

-
Git 可以使用四种不同的协议来传输资料:
- 本地协议(Local)
#本机clone,尽量采用不带file://前缀,加快速度 git clone /srv/git/project.git git clone file:///srv/git/project.git- HTTP 协议,现在git一般采用智能 HTTP 协议
git clone https://example.com/gitproject.git- SSH(Secure Shell)协议
git clone ssh://[user@]server/project.git git clone [user@]server:project.git- Git 协议
- Git里的一个特殊的守护进程,它监听在一个特定的端口(9418)
- 速度最快的
- 缺乏授权机制
- git://
-
利用post-receive钩子自动更新
#!/usr/bin/env bash
# post-receive脚本代码
cd ~
target=xxx
# 简单粗暴,删除旧目录
if [ -d ${target} ]; then
rm -rf ${target}
fi
# 重新建立,从git代码库目录
git clone gogs-repositories/yyy/${target}.git
# 杀死进程
pkill ${target}
cd ${target}
# 后台运行进程
nohup ./${target} >${target}.nohup 2>&1 &
-
push碰到HTTP 413
- 问题表现
Git push error: error: RPC failed; HTTP 413 curl 22 the requested URL returned error: 413- 解决办法
# 增加最大http长度 git config –global http.postBuffer 524288000location / { ... # 如果有nginx转发 client_max_body_size 200M; ... }
多项目-一个项目(采用git管理)使用另一个项目(采用git管理)
-
Git Submodule
-
添加子目录
# 默认在目录下建立repo子目录,并且克隆仓库,并且创建.gitmodules git submodule add https://xxx/repo.git # 提交到仓库 git commit -am "submodule" # 如果子项目有更新,直接取更新 git submodule update --remote # 然后更新父目录,子项目引用到更新后的 git commit -am "更新submodule" #可以直接在子目录修改提交,和正常git操作一样 -
其他人使用
# 一次性克隆项目及子项目 git clone --recursive https://xxx/repo.git # 或者先克隆项目 git clone https://xxx.git # 手动更新子项目 git submodule init git submodule update --remote #可以直接在子目录修改提交,和正常git操作一样 -
子项目.git目录储存到父项目的.git/modules目录

-
用引用方式,显式操作
-
-
Git Subtree
-
添加子目录,建立与git项目的关联
#-f在添加远程仓库之后,立即执行fetch git remote add -f <子仓库名> <子仓库地址> #–squash意思是把subtree的改动合并成一次commit,不用拉取子项目完整的历史记录。 #–prefix之后的=等号也可以用空格。 git subtree add --prefix=<子目录名> <子仓库名> <分支> --squash -
从远程仓库更新子目录
git fetch <远程仓库名> <分支> git subtree pull --prefix=<子目录名> <远程分支> <分支> --squash -
从子目录push到远程仓库(确认你有写权限)
git subtree push --prefix=<子目录名> <远程分支名> 分支 -
用复制方式,隐式操作
-
-
GitSlave
清除大文件
-
采用工具
-
清理仓库大文件需要修改仓库的提交历史,git-filter-repo 是 Git 官方社区推荐的修改仓库提交历史的工具,本文介绍使用 git-filter-repo 来清理仓库大文件的方法。 看他
pip3 install git-filter-repo -
手动执行
# 完全清除git中大文件提交
# 查看大文件
# 使用verify-pack命令查看, pack包里面的最大的10个文件对应的hash值
# 根据rev-list命令来查看, 最大的文件的文件名是什么
git rev-list --objects --all | grep "$(git verify-pack -v .git/objects/pack/*.idx | sort -k 3 -n | tail -10 | awk '{print$1}')"
# 删除大文件
git filter-branch --force --index-filter "git rm -rf --cached --ignore-unmatch linux_x86_64/zinc_upx" --prune-empty --tag-name-filter cat -- --all
# 回收空间,清理本地仓库不可达对象;
git for-each-ref --format='delete %(refname)' refs/original | git update-ref --stdin
rm -rf .git/refs/original/
rm -rf .git/logs/
git reflog expire --expire=now --all
git gc --prune=now
git gc --aggressive --prune=now
# 强制推到远程
git push origin --force --all
# git push origin –-force --tag
git remote prune origin
# !!清理完之后,每个人一定要删掉之前拉取的项目, 重新从git上拉项目。不要使用之前的项目了!否则会不降反升。
清除未跟踪文件
# 清除文件
git clean -f
# 连目录也一起清除文件
git clean -fd
brew-酿制
官网
![]()
- Homebrew 类似于一个软件中心,你可以理解成 App Store 或者 Google Play 那样的软件商店,只不过,Homebrew 比前者以及 Mac App Store 来说有着更丰富的资源与更高效的管理。
- Homebrew Cask,它是一套建立在 Homebrew 基础之上的 OS X 软件安装命令行工具,是 Homebrew 的扩展.
- homebrew-自家酿酒
- formula-配方
- key-桶酒,编译完成的套件资料夹
- Cellar-地窖
安装命令
# 如果很慢,可能切换国内源
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
常用命令
# 在 .zshrc 文件中添加
# Homebrew 取消自动更新
export HOMEBREW_NO_AUTO_UPDATE=true
# 安装hugo,nginx,memcached,redis,mongodb-community,mysql,jenkins-lts等等
brew install hugo
# 查看
brew info memcached
# 搜索
brew search redis
# 查看支持的命令
brew commands
# 列出常用帮助
brew help
# 运行后台服务 start restart stop
brew services start nginx
#unbound is a validating, recursive, caching DNS resolver.
brew services start unbound
# unrar已经被删除了,只能安装私人的
brew install unrar
brew install carlocab/personal/unrar
附录
-
HOMEBREW_NO_INSTALL_CLEANUP参数说明
Unless HOMEBREW_NO_INSTALL_CLEANUP is set, brew cleanup will be run for the installed formulae or, every 30 days, for all formulae -
brew install xxx过程
sequenceDiagram
actor b as brew
actor f as github源
actor ph as $Home/Library/Caches/Homebrew
actor pc as /opt/homebrew/Cellar
actor pb as /opt/homebrew/bin
actor p as $PATH
b->>f: 下载 xxx.rb
b->>b: 执行xxx.rb
b->>ph: 下载依赖及源码xxx.tar.gz到
b->>b: 解压编译
b->>pc:编译结果保存到
pc->>pb:软链接
pb-->>p:事先加入到
k8s
Kubernetes 中的 StatefulSet 是专为管理有状态应用而设计的控制器,适用于需要稳定标识、持久化存储和有序部署的场景。以下是其核心要点:
1. 与 Deployment 的主要区别
- 无状态 vs 有状态
Deployment 适用于无状态应用(如 Web 前端),Pod 随机命名且替换后存储丢失;StatefulSet 为每个 Pod 提供唯一且稳定的标识(如web-0,web-1),并绑定专属持久存储。 - 网络标识
StatefulSet 的 Pod 拥有固定 DNS 名称(通过 Headless Service),支持直接通过 Pod 名称访问(如web-0.nginx.default.svc.cluster.local)。
2. 核心特性
- 稳定的网络标识
每个 Pod 名称唯一且按序分配(<statefulset-name>-<ordinal-index>),重启或重新调度后保持不变。 - 持久化存储
通过volumeClaimTemplates为每个 Pod 动态创建独立的 PVC,确保数据持久化(即使 Pod 被删除,存储仍保留)。 - 有序部署与扩缩容
- 顺序创建:按索引升序(如先
web-0,再web-1)。 - 逆序终止:缩容时从最高索引开始删除。
- 适用于主从架构(如 MySQL 主节点需优先启动)。
- 顺序创建:按索引升序(如先
- 滚动更新策略
支持RollingUpdate(按序更新,从最高索引降序)和OnDelete(需手动删除 Pod 触发更新)。
3. 典型使用场景
- 分布式有状态应用
如 ZooKeeper、etcd、Kafka 等需要固定网络标识和持久存储的服务。 - 数据库集群
如 MySQL 主从复制、MongoDB 副本集,依赖稳定的节点标识和数据持久性。 - 需有序扩展的应用
如需按顺序初始化节点的场景(如主节点先于从节点启动)。
4. 依赖与配置
- Headless Service
必须关联一个 Headless Service(clusterIP: None),用于为 Pod 提供 DNS 解析,实现直接访问。 - 持久化存储
需配置volumeClaimTemplates,依赖 StorageClass 动态创建 PV,或手动预配 PV。 - 探针配置
建议设置readinessProbe和livenessProbe,确保应用就绪后再进行后续操作。
5. 注意事项
- 存储保留策略
Pod 删除后关联的 PVC 默认保留,需手动清理或配置删除策略(如persistentVolumeClaimRetentionPolicy)。 - 应用层协调
StatefulSet 仅保证 Pod 顺序,不处理应用层状态(如主从选举),需结合初始化容器或应用逻辑。 - 网络通信
Pod 间通信应使用 DNS 名称而非 IP,避免因 IP 变化导致故障。
示例 YAML 片段
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx" # 关联的 Headless Service
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates: # 每个 Pod 动态创建 PVC
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "fast"
resources:
requests:
storage: 1Gi
通过 StatefulSet,Kubernetes 能够有效管理有状态应用,提供稳定的网络、存储和部署顺序,是运行分布式数据库和集群化服务的理想选择。
在 Kubernetes 中,Job 和 CronJob 是两种用于管理短期任务的工作负载资源,但它们的用途和设计目标有显著区别。以下是两者的核心差异和适用场景:
1. 核心区别
| 特性 | Job | CronJob |
|---|---|---|
| 设计目的 | 运行一次性任务(如数据处理、批处理作业) | 运行周期性任务(如定时备份、定期清理) |
| 触发方式 | 手动触发或由其他系统触发 | 按预定义的时间表(Cron 表达式)自动触发 |
| 任务执行模式 | 任务运行到成功完成或达到重试次数 | 定期生成新的 Job 实例执行任务 |
| 生命周期 | 任务完成后自动终止 | 持续运行,按计划不断创建新的 Job |
| 典型场景 | 数据库迁移、批量计算、测试任务 | 每日日志归档、每小时数据同步、每周报告生成 |
2. 关键功能对比
(1) Job:一次性任务
- 任务完成机制
- 确保 Pod 成功运行到完成状态(exit code 0)。
- 可配置
completions(需成功完成的 Pod 数量)和parallelism(并行运行的 Pod 数)。
- 错误处理
- 若 Pod 失败(exit code 非 0),Job 会根据
backoffLimit自动重启 Pod。
- 若 Pod 失败(exit code 非 0),Job 会根据
- 资源清理
- 任务完成后,Job 对象保留历史记录(默认不删除),需手动清理或通过 TTL 机制自动清理。
示例场景:
运行一个数据处理任务,处理完成后自动终止。
apiVersion: batch/v1
kind: Job
metadata:
name: data-processor
spec:
completions: 1 # 需要成功完成的次数
parallelism: 1 # 并行运行的 Pod 数
template:
spec:
containers:
- name: processor
image: data-processor:v1
restartPolicy: Never # Job 的 Pod 不允许 Always 重启
(2) CronJob:定时任务
- 时间调度
- 使用 Cron 表达式(如
0 * * * *表示每小时执行)定义任务计划。 - 支持标准 Cron 语法(
分钟 小时 日 月 周几)。
- 使用 Cron 表达式(如
- 任务生成
- 每次触发时创建一个新的 Job 对象来执行任务。
- 并发控制
- 通过
concurrencyPolicy控制并发行为:Allow(默认):允许并发执行。Forbid:禁止并发,若前一个任务未完成则跳过新任务。Replace:取消未完成的任务,替换为新任务。
- 通过
- 历史记录保留
- 通过
successfulJobsHistoryLimit和failedJobsHistoryLimit控制保留的已完成 Job 数量。
- 通过
示例场景:
每天凌晨 2 点执行数据库备份。
apiVersion: batch/v1
kind: CronJob
metadata:
name: daily-backup
spec:
schedule: "0 2 * * *" # Cron 表达式(每天 2:00 AM)
concurrencyPolicy: Forbid # 禁止并发执行
jobTemplate:
spec:
template:
spec:
containers:
- name: backup-tool
image: backup-agent:v1
restartPolicy: OnFailure # 失败时重启容器(非 Pod)
3. 使用场景对比
| 场景 | Job | CronJob |
|---|---|---|
| 数据处理 | ✅ 单次运行 MapReduce 任务 | ✅ 每小时处理增量数据 |
| 系统维护 | ✅ 手动触发日志清理 | ✅ 每日凌晨自动清理旧日志 |
| 测试任务 | ✅ 运行一次集成测试 | ✅ 每晚定时执行回归测试 |
| 资源初始化 | ✅ 初始化数据库或配置 | ❌ 无需重复执行 |
| 周期性监控 | ❌ 不适合 | ✅ 每 5 分钟检查系统健康状态 |
4. 注意事项
- Job 的 Pod 重启策略
Job 的 Pod 必须设置restartPolicy: Never或OnFailure(不可用Always),避免无限重启。 - CronJob 的时区问题
CronJob 默认使用 Kubernetes 控制平面节点的时区,若需指定时区,需在 Kubernetes 1.27+ 版本中配置timeZone字段。 - 资源泄漏风险
- Job 完成后需手动清理或配置
ttlSecondsAfterFinished自动删除。 - CronJob 应合理设置历史记录保留策略,避免存储过多旧 Job 对象。
- Job 完成后需手动清理或配置
5. 总结
- 选择 Job:当需要运行一次性任务(如数据处理、初始化操作),且任务完成后无需重复执行。
- 选择 CronJob:当需要按固定时间表重复执行任务(如定时备份、周期性报表生成)。
- 组合使用:CronJob 本质是通过生成 Job 来执行任务,两者可结合使用实现复杂调度逻辑。
在 Kubernetes 中,Service 是一个核心抽象,用于定义一组 Pod 的访问策略,提供稳定的网络端点、负载均衡和服务发现功能。它是解耦前端(客户端)和后端(Pod)的关键组件,尤其适用于动态变化的容器化环境。
1. Service 的作用
- 稳定的网络标识
解决 Pod IP 动态变化的问题,为 Pod 组提供固定访问入口(ClusterIP、DNS 名称等)。 - 负载均衡
自动将流量分发到多个 Pod,支持多种负载均衡策略(如轮询、会话保持)。 - 服务发现
通过 DNS 名称或环境变量,使应用能够动态发现后端服务。 - 流量控制
支持定义访问端口映射、协议类型(TCP/UDP)等。
2. Service 的核心类型
(1) ClusterIP(默认类型)
- 用途:仅在集群内部访问服务(Pod 到 Pod 或内部组件间的通信)。
- 特点:
- 分配一个虚拟 IP(ClusterIP),生命周期内固定。
- 通过
kube-proxy实现内部负载均衡。
- 示例场景:数据库服务仅允许集群内应用访问。
apiVersion: v1
kind: Service
metadata:
name: mysql-service
spec:
type: ClusterIP
selector:
app: mysql
ports:
- protocol: TCP
port: 3306 # Service 暴露的端口
targetPort: 3306 # Pod 监听的端口
(2) NodePort
- 用途:通过节点 IP 和固定端口暴露服务,允许集群外部访问。
- 特点:
- 在集群所有节点上开放同一个端口(默认范围 30000-32767)。
- 流量路径:外部请求 → 节点 IP:NodePort → Service → Pod。
- 示例场景:开发测试环境临时暴露服务。
apiVersion: v1
kind: Service
metadata:
name: web-service
spec:
type: NodePort
selector:
app: web
ports:
- protocol: TCP
port: 80 # Service 端口
targetPort: 80 # Pod 端口
nodePort: 31000 # 手动指定节点端口(可选)
(3) LoadBalancer
- 用途:通过云提供商的负载均衡器(如 AWS ELB、GCP LB)暴露服务。
- 特点:
- 自动创建外部负载均衡器,并分配外部 IP。
- 通常与
NodePort和ClusterIP协同工作。
- 示例场景:生产环境对外暴露高可用服务。
apiVersion: v1
kind: Service
metadata:
name: api-service
spec:
type: LoadBalancer
selector:
app: api
ports:
- protocol: TCP
port: 443
targetPort: 8080
(4) Headless Service
- 用途:直接访问 Pod IP(无需负载均衡),适用于有状态应用(如 StatefulSet)。
- 特点:
- 设置
clusterIP: None,不分配 ClusterIP。 - DNS 查询返回所有 Pod 的 IP 列表(或直接解析到单个 Pod)。
- 设置
- 示例场景:MySQL 主从集群中通过 Pod 域名直接访问特定实例。
apiVersion: v1
kind: Service
metadata:
name: mysql-headless
spec:
clusterIP: None
selector:
app: mysql
ports:
- protocol: TCP
port: 3306
targetPort: 3306
3. 关键机制
(1) 标签选择器(Selector)
- 通过
selector字段匹配 Pod 的标签,动态维护后端端点(Endpoints)。 - 示例:
selector: app: web会关联所有标签为app=web的 Pod。
(2) kube-proxy 的流量转发
- iptables/IPVS 模式:
kube-proxy监听 Service 和 Endpoints 变化,动态配置节点上的流量转发规则。
(3) DNS 解析
- Service 的 DNS 名称格式:
<service-name>.<namespace>.svc.cluster.local。 - 同一命名空间内的 Pod 可直接通过
<service-name>访问。
4. 高级特性
- 会话保持(Session Affinity)
通过sessionAffinity: ClientIP将同一客户端的请求转发到固定 Pod。 - 多端口定义
一个 Service 可暴露多个端口,适用于复杂协议(如 HTTP + gRPC)。 - 外部流量策略
externalTrafficPolicy: Local保留客户端源 IP,但可能导致流量不均衡。
5. 与其他组件的关系
- Ingress
Service 通常与 Ingress 配合使用:
Ingress 定义外部访问规则(如域名、路径),并将流量转发到 Service。 - EndpointSlices
替代传统的 Endpoints 对象,提升大规模集群的性能。
6. 示例:完整请求流程
- 客户端访问
web-service:80(ClusterIP 类型)。 kube-proxy通过 iptables/IPVS 规则将流量转发到后端 Pod。- 若 Pod 扩缩容,Service 自动更新 Endpoints,无需客户端感知。
7. 总结
- 使用 Service 的场景:
- 需要为 Pod 组提供稳定访问入口。
- 需负载均衡或服务发现。
- 需隔离内部和外部流量(如 ClusterIP + Ingress)。
- 优势:
- 解耦服务提供方和消费方。
- 适配 Pod 的动态生命周期。
- 支持多云和混合云环境。
通过 Service,Kubernetes 实现了应用网络的抽象化,使开发者无需关注底层 Pod 的细节,专注于业务逻辑的实现。
在 Kubernetes 中,LoadBalancer 类型的 Service 是专为公有云环境设计的资源,通过与云提供商的负载均衡器(如 AWS ELB、GCP LB)集成,将集群内的服务暴露到外部网络。以下是其核心机制、配置方法及与云提供商集成的详细说明:
1. LoadBalancer Service 的核心机制
- 自动创建外部负载均衡器
当创建type: LoadBalancer的 Service 时,Kubernetes 会调用云提供商的 API,自动创建对应的负载均衡器(如 AWS 的 ELB、GCP 的 Cloud Load Balancing)。 - 外部 IP 分配
云提供商为负载均衡器分配一个外部 IP 或 DNS 名称,供外部客户端访问。 - 流量转发路径
外部流量 → 云负载均衡器 → Kubernetes 节点(NodePort)→ 目标 Pod。
2. 与云提供商负载均衡器的集成流程
以 AWS ELB 和 GCP LB 为例:
步骤 1:创建 LoadBalancer Service
定义 Service 时指定 type: LoadBalancer,并关联后端 Pod 的标签选择器(selector)。
apiVersion: v1
kind: Service
metadata:
name: my-web-service
spec:
type: LoadBalancer
selector:
app: web # 匹配 Pod 的标签
ports:
- protocol: TCP
port: 80 # 负载均衡器监听端口
targetPort: 80 # Pod 的端口
步骤 2:云提供商自动创建负载均衡器
- AWS:创建一个 Classic Load Balancer (CLB) 或 Application Load Balancer (ALB),具体类型可通过注解配置。
- GCP:创建一个 TCP/UDP 网络负载均衡器或 HTTP(S) 负载均衡器。
步骤 3:流量转发
- 负载均衡器监听外部请求,并将流量转发到集群节点的 NodePort(由 Kubernetes 自动分配或手动指定)。
kube-proxy将 NodePort 流量路由到后端 Pod。
3. 云提供商特定配置(通过注解)
不同云提供商支持通过 annotations 自定义负载均衡器的行为:
(1) AWS 示例
-
指定负载均衡器类型(ALB vs CLB):
metadata: annotations: service.beta.kubernetes.io/aws-load-balancer-type: "external" service.beta.kubernetes.io/aws-load-balancer-scheme: "internet-facing" -
启用 SSL 终止:
metadata: annotations: service.beta.kubernetes.io/aws-load-balancer-ssl-cert: "arn:aws:acm:us-west-2:123456789012:certificate/xxxxxx" service.beta.kubernetes.io/aws-load-balancer-backend-protocol: "http"
(2) GCP 示例
-
配置全局访问:
metadata: annotations: networking.gke.io/load-balancer-type: "Internal" # 内部负载均衡器 -
设置健康检查参数:
metadata: annotations: cloud.google.com/load-balancer-type: "Regional" # 区域级负载均衡
4. 高级配置选项
(1) 外部流量策略(externalTrafficPolicy)
Cluster(默认)
流量均匀分配到所有节点,但客户端源 IP 会被隐藏(NAT 转换)。Local
仅将流量转发到运行目标 Pod 的节点,保留客户端源 IP,但可能导致负载不均。
spec:
externalTrafficPolicy: Local
(2) 保留客户端源 IP
- 结合
externalTrafficPolicy: Local使用,确保客户端 IP 不被丢失。 - 在云提供商负载均衡器中启用代理协议(如 AWS 需要配置注解)。
5. 示例:AWS 中创建 HTTPS 负载均衡器
apiVersion: v1
kind: Service
metadata:
name: web-https
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: "external"
service.beta.kubernetes.io/aws-load-balancer-ssl-ports: "443"
service.beta.kubernetes.io/aws-load-balancer-ssl-cert: "arn:aws:acm:us-west-2:123456789012:certificate/xxxxxx"
spec:
type: LoadBalancer
selector:
app: web
ports:
- name: https
protocol: TCP
port: 443
targetPort: 80
6. 常见问题与排查
(1) 负载均衡器未创建
- 检查点:
- 确认集群运行在支持的云环境中(如 AWS EKS、GCP GKE)。
- 查看 Service 事件:
kubectl describe service <service-name>。 - 检查云账号权限是否允许创建负载均衡器。
(2) 外部 IP 处于 Pending 状态
- 可能原因:
- 云提供商配额不足(如 AWS ELB 数量限制)。
- 安全组或防火墙规则阻止了负载均衡器的创建。
(3) 健康检查失败
- 解决方案:
- 确保 Pod 的
readinessProbe和livenessProbe配置正确。 - 检查负载均衡器的健康检查端口和路径是否与 Pod 匹配。
- 确保 Pod 的
7. 总结
- 适用场景:
✅ 需要将服务暴露到公网,且运行在公有云环境(AWS、GCP、Azure 等)。
✅ 要求高可用性和自动扩缩容的外部流量入口。 - 优势:
- 自动化集成云基础设施,减少手动配置。
- 提供企业级负载均衡能力(如 SSL 终止、WAF 集成)。
- 注意事项:
- 成本:云负载均衡器通常按使用量计费。
- 延迟:流量需经过云负载均衡器和节点转发,可能增加延迟。
通过 LoadBalancer Service,Kubernetes 无缝对接云平台的高级网络功能,为生产环境提供可靠的外部服务暴露方案。
在 Kubernetes 中,Service 是一个核心抽象,用于定义一组 Pod 的访问策略,提供稳定的网络端点、负载均衡和服务发现功能。它是解耦前端(客户端)和后端(Pod)的关键组件,尤其适用于动态变化的容器化环境。
1. Service 的作用
- 稳定的网络标识
解决 Pod IP 动态变化的问题,为 Pod 组提供固定访问入口(ClusterIP、DNS 名称等)。 - 负载均衡
自动将流量分发到多个 Pod,支持多种负载均衡策略(如轮询、会话保持)。 - 服务发现
通过 DNS 名称或环境变量,使应用能够动态发现后端服务。 - 流量控制
支持定义访问端口映射、协议类型(TCP/UDP)等。
2. Service 的核心类型
(1) ClusterIP(默认类型)
- 用途:仅在集群内部访问服务(Pod 到 Pod 或内部组件间的通信)。
- 特点:
- 分配一个虚拟 IP(ClusterIP),生命周期内固定。
- 通过
kube-proxy实现内部负载均衡。
- 示例场景:数据库服务仅允许集群内应用访问。
apiVersion: v1
kind: Service
metadata:
name: mysql-service
spec:
type: ClusterIP
selector:
app: mysql
ports:
- protocol: TCP
port: 3306 # Service 暴露的端口
targetPort: 3306 # Pod 监听的端口
(2) NodePort
- 用途:通过节点 IP 和固定端口暴露服务,允许集群外部访问。
- 特点:
- 在集群所有节点上开放同一个端口(默认范围 30000-32767)。
- 流量路径:外部请求 → 节点 IP:NodePort → Service → Pod。
- 示例场景:开发测试环境临时暴露服务。
apiVersion: v1
kind: Service
metadata:
name: web-service
spec:
type: NodePort
selector:
app: web
ports:
- protocol: TCP
port: 80 # Service 端口
targetPort: 80 # Pod 端口
nodePort: 31000 # 手动指定节点端口(可选)
(3) LoadBalancer
- 用途:通过云提供商的负载均衡器(如 AWS ELB、GCP LB)暴露服务。
- 特点:
- 自动创建外部负载均衡器,并分配外部 IP。
- 通常与
NodePort和ClusterIP协同工作。
- 示例场景:生产环境对外暴露高可用服务。
apiVersion: v1
kind: Service
metadata:
name: api-service
spec:
type: LoadBalancer
selector:
app: api
ports:
- protocol: TCP
port: 443
targetPort: 8080
(4) Headless Service
- 用途:直接访问 Pod IP(无需负载均衡),适用于有状态应用(如 StatefulSet)。
- 特点:
- 设置
clusterIP: None,不分配 ClusterIP。 - DNS 查询返回所有 Pod 的 IP 列表(或直接解析到单个 Pod)。
- 设置
- 示例场景:MySQL 主从集群中通过 Pod 域名直接访问特定实例。
apiVersion: v1
kind: Service
metadata:
name: mysql-headless
spec:
clusterIP: None
selector:
app: mysql
ports:
- protocol: TCP
port: 3306
targetPort: 3306
3. 关键机制
(1) 标签选择器(Selector)
- 通过
selector字段匹配 Pod 的标签,动态维护后端端点(Endpoints)。 - 示例:
selector: app: web会关联所有标签为app=web的 Pod。
(2) kube-proxy 的流量转发
- iptables/IPVS 模式:
kube-proxy监听 Service 和 Endpoints 变化,动态配置节点上的流量转发规则。
(3) DNS 解析
- Service 的 DNS 名称格式:
<service-name>.<namespace>.svc.cluster.local。 - 同一命名空间内的 Pod 可直接通过
<service-name>访问。
4. 高级特性
- 会话保持(Session Affinity)
通过sessionAffinity: ClientIP将同一客户端的请求转发到固定 Pod。 - 多端口定义
一个 Service 可暴露多个端口,适用于复杂协议(如 HTTP + gRPC)。 - 外部流量策略
externalTrafficPolicy: Local保留客户端源 IP,但可能导致流量不均衡。
5. 与其他组件的关系
- Ingress
Service 通常与 Ingress 配合使用:
Ingress 定义外部访问规则(如域名、路径),并将流量转发到 Service。 - EndpointSlices
替代传统的 Endpoints 对象,提升大规模集群的性能。
6. 示例:完整请求流程
- 客户端访问
web-service:80(ClusterIP 类型)。 kube-proxy通过 iptables/IPVS 规则将流量转发到后端 Pod。- 若 Pod 扩缩容,Service 自动更新 Endpoints,无需客户端感知。
7. 总结
- 使用 Service 的场景:
- 需要为 Pod 组提供稳定访问入口。
- 需负载均衡或服务发现。
- 需隔离内部和外部流量(如 ClusterIP + Ingress)。
- 优势:
- 解耦服务提供方和消费方。
- 适配 Pod 的动态生命周期。
- 支持多云和混合云环境。
通过 Service,Kubernetes 实现了应用网络的抽象化,使开发者无需关注底层 Pod 的细节,专注于业务逻辑的实现。
Kubernetes 中的 Ingress 用于管理外部访问集群内部服务的 HTTP/HTTPS 流量,充当集群的“智能路由网关”。它通过定义路由规则,将外部请求按域名、路径等条件分发到不同的后端服务,同时支持 TLS 加密等高级功能。以下是其核心作用及与外部流量的交互机制:
一、Ingress 的核心作用
1. 统一流量入口
- 替代多个 LoadBalancer
无需为每个服务创建独立的负载均衡器(节省云资源成本),通过单一入口(如一个公网 IP)承载多个服务的流量。 - 示例:
通过api.example.com和app.example.com两个域名访问同一个集群的不同服务。
2. 灵活的路由规则
- 基于域名(Host)路由
将不同域名的请求分发到对应的服务(如blog.example.com→ 博客服务,api.example.com→ API 服务)。 - 基于路径(Path)路由
同一域名下,按 URL 路径分发流量(如example.com/user→ 用户服务,example.com/order→ 订单服务)。
3. TLS 终止
- 集中管理 HTTPS
在 Ingress 层统一配置 SSL/TLS 证书,实现 HTTPS 加密访问,无需在后端服务中单独处理加密。 - 支持自动证书续签
结合工具如cert-manager可自动申请和更新 Let’s Encrypt 证书。
4. 负载均衡与流量控制
- 权重分流
按比例将流量分配到不同版本的服务(如金丝雀发布)。 - 会话保持、限流、重试
通过 Ingress 控制器扩展功能(如 Nginx 注解)。
二、Ingress 的工作原理
1. 核心组件
- Ingress 资源(API 对象)
声明路由规则(YAML 文件定义域名、路径、后端服务等)。 - Ingress 控制器(实际执行组件)
监控 Ingress 资源变化,动态配置负载均衡器或反向代理(如 Nginx、Traefik、AWS ALB)。
2. 工作流程
-
部署 Ingress 控制器
安装如 Nginx Ingress Controller,它会自动创建一个 LoadBalancer 或 NodePort 类型的 Service,对外暴露入口。 -
创建 Ingress 规则
定义路由规则并关联后端 Service(ClusterIP 类型)。 -
外部流量进入
客户端通过 Ingress 控制器的外部 IP/DNS 发起请求。 -
规则匹配与转发
Ingress 控制器根据请求的域名和路径,将流量转发到对应的 Service,再由 Service 路由到 Pod。

三、Ingress 与外部流量的交互
1. 暴露 Ingress 控制器
- 云环境(如 AWS/GCP)
Ingress 控制器通常以LoadBalancer类型部署,云平台自动为其分配公网 IP。 - 本地环境
使用NodePort或hostNetwork模式,通过节点 IP 和端口访问。
2. DNS 配置
- 将域名解析指向 Ingress 控制器的公网 IP(如
A 记录或CNAME)。
3. 示例:完整请求路径
- 用户访问
https://app.example.com。 - DNS 解析到 Ingress 控制器的公网 IP。
- Ingress 控制器验证 TLS 证书并解密 HTTPS 流量。
- 根据
Host: app.example.com匹配 Ingress 规则,将请求转发到对应的 Service(如app-service:80)。 - Service 负载均衡到后端 Pod。
四、Ingress 配置示例
1. 定义 Ingress 规则
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: / # Nginx 特定注解(路径重写)
spec:
tls:
- hosts:
- app.example.com
secretName: tls-secret # 引用存储证书的 Secret
rules:
- host: app.example.com
http:
paths:
- path: /api
pathType: Prefix
backend:
service:
name: api-service # 关联的后端 Service 名称
port:
number: 80
- path: /static
backend:
service:
name: static-service
port:
number: 80
2. 创建 TLS 证书 Secret
apiVersion: v1
kind: Secret
metadata:
name: tls-secret
type: kubernetes.io/tls
data:
tls.crt: <base64 编码的证书>
tls.key: <base64 编码的私钥>
五、常见 Ingress 控制器
| 控制器 | 特点 |
|---|---|
| Nginx Ingress | 最常用,功能丰富,支持注解扩展(限流、重写等)。 |
| Traefik | 原生支持 Let’s Encrypt,适合动态配置环境。 |
| AWS ALB Ingress | 直接集成 AWS ALB,适合云原生环境。 |
| HAProxy Ingress | 高性能,适合需要极致吞吐量的场景。 |
六、Ingress vs. Service LoadBalancer
| 特性 | Ingress | Service (LoadBalancer) |
|---|---|---|
| 协议支持 | HTTP/HTTPS | 任意 TCP/UDP |
| 路由粒度 | 基于域名/路径 | 仅端口级别 |
| 成本效率 | 单一入口承载多服务(节省公网 IP 和 LB) | 每个服务需独立 LB(成本高) |
| 适用场景 | 对外暴露 Web 服务 | 非 HTTP 服务或需直接暴露 TCP 的场景 |
七、总结
- Ingress 的核心价值:
✅ 统一管理 HTTP/HTTPS 流量入口
✅ 灵活的路由规则与 TLS 集中管理
✅ 节省云资源成本 - 使用场景:
- 需要对外暴露多个 Web 服务(如微服务架构)。
- 实现灰度发布、A/B 测试等高级流量控制。
- 统一 HTTPS 证书管理。
通过 Ingress,Kubernetes 能够以声明式的方式高效管理外部流量,是现代云原生应用不可或缺的组件。
k8s简介
一、核心载体:容器与Pod 这是k8s里最小的部署和运行单元,是所有概念的基础。
Pod
- 定义:k8s中最小的可部署单元,不是容器,而是一组紧密关联的容器的集合(通常1个Pod里跑1个主容器+若干辅助容器)。
- 特点:同一个Pod内的容器共享网络命名空间(可以用localhost互相通信)和存储卷;Pod是临时性的,被删除或故障后不会恢复,而是由控制器重新创建。
- 实例YAML(精简):
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
labels: {app: nginx}
spec:
containers:
- name: nginx-container
image: nginx:1.25
ports: [{containerPort: 80}]
容器(Container)
- 定义:就是Docker这类容器技术打包的应用,Pod是容器的“外壳”,k8s通过管理Pod来间接管理容器。
二、调度与管理:控制器(Controller) 控制器是k8s的“调度大脑”,负责确保Pod的实际状态和你声明的期望状态一致(比如你要3个Pod副本,它就会维持3个,少了就补)。
- Deployment
- 用途:最常用的控制器,用于管理无状态应用(比如前端、后端API)。
- 核心功能:支持滚动更新(逐个替换旧Pod,不中断服务)、回滚(更新出问题时一键退回旧版本)、扩缩容。
- 常用操作:
- 扩缩容:
kubectl scale deployment nginx-deploy --replicas=5 - 滚动更新:
kubectl set image deployment nginx-deploy nginx=nginx:1.26
- 扩缩容:
- StatefulSet
- 用途:用于管理有状态应用(比如数据库、Redis集群)。
- 核心特点:Pod有固定的名称和网络标识,存储卷和Pod绑定,重启后身份不变,适合需要持久化状态的应用。
- DaemonSet
- 用途:确保集群中每一个节点(或指定节点)都运行一个Pod副本。
- 典型场景:日志收集(比如Fluentd)、监控代理(比如Prometheus Node Exporter)。
- Job/CronJob
- Job:用于运行一次性任务(比如数据备份、批量计算),任务完成后Pod自动结束。
- CronJob:基于时间的定时任务(类似Linux的crontab),比如每天凌晨备份数据库。
- ReplicaSet(RS)
- 用途:直接管理Pod的副本数量,确保集群中始终有指定数量的Pod在运行。Deployment就是基于ReplicaSet实现的,日常使用中一般直接用Deployment即可。
三、服务访问:Service & Ingress Pod的IP是动态的(重启后会变),这两类概念解决“如何稳定访问Pod”的问题。
- Service
- 定义:为一组相同功能的Pod提供固定的访问入口和负载均衡。
- 核心类型:
- ClusterIP:默认类型,仅在集群内部可访问,用于集群内服务间通信(比如前端Pod访问后端Pod)。
- NodePort:在集群每个节点上开放一个固定端口,外部可以通过节点IP:端口访问服务,适合测试环境。
- LoadBalancer:结合云厂商的负载均衡器,自动分配公网IP,适合生产环境暴露服务。
- Ingress
- 定义:相当于k8s的“智能反向代理”,解决Service无法满足的复杂HTTP/HTTPS路由需求。
- 核心功能:域名路由(比如api.example.com指向后端服务,web.example.com指向前端服务)、SSL证书管理、路径匹配(比如/api转发到API服务)。
- 注意:Ingress本身只是规则,需要部署Ingress Controller(比如Nginx Ingress Controller)才能生效。
四、配置与存储:ConfigMap、Secret、Volume、PV/PVC 解决“应用配置管理”和“数据持久化”的问题。
- ConfigMap
- 用途:用于存储非敏感的配置数据(比如配置文件、环境变量、命令行参数)。
- 特点:可以和Pod解耦,修改ConfigMap后可以热更新Pod的配置,不用重建镜像。
- Secret
- 用途:用于存储敏感信息(比如密码、Token、SSL证书)。
- 特点:数据会被Base64编码存储(注意:不是加密,生产环境建议结合密钥管理工具),可以挂载到Pod里作为文件或环境变量。
- Volume
- 用途:用于Pod内的容器共享存储,或临时存储数据。
- 常见类型:
- emptyDir:Pod生命周期内的临时存储,Pod删除后数据丢失。
- hostPath:挂载节点的本地目录,适合单节点测试,不推荐生产用。
- PersistentVolume(PV)& PersistentVolumeClaim(PVC)
- 这是一套“存储资源池”机制,解决Pod数据持久化的问题(比如数据库数据需要永久保存)。
- PV:集群管理员创建的持久化存储资源(比如云硬盘、NFS共享存储),和节点无关。
- PVC:用户(开发者)申请存储的“请求单”,声明需要的存储大小、访问模式,k8s会自动绑定匹配的PV。
- 核心优势:用户不用关心底层存储的具体实现,只需要申请PVC即可。
五、基础架构核心组件
控制平面(Control Plane)
- API Server:所有操作统一入口,接收kubectl命令调用。
- etcd:分布式键值存储,保存集群所有状态(如Pod IP、Service配置)。
- Scheduler:按资源情况、亲和性规则,将Pod调度到合适Node。
- Controller Manager:包含多种控制器,自动修复故障Pod、维持集群状态。
工作节点(Node)
- Kubelet:与API Server通信,确保Pod按规格运行,上报Node状态。
- Kube-proxy:实现Service网络规则,将请求转发到后端Pod。
- Container Runtime:容器运行时(如Docker、Containerd),负责启动/停止容器。
六、补充核心概念:Namespace & Label/Selector
- Namespace
- 用途:集群的逻辑隔离单元,可以把不同的应用、环境(开发/测试/生产)隔离开,比如default(默认命名空间)、kube-system(k8s系统组件所在的命名空间)。
- 常用操作:
- 创建:
kubectl create namespace prod - 指定命名空间部署:
kubectl apply -f xxx.yaml -n prod
- 创建:
- Label & Selector
- 用途:k8s的“分组和筛选”机制,是实现“松耦合管理”的核心。
- Label:给资源(Pod、Service等)打标签,比如
app=web、env=prod。 - Selector:通过标签筛选资源,比如Service通过Selector找到对应的Pod,控制器通过Selector管理Pod。
七、核心总结
- 核心载体:Pod是最小部署单元,容器是应用载体,Pod为容器提供共享资源环境。
- 调度管理:控制器确保Pod状态符合期望,不同控制器适配不同应用场景(无状态/有状态/定时任务等)。
- 服务访问:Service提供稳定入口,Ingress解决复杂HTTP/HTTPS路由需求,保障Pod动态变化下的稳定访问。
- 配置存储:ConfigMap/Secret管理配置,Volume/PV/PVC实现数据持久化,解耦应用与配置、存储。
- 架构支撑:控制平面决策调度,Node节点执行运行,Namespace隔离资源,Label/Selector实现松耦合管理。
grpc
相关网站
- 官网
- github下载
- protobuf-go插件
- grpc-gateway-http转grpc
- swagger.json-根据api接口client
- buf-强化pb生成
- rk-golang微服务框架
- grpc-swift语言实现
- capnp-更快的protobuf
#mac系统中采用brew,很可能已安装过
brew list | grep protobuf
brew info protobuf
golang使用图示
sequenceDiagram
actor u as user
actor pf as proto文件
actor pc as protoc
actor pgg as protoc-gen-go
actor pb as .pb.go文件
u->>pf: 编写message
u->>pc: 启动
pc->>pf: 读取
pc->>pgg: 调用
pgg->>pb: 生成
u->>pb: 使用
- 生成文件
sequenceDiagram
actor u as user
actor pf as proto文件
actor pc as protoc
actor pgg as protoc-gen-go
actor pb as .pb.go文件
actor pggg as protoc-gen-go-grpc
actor gpb as grpc.pb.go文件
u->>pf: 编写message,service
u->>pc: 启动
pc->>pf: 读取
pc->>pgg: 调用
pgg->>pb: 生成
pc->>pggg: 调用
pggg->>gpb: 生成
u->>pb: 使用
u->>gpb: 使用
- 客户端使用
sequenceDiagram
actor u as user
actor gpb as grpc.pb.go文件
actor r as rpc服务器
u->>r: Dial()conn
u->>gpb: Newclient(conn)
u->>gpb: client.XXX()
gpb->>+r: conn发送请求
r-->>-gpb: return
gpb-->>u: return
- 服务端使用
sequenceDiagram
actor u as user
actor t as tcp
actor g as grpc
actor gpb as grpc.pb.go文件
u->>t: Listen()conn
u->>g: NewServer
u->>gpb: NewService
u->>g: RegService
u->>+g: Serve(conn)
g->>g: 等待客户端
实践示例
protoc --proto_path=IMPORT_PATH \
--cpp_out=DST_DIR \
--java_out=DST_DIR \
--python_out=DST_DIR \
--go_out=DST_DIR \
--ruby_out=DST_DIR \
--objc_out=DST_DIR \
--csharp_out=DST_DIR \
path/to/file.proto
#--go_out表示启动protoc-gen-go插件
#proto文件和本脚本在同一目录,执行前要cd到本目录,防止出现各种相对路径找不到
#Could not make proto path relative: *.proto: No such file or directory
protoc --cpp_out=../cpp --python_out=../python --go_out=../event *.proto
#--go-grpc_out表示启动protoc-gen-go-grpc插件
protoc --go_out=../event --go-grpc_out=../event *.proto
- user.proto内容
syntax = "proto3";
option go_package = "./;event";
import "person.proto";
service User {
rpc Reg(Person)returns(Person){}
}
- example.proto内容
syntax = "proto3";
package example;
//protoc-gen-go The import path must contain at least one period ('.') or forward slash ('/') character.
//https://developers.google.com/protocol-buffers/docs/reference/go-generated
//表示直接生成文件到go_out目录
option go_package = "./;event";
//vscode中vscode-proto3插件import提示无法找到other.proto
//vscode直接打开other.proto所在目录,不要打开父目录
import "other.proto";
//单行注释
message Person {
string name = 1;
int32 id = 2;
repeated string emails = 3;
map<string, int32> dict = 4;
repeated Order orders = 5;
}
/*
多行注释
*/
message SearchResponse {
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
repeated Result results = 1;
}
- other.proto内容
syntax = "proto3";
package example;
option go_package = "./;event";
message Order {
int64 id = 1;
uint64 date = 2;
string customer = 3;
double price = 4;
string goods = 5;
string remark = 6;
}
数据类型
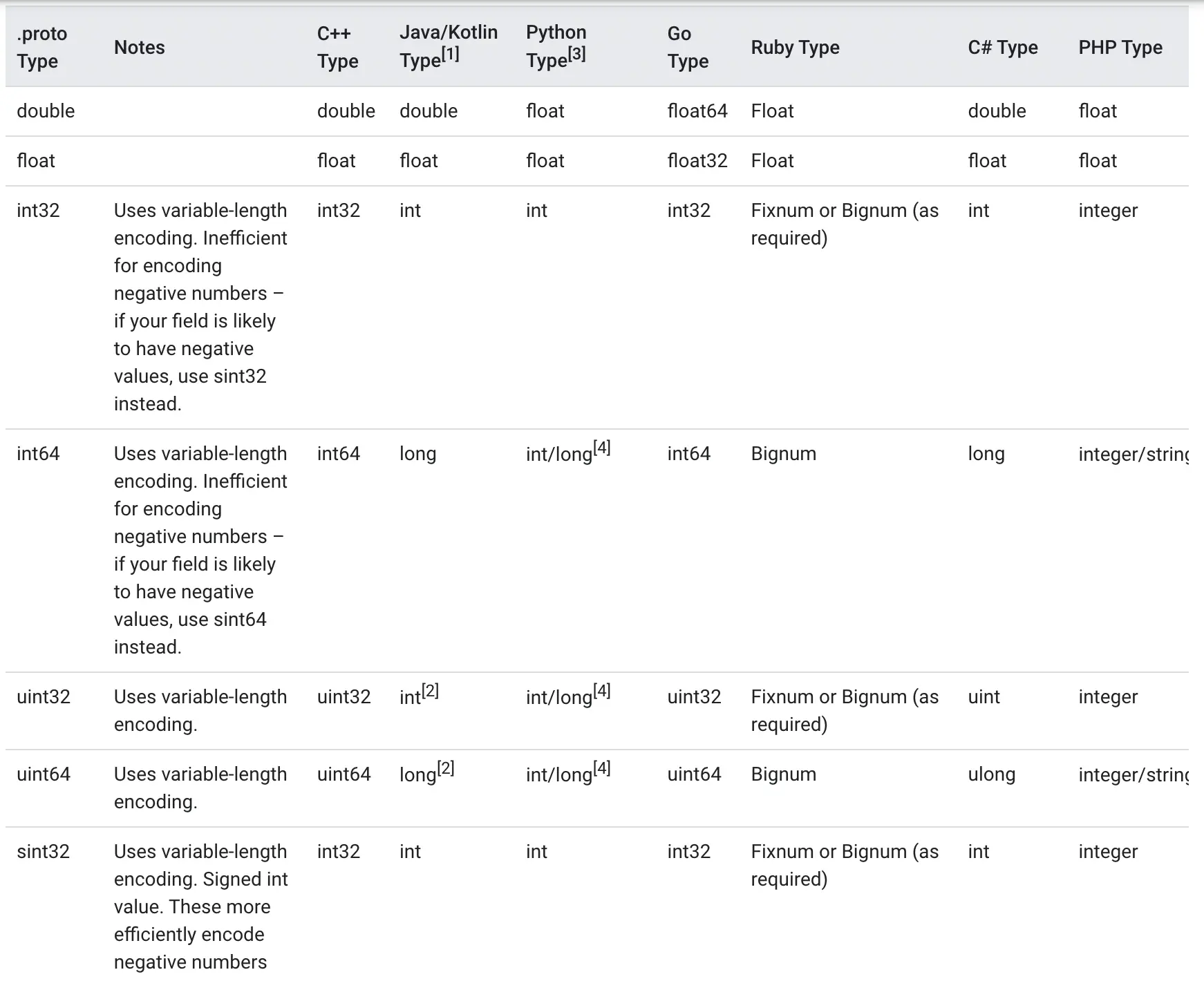

golang专用
在 Golang 中使用 Protocol Buffers (protobuf) 时,以下插件可以帮助提升开发效率:
1. protoc-gen-go
-
功能: 生成 Go 代码,将
.proto文件转换为 Go 结构体和序列化代码。 -
安装:
go install google.golang.org/protobuf/cmd/protoc-gen-go@latest -
使用:
protoc --go_out=. your_proto_file.proto
2. protoc-gen-go-grpc
-
功能: 生成 gRPC 服务代码,用于 gRPC 服务端和客户端。
-
安装:
go install google.golang.org/grpc/cmd/protoc-gen-go-grpc@latest -
使用:
protoc --go-grpc_out=. your_proto_file.proto
3. protoc-gen-gogo
-
功能:
protoc-gen-go的增强版,提供更多功能和优化。 -
安装:
go install github.com/gogo/protobuf/protoc-gen-gogo@latest -
使用:
protoc --gogo_out=. your_proto_file.proto
4. protoc-gen-validate
-
功能: 生成字段验证代码,基于
validate.proto文件中的规则。 -
安装:
go install github.com/envoyproxy/protoc-gen-validate@latest -
使用:
protoc --validate_out="lang=go:. your_proto_file.proto
5. protoc-gen-doc
-
功能: 生成
.proto文件的文档,支持多种格式。 -
安装:
go install github.com/pseudomuto/protoc-gen-doc/cmd/protoc-gen-doc@latest -
使用:
protoc --doc_out=. your_proto_file.proto
6. protoc-gen-grpc-gateway
-
功能: 生成 gRPC-Gateway 代码,将 gRPC 服务转换为 RESTful API。
-
安装:
go install github.com/grpc-ecosystem/grpc-gateway/v2/protoc-gen-grpc-gateway@latest -
使用:
protoc --grpc-gateway_out=. your_proto_file.proto
7. protoc-gen-swagger
-
功能: 生成 Swagger/OpenAPI 文档,通常与 gRPC-Gateway 配合使用。
-
安装:
go install github.com/grpc-ecosystem/grpc-gateway/v2/protoc-gen-openapiv2@latest -
使用:
protoc --openapiv2_out=. your_proto_file.proto
8. protoc-gen-gotag
-
功能: 为生成的 Go 结构体添加自定义标签。
-
安装:
go install github.com/srikrsna/protoc-gen-gotag@latest -
使用:
protoc --gotag_out=. your_proto_file.proto
9. protoc-gen-gorm
-
功能: 生成 GORM 模型代码,便于数据库操作。
-
安装:
go install github.com/infobloxopen/protoc-gen-gorm@latest -
使用:
protoc --gorm_out=. your_proto_file.proto
10. protoc-gen-inject-tag
-
功能: 为生成的 Go 结构体注入自定义标签。
-
安装:
go install github.com/favadi/protoc-gen-inject-tag@latest -
使用:
protoc --inject-tag_out=. your_proto_file.proto
11. protoc-gen-go-grpc-http
-
功能: 生成支持 HTTP/JSON 的 gRPC 服务代码。
-
安装:
go install github.com/grpc-ecosystem/grpc-gateway/v2/protoc-gen-grpc-http@latest -
使用:
protoc --grpc-http_out=. your_proto_file.proto
12. protoc-gen-twirp
-
功能: 生成 Twirp 服务代码,Twirp 是另一种 RPC 框架。
-
安装:
go install github.com/twitchtv/twirp/protoc-gen-twirp@latest -
使用:
protoc --twirp_out=. your_proto_file.proto
13. protoc-gen-go-binary
-
功能: 生成二进制序列化和反序列化代码。
-
安装:
go install github.com/golang/protobuf/protoc-gen-go-binary@latest -
使用:
protoc --go-binary_out=. your_proto_file.proto
14. protoc-gen-grpc-web
-
功能: 生成 gRPC-Web 客户端代码,适用于浏览器环境。
-
安装:
go install github.com/grpc/grpc-web/protoc-gen-grpc-web@latest -
使用:
protoc --grpc-web_out=. your_proto_file.proto
15. protoc-gen-grpc-gateway-ts
-
功能: 生成 TypeScript 客户端代码,适用于 gRPC-Gateway。
-
安装:
go install github.com/grpc-ecosystem/grpc-gateway/v2/protoc-gen-grpc-gateway-ts@latest -
使用:
protoc --grpc-gateway-ts_out=. your_proto_file.proto
更多
-
gRPC + Opentracing + Zipkin 分布式链路追踪系统
常用的插件
-
protoc-gen-python: 与
protoc-gen-go类似,这是为Python语言准备的一个官方插件,可以生成适用于Python环境的代码。 -
protoc-gen-swagger: 这个插件可以从你的.proto文件生成Swagger(现称为OpenAPI)文档。这对于想要提供RESTful API接口并需要良好API文档支持的项目来说非常有用。
-
protoc-gen-nats: 针对NATS消息系统的插件,它可以帮助你从.proto定义中生成适用于NATS的消息格式和处理逻辑,方便集成NATS作为你的消息传递层。
-
protoc-gen-ts: 一个用于生成TypeScript代码的插件。随着前端应用越来越复杂,这个插件允许你使用protobuf直接在TypeScript或JavaScript环境中定义数据结构,从而保持前后端数据模型的一致性。
-
protoc-gen-as3: 为ActionScript 3开发者提供的插件,使他们能够利用protobuf进行数据序列化和反序列化。
-
protoc-gen-rbi: 为Ruby开发者设计的插件,生成强类型的RBI(Ruby Interface)文件,以便更好地支持静态类型检查工具如Sorbet。
-
protoc-gen-mypy: 提供了为Python项目生成mypy兼容类型注解的能力,使得在Python中使用protobuf时可以获得更好的类型安全保证。
-
protoc-gen-starlark: 一个比较新颖的插件,允许用户通过Starlark脚本定制protobuf编译过程。Starlark是一种Python风格的配置语言,最初是为Bazel构建系统开发的。
-
protoc-gen-gorm: 为GORM(Go语言的ORM库)用户设计的插件,可以从.proto文件自动生成GORM模型,简化数据库操作。
-
protoc-gen-grpc-web: 这个插件允许从
.proto文件生成适用于gRPC-Web客户端的代码。gRPC-Web使得可以直接从浏览器通过HTTP/2调用gRPC服务,这对于构建现代化的Web应用非常有用。 -
protoc-gen-gofast: 一个高性能的Go语言插件,旨在比官方的
protoc-gen-go提供更快的序列化/反序列化速度。它优化了内存使用并减少了反射操作,适合性能敏感的应用场景。 -
protoc-gen-buf-breaking 和 protoc-gen-buf-lint: Buf工具集的一部分,这些插件用于检查protobuf定义中的潜在问题。
buf-breaking用于检测API兼容性破坏的变化,而buf-lint则用于确保遵循最佳实践和风格指南。 -
protoc-gen-openapiv2: 此插件可以从你的
.proto文件生成OpenAPI v2(以前称为Swagger)文档。这有助于创建RESTful API接口,并且可以集成到API网关或开发者门户中。 -
protoc-gen-micro: Micro是一个微服务生态系统,这个插件允许你为Micro服务生成客户端和服务端代码。它简化了微服务架构下的开发流程。
-
protoc-gen-jsonschema: 允许从
.proto文件生成JSON Schema,这对于需要与非protobuf系统交互的应用程序来说是非常有价值的,因为它们可能期望以JSON格式进行数据交换。 -
protoc-gen-doc: 提供了一个便捷的方式来生成协议缓冲区的文档。它可以输出多种格式的文档,包括Markdown、HTML等,帮助团队成员更好地理解和维护协议缓冲区定义。
-
protoc-gen-gateway: 类似于grpc-gateway,但它专注于生成基于HTTP/1.1的反向代理服务器,而不是gRPC Gateway使用的HTTP/2。这对于需要支持旧版HTTP协议的环境特别有用。
-
protoc-gen-validate: 提供了在.proto文件中指定验证规则的能力,并生成相应的验证逻辑。这对于确保数据完整性至关重要,尤其是在分布式系统中。
-
protoc-gen-natsrpc: 如果你在使用NATS作为消息队列或事件驱动架构的一部分,那么这个插件可以帮助你快速实现基于protobuf的消息传输机制。
自定义插件
syntax = "proto3";
package test;
option go_package = "/test";
message User {
//用户名
string Name = 1;
//用户资源
map<int32,string> Res=2 ;
}
package main
import (
"bytes"
"fmt"
"google.golang.org/protobuf/compiler/protogen"
"google.golang.org/protobuf/types/pluginpb"
"google.golang.org/protobuf/proto"
"io/ioutil"
"os"
)
func main() {
//1.读取标准输入,接收proto 解析的文件内容,并解析成结构体
input, _ := ioutil.ReadAll(os.Stdin)
var req pluginpb.CodeGeneratorRequest
proto.Unmarshal(input, &req)
//2.生成插件
opts := protogen.Options{}
plugin, err := opts.New(&req)
if err != nil {
panic(err)
}
// 3.在插件plugin.Files就是demo.proto 的内容了,是一个切片,每个切片元素代表一个文件内容
// 我们只需要遍历这个文件就能获取到文件的信息了
for _, file := range plugin.Files {
//创建一个buf 写入生成的文件内容
var buf bytes.Buffer
// 写入go 文件的package名
pkg := fmt.Sprintf("package %s", file.GoPackageName)
buf.Write([]byte(pkg))
//遍历消息,这个内容就是protobuf的每个消息
for _, msg := range file.Messages {
//接下来为每个消息生成hello 方法
buf.Write([]byte(fmt.Sprintf(`
func (m*%s)Hello(){
}
`,msg.GoIdent.GoName)))
}
//指定输入文件名,输出文件名为demo.foo.go
filename := file.GeneratedFilenamePrefix + ".foo.go"
file := plugin.NewGeneratedFile(filename, ".")
// 将内容写入插件文件内容
file.Write(buf.Bytes())
}
// 生成响应
stdout := plugin.Response()
out, err := proto.Marshal(stdout)
if err != nil {
panic(err)
}
// 将响应写回 标准输入, protoc会读取这个内容
fmt.Fprintf(os.Stdout, string(out))
}
在 Protocol Buffers (Protobuf) 中,扩展(Extensions) 是一种机制,允许你在不修改原始消息定义的情况下,向消息中添加额外的字段。这在需要扩展第三方或已定义的消息类型时非常有用。
在 proto3 中,扩展的功能有所限制,但仍然可以通过 Any 类型或自定义选项来实现类似的功能。以下是一个详细的示例,展示如何在 proto3 中使用扩展。
1. 扩展的基本概念
在 proto2 中,扩展是通过 extend 关键字实现的。但在 proto3 中,extend 关键字被移除了,官方推荐使用 Any 类型或自定义选项来实现扩展。
1.1 使用 Any 类型
Any 类型是 proto3 提供的一种通用类型,可以存储任意序列化的 Protobuf 消息。通过 Any 类型,你可以动态地将附加数据嵌入到消息中。
1.2 使用自定义选项
自定义选项是通过定义 google.protobuf.FieldOptions 或其他选项类型来实现的。你可以为字段添加自定义元数据。
2. 示例:使用 Any 类型实现扩展
以下是一个使用 Any 类型实现扩展的示例。
2.1 定义 .proto 文件
syntax = "proto3";
import "google/protobuf/any.proto";
// 定义一个基础消息
message BaseMessage {
string id = 1;
google.protobuf.Any extension = 2; // 用于存储扩展数据
}
// 定义一个扩展消息
message ExtendedMessage {
int32 extra_field = 1;
}
2.2 使用扩展
在代码中,你可以将 ExtendedMessage 嵌入到 BaseMessage 的 Any 字段中。
package main
import (
"fmt"
"log"
"google.golang.org/protobuf/proto"
"google.golang.org/protobuf/types/known/anypb"
"github.com/yourusername/yourproject/proto" // 替换为你的模块路径
)
func main() {
// 创建一个 ExtendedMessage
extendedMsg := &proto.ExtendedMessage{
ExtraField: 42,
}
// 将 ExtendedMessage 打包为 Any 类型
anyMsg, err := anypb.New(extendedMsg)
if err != nil {
log.Fatalf("Failed to pack ExtendedMessage into Any: %v", err)
}
// 创建一个 BaseMessage 并设置扩展字段
baseMsg := &proto.BaseMessage{
Id: "123",
Extension: anyMsg,
}
// 序列化 BaseMessage
data, err := proto.Marshal(baseMsg)
if err != nil {
log.Fatalf("Failed to marshal BaseMessage: %v", err)
}
// 反序列化 BaseMessage
newBaseMsg := &proto.BaseMessage{}
if err := proto.Unmarshal(data, newBaseMsg); err != nil {
log.Fatalf("Failed to unmarshal BaseMessage: %v", err)
}
// 从 Any 字段中提取 ExtendedMessage
newExtendedMsg := &proto.ExtendedMessage{}
if err := newBaseMsg.GetExtension().UnmarshalTo(newExtendedMsg); err != nil {
log.Fatalf("Failed to unpack ExtendedMessage from Any: %v", err)
}
// 打印结果
fmt.Printf("BaseMessage ID: %s\n", newBaseMsg.GetId())
fmt.Printf("ExtendedMessage ExtraField: %d\n", newExtendedMsg.GetExtraField())
}
3. 示例:使用自定义选项实现扩展
以下是一个使用自定义选项实现扩展的示例。
3.1 定义自定义选项
首先,定义一个自定义选项:
syntax = "proto3";
import "google/protobuf/descriptor.proto";
// 定义自定义选项
extend google.protobuf.FieldOptions {
string custom_option = 50000;
}
// 使用自定义选项
message MyMessage {
string field1 = 1 [(custom_option) = "custom_value"];
}
3.2 使用自定义选项
在代码中,你可以通过反射访问自定义选项的值。
package main
import (
"fmt"
"log"
"reflect"
"google.golang.org/protobuf/proto"
"google.golang.org/protobuf/reflect/protoreflect"
"google.golang.org/protobuf/types/descriptorpb"
"github.com/yourusername/yourproject/proto" // 替换为你的模块路径
)
func main() {
// 获取 MyMessage 的描述符
msgType := proto.MessageType("proto.MyMessage").Elem()
msgDescriptor := msgType.New().Interface().(protoreflect.ProtoMessage).ProtoReflect().Descriptor()
// 获取字段描述符
fieldDescriptor := msgDescriptor.Fields().ByName("field1")
// 获取字段选项
options := fieldDescriptor.Options().(*descriptorpb.FieldOptions)
// 获取自定义选项的值
customOptionValue := proto.GetExtension(options, proto.E_CustomOption).(string)
fmt.Printf("Custom option value: %s\n", customOptionValue)
}
4. 总结
在 proto3 中,扩展的功能主要通过以下方式实现:
- 使用
Any类型:动态嵌入任意消息类型。 - 使用自定义选项:为字段添加元数据。
这两种方式都可以在不修改原始消息定义的情况下扩展消息的功能。根据具体需求选择合适的方式即可。
参考文档
作为 Protobuf 专家,MethodOptions 的自定义选项在定义 RPC 方法时非常有用,能够为方法添加额外的元数据或行为控制。以下是一些经典的 MethodOptions 自定义选项应用场景:
作为 Protobuf 专家,MethodOptions 的自定义选项在定义 RPC 方法时非常有用,能够为方法添加额外的元数据或行为控制。以下是一些经典的 MethodOptions 自定义选项应用场景:
1. 方法超时配置
-
用途: 为 RPC 方法配置超时时间,确保方法在指定时间内完成。
-
示例: 标记方法的超时时间。
import "google/protobuf/descriptor.proto"; extend google.protobuf.MethodOptions { int32 timeout_ms = 50000; } service MyService { rpc MyMethod(MyRequest) returns (MyResponse) { option (timeout_ms) = 5000; // 5 seconds } }
2. 方法重试策略
-
用途: 为 RPC 方法配置重试策略,如重试次数和重试间隔。
-
示例: 标记方法的最大重试次数和重试间隔。
extend google.protobuf.MethodOptions { int32 max_retries = 50001; int32 retry_interval_ms = 50002; } service MyService { rpc MyMethod(MyRequest) returns (MyResponse) { option (max_retries) = 3; option (retry_interval_ms) = 1000; // 1 second } }
3. 方法安全性配置
-
用途: 为 RPC 方法配置安全性要求,如是否需要身份验证或加密。
-
示例: 标记方法是否需要身份验证。
extend google.protobuf.MethodOptions { bool requires_authentication = 50003; } service MyService { rpc SecureMethod(SecureRequest) returns (SecureResponse) { option (requires_authentication) = true; } }
4. 方法权限控制
-
用途: 为 RPC 方法配置权限要求,如用户角色或权限级别。
-
示例: 标记方法所需的用户角色。
extend google.protobuf.MethodOptions { string required_role = 50004; } service MyService { rpc AdminMethod(AdminRequest) returns (AdminResponse) { option (required_role) = "ADMIN"; } }
5. 方法性能优化
-
用途: 为 RPC 方法配置性能优化选项,如是否启用压缩或缓存。
-
示例: 标记方法是否启用响应缓存。
extend google.protobuf.MethodOptions { bool enable_caching = 50005; } service MyService { rpc GetData(DataRequest) returns (DataResponse) { option (enable_caching) = true; } }
6. 方法日志配置
-
用途: 为 RPC 方法配置日志记录行为,如是否记录详细日志。
-
示例: 标记方法是否启用详细日志记录。
extend google.protobuf.MethodOptions { bool enable_detailed_logging = 50006; } service MyService { rpc LoggedMethod(LoggedRequest) returns (LoggedResponse) { option (enable_detailed_logging) = true; } }
7. 方法路由配置
-
用途: 为 RPC 方法配置路由信息,便于在分布式系统中进行消息分发。
-
示例: 标记方法的路由键或目标服务。
extend google.protobuf.MethodOptions { string routing_key = 50007; } service MyService { rpc RoutedMethod(RoutedRequest) returns (RoutedResponse) { option (routing_key) = "service_a"; } }
8. 方法负载均衡策略
-
用途: 为 RPC 方法配置负载均衡策略。
-
示例: 标记方法的负载均衡策略(如
ROUND_ROBIN,LEAST_CONNECTIONS)。extend google.protobuf.MethodOptions { string load_balancing_strategy = 50008; } service MyService { rpc BalancedMethod(BalancedRequest) returns (BalancedResponse) { option (load_balancing_strategy) = "ROUND_ROBIN"; } }
9. 方法扩展插件支持
-
用途: 为 RPC 方法添加插件支持的配置,如自定义代码生成插件。
-
示例: 为自定义插件提供配置选项。
extend google.protobuf.MethodOptions { string plugin_option = 50009; } service MyService { rpc PluginMethod(PluginRequest) returns (PluginResponse) { option (plugin_option) = "custom_value"; } }
10. 方法优先级
-
用途: 为 RPC 方法配置优先级,便于在任务调度或资源分配中处理。
-
示例: 标记方法的优先级(如
HIGH,MEDIUM,LOW)。extend google.protobuf.MethodOptions { string priority = 50010; } service MyService { rpc HighPriorityMethod(HighPriorityRequest) returns (HighPriorityResponse) { option (priority) = "HIGH"; } }
11. 方法跨平台兼容性
-
用途: 为 RPC 方法配置跨平台兼容性选项。
-
示例: 标记方法在特定平台上的行为。
extend google.protobuf.MethodOptions { string platform_specific = 50011; } service MyService { rpc PlatformMethod(PlatformRequest) returns (PlatformResponse) { option (platform_specific) = "windows"; } }
12. 方法生命周期管理
-
用途: 为 RPC 方法配置生命周期状态,如是否已弃用。
-
示例: 标记方法的状态(如
ACTIVE,DEPRECATED,REMOVED)。extend google.protobuf.MethodOptions { string lifecycle_status = 50012; } service MyService { rpc DeprecatedMethod(DeprecatedRequest) returns (DeprecatedResponse) { option (lifecycle_status) = "DEPRECATED"; } }
13. 方法流量控制
-
用途: 为 RPC 方法配置流量控制策略,如限流或速率限制。
-
示例: 标记方法的速率限制(如每秒请求数)。
extend google.protobuf.MethodOptions { int32 rate_limit = 50013; } service MyService { rpc RateLimitedMethod(RateLimitedRequest) returns (RateLimitedResponse) { option (rate_limit) = 100; // 100 requests per second } }
14. 方法监控配置
-
用途: 为 RPC 方法配置监控选项,如是否启用性能监控。
-
示例: 标记方法是否启用性能监控。
extend google.protobuf.MethodOptions { bool enable_performance_monitoring = 50014; } service MyService { rpc MonitoredMethod(MonitoredRequest) returns (MonitoredResponse) { option (enable_performance_monitoring) = true; } }
总结
MethodOptions 的自定义选项为 Protobuf 的 RPC 方法提供了强大的扩展能力,能够满足各种复杂的应用场景。通过合理使用这些选项,可以增强方法的元数据管理、行为控制、跨平台兼容性以及与其他系统的集成能力。这些选项在微服务架构、API 管理和分布式系统中尤其有用。
1. 方法超时配置
-
用途: 为 RPC 方法配置超时时间,确保方法在指定时间内完成。
-
示例: 标记方法的超时时间。
import "google/protobuf/descriptor.proto"; extend google.protobuf.MethodOptions { int32 timeout_ms = 50000; } service MyService { rpc MyMethod(MyRequest) returns (MyResponse) { option (timeout_ms) = 5000; // 5 seconds } }
2. 方法重试策略
-
用途: 为 RPC 方法配置重试策略,如重试次数和重试间隔。
-
示例: 标记方法的最大重试次数和重试间隔。
extend google.protobuf.MethodOptions { int32 max_retries = 50001; int32 retry_interval_ms = 50002; } service MyService { rpc MyMethod(MyRequest) returns (MyResponse) { option (max_retries) = 3; option (retry_interval_ms) = 1000; // 1 second } }
3. 方法安全性配置
-
用途: 为 RPC 方法配置安全性要求,如是否需要身份验证或加密。
-
示例: 标记方法是否需要身份验证。
extend google.protobuf.MethodOptions { bool requires_authentication = 50003; } service MyService { rpc SecureMethod(SecureRequest) returns (SecureResponse) { option (requires_authentication) = true; } }
4. 方法权限控制
-
用途: 为 RPC 方法配置权限要求,如用户角色或权限级别。
-
示例: 标记方法所需的用户角色。
extend google.protobuf.MethodOptions { string required_role = 50004; } service MyService { rpc AdminMethod(AdminRequest) returns (AdminResponse) { option (required_role) = "ADMIN"; } }
5. 方法性能优化
-
用途: 为 RPC 方法配置性能优化选项,如是否启用压缩或缓存。
-
示例: 标记方法是否启用响应缓存。
extend google.protobuf.MethodOptions { bool enable_caching = 50005; } service MyService { rpc GetData(DataRequest) returns (DataResponse) { option (enable_caching) = true; } }
6. 方法日志配置
-
用途: 为 RPC 方法配置日志记录行为,如是否记录详细日志。
-
示例: 标记方法是否启用详细日志记录。
extend google.protobuf.MethodOptions { bool enable_detailed_logging = 50006; } service MyService { rpc LoggedMethod(LoggedRequest) returns (LoggedResponse) { option (enable_detailed_logging) = true; } }
7. 方法路由配置
-
用途: 为 RPC 方法配置路由信息,便于在分布式系统中进行消息分发。
-
示例: 标记方法的路由键或目标服务。
extend google.protobuf.MethodOptions { string routing_key = 50007; } service MyService { rpc RoutedMethod(RoutedRequest) returns (RoutedResponse) { option (routing_key) = "service_a"; } }
8. 方法负载均衡策略
-
用途: 为 RPC 方法配置负载均衡策略。
-
示例: 标记方法的负载均衡策略(如
ROUND_ROBIN,LEAST_CONNECTIONS)。extend google.protobuf.MethodOptions { string load_balancing_strategy = 50008; } service MyService { rpc BalancedMethod(BalancedRequest) returns (BalancedResponse) { option (load_balancing_strategy) = "ROUND_ROBIN"; } }
9. 方法扩展插件支持
-
用途: 为 RPC 方法添加插件支持的配置,如自定义代码生成插件。
-
示例: 为自定义插件提供配置选项。
extend google.protobuf.MethodOptions { string plugin_option = 50009; } service MyService { rpc PluginMethod(PluginRequest) returns (PluginResponse) { option (plugin_option) = "custom_value"; } }
10. 方法优先级
-
用途: 为 RPC 方法配置优先级,便于在任务调度或资源分配中处理。
-
示例: 标记方法的优先级(如
HIGH,MEDIUM,LOW)。extend google.protobuf.MethodOptions { string priority = 50010; } service MyService { rpc HighPriorityMethod(HighPriorityRequest) returns (HighPriorityResponse) { option (priority) = "HIGH"; } }
11. 方法跨平台兼容性
-
用途: 为 RPC 方法配置跨平台兼容性选项。
-
示例: 标记方法在特定平台上的行为。
extend google.protobuf.MethodOptions { string platform_specific = 50011; } service MyService { rpc PlatformMethod(PlatformRequest) returns (PlatformResponse) { option (platform_specific) = "windows"; } }
12. 方法生命周期管理
-
用途: 为 RPC 方法配置生命周期状态,如是否已弃用。
-
示例: 标记方法的状态(如
ACTIVE,DEPRECATED,REMOVED)。extend google.protobuf.MethodOptions { string lifecycle_status = 50012; } service MyService { rpc DeprecatedMethod(DeprecatedRequest) returns (DeprecatedResponse) { option (lifecycle_status) = "DEPRECATED"; } }
13. 方法流量控制
-
用途: 为 RPC 方法配置流量控制策略,如限流或速率限制。
-
示例: 标记方法的速率限制(如每秒请求数)。
extend google.protobuf.MethodOptions { int32 rate_limit = 50013; } service MyService { rpc RateLimitedMethod(RateLimitedRequest) returns (RateLimitedResponse) { option (rate_limit) = 100; // 100 requests per second } }
14. 方法监控配置
-
用途: 为 RPC 方法配置监控选项,如是否启用性能监控。
-
示例: 标记方法是否启用性能监控。
extend google.protobuf.MethodOptions { bool enable_performance_monitoring = 50014; } service MyService { rpc MonitoredMethod(MonitoredRequest) returns (MonitoredResponse) { option (enable_performance_monitoring) = true; } }
总结
MethodOptions 的自定义选项为 Protobuf 的 RPC 方法提供了强大的扩展能力,能够满足各种复杂的应用场景。通过合理使用这些选项,可以增强方法的元数据管理、行为控制、跨平台兼容性以及与其他系统的集成能力。这些选项在微服务架构、API 管理和分布式系统中尤其有用。
代码托管
总览
flowchart LR A(域名解析) --> B(配置Nginx) B --> C(配置gogs) C --> D(git提交) D --> E(golang使用)
sequenceDiagram
actor u as 用户
actor h as hosts
actor n as Nginx
actor g as Gogs
actor f as 文件系统
u->>h: mydomain.site
h-->>u: 127.0.0.1
n->>n: 监听127.0.0.1
u->>n: `https://mydomain.site/what/up....`
n->>+g: `http://xx.xx.xx.xx:3000/what/up...`
g->>f: 读写
g-->>-n: http回包
n-->>u: https回包
域名解析
-
修改hosts
vim /etc/hosts #配置mydomain.site的dns为本机 #如果域名有备案,可以跳过此步,直接增加域名的A记录 127.0.0.1 mydomain.site -
申请域名证书
现在都不走http,都走https.个人项目,所以申请免费证书.生产环境还是要收费证书.免费申请证书途径:
- freessl网站
- letsencrypt网站
- 阿里云SSL证书服务
- 又拍云SSL 证书服务
- 七牛云免费SSL证书
- 百度云SSL证书服务
- 腾讯云SSL证书服务
- 华为云SSL证书管理SCM
配置Nginx
-
安装nginx
brew install nginx # 如果遇到不能启动,尝试启动sudo brew services start nginx brew services start nginx -
修改配置文件
...
server {
listen 443 ssl;
server_name mydomain.site;
#mydomain.site.pem/mydomain.site.key
#就是申请域名证书后,网站提供的相关文件
ssl_certificate ssl/mydomain.site.pem;
ssl_certificate_key ssl/mydomain.site.key;
ssl_session_cache shared:SSL:1m;
ssl_session_timeout 5m;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_prefer_server_ciphers on;
location / {
#直接转发gogs目录
proxy_pass http://xx.xx.xx.xx:3000;
}
}
...
配置gogs
-
安装gogs
wget https://dl.gogs.io/$VERSION/gogs_$VERSION_$OS_$ARCH.tar.gz tar -zxvf gogs_$VERSION_$OS_$ARCH.tar.gz cd gogs_$VERSION_$OS_$ARCH- 其他方式安装,看这里
-
修改配置
[server] DOMAIN = mydomain.site HTTP_PORT = 3000 //旧版本是修改ROOT_URL EXTERNAL_URL = https://mydomain.site/ -
运行
#后台守护进程运行 nohup ./gogs web & -
创建仓库(可以导入其他的repos,快速创建)
#假设用户名为what,仓库名为up,仓库必须为公开,则仓库地址: https://mydomain.site/what/up.git
git使用
#git下载
git clone https://mydomain.site/what/up.git
#增加代码及其他
....
#提交代码
git push
golang使用
-
设置私域名,不走代理
go env -w GOPRIVATE=mydomain.site -
代码使用
package main import ( "fmt" "mydomain.site/what/up" ) func main() { fmt.Println(up.Add(10, 10)) fmt.Println(up.Power(10, 10)) }
shell
man中文手册(https://github.com/man-pages-zh/manpages-zh)
sudo apt update
sudo apt install manpages-zh
dnf update
dnf install man-pages-zh-CN
升级替换系统命令-modern-unix)
- bat代替cat, bat 相比 cat 增加了行号和颜色高亮 👍
- duf代替df
- exa代替ls
- dust代替du
- procs代替ps
- difft替代diff
- McFly(https://github.com/cantino/mcfly) 执行时间久,会影响启动速度
- zoxide代替cd,可能不用启动z
- tldr替代man, tldr-github pip install tldr
- ctrl+r 搜索历史命令
tmux-会话与窗口分离器
brew install tmux
Tmux 是一个终端复用器(terminal multiplexer),非常有用,属于常用的开发工具。
1.1 会话与进程
命令行的典型使用方式是,打开一个终端窗口(terminal window,以下简称"窗口"),在里面输入命令。用户与计算机的这种临时的交互,称为一次"会话"(session) 。
会话的一个重要特点是,窗口与其中启动的进程是连在一起的。打开窗口,会话开始;关闭窗口,会话结束,会话内部的进程也会随之终止,不管有没有运行完。
为了解决这个问题,会话与窗口可以"解绑":窗口关闭时,会话并不终止,而是继续运行,等到以后需要的时候,再让会话"绑定"其他窗口。
Tmux 可以将窗口分成多个窗格(pane),每个窗格运行不同的命令。以下命令都是在 Tmux 窗口中执行。
tmux split-window 上下
tmux split-window -h 左右
# 光标切换到上方窗格
$ tmux select-pane -U
# 光标切换到下方窗格
$ tmux select-pane -D
# 光标切换到左边窗格
$ tmux select-pane -L
# 光标切换到右边窗格
$ tmux select-pane -R
# 或者ctrl+r
mcfly search
并发启动命令
for var in {0..2}
do
#用{}把循环体括起来,后加一个&符号,代表每次循环都把命令放入后台运行
#一旦放入后台,就意味着{}里面的命令交给操作系统的一个线程处理了
{
echo ${var}
}&
done
wait
#wait命令的意思是,等待(wait命令)上面的命令(放入后台的)都执行完毕了再往下执行
常用源目录
- /etc/yum.repos.d
systemd新时代linux服务管理软件,就是平时使用(systemctl start stop enable disable status) xxx
- systemd是一个服务管理器,它使管理服务器变得更加容易。
- 对于支持 systemd 的软件,安装的时候,它会自动的在 /usr/lib/systemd/system 目录添加一个配置文件
- /lib -> /usr/lib 通常路径被软链接
curl带用户名密码的pos提交
curl -i -X POST \
http://localhost:4080/api/test/_doc \
-u user:pwd \
-H 'Content-Type: application/json' \
-d '{"name":"中文12344", "value":"https://abc.iste/"}'
curl -X DELETE \
http://127.0.0.1:4080/api/index/xxx/ \
-u user:pwd
# 获取本机外网ip
curl ifconfig.me
查看哪个命令在哪个包中
# dnf是yum的继承者,更好用
# 查找提供指定内容的软件包
dnf provides '*/chsh'
# 以 Fedora 为基准的安装包如下
dnf install -y util-linux-user
# 搜索一定要加引号
dnf search 'keyword'
# 修改默认的shell
chsh [option] user
# 带调试查看ssh登陆过程,用于卡
ssh -vvv xxxx
# 后来ssh -v 登录查看了下日志,发现一直卡在debug1: SSH2_MSG_KEXINIT sent。直到最后链接失败。
# 网上查了很多,发现是因为mtu设置的数值太大。网络->高级->手动(平时是自动)->指定1500
.ssh/config管理多个ssh密钥
-
~/.ssh/config如果不存在,则创建.
... # Host可以自定义 Host github2 # github.com这个是真实远程服务器,不能修改 # id_ecdsa.pub内容要在github相应帐户添加为ssh密钥 HostName github.com PreferredAuthentications publickey # 指明用哪个文件 IdentityFile ~/.ssh/id_ecdsa ...- Host的定义可以有多组,用指定哪个ssh密钥对应哪个HostName/Host
- 一般不同域名不同ssh密钥不用配置config,能自动查找对应
-
测试config
#github2为config文件中的Host值 ssh -T git@github2 # 查看ssh登陆详情 ssh -vvvT git@github2- 如果github.com的帐户username设置了id_ecdsa.pub
- 则会回包Hi username! You’ve successfully authenticated, but GitHub does not provide shell access
-
修改远程仓库url
#git@github.com:username/reposname.git==>git@github2:username/reposname.git #github2为config文件中的Host值,表明reposname要采用id_ecdsa密钥 git clone git@github2:username/reposname.git -
本地reposename配置.git/config
cd reposname git config user.name 'username' git config user.email 'username@xx.com'- github根据配置文件的user.email来获取github帐号显示author信息
在连接远程SSH服务的时候,经常会发生长时间后的断线,或者无响应(无法再键盘输入)
- 客户端定时发送心跳,添加修改本机~/ssh/config
vim config
# 即每隔30秒,向服务器发出一次心跳
ServerAliveInterval 30
# 若超过100次请求,都没有发送成功,则会主动断开与服务器端的连接。
ServerAliveCountMax 100
- 服务器端定时向客户端发送心跳,修改服务器端 ssh配置 /etc/ssh/sshd_config
vim /etc/ssh/sshd_config
# 表示每隔多少秒,服务器端向客户端发送心跳
ClientAliveInterval 30
# 表示上述多少次心跳无响应之后,会认为Client已经断开
ClientAliveCountMax 6
xargs(命令行参数)和|(标准输入)
#find标准输出为每行一个文件名
#直接通过管道转为grep的标准输入,则grep搜索标准输入包括protobuf的
#输出结果:文件名以.mod结束且包括protobuf
find . -name "*.mod" | grep protobuf
#管道转为xargs的标准输入,
#xargs把标准输入转化为grep的参数
#grep指定的文件名里内容包括protobuf的
#输出结果:文件名以.mod结束且文件内容包括protobuf
find . -name "*.mod" | xargs grep protobuf
# 搜索名字叫html目录
find . -type d -name 'html'
- 管道(|)的作用是将前面命令的标准输出作为后面命令的标准输入
- xargs将标准输入转成各种格式化的参数
常用命令
set -v 回显命令,但不替换变量值
set -x 回显命名,替换变量值
# 用双引号处理带空格的文件
cp "带空格的文件" newfile
ls -l | grep "^-" | wc -l 当前目录下文件总数
# linux网络共享网盘nfs,/etc/exports文件增加一个共享目录
#产生ssh密钥对,注意-C大写,保存id_rsa文件名,ssh会默认读取,否则就要明确指出
#-b:指定密钥长度;-C:添加注释;-f:指定用来保存密钥的文件名;-t:指定要创建的密钥类型。
#现在很多地方都不支持rsa,建议采用ed25519/ecdsa
# -t [dsa | ecdsa | ecdsa-sk | ed25519 | ed25519-sk | rsa]
ssh-keygen -t rsa -C "xxx@aliyun.com" -f id_rsa
# 注意-t之后的空格,有可能提示不识别参数
ssh-keygen -t ed25519 -C "xxx@aliyun.com" -f id_ed25519
# 显示正在使用的shell
echo $SHELL
# 快速切换目录, vim .bashrc/.zshrc source .bashrc/.zshrc
export $CDPATH=.:~:/xxx/
#获取历史命令
#zsh
cat $HOME/.zsh_history
#bsh
cat $HOME/.bash_history
# 查看磁盘占用情况
df -h
#查看当前一级目录文件大小
du -h --max-depth=1
# 清空./var/journalctl日志
journalctl --vacuum-size=10M
# ls人性化阅读
ls -lh
# 复制到粘贴板
#windows
clip < ~/.ssh/id_ed25519.pub
#mac
pbcopy < ~/.ssh/id_ed25519.pub
#linux
xclip -sel clip < ~/.ssh/id_ed25519.pub
# 获取脚本所在目录
dirname $0
cd `dirname $0`
pwd
# 获取home目录
echo $HOME
# 当前时间、系统已经运行了多长时间、目前有多少登陆用户、系统在过去的1分钟、5分钟和15分钟内的平均负载。
uptime
# 解决ssh超级慢(去除服务端利用dns反查客户端)
vi /etc/ssh/sshd_config
UseDNS no
GSSAPIAuthentication no
# 列出所有监听tcp端口程序
netstat -ltpn
#查看所有服务监听端口
netstat -a
# 监听tcp指定端口
tcpdump tcp port xxx
#查看网卡流量:每1秒 显示 1次 显示 10次
sar -n DEV 1 10
# 查看命令执行情况
set -V
#防火墙:
#查看是否打开端口:
firewall-cmd --list-all
#添加端口:
firewall-cmd --permanent --add-port=3000/tcp
#批量增加端口:
firewall-cmd --permanent --zone=public --add-port=7000-8000/tcp
#移除端口:
firewall-cmd --permanent --remove-port=7780/tcp
#重新加载规则生效
firewall-cmd --reload
#查找前20名占用内存较大:
ps aux | head -1;ps aux |grep -v PID |sort -rn -k +4 | head -20
# 建立软连接
ln -s 真实存在目录 软链接
积累
# 使用-j参数 不处理压缩文件中原来目录路径
zip -qj file.zip /xxx/xx/xx
# Parallel
https://linux.cn/article-9718-1.html 使用 GNU Parallel 提高 Linux 命令行执行效率
示例脚本
- linux 普通用户实现sudo免密
vim /etc/sudoers.d
增加一个文件,添加以下内容
username ALL=(ALL) NOPASSWD:ALL
- 利用git部署更新脚本
#!/usr/bin/env bash
cd ${gitdir}
# 批量杀死监控进程 shell脚本或专用管理程序
ps -ef|grep xxx | grep -v grep | awk '{print $2}' | xargs kill -9
# 批量杀死目标进程
ps -ef|grep yyy | grep -v grep | awk '{print $2}' | xargs kill -9
# 拉取最新程序
git pull
# 跑起监控进程
nohup ./xxx.sh >/dev/null 2>&1 &
- 监控脚本
#!/usr/bin/env bash
while true
do
# 查看目标进程还在不在
procnum=` ps -ef|grep "yyy$"|grep -v grep|wc -l`
if [ $procnum -eq 0 ]; then
cd ${basedir}
nohup ./yyy >/dev/null 2>&1 &
fi
# 延时30秒
sleep 30
done
- 编译脚本
#!/usr/bin/env bash
# 批量杀死目标进程
ps -ef|grep yyy | grep -v grep | awk '{print $2}' | xargs kill -9
hash=`git rev-parse --short HEAD`
rc=`date "+%Y-%m-%d_%H:%M:%S"`
target=yyy
go build -ldflags "-s -w -X main.GitHash=${hash} -X main.CompileTime=${rc}" -tags=jsoniter -o ${target} ${target}.go
chmod a+x ${target}
rundir=${target}_run
rm -rf ${rundir}
mkdir ${rundir}
mv ${target} ${rundir}
cp -r conf ${rundir}/
nohup ./${target} >/dev/null 2>&1 &
exit
- 设置北京时间
sudo timedatectl set-timezone Asia/Shanghai
常见包管理
- apt = apt-get、apt-cache 和 apt-config 中最常用命令选项的集合。
- dnf 是 yum的升级版
显卡
sudo lshw -numeric -C display显示显卡信息,lspci | grep -i vga
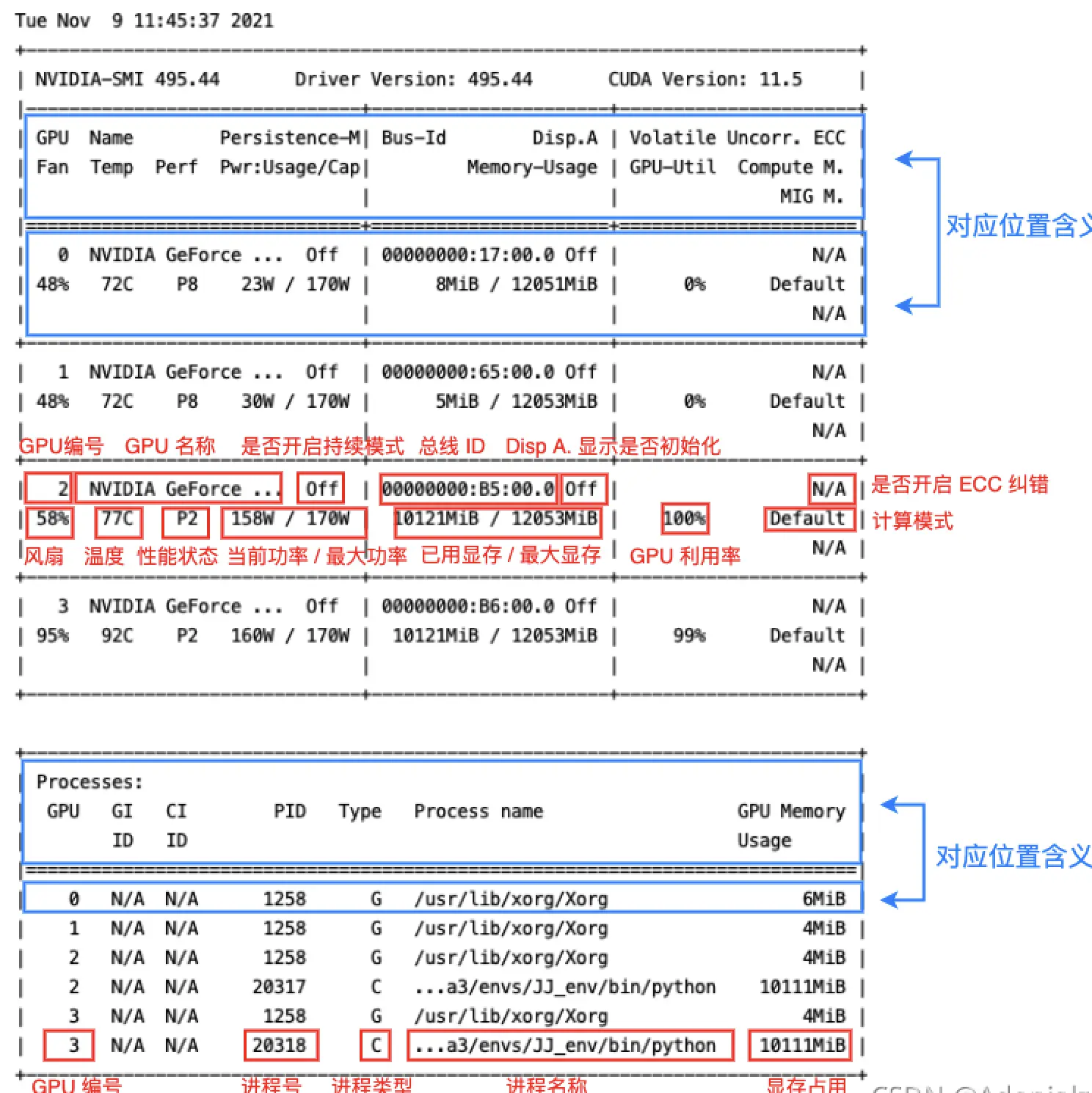
权限错误
# Permissions 0644 for '/root/.ssh/id_ecdsa' are too open
# 降低权限
chmod 0600 ~/.ssh/id_ecdsa
mlocate-更快的find
这个命令的原理是,先为文件系统创建索引数据库,mlocate只是搜索索引,所以速度快 对于新增文件应该先updatedb更新数据库,否则就搜不到,当然更新索引时,执行updatedb还是比较快的 mlocate在很多系统中和locate同名
#创建索引 扫描整个系统,为整个系统创建索引,数据库在/var/lib/mlocate/mlocate.db
sudo updatedb
mlocate abc.txt
mlocate -ie abc.txt 如果 abc.txt已经删除了,使用-e会检查文件是否真实存在,而不必updatedb;-i,忽略大小写
mlocate /etc/*profile 在/etc中查找类似profile的文件
古老的netrc,windows是_netrc文件
.netrc文件是unix系统中古老的文件,该.netrc文件格式于 1978 年发明并首次用于Berknet,此后一直被各种工具和库使用。顺便说一句,这就是英特尔推出 8086 的同一年,而 DNS 还不存在。几十年来,ftp、curl(从 1998 年夏天开始)、wget、fetchmail 和大量其他工具和网络库一直支持 .netrc。在许多情况下,它是向远程系统提供凭据的唯一跨工具方式。
Delta RPM
Delta RPM软件包包含RPM软件包的新旧版本之间的差异。在旧的RPM上应用增量RPM会得到完整的新RPM。不必拥有旧RPM的副本,
startship.rs值得一用
wireshark
替代品
-
[Sniffnet 是一个基于 Rust 的网络监控工具,可让你跟踪通过系统的所有互联网流量]
-
[proxyman-可免费使用优秀的抓包工具]
抓https,http2包
- 配置firefox
#设置环境变量,让firefox编入通讯密钥,调试完成后记得删除这个环境变量,它会影响速度和浪费空间
export SSLKEYLOGFILE=~/sslkeylog.log
#命令行启动,让firefox继承环境变量,也防止firefox后台运行,没有真正重启
/Applications/Firefox.app/Contents/MacOS/firefox-bin
-
配置wireshark
-
设置通讯密钥文件位置
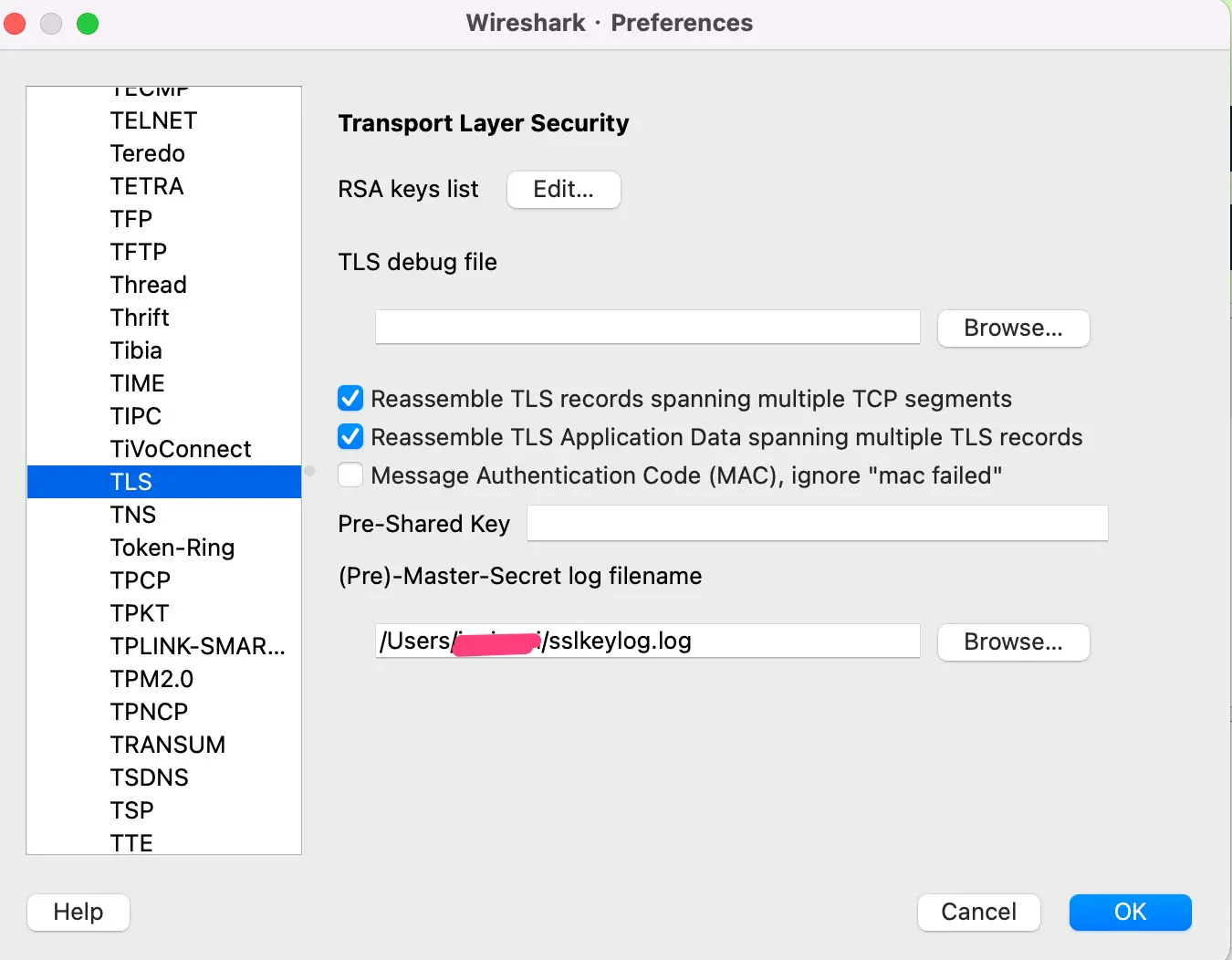
-
设置显示域名,默认显ip
-
-
firefox访问网址,wireshark抓包
显示过滤语法

# 获取指定port包
tcp.port == 8411
tcp.port in {80, 443, 8080}
# 指定ip源或目的
ip.src == 192.168.0.1
ip.dst == 192.168.0.1
# 按长度
http.content_length <=20
udp.length < 30
# 按协议
http
http contains "https://www.wireshark.org"
http.request.method == "POST"
http.request.method in {"HEAD", "GET"}
# 条件组合 and or
ip.src == 192.168.0.1 or ip.dst == 192.168.0.1
ip.dst eq www.mit.edu
capture过滤语法
- 表达式规则
[not] primitive [and|or [not] primitive ...]
-
primitive有几种形式
- [src|dst] host
- ether [src|dst] host
- gateway host
- [src|dst] net
[{mask }|{len }] - [tcp|udp] [src|dst] port
- less|greater
- ip|ether proto
relop
- [src|dst] host
-
示例
tcp port 23 and not src host 10.0.0.5
小知识
- 局域网抓包可采用路由器镜像端口
- 远程服务器抓包,远程抓包+rpcap,本机wireshark连接远程rpcap,则远程数据包转发到本机
- wireshark支持lua扩展解释自定义协议
windows
-
win10运行linux命令
- 系统设置——更新和安全——针对开发人员——选择开发者模式
- 搜索“程序和功能”,选择“开启或关闭Windows功能”,开启Windows Subsystem for Linux (Beta),并重启系统
- 下载安装linux
-
配置windows Terminal
-
小知识
- power shell
# 十六进制显示文件 Format-Hex -Path ./fileName.xxx # 文件浏览器打开当前目录 explorer .
elastic
官网
docker run --name ms1.0 --restart always -p 9080:7700 -v $(pwd)/meili_data:/meili_data -d getmeili/meilisearch:v1.0
安装
-
elasticsearch,基于Lucene(TM)的开源搜索引擎
brew tap elastic/tap brew install elastic/tap/elasticsearch-full brew services start elasticsearch-full curl -X GET http://localhost:9200/ # 查看安装的插件 curl -X GET http://localhost:9200/_cat/pluginsdocker pull docker.elastic.co/elasticsearch/elasticsearch:8.1.3 docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:8.1.3-
名词概念对比 | 关系数据库 | elasticsearch | | – | – | | 库 | 索引 | | 表 | 类型 | | 表模式 | 映射 | | 行 | 文档 | | 字段 | 字段 |
- 支持类型|字段类型|说明| |––|–| |string|字符串| |byte, short, integer, long|数字| |float, double|浮点| |boolean|布尔| |date|日期|
-
采用倒序存储,关键字 –》[文档1, 文档2, 文档3 ….],所以能快速搜索
-
插入的数据自动地创建类型(type)及其映射(mapping)
-
没有事务一致性,采用乐观版本,文档每更新一次,文档元数据中版本号就增加
-
传统数据库更关注数据一致性,永久存储等,在于操作数据,es则偏重于快速搜索
-
通常用数据库数据初始化es索引
-
索引别名理解及应用
-
默认端口9200
-
查询语法
- Leaf query clauses
-
match,全文搜索,支持text, number, date or boolean
GET /_search { "query": { "match": { "message": "this is a test" } } } -
term,精确相等,不要查询text字段
GET /_search { "query": { "term": { "user.id": { "value": "kimchy", "boost": 1.0 } } } } -
range
-
- Leaf query clauses
-
-
浏览器插件
- es-client-elasticsearch客户端
- Elasticvue-elasticsearch客户端
-
kibana
# 注意和elasticsearch版本配对,否则跑不起来 curl -O https://artifacts.elastic.co/downloads/kibana/kibana-7.17.2-darwin-x86_64.tar.gz curl https://artifacts.elastic.co/downloads/kibana/kibana-7.17.2-darwin-x86_64.tar.gz.sha512 | shasum -a 512 -c - tar -xzf kibana-7.17.2-darwin-x86_64.tar.gz cd kibana-7.17.2-darwin-x86_64/ ./bin/kibana # 浏览器访问 http://localhost:5601/
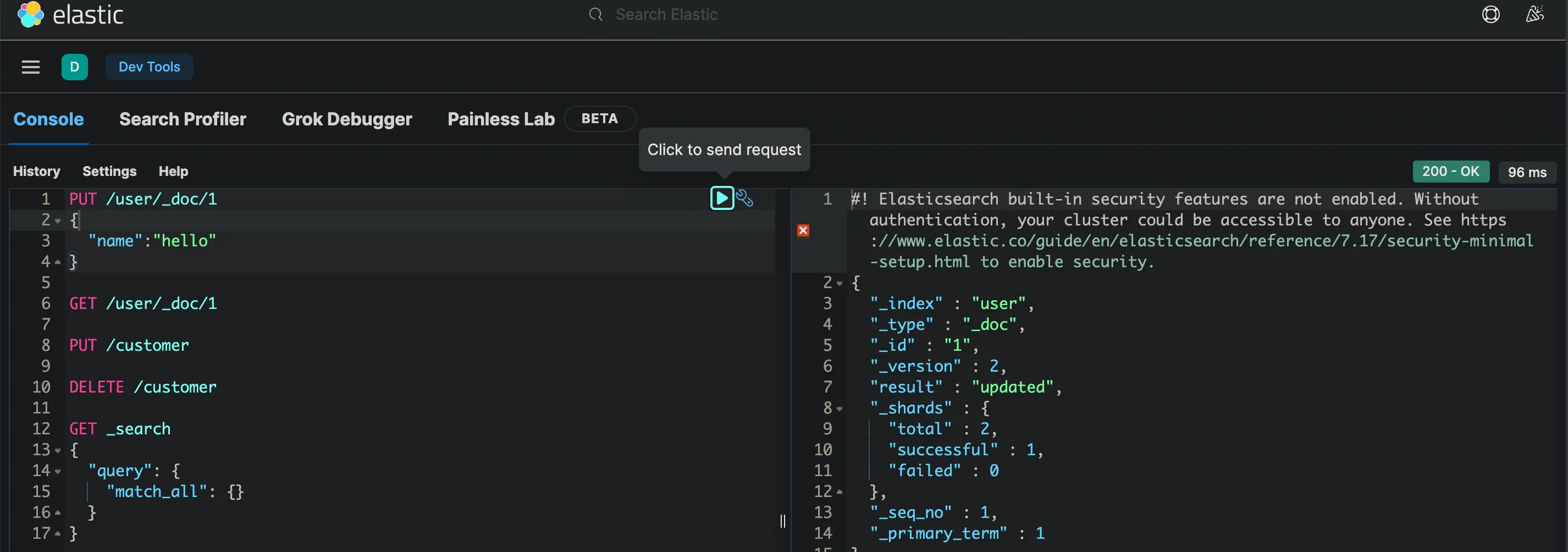
-
如果报内存不够,则删除monitoring索引
makefile
常见编译变量参数
SHELL := /usr/bin/env bash -o pipefail
GIT_VERSION ?= $(shell git describe --always --tags --match 'v*' --dirty)
COMMIT ?= $(shell git rev-parse HEAD)
BRANCH ?= $(shell git rev-parse --abbrev-ref HEAD)
BUILD_DATE ?= $(shell date +%s)
BUILD_HOST ?= $(shell hostname)
BUILD_USER ?= $(shell id -un)
变量不同赋值区别
= 是最基本的赋值
:= 是覆盖之前的值
?= 是如果没有被赋值过就赋予等号后面的值
+= 是添加等号后面的值
生成makefile的cmakelist介绍
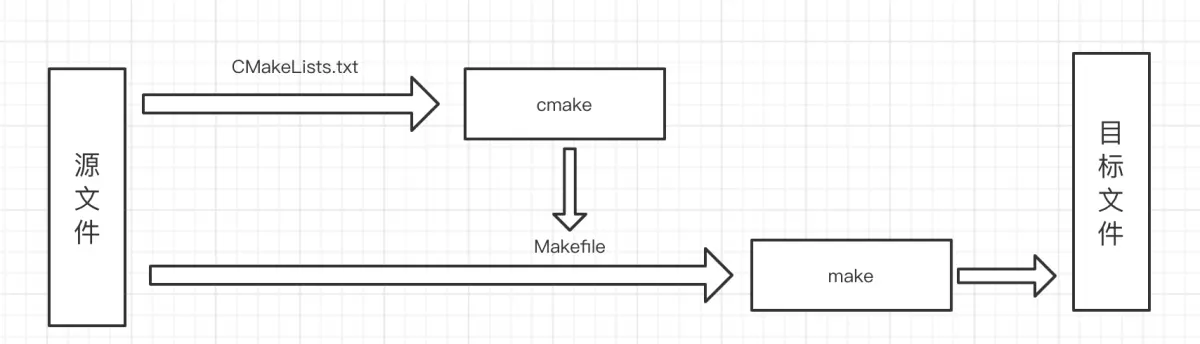
makelist介绍

jenkins
动作
- 重启-直接在地址后面加个 /restart
https://jenkins.xxx/restart
- 退出-直接在地址后面加个/exit
https://jenkins.xxx/exit
- 出现错误
# 一般是私钥的-----BEGIN OPENSSH PRIVATE KEY-----没有复制全
stderr: Load key "/tmp/jenkins-gitclient-ssh7026290831916999837.key": invalid format
-
复制到远程主机
- 安装publish-over-ssh插件
Jenkins 是一个开源的持续集成和持续交付(CI/CD)工具,广泛用于自动化软件构建、测试和部署。以下是 Jenkins 的核心概念及其详细解释,帮助你理解它的工作原理和核心功能:
1. Pipeline(流水线)
-
定义:Pipeline 是 Jenkins 的核心概念,用于定义自动化流程(如构建、测试、部署),通过代码(Jenkinsfile)描述整个过程。
-
特点:
- 使用 Declarative Pipeline(声明式语法)或 Scripted Pipeline(脚本式语法)编写。
- 支持多阶段(
stages)、并行任务、错误处理等复杂逻辑。
-
示例:
pipeline { agent any stages { stage('Build') { steps { sh 'mvn clean package' } } stage('Test') { steps { sh 'mvn test' } } } }
2. 节点(Node)与代理(Agent)
- 节点(Node):指 Jenkins 环境中的物理或虚拟机器(如服务器、Docker 容器)。
- 代理(Agent):在节点上运行的程序,负责执行具体的任务(如构建)。
- 主节点(Master):Jenkins 控制中心,管理任务调度、界面展示等,不推荐直接执行任务。
- 工作节点(Slave/Agent):实际执行任务的节点,支持分布式构建。
3. Job/Project(任务/项目)
- 定义:Job 是 Jenkins 中一个可配置的自动化任务单元,代表一个具体的构建流程。
- 类型:
- Freestyle Project:通过界面配置的简单任务。
- Pipeline Job:基于 Jenkinsfile 的复杂流水线任务。
- Multi-configuration Project:支持多环境(如不同操作系统、浏览器)并行测试。
4. Build(构建)
- 定义:Job 的一次具体执行,生成日志、测试报告、构建产物(Artifacts)等。
- 构建历史:保留每次构建的结果(成功/失败)、日志和产出,便于调试和分析。
5. Executor(执行器)
- 定义:节点上的执行线程,决定同时运行的构建数量。例如,一个节点有 2 个 Executor 可并行执行 2 个任务。
6. 插件(Plugin)
- 作用:扩展 Jenkins 功能(如集成 Git、Docker、Kubernetes、消息通知等)。
- 常见插件:
- Git Plugin:从 Git 仓库拉取代码。
- Docker Pipeline:集成 Docker 容器。
- Email Extension:发送构建通知邮件。
7. Workspace(工作区)
- 定义:节点上为 Job 分配的专属目录,存放源代码、构建产物和临时文件。
- 清理:每次构建前可配置清理工作区,避免旧文件干扰。
8. Trigger(触发器)
- 定义:触发构建的条件,常见类型:
- SCM 变更(如 Git 提交)。
- 定时触发(如
H/15 * * * *每 15 分钟)。 - 手动触发(用户点击构建按钮)。
- 上游任务触发(其他 Job 完成后触发)。
9. Credential(凭证)
- 作用:安全存储敏感信息(如 Git 密码、SSH 密钥、API Token)。
- 类型:支持用户名密码、密钥文件、Secret Text 等。
10. Distributed Build(分布式构建)
- 场景:将任务分发到多个节点执行,加速构建或适配不同环境(如跨平台测试)。
- 配置:通过 Jenkins 管理界面添加工作节点并分配标签(Label)。
11. Shared Library(共享库)
- 定义:将通用的 Pipeline 代码封装为库,供多个项目复用。
- 存储:通常托管在 Git 仓库中,通过 Jenkins 全局配置引入。
12. Blue Ocean
- 定义:Jenkins 的现代化 UI,提供可视化流水线编辑和构建状态展示。
- 功能:直观的 Pipeline 设计器、实时日志、分支和拉取请求集成。
13. 安全性
- 认证(Authentication):用户登录验证(如 LDAP、GitHub OAuth)。
- 授权(Authorization):权限控制(如基于角色的权限管理插件 Role-Based Strategy)。
14. 其他关键概念
- File Fingerprinting(文件指纹):跟踪文件版本,用于依赖管理。
- Artifact(构建产物):构建生成的二进制文件、报告等,可存档或分发。
- Environment Variables(环境变量):全局或 Job 级别的变量(如
BUILD_NUMBER)。 - Parameterized Build(参数化构建):允许用户输入参数(如版本号、环境类型)后再执行构建。
应用场景示例
- 自动化测试:每次代码提交后自动运行单元测试和集成测试。
- 持续交付:构建成功后自动部署到测试环境,手动审批后发布到生产环境。
- 多环境部署:通过分布式构建在不同节点上部署到不同云平台(如 AWS、Azure)。
总结
Jenkins 的核心在于通过 Pipeline 即代码 和 插件扩展 实现高度灵活和可定制的自动化流程。掌握这些概念后,可以结合具体需求设计高效的 CI/CD 流水线,提升软件交付速度和质量。如需深入学习,建议从官方文档和实际项目实践入手。
vim
常用命令
- ddp-交换上下行-光标在上行,其与下行交换
- :$ 跳转到最后一行
- :1 跳转到第一行
查找字符串
- /hello 查找光标处下一个“hellp“ ,键入“n“ 继续查找下一个,键入“shift+n“(大写N), 向上查找
- ?hello朝找光标处上一个“hellp“ 键入“n“ 继续查找上一个, 键入“shift+n“(大写N), 向下查找
- /<printf> 精确搜索printf:“<“表示匹配单词开头,”>“表示匹配单词末尾,需要加转义符”“
复制粘贴
- 复制一行,我们只要把光标移动到想复制的那一行,按yy,就是两次y键,
- 粘贴,把光标移动到你想粘贴的那一行,按p键即可。
- 复制多行,把光标移动到想复制多行的开头,想要向下复制几行,就按nyy,比如我想从这一行开始复制5行,就按5yy
插件管理器-vim-plug
-
vim-plug 是 vim 下的插件管理器, 可以帮我们统一管理后续的所有插件, 后续的安装插件全部由此工具完成 类似的插件管理工具还有 Vundle, 相较而言 vim-plug 支持异步且效率非常高, 具体选择交由读者自己
-
安装
curl -fLo ~/.vim/autoload/plug.vim --create-dirs \
https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim
- 配置声明
vim .vimrc
:set term=builtin_ansi
:set encoding=utf-8
:set nocompatible
:set nu
:set hlsearch
:syn on
call plug#begin()
Plug 'preservim/nerdtree'
Plug 'jiangmiao/auto-pairs'
Plug 'vim-airline/vim-airline'
Plug 'vim-airline/vim-airline-themes'
Plug 'morhetz/gruvbox'
Plug 'frazrepo/vim-rainbow'
Plug 'chiel92/vim-autoformat'
Plug 'vim-scripts/bash-support.vim'
Plug 'zaach/jsonlint'
Plug 'plasticboy/vim-markdown'
Plug 'ambv/black'
Plug 'fatih/vim-go'
Plug 'sheerun/vim-polyglot'
Plug 'ekalinin/Dockerfile.vim'
call plug#end()
- 激活安装-相应插件
$ vim #打开vim
:PlugStatus #查看插件状态
:PlugInstall #安装之前在配置文件中声明的插件
机器上/.vimrc 修改无法显示中文及方向键不能移动光标
:set term=builtin_ansi
:set encoding=utf-8
:set nocompatible
修改~/.bashrc 打开force_color_prompt=yes
- 右键不能复制
vim set mouse-=a屏蔽了鼠标右健功能.
github
重要提示
国内境像
- https://hub.njuu.cf/
- https://hub.yzuu.cf/
- https://hub.nuaa.cf/
- https://kgithub.com/
- https://gitclone.com/
解决访问超慢
-
修改/etc/hosts
140.82.113.21 collector.Github.com 140.82.113.5 api.github.com 140.82.114.4 github.com 140.82.113.4 github.com 185.199.108.154 github.githubassets.com 185.199.109.154 github.githubassets.com 185.199.110.154 github.githubassets.com 185.199.111.154 github.githubassets.com 185.199.110.153 assets-cdn.github.com 185.199.111.153 assets-cdn.github.com 185.199.108.153 assets-cdn.github.com 199.232.69.194 github.global.ssl.fastly.net -
原因是国内dns解析相应域名都是到新加坡,有时候访问不了
-
FastGithubgithub加速神器

-
osx-arm64版本会直接被杀死,改用osx-x86
[1] 9226 killed ./fastgithub # 丢掉烦人的输出,并且后台运行 ./fastgithub > /dev/null & godoc -http=:6060 & -
最新版firefox替换证书, 证书-查看证书-颁发机构-导入cer证书,否则报错
-
设置系统自动代理为
http://127.0.0.1:38457,或手动代理http/https为127.0.0.1:38457
pages服务
-
User/Organization Pages 个人或公司站点
- 创建username.github.io仓库
- 仓库设置自定义域名,项目下面会自动增加CNAME文件
- 域名解析增加相应的CNAME记录
-
Project Pages 项目站点
- gh-pages分支用于构建和发布;
- 如果user/org pages使用了独立域名,那么托管在账户下的所有project pages将使用相同的域名进行重定向,除非project pages使用了自己的独立域名; 如果没有使用独立域名,project pages将通过子路径的形式提供服务http://username.github.com/projectname;
自定义github主页
-
新建一个同名仓库
官方提示:…. is a special repository. Its README.md will appear on your public profile!
-
编辑该仓库的 README.md 文件
官方工具
名词
-
Sponsor:打赏
-
Watch:如有更新,通知提醒。
-
Fork:分支一份到你的仓库。
-
Code:默认页面,通常会有一个 README.md 文件,用于介绍该项目。
-
Pull requests:请求代码合并,如果你想为项目贡献代码,可以在这里提交。
-
Actions:工作流。
大家知道,持续集成由很多操作组成,比如抓取代码、运行测试、登录远程服务器,发布到第三方服务等等。GitHub 把这些操作就称为 actions。 很多操作在不同项目里面是类似的,完全可以共享。GitHub 注意到了这一点,想出了一个很妙的点子,允许开发者把每个操作写成独立的脚本文件,存放到代码仓库,使得其他开发者可以引用。 如果你需要某个 action,不必自己写复杂的脚本,直接引用他人写好的 action 即可,整个持续集成过程,就变成了一个 actions 的组合。这就是 GitHub Actions 最特别的地方。 GitHub 会监控到,然后分配一台虚拟机先将你的项目 checkout 过去,然后按照你指定的 step 顺序执行定义好的 action
-
Projects:项目管理
-
Security:安全评估
-
Wiki:说明文档
-
Insights:数据统计
-
codespaces 类似web IDE,省去环境配置环节,云端开发
-
高级搜索 例如包括nginx的pdf书 nginx extension:pdf
配套网站-Netlify
- 用最快的方法构建最快的网站
当使用 Github 将网站项目文件夹里的所有东西上传完毕之后,那么就可以打开 Netlify 给予它访问 Github 仓库的权限。 当 Netlify 读取完你的网站所属仓库时,会自动识别你所用的静态网页生成器的程序,然后只要点击部署并发布,你的网站就会在 Netlify 被构建并且被发布.
-
能够托管服务,免费 CDN
-
能够绑定自定义域名
-
能够启用免费的TLS证书,启用HTTPS
-
支持自动构建
-
提供 Webhooks 和 API
多个帐号,多个ssh
# ~/.ssh/config配置
Host github3
HostName github.com
PreferredAuthentications publickey
IdentityFile ~/.ssh/id_rsa
Host github2
HostName github.com
PreferredAuthentications publickey
IdentityFile ~/.ssh/id_ecdsa
# 修改远程地址
# git@github.com:xxx/yyy -> git@github3:xxx/yyy
# git@github.com:xxx/yyy -> git@github2:xxx/yyy
git项目在github打不开的时候,采用gitee映像解决
- https://gitee.com/organizations/mirrors/projects
- 搜索开源项目
- 修改远程地址, 一般情况下都有的.如果没有,可以自已创建项目同步克隆github代码
优秀的github项目
- https://www.github-zh.com/
- https://github.com/GrowingGit/GitHub-Chinese-Top-Charts
- https://github.com/ruanyf/weekly
- https://github.com/EbookFoundation/free-programming-books
- https://github.com/521xueweihan/HelloGitHub/
- https://github.com/ljinkai/weekly
firefox
-
扩展组件
- 实际上zip压缩后,直接改后缀名xpi
- 注意不能直接压缩整个目录,应该是选择文件压缩,否则认为损坏.估计压缩比解压多一级目录.
- 现代firefox一般要求认证,扩展组件开发者,否则不能安装与运行
-
“此附件组件无法安装,未通过验证”
- 打开Firefox浏览器
- 地址栏输入“about:config”
- 搜索“xpinstall.signatures.required”设置项,双击改为“false”,重启
- 再把xpi拖进Firefox窗口便会提示是否安装
-
优秀插件
- Dark Reader-推荐使用,把网站改成暗黑主题,少数网站表现不好
- uBlock Origin-推荐使用去广告
- sourcegraph-推荐使用浏览器享受ide级别待遇
- savetopdf-自动把网页转化为pdf
- es-client-elasticsearch客户端
- Elasticvue-elasticsearch客户端
- autocopy-自动复制选中内容
- 探索者小舒–一键切换多个搜索引擎
- Vue.js devtools-vue.js开发助手
- jsonview-在浏览器中查看JSON 文件
- Postwoman中文版-优秀Api测试插件
- monknow新标签页,美观且允许高度自定义的新标签页扩展插件
- chrome://flags/#enable-force-dark 自带暗黑模式
-
开发者模式-禁止网页跳转自动清除日志
- 禁止页面跳过自动清除log


- 禁止页面跳过自动清除log
-
lighthouse-chrome出品网站优化建议报告,dev-tools自带,方便又快捷
-
firefox开发者专用版,获取最新的开发者工具,帮助调试很多问题
-
- MDN-Mozilla开发者社区(MDN)是一个完整的学习平台
- 临时加载的脚本扩展,必须用cmd+shift+j调出浏览器控制台,设置“显示消息内容“,才能看到日志,
- PWA(Progressive Web App)-渐进式Web应用,利用缓存+在线网站构建本地应用
-
WebDriver是远程控制接口,可以对用户代理进行控制。它提供了一个平台和语言中性线协议,作为进程外程序远程指导web浏览器行为的方法.
-
有空实现插件
- 浏览器扩展 类似go search,python search
- 浏览器扩展 把github有关hg项目生成pdf
- dial,类似monknow
- 批量html转化成pdf


flutter
中文官网
常用命令
# 检查环境
flutter doctor
# 创建新工程
flutter create xxx
# 调试运行
flutter run
# 生成apk,默认release,上线应用市场需要签名,个人使用可以直接生成
flutter build apk
# 插上数据线,连上手机,手机打开调试选项,直接安装
flutter install
# 生成不同的ios应用,默认生成apple store,否则就指定用途
# 没有订阅会费,无法生成上架及ad-hoc,只能生成 development
flutter build ipa --export-method ad-hoc、--export-method development 和 --export-method enterprise。
flutter build ipa --export-method development
# 应用程序支持的最低 macOS 版本。Flutter 支持 macOS 10.11 及更高版本。Deployment Target(部署目标)需要注意.
flutter build macos
# 出现类似下面提示,可能是xcode版本或m1芯片造成,仍然可以正常打包
# --- xcodebuild: WARNING: Using the first of multiple matching destinations:
# { platform:macOS, arch:arm64, id:xxxxx }
# { platform:macOS, arch:x86_64, id:xxxx }
# cd project/build/web
# python3 -m http.server 8000
flutter build web
# linux仅限linux主机支持
flutter build linux
# windows仅限windows主机支持
flutter build windows
中国特定的环境变量,否则doctor失败
vim .zshrc
vim .bashrc
export CHROME_EXECUTABLE=/Applications/Chromium.app/Contents/MacOS/Chromium
export PUB_HOSTED_URL=https://pub.flutter-io.cn
export FLUTTER_STORAGE_BASE_URL=https://storage.flutter-io.cn
本地跑起flutter官网
cd git-code/github/flutter-website
# make up,如果不能,就先启动docker
./local.sh
知名扩展库
Bundle和apk区别
Bundle是google推出一种文件格式,帮助下载时动态产生apk,以节省不必要的浪费.Google Play就是基于对aab文件处理,将App Bundle在多个维度进行拆分,在资源维度,ABI维度和Language维度进行了拆分,你只要按需组装你的Apk然后安装即可。如果你的手机是一个x86,xhdpi的手机,你在google play应用市场下载apk时,gogle play会获取手机的信息,然后根据App Bundle会帮你拼装好一个apk,这个apk的资源只有xhdpi的,而且so库只有x86,其他无关的都会剔除。从而减少了apk的大小。
xcode无线调试真机(同局域内)
-
手机采用数据线连接上Xcode,打开Xcode菜单:Windows->Device and Simulators。找到连接上的设备,把Connect via network选项打勾.
-
之后Xcode将会转一会圈圈,耐心等待一会就成功了,此时拔掉数据线,可以看到左侧的设备连接列表上手机仍在列表中
-
运行我们的项目,在设备列表中不出意外会看到我们的无线连接的手机。选择手机后运行
-
不出意外的话,此时是跑不起来的。还需要最后一步,回到刚刚的设备列表中,选中手机右键,在出来的选项卡中选择一个Connect via IP Address项。选择之后输入手机的局域网ip地址。
-
完成后可以看到在连接的手机右边有一个地球连接标志.
-
以后项目运行,在下拉列表如果手机在局域网中也会有这个标志
-
最后一步,选择后直接运行,不出意外的话,项目无需数据线就跑起来了
-
此方法是支持无线调试的,连一次以后就不需要数据线了了
苹果帐户添加设备uuid
-
打开https://developer.apple.com/ 登录你的苹果开发者账号,交过钱才能看到界面
-
登进去之后点击Certificates, Identifiers & Profiles
-
左侧点击Devices,可以看到现在账号里面注册的设备,再点击+号新增设备
-
填写设备的名字(这个自己随便写就好了,方便你知道是谁的什么设备就行)还有设备的UDID,完成后点击Continue
-
然后会让你再次确认信息,看你填写是否正确,下面显示的是该账号最多可以添加的测试设备数目和剩余可添加设备的数目。信息无误,点击Register下一步。再点击done完成注册,跳转回Devices页面,就可以看到我们新添加的设备了。如果是做app开发,需要重新打包之后,新设备才能进行测试
-
平时打adhoc,不用打store包
-
iphone6 plus的uuid 0da336454935d7d38373cbd54a403cad888ba845
xcode查看uuid
-
iphone数据线连接MAC
-
打开Xcode
-
点击Window––>Devices and Simulators—>在右侧可查看到identifier
-
identifier即为我们获取到的iPhone 的UDID
总结
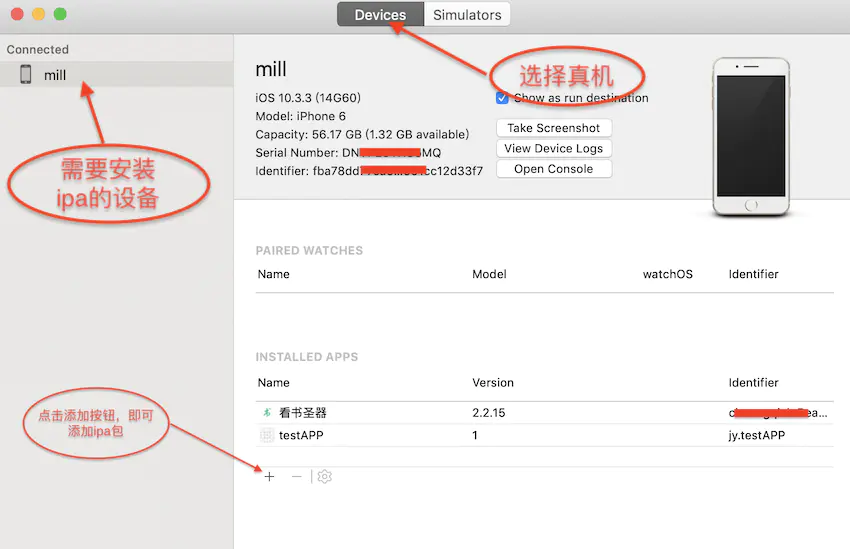
Flutter 是一个强大的 UI 框架,提供了丰富的 Widget 来构建应用程序。以下是 Flutter 的基础、重点和常用 Widget 的分类和说明,以及它们之间的关系图。
Flutter Widget 分类
1. 基础 Widget
这些是 Flutter 中最基本的 Widget,用于构建 UI 的骨架。
Text:显示文本。Image:显示图片。Icon:显示图标。Container:用于布局和装饰的通用容器。Row和Column:用于水平(Row)和垂直(Column)排列子 Widget。Stack:用于将子 Widget 堆叠在一起。Padding:为子 Widget 添加内边距。Center:将子 Widget 居中显示。
2. 布局 Widget
用于控制 Widget 的排列和布局。
ListView:可滚动的列表。GridView:网格布局。Expanded和Flexible:在 Row 或 Column 中分配空间。SizedBox:固定大小的盒子。AspectRatio:按比例调整子 Widget 的大小。ConstrainedBox:对子 Widget 施加约束。Align:对齐子 Widget。
3. 交互 Widget
用于处理用户输入和交互。
GestureDetector:检测手势(如点击、拖动等)。InkWell:带水波纹效果的点击区域。TextField:文本输入框。Button(如ElevatedButton、TextButton、OutlinedButton):按钮。Checkbox和Radio:复选框和单选按钮。Slider:滑动条。Switch:开关。
4. 样式和装饰 Widget
用于美化 UI。
DecoratedBox:为子 Widget 添加装饰(如背景、边框)。BoxDecoration:定义装饰样式(颜色、边框、阴影等)。Theme:应用主题样式。TextStyle:定义文本样式。ClipRRect:裁剪 Widget 为圆角矩形。
5. 状态管理 Widget
用于管理 Widget 的状态。
StatefulWidget:有状态的 Widget。StatelessWidget:无状态的 Widget。InheritedWidget:在 Widget 树中共享数据。Provider(第三方库):状态管理的推荐方式。
6. 动画 Widget
用于实现动画效果。
AnimatedContainer:带动画效果的 Container。AnimatedOpacity:带动画效果的透明度。Hero:实现页面切换时的共享元素动画。TweenAnimationBuilder:自定义动画。
7. 导航和路由 Widget
用于页面导航。
Navigator:管理页面堆栈。MaterialPageRoute:Material 风格的页面路由。BottomNavigationBar:底部导航栏。TabBar和TabView:标签页导航。
8. 平台相关 Widget
用于适配不同平台(iOS 和 Android)。
CupertinoApp:iOS 风格的应用程序。CupertinoButton:iOS 风格的按钮。CupertinoNavigationBar:iOS 风格的导航栏。
Flutter Widget 关系图
以下是 Flutter 常用 Widget 的关系图(简化版):
Widget
├── StatelessWidget
│ ├── Text
│ ├── Image
│ ├── Icon
│ ├── Container
│ ├── Row
│ ├── Column
│ ├── Stack
│ └── Padding
│
├── StatefulWidget
│ ├── Checkbox
│ ├── Radio
│ ├── Slider
│ ├── Switch
│ └── TextField
│
├── Layout Widgets
│ ├── ListView
│ ├── GridView
│ ├── Expanded
│ ├── SizedBox
│ └── Align
│
├── Interaction Widgets
│ ├── GestureDetector
│ ├── InkWell
│ ├── ElevatedButton
│ ├── TextButton
│ └── OutlinedButton
│
├── Styling Widgets
│ ├── DecoratedBox
│ ├── BoxDecoration
│ ├── Theme
│ └── ClipRRect
│
├── Animation Widgets
│ ├── AnimatedContainer
│ ├── AnimatedOpacity
│ ├── Hero
│ └── TweenAnimationBuilder
│
├── Navigation Widgets
│ ├── Navigator
│ ├── MaterialPageRoute
│ ├── BottomNavigationBar
│ └── TabBar
│
└── Platform Widgets
├── CupertinoApp
├── CupertinoButton
└── CupertinoNavigationBar
重点 Widget
StatelessWidget和StatefulWidget:所有 Widget 的基础。Container:最常用的布局和装饰 Widget。Row和Column:用于构建复杂的布局。ListView和GridView:用于显示大量数据。Navigator:用于页面导航。Provider:状态管理的推荐方式。
总结
-
Flutter 的 Widget 分为基础、布局、交互、样式、状态管理、动画、导航和平台相关等类别。
-
掌握这些 Widget 的使用方法是 Flutter 开发的基础。
-
通过组合这些 Widget,可以构建出复杂的 UI 界面。
tesseract
安装
# 多半已安装过了,最新版本为5.xx
brew install tesseract
# This formula contains only the "eng", "osd", and "snum" language data files.
# If you need any other supported languages, run `brew install tesseract-lang`
# 本质是下载github所有训练完好的模型数据,放在/opt/homebrew/share/tessdata,供tesseract调用
brew install tesseract-lang
使用
# 获取帮助
tesseract --help-extra
# 告诉tesseract 源文件chinese.png -l 表示中文 stdout输出到标准库
tesseract chinese.png stdout -l chi_sim
# 类似数字识别
tesseract digit.png stdout -l snum
# 类似英文识别
tesseract english.png stdout -l eng
# 单行文本识别率非常不错,多行错误率非常高
harbor
简介
-
Harbor是VMware公司开源的企业级Docker Registry项目,其目标是帮助用户迅速搭建一个企业级的Docker Registry服务
-
Harbor以 Docker 公司开源的Registry 为基础,提供了图形管理UI、基于角色的访问控制(Role Based AccessControl)、AD/LDAP集成、以及审计日志(Auditlogging)等企业用户需求的功能,同时还原生支持中文
-
Harbor的每个组件都是以Docker 容器的形式构建的,使用docker-compose 来对它进行部署。用于部署Harbor 的docker- compose模板位于harbor/ docker- compose.yml
-
linux至少4核/8G
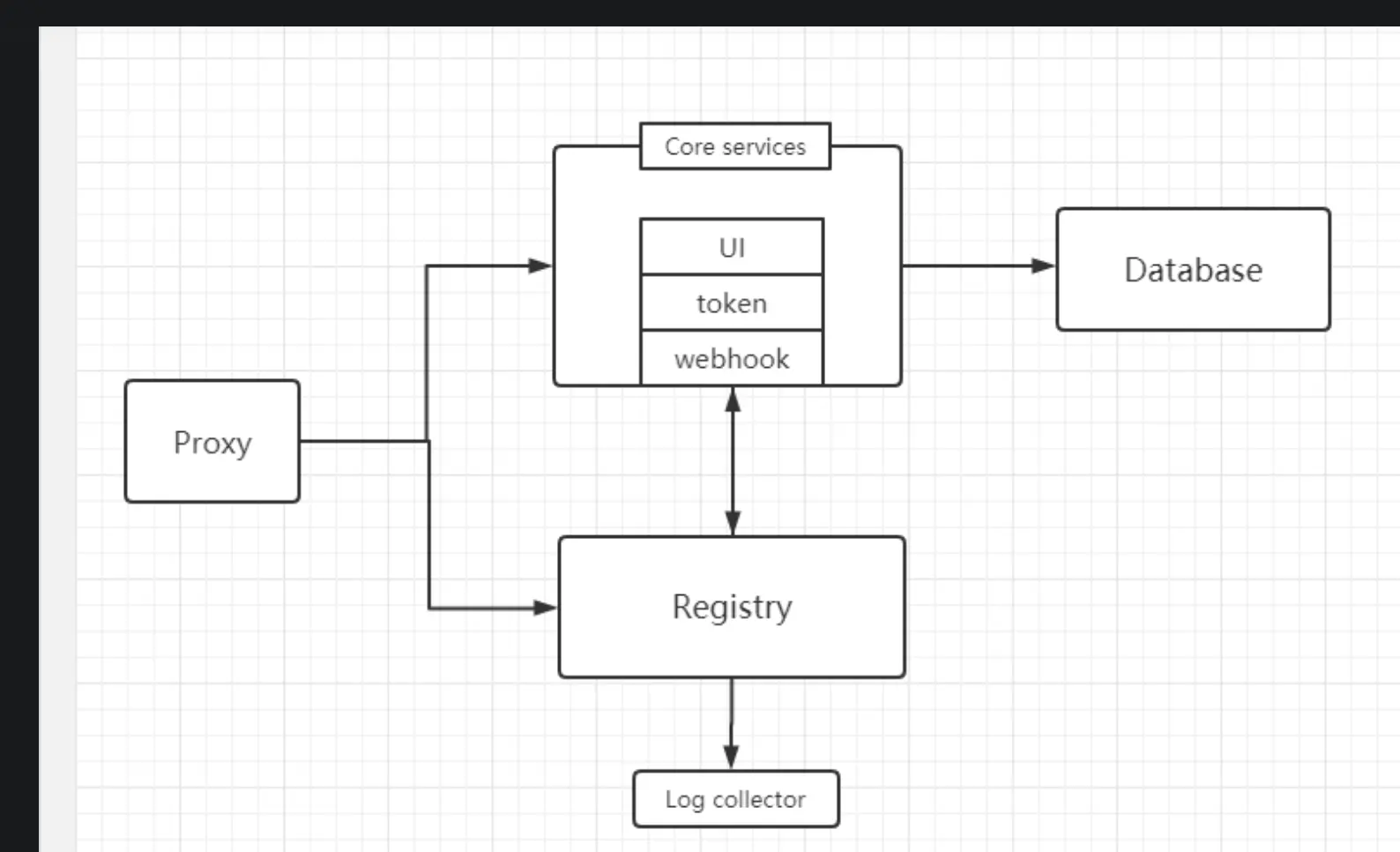
# 下载离线安装包
~/Downloads/harbor-offline-installer-v1.10.11.tgz
最好在linux机器上
# mac机器出现
ERROR: for portal Cannot start service portal: failed to initialize logging driver: dial tcp 127.0.0.1:1514: connect: connection refused
ERROR: Encountered errors while bringing up the project.
docker-compose脚本转发命令
- docker compose自带,不必另外按装.
- harbor需要启动docker-compose相关依赖,所以需要一个转发
vim docker-compose
#!/bin/bash
docker compose $*
修改common.sh
# 注释掉dockercompose检查
function check_dockercompose {
return
....
}
修改配置
# The IP address or hostname to access admin UI and registry service.
# DO NOT use localhost or 127.0.0.1, because Harbor needs to be accessed by external clients.
hostname: 修改自定义ip或域名
# 根据自已需求来配置http/https
# http related config
http:
# port for http, default is 80. If https enabled, this port will redirect to https port
port: 80
# https related config
#https:
# https port for harbor, default is 443
# port: 443
# The path of cert and key files for nginx
# certificate: /your/certificate/path
# private_key: /your/private/key/path
[免费制品管理-nexus]https://www.sonatype.com/products/repository-oss-download
gitlab
安装私有部署(内存最低2GB,机器配置越高越好,否则会有各种问题)
# 下载安装docker
curl -fsSL <https://get.docker.com> | bash -s docker --mirror Aliyun
# 启动docker
systemctl start docker
# 创建gitlab home
mkdir /srv/gitlab
# 导出环境变量 vim .bash_profile
export GITLAB_HOME=/srv/gitlab
# docker跑起来,采用社区版,自带常见服务足够了
docker run --detach \
--hostname gitlab.example.com \
--publish 443:443 --publish 80:80 --publish 8090:22 \
--name gitlab \
--restart always \
--volume $GITLAB_HOME/config:/etc/gitlab \
--volume $GITLAB_HOME/logs:/var/log/gitlab \
--volume $GITLAB_HOME/data:/var/opt/gitlab \
--shm-size 256m \
registry.gitlab.cn/omnibus/gitlab-jh:latest
# 初始化过程可能需要很长时间。 您可以通过以下方式跟踪此过程,查看日志
docker logs -f gitlab
# 获取默认初始化密码,用户名是root
docker exec -it gitlab grep 'Password:' /etc/gitlab/initial_root_password
# 安装sourcegraph
docker run --detach \
--publish 8091:7080 \
--publish 127.0.0.1:3370:3370 \
--rm --volume ~/.sourcegraph/config:/etc/sourcegraph \
--volume ~/.sourcegraph/data:/var/opt/sourcegraph sourcegraph/server:3.40.0
hugo
简介
- Hugo是由Go语言实现的静态网站生成器 官网
- 用户编辑内容文件,主题插件提供显示方式,hugo利用两者生成纯静态网站
- Hugo靠shortcode扩展
- 用最新的mermaid.js替换Hugo-theme-learn主题自带的mermaid.js,可获取最新mermaid功能
- config.toml中“home = [“HTML”, “RSS”, “JSON”]“,会产生index.json索引,不要删除
本地运行官网
git clone https://github.com/gohugoio/hugoDocs.git
cd hugoDocs
hugo -D server
出现类似下面报错,hugoDocs中的config.toml增加timeout = 100000000000,单位ms
timeout默认值过短,原因为hugo生成网站时间超出默认配置
Error building site: ".../hugoDocs/content/en/troubleshooting/faq.md:1:1": timed out initializing value. You may have a circular loop in a shortcode, or your site may have resources that take longer to build than the `timeout` limit in your Hugo config file.
优秀的主题网站(https://wowchemy.com/)
替代品-jekyll
-
中文官网(http://jekyllcn.com/)
-
mac自带的ruby,gem安装权限问题-示例本地运行fyne官网
ERROR: While executing gem ... (Gem::FilePermissionError)
You don't have write permissions for the /usr/bin directory.
-
sudo gem install fastlane,采用sudo
-
gem install fastlane –user-install, 采用用户级别安装
-
sudo gem install -n /usr/local/bin fastlane,同时指时路径
-
bundle exec jekyll serve-如果出错
-
常用参数
# -w 表示监控文件变化及时生成网站
# --incremental 增量构建
# 启动过程会有点慢,需要等待一会儿
jekyll serve -w --port=4001
- github项目中,如果只有__config.yml,没有Gemfile,则可能手动添加,方便本地跑起来
gem 'github-pages', group: :jekyll_plugins
Ruby Version Manager-RVM (https://rvm.io/)
curl -sSL https://get.rvm.io | bash -s stable
svn
svn命令
- 下载
svn checkout svn://host/svn/IOS/remote_dir (svn项目全路径)project_dir(本地目录全路径) --username 用户名 --password 密码
svn checkout 简写:svn co
- 添加新文件
svn add file(文件名)
svn add *.php(添加当前目录下所有的php文件)
- 提交到版本库
svn commit -m "LogMessage" PATH
svn commit -m “提交当前目录下的全部在版本控制下的文件“ * ( *表示全部文件 )
svn commit 简写:svn ci
- 更新文件
svn update
svn update 文件名
提交的时候提示过期冲突,需要先 update 修改文件
然后清除svn resolved,最后再提交commit。
svn update 间写: svn up
- 查看文件或者目录状态
svn status [-v] path(目录下的文件和子目录的状态,正常状态不显示)
?:不在svn的控制中;
M:内容被修改;
C:发生冲突;
A:预定加入到版本库;
K:被锁定
D:文件、目录或是符号链item预定从版本库中删除。
I:忽略
svn status 简写:svn st
- 查看日志(显示文件的所有修改记录,及其版本号的变化)
# 查看最近3条日志
svn log [path] -l 3
- 解决冲突
# 手工解决冲突后,移除工作副本的目录或文件的“冲突”状态,再提交
svn resolved PATH
- 删除文件
# 本地先删,再提交
svn delete test.php
svn ci -m 'delete test file‘
- 恢复本地修改
# 用法: revert PATH...
svn revert: 恢复原始未改变的工作副本文件 (恢复大部份的本地修改)。
注意: 本子命令不会存取网络,并且会解除冲突的状况。但是它不会恢复被删除的目录
# 丢弃对一个文件的修改
svn revert foo.c
# 恢复一整个目录的文件,. 为当前目录
svn revert --recursive .
- 版本库下的文件和目录列表
svn list [path]
- 忽略目录
# 注意没有目录斜杠
svn propset svn:ignore .idea .
- 查看文件详细信息
# svn info path
svn info test.php
- 比较差异
# svn diff path(将修改的文件与基础版本比较)
svn diff test.php
# svn diff -r m:n path(对版本m和版本n比较差异)
svn diff -r 200:201 test.php
svn diff 简写:svn di
- SVN 帮助
svn help 全部功能选项
svn help ci 具体功能的说明
- 上传
svn import project_dir(本地项目全路径) http://host/svn/IOS/Ben/remote_dir(svn项目全路径) -m "必填, 不填此命令执行不会成功."
服务器上remote_dir若不存在, 会自动创建;
只会上传project_dir目录下的文件到remote_dir的目录下
import之后, project_dir并没有自动转化为工作目录, 需要重新checkout(后面会用到)
杂项
STMP发邮件
sequenceDiagram
actor c as 邮件客户端
actor s as smtp服
actor o as 目标邮件服
actor u as 邮件接收者
c->>s: 登陆发邮件
s-->>c: 错误或者垃级邮件就退回
s->>o: 成功中转发邮件
o-->>s: 错误或者垃级邮件就退回
o->>u: 成功放入用户邮箱
NewSQL
flowchart LR
SQL(SQL例如MySQL) --> NoSQL(NoSQL例如MongoDB)
NoSQL --> newSQL(NewSQL例如CockroachDB,TiDB)
简述
- newSQL 就是在传统关系型数据库上集成了 noSQL 强大的可扩展性
- newSQL 生于云时代,天生就是分布式架构
- CockroachDB
- TiDB
好用的搜索
- whoogle-search-自建google元搜索
- searxng-另一个searx
- SEARX-开源元搜索
- 百度开发者-搜索
- 必应国际版-搜索
- goobe-程序员专用搜索
- mengso-搜索引擎,采用opensearch方式才能用
- yandex-搜索引擎,过滤得不够
- 专搜代码-source
- 专搜代码-search
- 专搜代码-publicwww
chromium安装darkreader
-
github下载

-
chromium安装

写好博客/wiki有用参考
- 官方文档/教程
- github优秀项目的readme
- 搜索 Stackoverflow 「关于某个 Wiki 话题」,前 10 ~ 20 个问题;
- 阅读 Google 搜索「关于某个 Wiki 话题」,前 10 ~ 100 篇文章;
- 社区优秀的免费和付费书籍(如果有的话);
- 优秀的出版书籍(如果有的话)
DBeaver 增加第三方mavn,加速驱动下载
- 窗口/首选项/DBeaver/驱动/maven/添加 http://maven.aliyun.com/nexus/content/groups/public/
华为手机自定义安装VLC
-
用数据线连接电脑和手机,手机开启HDB
-
下载VLC安装包

-
复制到手机
-
手机->实用工具->文件管理->浏览->下载与接收->下载管理器->点击apk
-
vlc的开源替代品iina
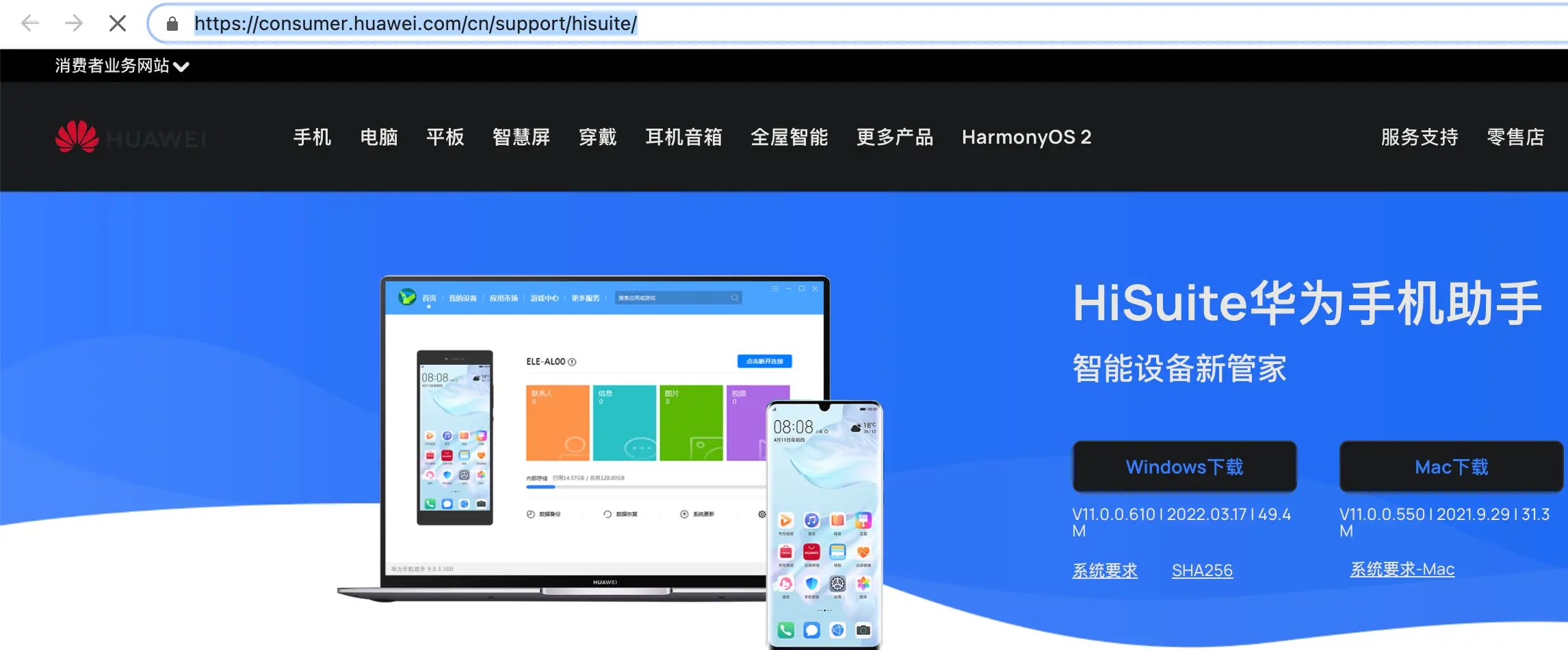
小度音箱播放本地音乐
-
进入小度APP之后,点击上方配置的小度智能音箱
-
点击进入设备设置。
-
点击进入蓝牙设置。
-
打开音箱蓝牙的开关。
-
再打开手机的蓝牙功能,找到音箱的蓝牙名称。
-
成功连接音箱蓝牙后,打开手机音乐即可在小度音箱中播放
优秀工具
- githubs中文社区
- wiki.js-优秀的wiki
- alist-各种网盘分享非常优秀,值得试试
- 腾讯兔小巢快速建立用户反馈系统,值得试试
- wkhtmltopdf-html转pdf把html转化为pdf
brew install --cask wkhtmltopdf
- riptutorial国内免费分享的书籍示例
- 无google全家桶的chromium
- jenkins
- jenkins-pipeline语法
- jenkins-BlueOcean插件
- drone-轻量级的jenkins
- onedev-java版gogs
- gogs本地代码托管
- gitea本地代码托管
- mermaid
- 中科大镜像
- 阿里云镜像
- 清华大学镜像
- 类似hugo-文档建站工具
- cloc代码统计工具
- 企业管理系统
- Discord社交软件
- Slack社交软件
- odoo以前openERP
- 禅道
- LayaAirH5小游戏引擎
- apijson
- apifox
- 八爪鱼-自动爬虫
- clickhouse-联机分析(OLAP)的列式数据库管理系统(DBMS),用来分析现有数据,发现数据规律,商业模式好帮手.
Apache Doris是由百度贡献的开源MPP分析型数据库产品,亚秒级查询响应时间,支持实时数据分析;分布式架构简洁,易于运维,可以支持10PB以上的超大数据集;可以满足多种数据分析需求,例如固定历史报表,实时数据分析,交互式数据分析和探索式数据分析等。 ClickHouse是俄罗斯的搜索公司Yandex开源的MPP架构的分析引擎,号称比事务数据库快100-1000倍,团队有计算机体系结构的大牛,最大的特色是高性能的向量化执行引擎,而且功能丰富、可靠性高。
小知识
- 国内dns地址
字节DNS
180.184.1.1
180.184.2.2
腾讯 DNS
119.29.29.29
182.254.116.116
阿里DNS
223.5.5.5
223.6.6.6
2400:3200::1
百度DNS
180.76.76.76
114.114.114.114
2400:da00::6666
下一代互联网国家工程中心
240c::6666
240c::6644
- 域名解析ipv6地址,是增加AAAA记录
#采用ipv6
ping -6 host
#mac
ping6 host
- utm-虚拟机 detian linux可以正常启动 Username: debian Password: debian
centos-stream9 root 密码同mac的帐户密码
utm一个虚拟机对应一个utm文件,当初次创建可能需要iso,等iso安装完成了,编辑虚拟机属性,删除掉dvd就不会再安装
-
flutter-跨六个平台-为每个平台生成对应的工程目录,从而达到支持多平台目录
-
蓝湖是一款产品文档和设计图的共享平台,帮助互联网团队更好地管理文档和设计图。蓝湖可以在线展示Axure,自动生成设计图标注,与团队共享设计图,展示页面之间的跳转关系
-
OCSP-在线证书状态协议 目的:验证SSL证书的有效性,以确保它未被吊销。
-
企业微信添加机器人,实现接受webhook
-
钉钉添加机器人,实现接受webhook,钉钉开放平台
-
介绍不需要碎片整理
- 文件系统基于区块分配的设计使得磁盘上出现碎片的概率很低,延迟分配和自动的整理策略解放了操作系统的使用者,在多数情况下不需要考虑磁盘的碎片化;
- 固态硬盘的随机读写性能远远好于机械硬盘,随机读写和顺序读写虽然也有性能差异,但是没有机械硬盘的差异巨大,而频繁的碎片整理也会影响固态硬盘的使用寿命;
-
存在ipv0,ipv1,ipv2,ipv3,ipv5协议
-
ipv6难取代ipv4,IPv6的回环地址是:0:0:0:0:0:0:0:0或::,ipv4使用32bit/4字节,每组一个字节,4组,ipv6采用128bit/16字节,每组2个字节,8组.
- IPv6 协议在设计时没有考虑与 IPv4 的兼容性问题
- NAT 技术很大程度上缓解了 IPv4 地址短缺的问题
- 更细粒度的管控 IPv4 地址并回收闲置的资源
- 谁有能力强制推行大家支持?国家虽有文件要求,但设备厂商、运营商、互联网服务提供商、软件开发者、用户这整个链路中,所有的人都把IPv4当必选方案,IPv6当可选方案。所有的人都有非常一致的思维:既然IPv4 100%能访问,IPv6不确定因素那么多,那我就直接全部用IPv4多好多省事。
- 这里测试ipv6
-
tcp粘包因为是传输字节流,解决办法是协议自定义消息边界
- 消息长度固定
- 消息中有包括长度的字段
- 采用特定字符串作为消息边界
-
Google perftools
- 它的主要功能就是通过采样的方式,给程序中cpu的使用情况进行“画像”,通过它所输出的结果,我们可以对程序中各个函数(得到函数之间的调用关系)耗时情况一目了然。
- 在对程序做性能优化的时候,这个是很重要的,先把最耗时的若干个操作优化好,程序的整体性能提升应该十分明显.
-
[almalinux-centos社区版](https://almalinux.org/zh-hans/)
-
转换pdf为jpg图片
# -density 300设置渲染PDF的dpi。
# -trim删除与角像素颜色相同的所有边缘像素。
# -quality 100将JPEG压缩质量设置为最高质量。
magick convert -density 300 -trim a.pdf -quality 100 a.jpg
英特尔的NUC迷你电脑
- 二手服务器主机(无尘机房下来的,质量较好)-费电,响声大
- NUC-性能低
AppImage(Linux apps that run anywhere)
- AppImage 是一个压缩的镜像文件,它包含所有运行所需要的依赖和库文件.你可以直接执行AppImage 文件不需要安装。. 当你把AppImage 文件删除,整个软件也被删除了。. 你可以把它当成windows系统中的那些免安装的exe文件。
jsonl(JSON Lines)
JSON Lines 是一种文本格式,适用于存储大量结构相似的嵌套数据、在协程之间传递信息等。 它有如下特点:
每一行都是完整、合法的 JSON 值;采用 \n 或 \r\n 作为行分隔符; 采用 UTF-8 编码; 使用 jsonl 作为文件扩展名;建议使用 gzip 或 bzip2 压缩并生成 .jsonl.gz 或 .jsonl.bz2 文件,以便节省空间。
gitlab
- gitlab->偏好设置->中文
wps
WPS加载网页表格
- 第一步:在网页上找到自己想要的表格,如果不能复制粘贴的话,那么就勾选其网址,然后复制
- 第二步:打开Excel表格,在菜单中的数据选项卡中找到“自网站”,然后点击进入。
- 第三步:在弹出的页面中,选择“基本”,然后在下方的空格中粘贴刚刚复制好的网址,点击确定。
- 第四步:稍等一会儿,就会弹出导航器,里面就有刚刚网页上的表格,选择你想要的表格,然后点击下方的加载。
- 第五步:最后表格就会很完美的加载在你的Excel中,而且格式都是网页上一样的,避免你再次挑战格式的麻烦
快速选中多行、多列
- 鼠标选中某个单元格,按住 shift 键,然后鼠标点击另外一个单元单元格
kcp/quic/enet协议的区别
-
quic 是一个完整固化的 http 应用层协议,目前已经更名 http/3,指定使用 udp(虽然本质上并不一定需要 udp)。其主要目的是为了整合TCP协议的可靠性和udp协议的速度和效率,其主要特性包括:避免前序包阻塞、减少数据包、向前纠错、会话重启和并行下载等,然而QUIC对标的是TCP+TLS+SPDY,相比其他方案更重,目前国内用于网络游戏较少
-
kcp 只是一套基于无连接的数据报文之上的连接和拥塞控制协议,对底层【无连接的数据报文】没有具体的限制,可以基于 udp,也可以基于伪造的 tcp/icmp 等,也可以基于某些特殊环境的非 internet 网络(比如各种现场通信总线),KCP协议就是在保留UDP快的基础上,提供可靠的传输,应用层使用更加简单.
-
enet: 有ARQ协议。收发不用自己实现,提供连接管理,心跳机制。支持人数固定。自己实现跨平台。支持可靠无序通道。没有拥塞控制。线程不安全
理解socks5协议的工作过程和协议细节
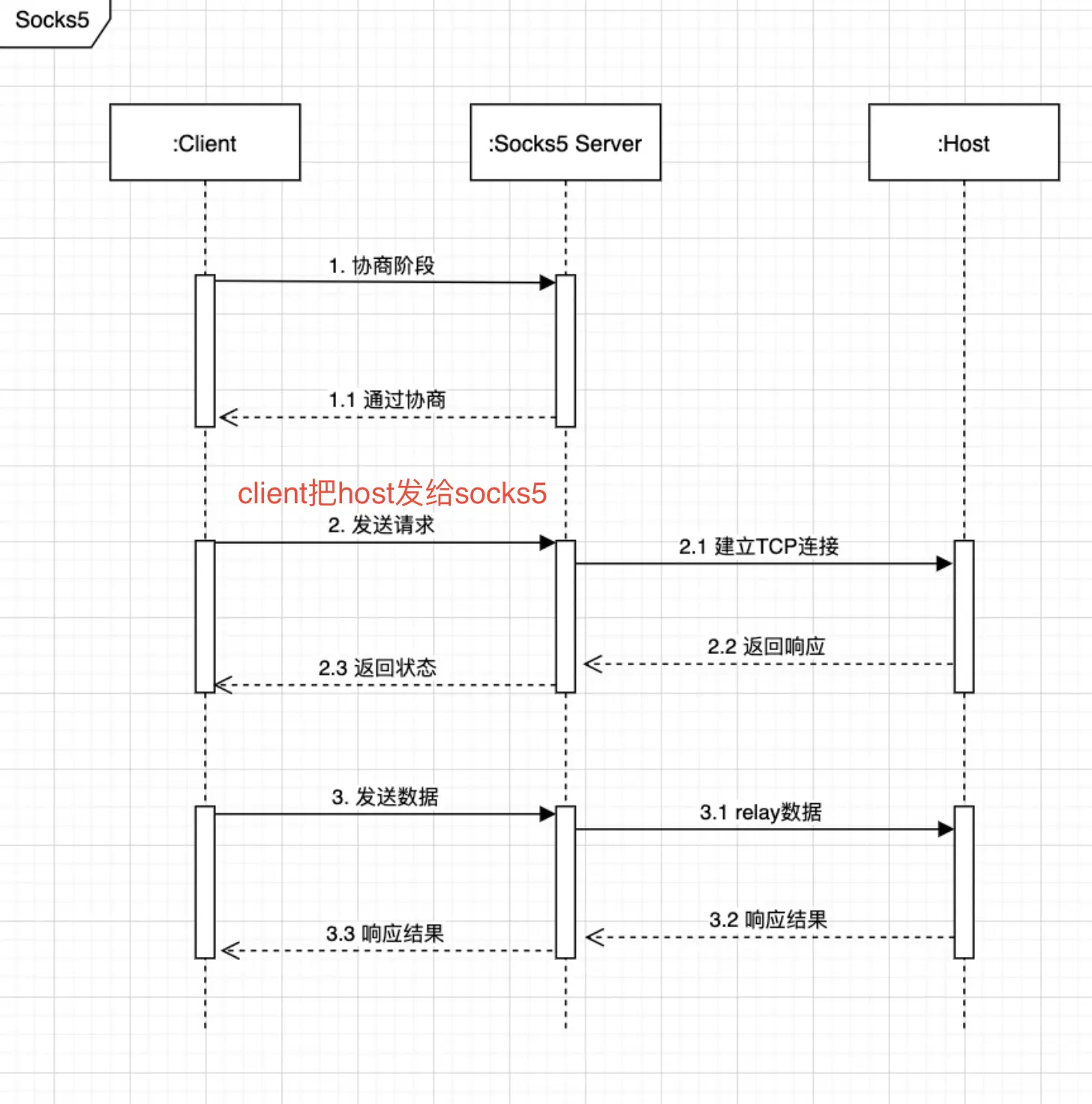
全球ip地址查询
luminati中国
- Luminati是全球最大的代理服务,全球拥有3500万IP的住宅代理网络和零编码代理管理接口。爬取任何网络数据, 从不被屏蔽,从不被掩盖。Luminati是道德代理网络。
无界面浏览器

openwrite-次编写markdown多个平台发布
检测vps的ip是否被封,有人检测到http代理或socks5,则会临时被封几分钟
-
中国站长工具,同时采用国内及国外ping,如果都不行,则肯定是vps问题,否则就极可能被封.
-
traceroute(linux/mac),tracert(windows) xxx 追踪一下
-
查看路由表
- mac系统
netstat -r Routing tables- linux系统
route -n- windows系统
route print
各大厂商的ocr接口
- 华为没有免费的
- 阿里和腾讯都有免费额度
- baidu的效果最好
- window10/11自带ocr api接口
https://cloud.tencent.com/document/product/866/35945
https://help.aliyun.com/document_detail/330957.html
https://ai.baidu.com/ai-doc/REFERENCE/Ck3dwjhhu#%E8%8E%B7%E5%8F%96-access-token
开源代码库可以通过关键字在 GitHub 中查找;教程博客可以在 Medium 这样的平台上搜索;API 则可在官方文档翻阅
埋点
- 是数据采集领域(尤其是用户行为数据采集领域)的术语,指的是针对特定用户行为或事件进行捕获、处理和发送的相关技术及其实施过程。比如用户某个icon点击次数、观看某个视频的时长等等。埋点的技术实质,是先监听软件应用运行过程中的事件,当需要关注的事件发生时进行判断和捕获
便宜的海外服务器
- 腾讯云孟买-特惠
代码相似度检查NiCad
ocr错别字都是形近字,根据语义能否提示错别字?
常见usb接口

阿里云智能插件,仅支持java
Antlr - 强大的开源语法分析工具
HAR
HAR(HTTP档案规范),是一个用来储存HTTP请求/响应信息的通用文件格式,基于JSON。这种格式的数据可以使HTTP监测工具以一种通用的格式导出所收集的数据,这些数据可以被其他支持HAR的HTTP分析工具(包括Firebug、httpwatch、Fiddler等)所使用,来分析网站的性能瓶颈。
开源的聊天应用RocketChat-替代微信
toml文件格式
开源替换Google Analytics-umamiOwn your website analytics 开源替换Google Analytics 应该是当今互联网使用最广泛的网站流量分析服务
次世代图片格式 JPEG XL、AVIF、WebP 2
- AVIF 有损压缩效果最好,无损压缩非常糟糕。编码速度很慢。
- JPEG XL 无损压缩效果最好,有损压缩较 AVIF 有些许差距。编码速度快。
- WebP 2 无损压缩效果优秀,有损压缩的上限达到了 AVIF 的水平,但下限很低,不稳定。编码速度很慢
这里是 Ant Design 的 Vue 实现,开发和服务于企业级后台产品(https://2x.antdv.com/docs/vue/introduce-cn)
github-404项目
gimp 颜色拾取工具 按住shift点击指定位置,弹出颜色拾取对话框,就会有像素值 wps开始,排序,自定义排序,可以多重排序 https://www.zhihu.com/question/496033808 opencv中的霍夫线变换,ρ取负值时怎么理解 https://blog.csdn.net/WZZ18191171661/article/details/101116949
内网服务发布到公网—ngrok,类似以前的花生壳
在加密的情况下,文档只能阅读而不能修改、添加注释
1.把pdf文件在Chrome浏览器/WPS/Adobe acrobat打开
2.点击打印机,“另存为PDF”
3.保存在任意位置
重要
保护眼晴
-
mac深色模式
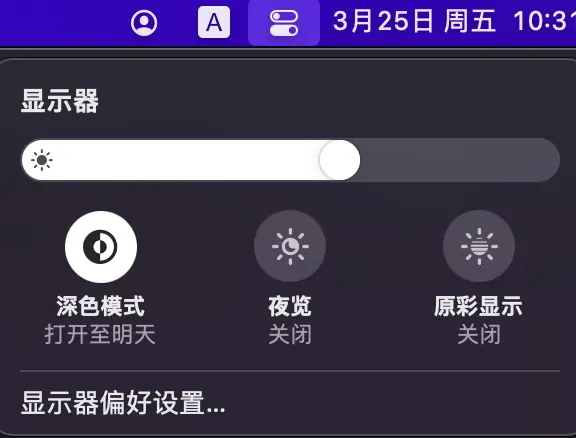

rpc
运行过程
sequenceDiagram
actor c as Client
actor cs as ClientSub
actor s as Server
actor ss as ServerSub
actor h as Handler
c->>cs: 函数调用
cs->>cs: json/protobuf等序列化
cs->>s: tcp/http等发送
s->>ss: 函数调用
ss->>ss: json/protobuf等反序列化
ss->>h: 功能实现
h-->>ss: 函数返回
ss-->>ss: json/protobuf等序列化
ss-->>s: 回包
s-->>cs: tcp/http等发送
cs-->>cs: json/protobuf等反序列化
cs-->>c: 函数返回
常见框架
-
-

-
-
-
grpcurl 类似curl,但用于grpc
搜索技巧
搜索技巧就是在搜索关键字时,配合一些通配符,帮助快速定位到想要的结果 搜索技巧常常作为SEO(Search Engine Optimization)技术学习的一部分 SEO : 是一种通过了解搜索引擎,以及提高目的网站在有关搜索引擎内排名的方式
intitle标题
keyword intitle:标题关键字
site站内(还可以查看网站的收录情况)
keyword site:cnblogs.com
duckduckgo site:zhihu.com
Filetype过滤文件类型
keyword:pdf
减号,排除关键词
# python -广告 -推广
keyword -keyword2
inurl链接
keyword inurl:video
限定时间段
keyword 2022..2022
intext内容
keyword intext:内容关键字
info 介绍
info:zhihu.com
cache 搜索引擎关于某项关键字的缓存
cache:keyword
双引号/书括号,禁止拆分
"keyword"《keyword》
模糊匹配
keyword*keyword
define 关键词定义
define:keyword
link 搜索与某个网址有关联的其他网址
keyword link:xxx.com
bing高级搜索帮助
U盘
选择U盘的文件系统需根据使用场景和需求权衡。以下是常见文件系统的特点及推荐方案
1. 跨平台通用性优先(Windows/Mac/Linux)
-
exFAT
- 优势:支持单个文件>4GB,兼容Windows、Mac(10.6.5+)和Linux(需内核支持或手动安装驱动)。
- 适用场景:跨系统传输大文件(如高清视频),且设备较新。
- 注意:部分老旧设备(如老电视、车载系统)可能不兼容。
-
FAT32
- 优势:所有系统原生支持,兼容性极强。
- 缺点:单个文件≤4GB,适合小文件传输。
- 适用场景:旧设备或仅需小文件跨平台共享。
2. Windows专用场景
- NTFS
- 优势:支持大文件、加密、权限管理,适合大容量U盘。
- 缺点:Mac/Linux默认仅支持读取(需安装额外驱动才能写入)。
- 适用场景:仅Windows使用,需高级功能或大文件存储。
3. Linux/Mac专用场景
- ext4(Linux) / APFS(Mac)
- 优势:性能优化,支持高级功能(如日志、权限)。
- 缺点:跨平台兼容性差,其他系统可能无法识别。
- 适用场景:U盘仅在单一系统使用,追求性能。
选择建议
- 通用性为王 → exFAT(现代设备首选)。
- 纯Windows大文件 → NTFS。
- 老旧设备/小文件 → FAT32。
- 单一系统深度使用 → 对应系统专用格式(如ext4/APFS)。
注意事项
- 备份数据:格式化会清除所有数据。
- 设备兼容性:不确定时优先选FAT32或exFAT。
- 性能影响:U盘速度主要取决于接口(USB 3.0/3.1)和闪存颗粒,文件系统差异较小。
磁盘
专业解析:磁盘分区、分区表与逻辑分区的核心定义与功能
一、磁盘分区(Disk Partitioning)
定义:
磁盘分区是将物理硬盘划分为多个独立的逻辑区域(称为分区)的过程。每个分区可独立管理文件系统、存储不同类型数据,相当于将一个大仓库分隔为多个功能明确的小房间。
核心功能:
- 数据隔离:例如将操作系统(C盘)、用户文件(D盘)、备份数据(E盘)分开存储,避免单一分区故障导致全部数据丢失。
- 性能优化:为不同数据类型(如系统文件、视频、数据库)分配独立分区,减少磁盘碎片和访问冲突。
- 扩展性:通过分区灵活调整存储空间,例如为游戏或大型软件预留独立分区。
分区类型:
- 主分区(Primary Partition):最多4个(MBR格式),可直接引导操作系统(如安装Windows的C盘)。
- 扩展分区(Extended Partition):占用1个主分区名额,作为逻辑分区的容器(不能直接存储数据)。
- 逻辑分区(Logical Partition):在扩展分区内创建,数量无限制,用于存储用户数据和应用程序。
二、分区表(Partition Table)
定义:
分区表是硬盘上的关键数据结构,记录所有分区的位置、大小、类型等信息,是操作系统识别和管理分区的“地图”。
核心功能:
- 分区定位:告知系统每个分区的起始和结束位置(如C盘从扇区0到1GB)。
- 引导支持:MBR分区表的引导程序负责启动操作系统(如加载Windows的Bootmgr)。
- 空间管理:分配磁盘空间,例如将未分配空间标记为可用,供新建分区使用。
技术演进:
- MBR(Master Boot Record):
- 传统格式,支持最大2TB硬盘,最多4个主分区(或3主分区+1扩展分区)。
- 存在局限性:分区数量少、不支持大容量硬盘。
- GPT(GUID Partition Table):
- 现代标准,支持最大18EB硬盘,最多128个分区,内置备份机制提高可靠性。
- 适配场景:3TB以上硬盘、双系统安装(如Windows+Linux)。
三、逻辑分区(Logical Partition)
定义:
逻辑分区是扩展分区内的子分区,用于存储用户数据和应用程序,不能直接引导系统,但数量不受限(仅受磁盘容量限制)。
核心优势:
- 灵活扩展:例如将剩余磁盘空间全部分配给扩展分区,再按需创建多个逻辑分区(如D盘存文档、E盘装软件)。
- 动态调整:通过工具(如Windows磁盘管理)增减逻辑分区大小,无需重装系统。
- 兼容性:突破MBR的4分区限制,例如将第5个分区设为逻辑分区存储视频库。
典型应用场景:
- 多用户环境:为每个用户分配独立逻辑分区,保障数据安全。
- 服务器存储:按客户或数据类型划分逻辑分区(如客户A的数据存于分区F,客户B存于分区G)。
总结:三者协作关系
- 磁盘分区:物理硬盘的逻辑划分,定义数据存储边界。
- 分区表:记录分区元数据的“账本”,确保系统正确访问分区。
- 逻辑分区:扩展分区内的弹性存储单元,满足动态数据增长需求。
类比理解:
- 磁盘 = 城市
- 分区表 = 城市地图
关于磁盘分区、分区表和逻辑分区的概念,我用生活化的比喻和通俗解释帮你梳理:
1⃣ 磁盘分区(Disk Partition)
👉 就像把一个大仓库划分成不同房间
- 物理硬盘就像一整个空仓库,分区就是在这个仓库里砌墙,划分出独立空间(如C盘、D盘)
- 作用:安装不同系统(如Windows和Linux分开装)、隔离数据(系统盘和存储盘分开)、提升管理效率
2⃣ 分区表(Partition Table)
👉 类似仓库的建筑图纸
- 存储在硬盘最开头的隐藏区域,记录所有分区的位置和大小(如“从第1到1000个货架属于C盘“)
- 两种主流格式:
- MBR(老式图纸):最多支持4个主分区,最大2TB硬盘(2012年前主流)
- GPT(新式图纸):支持128个分区,最大18EB硬盘(约18亿TB),现代电脑默认使用
3⃣ 逻辑分区(Logical Partition)
👉 主分区不够用时的“套娃方案“
- 主分区:直接登记在分区表中的独立空间(最多4个)
- 扩展分区:当需要超过4个分区时,把其中一个主分区改造成“扩展分区“(相当于一个大盒子)
- 逻辑分区:在扩展分区这个“大盒子“里继续划分的小分区(数量不限),用于突破4主分区的限制
💡 经典组合案例(MBR模式)
硬盘分区结构
├─ 主分区1(C盘:装系统)
├─ 主分区2(D盘:存储)
├─ 扩展分区(虚拟容器)
│ ├─ 逻辑分区1(E盘:电影)
│ ├─ 逻辑分区2(F盘:游戏)
└─ 主分区3(G盘:备用)
🔧 现代变化
- 使用GPT分区表的硬盘无需扩展分区,可直接创建128个主分区
- Windows系统通常保留EFI系统分区和恢复分区(隐藏的小分区)
通过分区管理工具(如DiskGenius),可以像拼积木一样自由调整这些分区结构。
专业解析:分区表与逻辑卷的关联及协作机制
一、分区表(Partition Table)的核心作用
定义:
分区表是硬盘上的关键数据结构,记录所有物理分区的位置、大小、类型等信息,是操作系统识别和管理分区的“地图”。
功能:
- 分区定位:明确每个分区的起始和结束扇区(如分区A从扇区0到1GB)。
- 引导支持:MBR分区表的引导程序负责启动操作系统(如加载Windows的Bootmgr)。
- 空间管理:分配磁盘空间,标记未分配区域供新建分区使用。
技术演进:
- MBR:支持4个主分区(或3主+1扩展),最大2TB磁盘。
- GPT:支持128个分区,最大18EB磁盘,内置备份机制。
二、逻辑卷(Logical Volume)的核心优势
定义:
逻辑卷是逻辑卷管理(LVM)中的抽象层,将多个物理分区或磁盘组合成逻辑存储空间,提供弹性扩展和高级功能。
功能:
- 跨磁盘整合:合并多个物理分区(如将2个1TB硬盘合并为2TB逻辑卷)。
- 动态调整:在线扩展/缩减逻辑卷大小(如将100GB卷扩展至200GB,无需停机)。
- 快照与镜像:支持数据备份(如创建快照卷用于测试)和冗余(如镜像卷提升可靠性)。
技术组件:
- 物理卷(PV):被LVM管理的物理分区或磁盘。
- 卷组(VG):PV的集合,作为逻辑卷的存储池。
- 逻辑卷(LV):从VG中划分的独立逻辑存储空间。
三、分区表与逻辑卷的关联协作
-
基础与扩展:
- 分区表定义物理分区(如/dev/sda1、/dev/sdb1),是存储管理的起点。
- 逻辑卷在物理分区基础上构建,例如将/dev/sda1和/dev/sdb1加入卷组VG,再划分逻辑卷LV。
-
灵活性提升:
- 分区表受限于磁盘容量(如MBR最大2TB),逻辑卷通过跨磁盘整合突破此限制。
- 动态调整:分区表修改需重新分区或格式化,逻辑卷支持在线扩容(如
lvextend -L +10G /dev/VG/LV)。
-
典型应用场景:
- 服务器存储池:将多块硬盘的分区加入卷组,按需划分逻辑卷(如数据库卷、备份卷)。
- 云环境扩展:虚拟机磁盘通过逻辑卷动态扩展,适应业务增长。
四、类比理解
- 分区表 = 城市地图(标记物理街道位置)。
- 逻辑卷 = 虚拟社区(跨街道整合土地,按需划分住宅/商业区)。
- 优势:虚拟社区可动态调整面积(如将商业区扩展至邻街土地),而物理街道布局(分区表)无需变动。
总结
分区表是磁盘管理的“地基”,定义物理分区边界;逻辑卷是“高层建筑”,在分区表基础上提供弹性、可扩展的存储解决方案。二者结合,既保证了存储的基础管理,又实现了资源的灵活调度,是现代存储技术的核心协作模式。
分区表和逻辑卷(Logical Volume)是不同层次的磁盘管理技术,二者可以协同工作,但解决的问题不同。下面用对比和场景化的方式解释它们的关联:
1⃣ 本质区别
| 分区表 | 逻辑卷(LVM) |
|---|---|
| 硬件层管理:直接操作物理硬盘,划分独立存储区域(如C盘、D盘) | 逻辑层管理:在物理分区之上构建“虚拟存储池“,动态分配空间 |
| 功能局限:分区大小固定,调整需格式化 | 高度灵活:可在线扩展/缩小,支持快照、镜像等高级功能 |
| 依赖标准:依赖MBR或GPT格式 | 跨分区能力:可整合多个物理硬盘或分区,组成超大存储池 |
2⃣ 关联场景:分区表是逻辑卷的物理基础
典型部署流程
1️⃣ 先有分区表
用MBR/GPT划分硬盘 → 创建一个或多个分区(例如 /dev/sda1)
2️⃣ 分区转为物理卷(PV)
将分区标记为LVM的物理卷(Physical Volume):
pvcreate /dev/sda1 # 将此分区纳入LVM管理
3️⃣ 整合物理卷为卷组(VG)
将多个物理卷(可跨不同硬盘)合并成卷组(Volume Group):
vgcreate my_vg /dev/sda1 /dev/sdb1
4️⃣ 从卷组划分逻辑卷(LV)
在卷组中动态创建逻辑卷(Logical Volume):
lvcreate -L 100G -n my_data my_vg # 创建名为my_data的100G逻辑卷
5️⃣ 格式化并使用逻辑卷
最终用户看到的是逻辑卷(如 /dev/mapper/my_vg-my_data),而非底层物理分区。
3⃣ 关键差异对比
| 场景 | 分区表方案 | 逻辑卷方案 |
|---|---|---|
| 调整分区大小 | 需备份数据 → 删除分区 → 重建 | 直接在线调整,无需停机 |
| 跨硬盘存储池 | 无法实现 | 可将多个硬盘的分区合并成统一池 |
| 快照备份 | 不支持 | 可创建瞬间快照,备份不影响业务 |
| 典型应用场景 | 个人电脑、简单服务器 | 企业级存储、云服务器、数据库 |
4⃣ 技术栈关系示意图
物理硬盘(如1TB HDD)
│
├─ **分区表(GPT/MBR)** → 划分出物理分区(如/dev/sda1、/dev/sda2)
│
├─ **直接使用分区** → 格式化为NTFS/ext4等文件系统(传统方式)
│
└─ **转为LVM物理卷(PV)** → 合并到卷组(VG)→ 划分逻辑卷(LV)→ 格式化为文件系统
💡 核心结论
- 分区表是底层物理划分,逻辑卷是上层逻辑抽象
- 逻辑卷依赖分区表:LVM的物理卷通常基于分区表中的分区(也可直接使用整块硬盘)
- 互补而非替代:
- 分区表确保硬件兼容性(例如系统引导分区必须基于分区表)
- 逻辑卷提供运维灵活性(适合需要动态调整的场景)
好的!逻辑卷管理(Logical Volume Management, LVM)的起源和发展与计算机存储需求的演变密切相关。以下从技术演进的角度,分阶段详解其发展历程:
一、前LVM时代:传统分区的痛点(1980年代前)
1. 磁盘管理基础
- 物理磁盘直接分区:早期操作系统(如DOS、Unix)直接通过分区表(MBR)将磁盘划分为固定大小的分区。
- 核心问题:
- 容量僵化:分区大小在创建时固定,无法动态调整。
- 空间浪费:分区预留过多导致浪费,或分配不足需重建。
- 扩展性差:无法跨多块硬盘合并存储空间。
2. 早期解决方案
- 手动调整:需停机备份数据 → 删除旧分区 → 重建更大分区 → 恢复数据(高风险且低效)。
- 软RAID:通过RAID组合磁盘,但灵活性仍不足。
二、LVM的起源:Unix系统的探索(1980-1990年代)
1. 初代LVM诞生
-
1985年:HP-UX的LVM
惠普在HP-UX(Unix系统)中首次实现逻辑卷管理,核心思想:- 将物理存储抽象为物理卷(PV) → 聚合为卷组(VG) → 动态划分逻辑卷(LV)。
- 支持在线调整逻辑卷大小,无需停机。
-
1988年:AIX的LVM
IBM在AIX操作系统中引入类似技术,进一步优化存储池管理。
2. 早期LVM特性
- 基本功能:动态扩展逻辑卷、跨磁盘存储池。
- 局限性:功能较为基础,缺乏快照、镜像等高级特性。
三、Linux的LVM革命(1990年代末-2000年代)
1. Linux LVM的诞生
- 1998年:LVM1
Heinz Mauelshagen为Linux内核开发了首个LVM实现(LVM1),特性包括:- 物理卷、卷组、逻辑卷的三层抽象。
- 支持在线扩展逻辑卷(但缩减仍需卸载文件系统)。
2. LVM2的飞跃
- 2001年:LVM2
基于设备映射器(Device Mapper)重构,成为现代Linux LVM的基石:- 动态调整:支持在线扩展和缩减逻辑卷。
- 快照功能:创建时间点副本,用于备份或测试。
- 跨平台兼容:支持RAID、多路径存储等底层技术。
3. 关键里程碑
- 2003年:Red Hat Enterprise Linux 3默认集成LVM2。
- 2004年:支持逻辑卷镜像(数据冗余)。
- 2007年:引入精简配置(Thin Provisioning),实现按需分配存储空间。
四、现代LVM的演进(2010年代至今)
1. 功能增强
- 快照优化:支持递归快照、快速克隆。
- 缓存加速:允许用SSD作为逻辑卷的缓存层(如LVM Cache)。
- 加密整合:与LUKS(Linux磁盘加密)深度结合,支持加密逻辑卷。
2. 云与虚拟化驱动
- 动态资源分配:在云计算中,LVM配合虚拟化技术(如KVM、Docker)实现存储资源的弹性分配。
- 容器存储:为Kubernetes提供动态卷供给(Dynamic Volume Provisioning)。
3. 跨平台发展
- Windows的类LVM方案:
Windows通过**存储空间(Storage Spaces)**实现类似功能,支持存储池和虚拟磁盘。 - ZFS与Btrfs:
新一代文件系统(如ZFS、Btrfs)内置卷管理功能,与LVM形成竞争互补。
五、LVM的核心价值与挑战
1. 核心优势
- 灵活性:动态调整存储空间,适应业务增长。
- 抽象化:解耦物理存储与逻辑视图,简化运维。
- 高级功能:快照、镜像、精简配置等企业级特性。
2. 当前挑战
- 复杂性:配置和管理门槛高于传统分区。
- 性能开销:多层抽象可能引入轻微I/O延迟(通常可忽略)。
- 新兴替代方案:
云原生存储(如Ceph)、分布式文件系统正在部分场景中替代LVM。
六、未来趋势
- 与NVMe/RDMA结合:优化高性能存储设备的利用率。
- 自动化管理:通过AIops实现智能容量预测和调整。
- 安全增强:更深度整合硬件加密与权限控制。
总结:LVM的技术演进图谱
1980年代(痛点) → 1985 HP-UX LVM(起源) → 1998 Linux LVM1 → 2001 LVM2(现代化) → 2010+ 云与虚拟化(扩展) → 未来(智能化)
逻辑卷管理从解决固定分区痛点出发,逐步演变为现代IT基础设施中存储虚拟化的核心技术,其发展史是计算机系统追求灵活性与效率的典型缩影。
css

iphone
一台电脑控制多台手机的技术原理主要涉及设备连接管理、通信协议、并行控制以及软件框架支持。以下是详细解析
1. 设备连接与通信
a. 物理连接方式
- USB连接:通过USB集线器扩展端口,多台手机连接到同一台电脑。每台设备会被分配唯一的标识符(如ADB序列号)。
- Wi-Fi连接:手机通过无线网络与电脑通信,需要先通过USB激活ADB调试,再切换为无线模式(
adb tcpip 5555)。 - 专用硬件设备:使用手机集群管理硬件(如STF框架的Device Farmer或厂商的测试机柜),支持同时连接数百台设备。
b. 通信协议
- ADB(Android Debug Bridge):核心协议,用于与Android设备通信,支持安装应用、执行Shell命令、传输文件等。
- WebDriver协议:通过Appium等框架实现自动化控制,兼容iOS/Android。
- VNC/Scrcpy协议:用于屏幕镜像和实时操作(如Scrcpy通过ADB传输H.264视频流)。
2. 设备识别与管理
- 唯一标识符:每台设备通过
adb devices获取唯一序列号,用于区分和定位。 - 端口映射:为每台设备分配独立端口(如
adb -s 设备号 forward tcp:本地端口 tcp:远程端口),实现多设备并行通信。 - 设备池(Device Farm):通过框架(如Selenium Grid、OpenSTF)动态分配设备资源,支持任务队列和负载均衡。
3. 并行控制技术
a. 多线程/异步编程
- 多线程:为每台设备启动独立线程执行命令(如Python的
threading库)。 - 异步I/O:使用异步框架(如Node.js的
async.js或Python的asyncio)提高效率。
b. 批量命令执行
-
通过脚本遍历设备列表,循环发送指令:
for device in $(adb devices | grep -v List | awk '{print $1}') do adb -s $device install app.apk & done
4. 常用工具与框架
a. 原生工具链
- ADB命令:基础控制(安装、截图、日志抓取)。
- Scrcpy:低延迟屏幕控制(支持多开窗口)。
b. 自动化测试框架
- Appium:跨平台自动化,支持多设备并发。
- Espresso/UIAutomator:针对Android的UI自动化。
c. 设备管理平台
- OpenSTF (Smartphone Test Farm):开源设备集群管理,支持远程调试和监控。
- Sauce Labs/BrowserStack:云设备农场,提供API集成。
d. 云真机服务
- 阿里云/AWS Device Farm:通过云端直接调度真实设备,无需本地连接。
5. iOS设备的特殊处理
- libimobiledevice:开源库支持iOS通信(类似ADB)。
- WebDriverAgent:Facebook提供的iOS自动化框架,需Xcode配合。
- 苹果限制:需开发者证书签名,且一台电脑通过USB仅能连接少量设备(通常不超过10台)。
6. 典型应用场景
- 自动化测试:并行运行兼容性测试(如Monkey测试)。
- 群控营销:批量操作社交媒体账号(需注意合规性)。
- 数据采集:多设备同时爬取App数据。
- 应用演示:同步展示功能到多台手机。
7. 技术挑战与解决方案
- 设备异构性:不同型号/系统版本需动态适配(通过
adb shell getprop获取设备信息)。 - 性能瓶颈:USB带宽限制(Wi-Fi控制或分布式集群缓解)。
- 安全性:ADB调试需授权,建议隔离网络环境。
总结
通过ADB/WebDriver协议通信、多线程/异步控制、设备管理框架及端口映射技术,一台电脑可高效控制多台手机,适用于测试、运维和自动化场景。实际实现需结合具体工具(如Appium+OpenSTF)和脚本编写。
DDNS服务
DDNS(Dynamic Domain Name System)是一种动态域名解析服务,它可以让用户通过一个固定的域名来访问一个动态变化的IP地址。在互联网上,每个设备都需要一个唯一的IP地址才能进行通信。然而,由于某些因素(如互联网服务提供商的动态分配),用户的公网IP地址可能会发生变化。这就导致了访问设备或服务时需要不断更新IP地址的问题。DDNS服务的出现解决了这一难题。
DDNS服务的用途非常广泛,以下是一些常见的应用场景:
远程访问:通过使用DDNS服务,用户可以为自己的设备(如摄像头、NAS、路由器等)分配一个固定的域名,以便在外部网络中远程访问。无论公网IP地址如何变化,用户只需使用域名即可稳定地连接到设备。
网站托管:如果用户在自己的电脑或服务器上搭建了一个网站或博客,并希望向外界提供访问,DDNS服务可以将用户的域名与动态IP地址绑定在一起。这样,即使IP地址变化,用户的网站仍然可以通过域名访问。
远程控制和文件共享:通过DDNS服务,用户可以远程控制家庭网络中的设备(如智能家居设备)或在不同地点之间共享文件。DDNS服务将动态分配的IP地址映射到用户的域名,使远程访问变得更加便捷。
使用DDNS服务并不复杂,下面是一般的使用指南:
注册域名:在域名注册商处购买或申请一个域名。确保选择一个易记且符合你需求的域名。
选择DDNS服务商:在各个DDNS服务提供商中选择一个合适的服务商。比较常用的有dnspod、noip等。注册一个账户并绑定你购买的域名。
配置DDNS客户端:根据DDNS服务商提供的指南,安装并配置DDNS客户端软件或脚本。这个客户端将定期检测你的公网IP地址,并将其发送给DDNS服务商,以便更新DNS服务器上的域名记录。确保配置正确,以保持IP地址的同步更新。
测试访问:使用浏览器或其他工具,尝试通过你的域名访问你的设备或服务。确认访问稳定和准确。
eBPF技术
摘抄于文章
如何使用 eBPF 是一个由多个组件组成的系统:
eBPF programs eBPF hooks BPF maps eBPF 验证器 eBPF 虚拟机 请注意,我交替使用了术语“BPF”和“eBPF”。 eBPF 代表“扩展伯克利数据包过滤器”。 BPF 最初被引入 Linux 来过滤网络数据包,但 eBPF 扩展了原始 BPF,使其可以用于其他目的。今天它与伯克利无关,而且它不仅仅用于过滤数据包。
下面说明了 eBPF 如何在用户空间和底层工作。 eBPF 程序用高级语言(例如 C)编写,然后编译为 eBPF bytecode 。然后,eBPF 字节码被加载到内核中并由 eBPF virtual machine 执行。
eBPF 程序附加到内核中的特定代码路径,例如系统调用。这些代码路径称为 hooks 。当钩子被触发时,eBPF 程序就会被执行,现在它会执行您编写的自定义逻辑。这样我们就可以在内核空间中运行我们的自定义代码。
图示
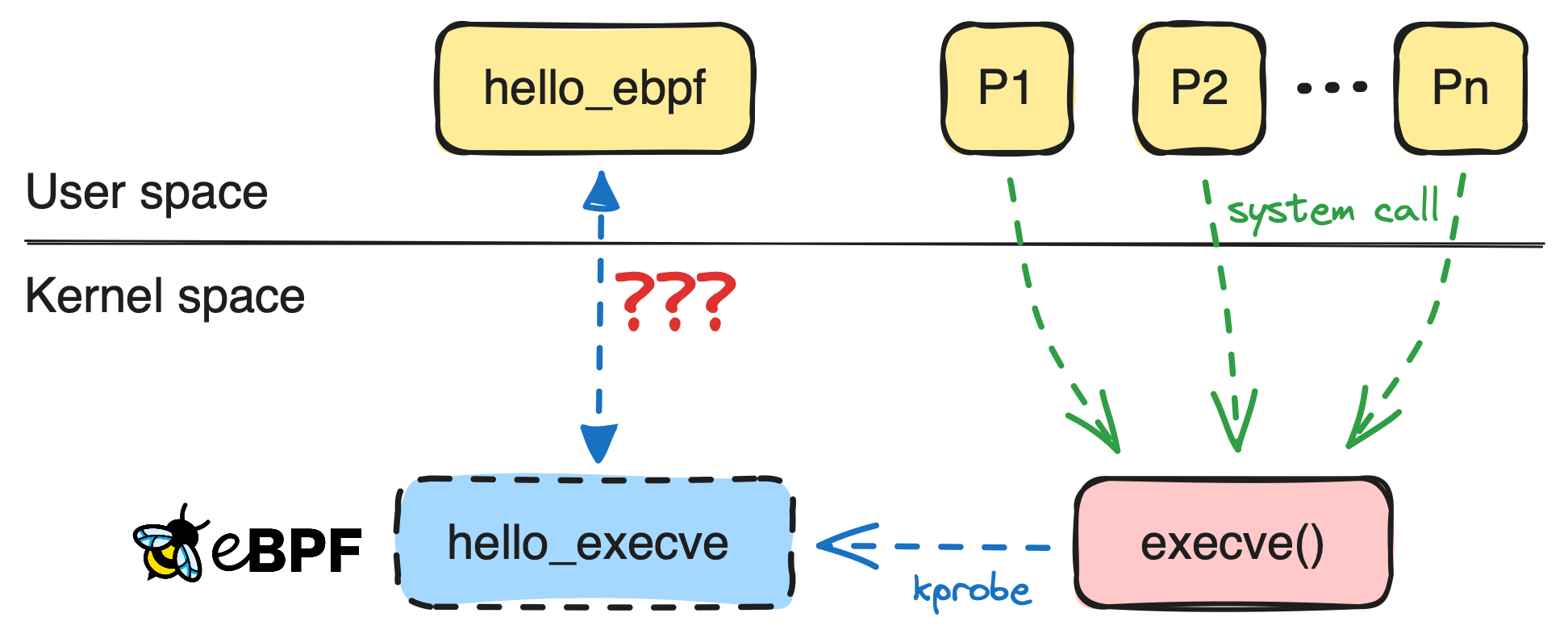
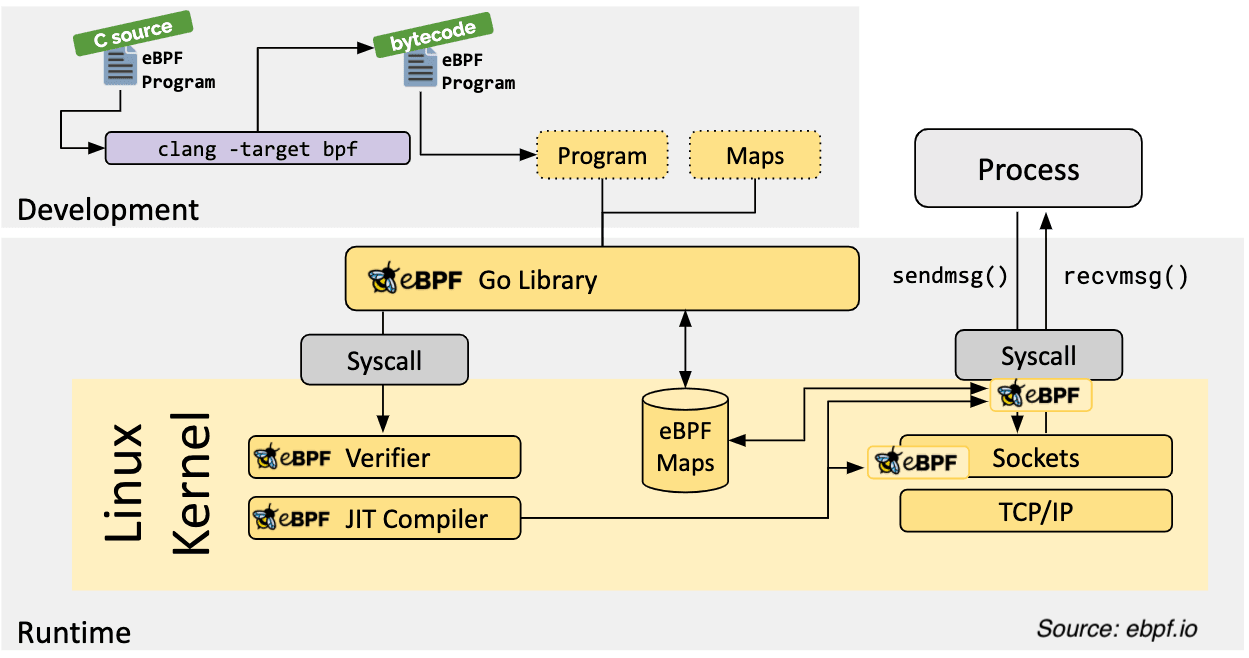
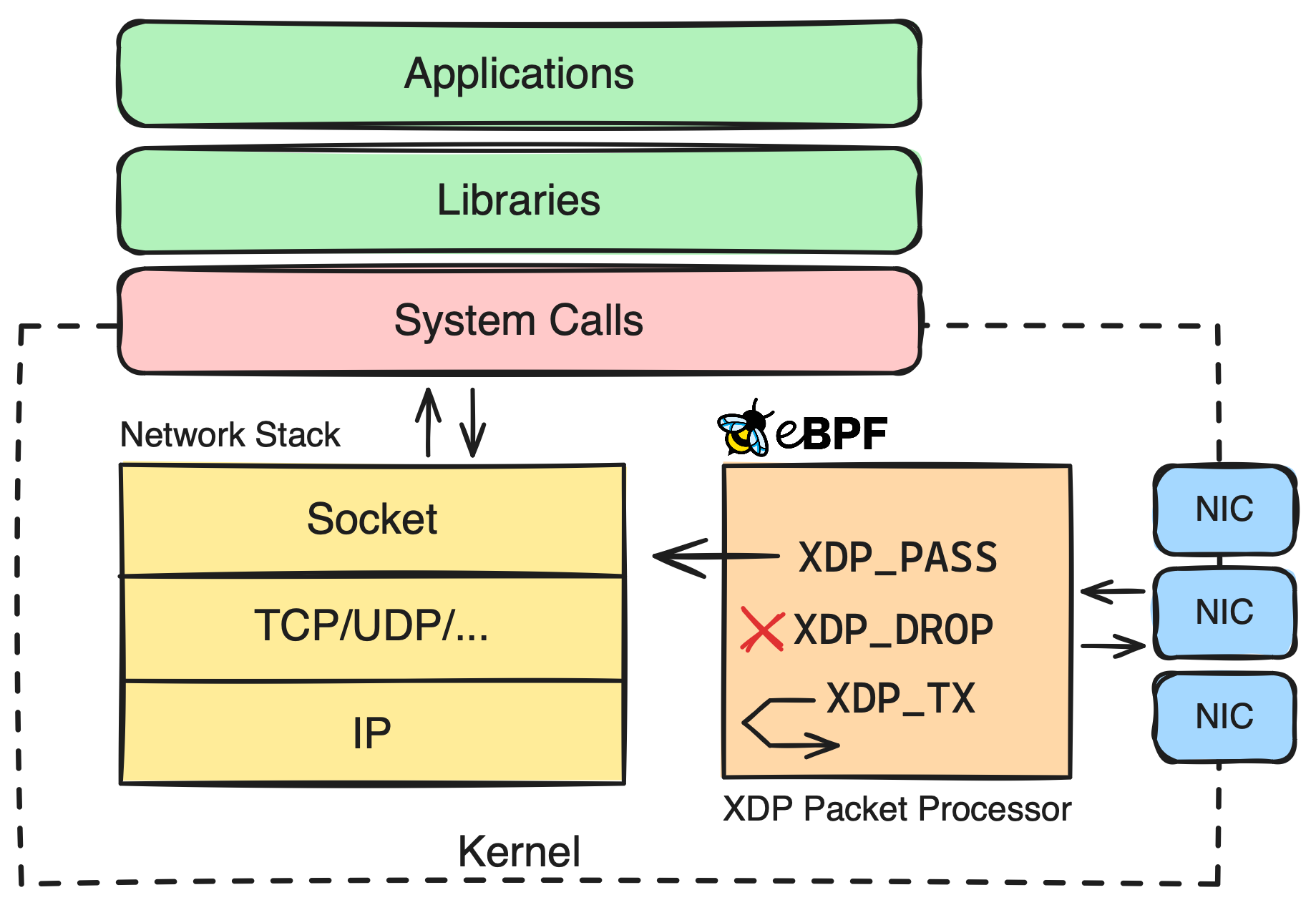
应用示例
i2p
I2P(Invisible Internet Project,隐形互联网项目)是一种开源的匿名网络层协议,旨在为用户提供高度匿名的通信环境。 它通过加密和分布式路由技术,保护用户的隐私和网络活动免受监控或追踪。
I2P的核心特点
-
匿名性
- 所有通信(如浏览网站、文件传输、聊天等)均通过多层加密和随机路由节点(称为“隧道”)转发,隐藏用户的真实IP地址和身份。
- 数据在传输过程中会被多次加密,且路径动态变化,防止第三方追踪。
-
去中心化架构
- I2P网络没有中心服务器,依赖全球志愿者运行的节点进行数据传输,抗审查能力较强。
-
暗网服务
- I2P支持创建和访问以
.i2p或.b32.i2p结尾的匿名网站,这些服务仅能通过I2P网络访问。
- I2P支持创建和访问以
-
多样化应用
- 除了网页浏览,还支持电子邮件、文件共享、即时通讯等匿名工具。
I2P与Tor的区别
- 目标场景
- Tor(The Onion Router)更注重通过出口节点访问普通互联网(如访问公开网站),而I2P专注于内部匿名网络(类似封闭的“暗网”)。
- 网络结构
- I2P采用分布式单向隧道(入口和出口分离),而Tor使用多跳的固定路径。
- 性能与延迟
- I2P因多层加密和动态路由,通常延迟更高,但设计上更注重隐蔽性而非速度。
如何访问I2P网站(如你提供的链接)
-
安装I2P软件
-
配置浏览器
- 设置浏览器代理为
127.0.0.1:4444(HTTP)或127.0.0.1:4445(HTTPS),或直接使用I2P内置的浏览器。
- 设置浏览器代理为
-
访问
.i2p地址- 输入类似
http://zlib24th6ptyb4ibzn3tj2cndqafs6rhm4ed4gruxztaaco35lka.b32.i2p的地址即可(需等待I2P网络完全启动)。
- 输入类似
注意事项
-
安全性
- I2P提供匿名性,但无法完全防御高级攻击(如流量分析或端点漏洞)。
- 仅访问可信资源,某些I2P网站可能涉及非法内容。
-
法律与道德风险
- 匿名网络常被用于合法隐私保护,但也可能被滥用。使用时需明确目的并规避风险。
总结
I2P是一个为隐私保护设计的工具,适合需要规避监控或访问受限资源的场景。其技术复杂性较高,普通用户需学习配置方法,并始终警惕潜在风险。对于你提供的链接,确保了解其内容合法性后再决定是否访问。
地理编码
地理编码
地理编码是指将地址或地名等位置描述转换为经纬度坐标的过程.
出于国家安全考虑,公布出来的坐标信息一般是经过加偏的.
逆地理编码
逆地理编码可将经纬度坐标转换为详细,标准的地址信息.
常用接口
优秀开源软件
mrdoc-觅思文档
- 其功能类似于国内的语雀平台、看云平台和飞书文档,国外的 GitBook 平台。
rustdesk-远程桌面
网络状态模拟器
opencv
机器学习
常见框架
-
pytorch,1.12之后支持m1芯片
-
tensorflow,目前支持m1芯片,需要打补丁tensorflow-plugin
-
Core ML,苹果内置机器学习
python机器学习包介绍

矩阵乘法

深度学习中图像为什么要归一化?
在神经网络里,输入RGB图片的时候,通常要除以255,把像素值对应到0和1之间
-
如果输入层 x 很大,在反向传播时候传递到输入层的梯度就会变得很大。梯度大,学习率就得非常小,否则会越过最优。在这种情况下,学习率的选择需要参考输入层数值大小,而直接将数据归一化操作,能很方便的选择学习率。
-
一般归一化还会做减去均值除以方差的操作, 这种方式可以移除图像的平均亮度值 (intensity)。很多情况下我们对图像的亮度并不感兴趣,而更多地关注其内容,比如在目标识别任务中,图像的整体明亮程度并不会影响图像中存在的是什么物体。此时,在每个样本上减去数据的统计平均值可以移除共同的部分,凸显个体差异。
ai
wasm
官方网站
WebAssembly,通常简称为 Wasm,是一种相对较新的技术,它允许你编译用 40 多种语言(包括 Rust、C、C++、JavaScript 和 Golang)编写的应用程序代码,并在沙盒环境中运行它。最初的用例主要是在 Web 浏览器中运行本地代码,但是由于 WebAssembly 系统接口(WASI)的存在,Wasm 正在迅速向浏览器之外扩展,
wasmedge
wasm-二进制标准格式,另一个“一次编译,到处执行“
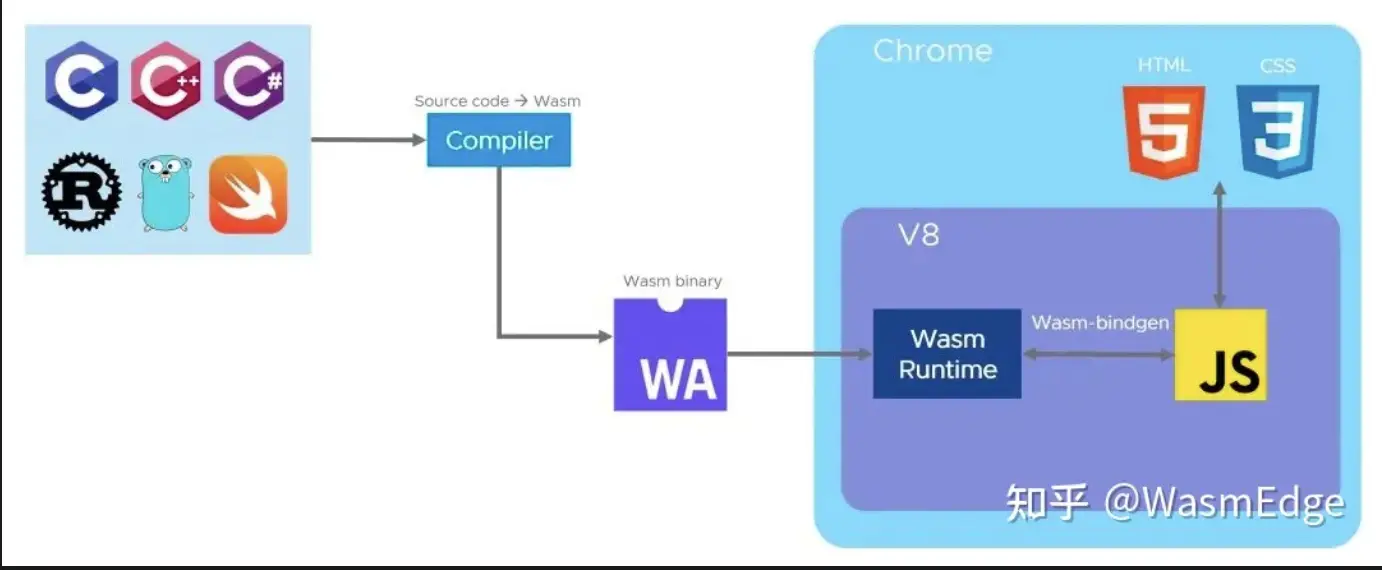
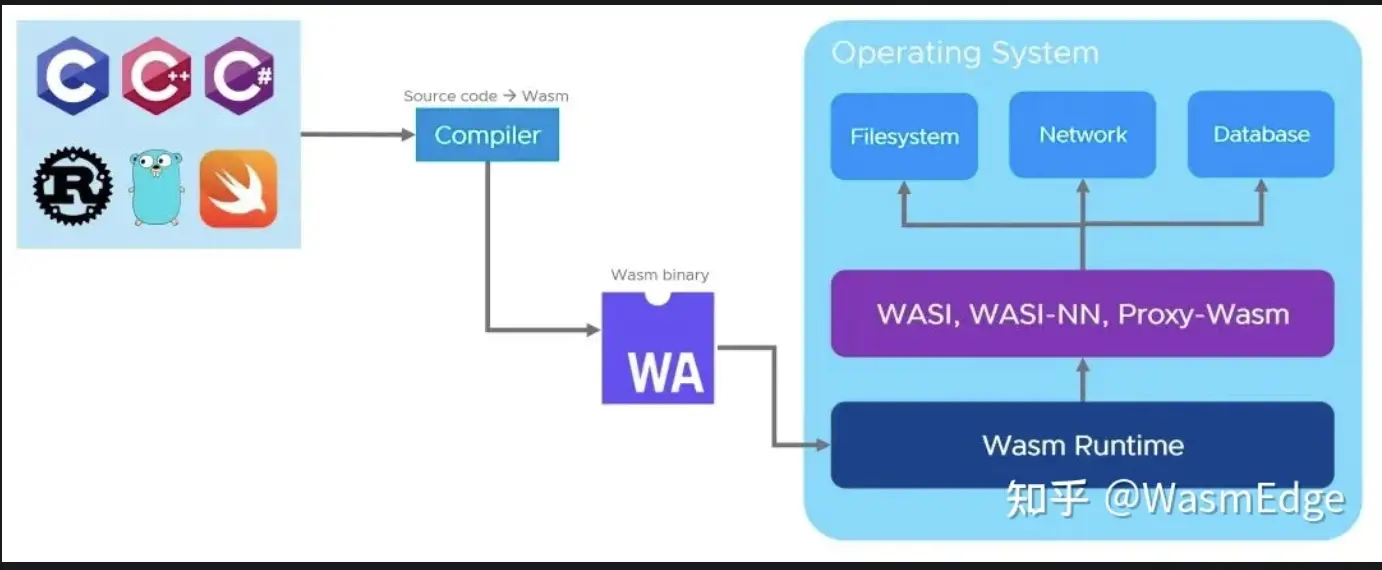
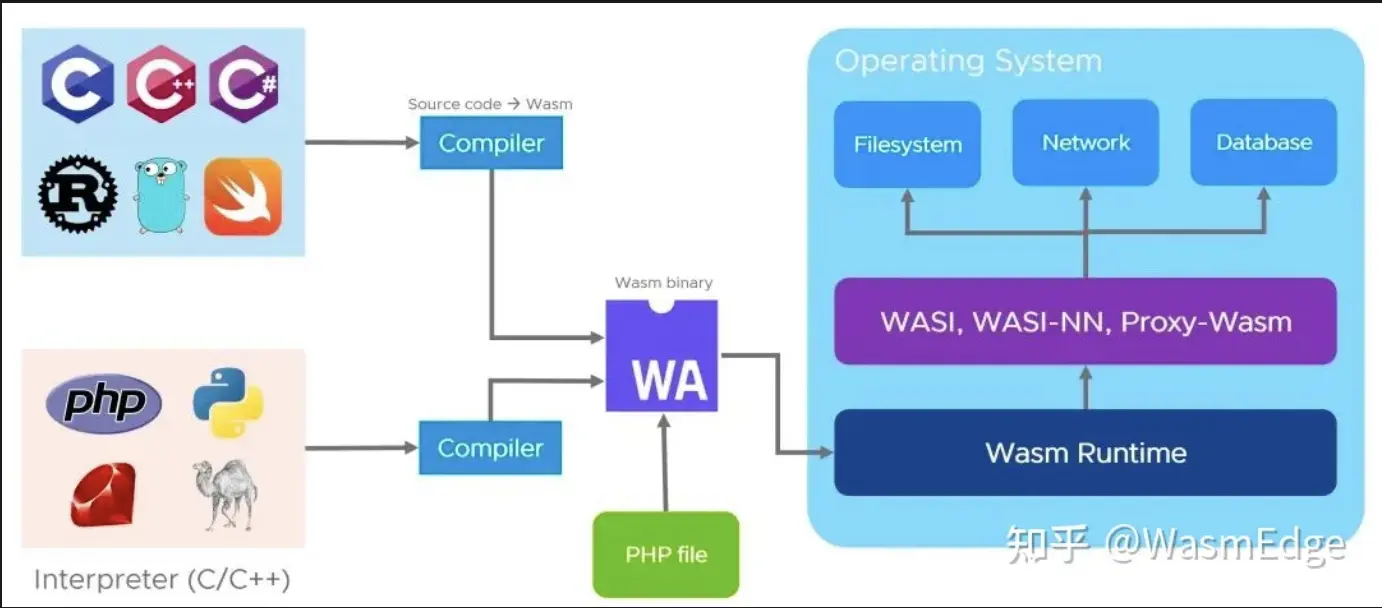
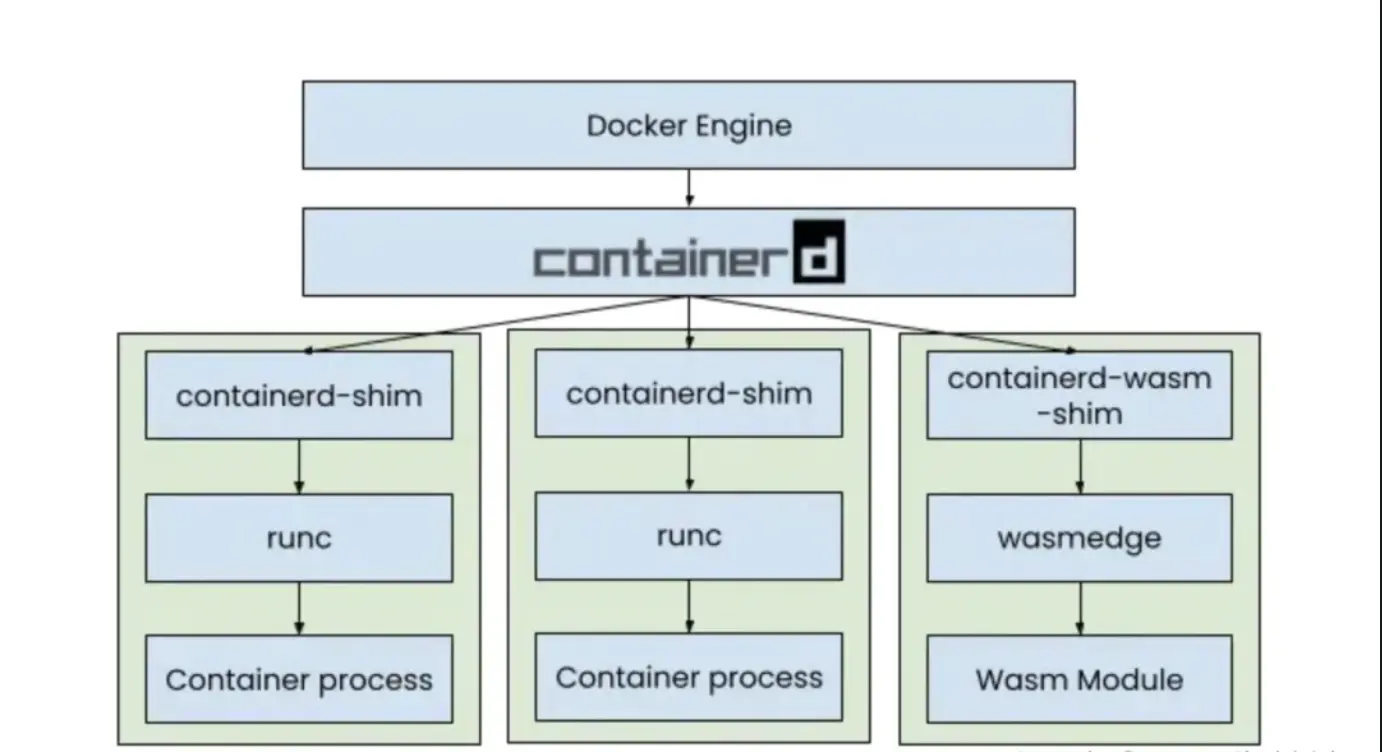
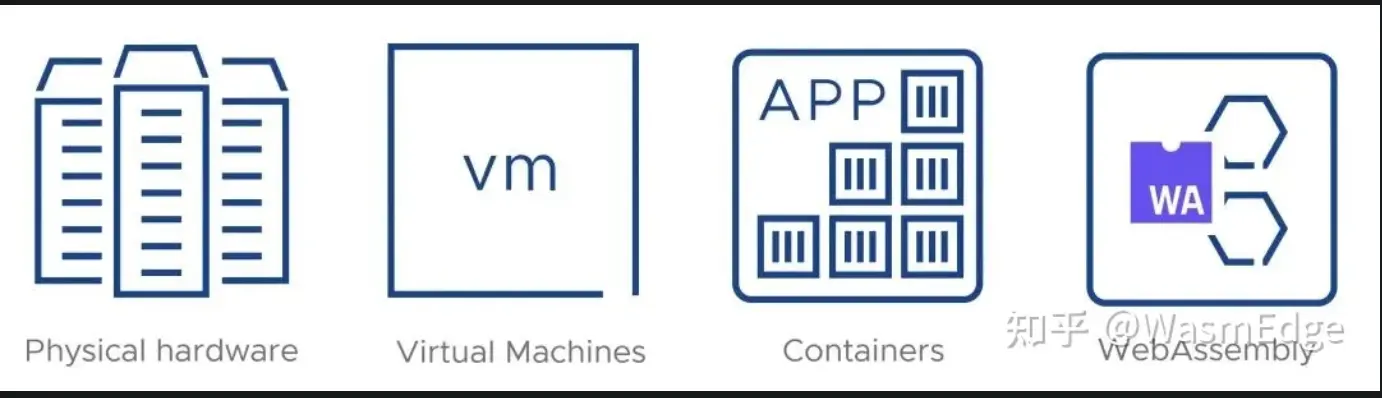
阿里云
开源mirror网址

阿里云专有网络
- 专有网络是您独有的云上虚拟网络,您可以将云资源部署在您自定义的专有网络中.
- 云资源不可以直接部署在专有网络中,必须属于专有网络内的一个交换机(子网)内.
- 目前专有网络必须手动开启ipv6功能
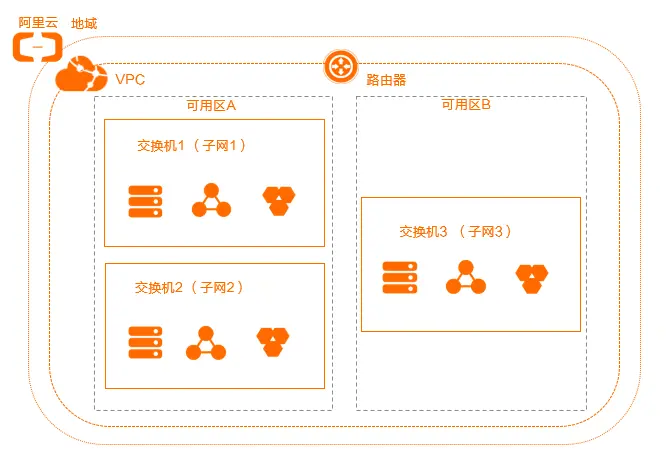
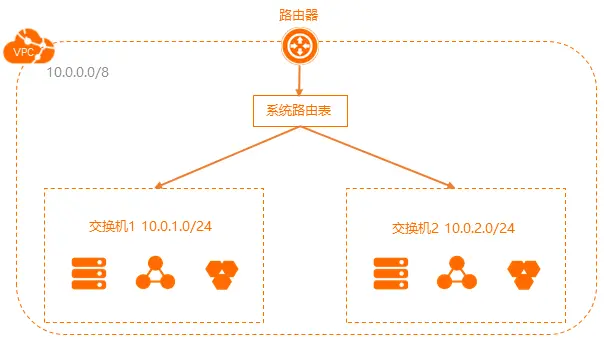
阿里云支持ipv6
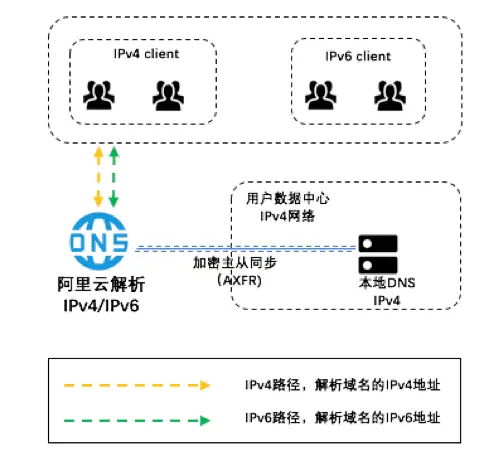
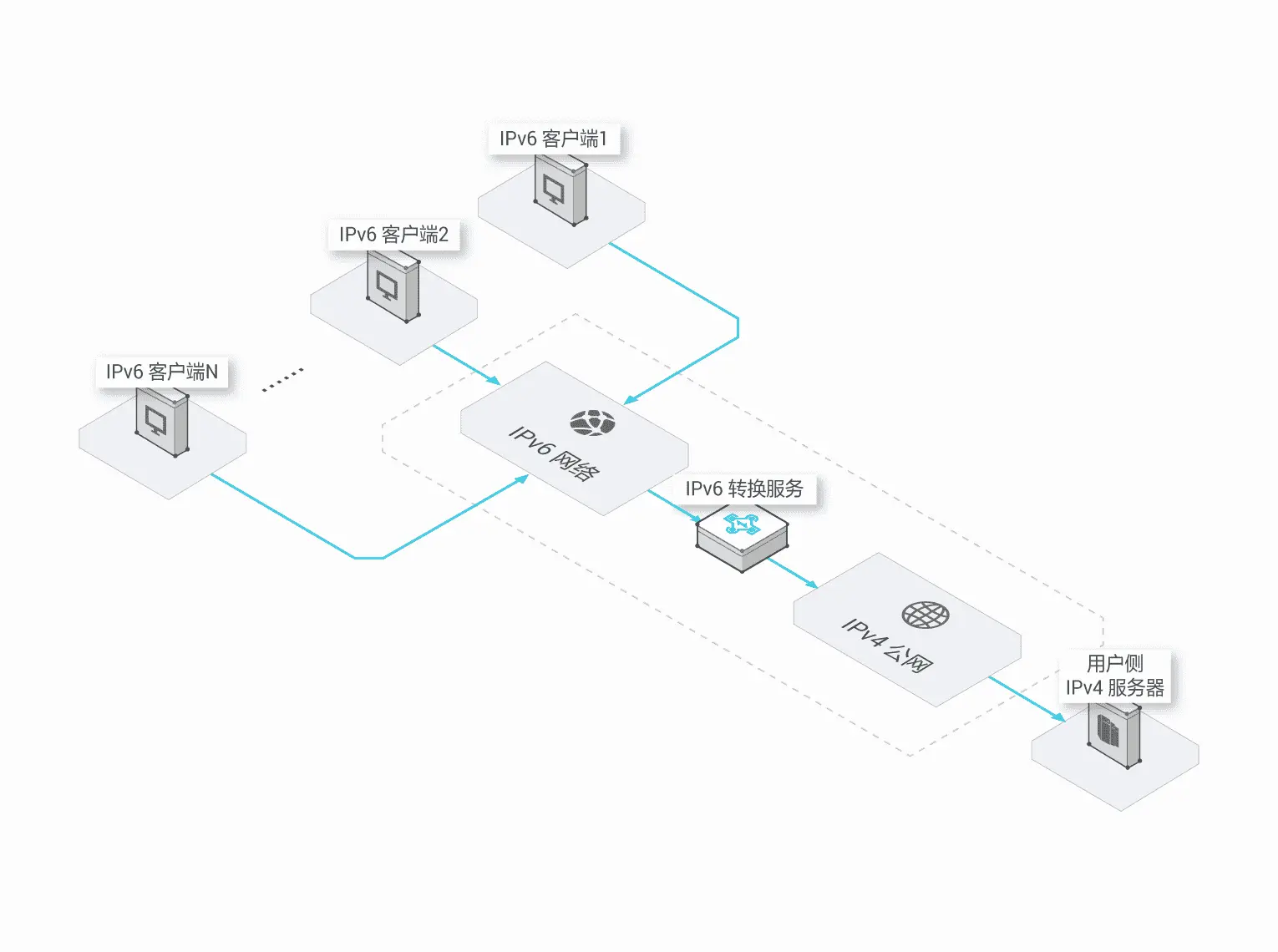
阿里云ECS配置ipv6

-
VPC和ECS支持双栈后,ECS上会分配到IPv6地址,部署在ECS上的系统需要主动访问Internet的IPv6系统,这就需要配合IPv6网关使用
-
开通IPv6网关后,通过配置IPv6网关规则,允许VPC内指定IPv6地址访问公网,则指定的IPv6 ECS就可以主动访问公网了
-
如不配置IPv6网关规则,默认ECS分配的IPv6地址只能在VPC内部通信
-
安全组,源:“::/0“表示允许ipv6,源:“0.0.0.0/0“表示允许ipv4,要支持双栈就要同端口开放两个规则
阿里云邮箱 默认开通
| 服务器名称 | 服务器地址 | 服务器端口号(非加密) | 服务器端口号(SSL加密) |
|---|---|---|---|
| POP3 | pop3.aliyun.com | 110 | 995 |
| SMTP | smtp.aliyun.com | 25 | 465 |
| IMAP | imap.aliyun.com | 143 | 993 |
subject不能太随意了,否则会认为垃圾邮件,被系统退信的! 发件邮箱最好加入白名单
杂项
- 阿里云:云市场,买各种api接口
- 阿里云:云效代码托管,可能快速导入其他的repos
- 钉钉开放平台
- 弹性云手机-远程虚拟手机,可以批量安装测试
- 批量安装设置服务器
- 设置一台机器为种子,进行各种配置和安装
- 把种子机器导出为镜像
- 购买其他实例,选择从指定镜像初始化
- 号码隐私保护服务-真实号码绑定虚拟号码,其他人可用虚拟号码转到真实号码
阿里云ECS高危漏洞问题处理
# 升级系统及软件就能解决多数
yum -y upgrade
服务器vi乱码
cd ~
vi .vimrc
set fileencodings=utf-8,ucs-bom,gb18030,gbk,gb2312,cp936
set termencoding=utf-8
set encoding=utf-8
set number
filetype on
syntax on
腾讯
微信公众号
-
清除微信公众号
找到 文件传输助手, 发送 debugtbs.qq.com, 打开链接,清楚TBS内核,success

-
头像300*300像素左右
-
页面模板位置

信息
医学
常见病
呼吸系统疾病
普通感冒
- 核心症状
鼻塞、流清水样鼻涕(后期可转为黄稠涕)、咽痛、轻度干咳或伴少量白痰,可伴低热(37.5-38℃)、头痛、乏力,病程3-7天,自限性。
- 详细原因
以病毒感染为主,鼻病毒占30%-50%,其次为冠状病毒(非新冠)、腺病毒等; 少数合并细菌感染。诱因包括受凉、过度劳累、熬夜等导致免疫力下降,病毒通过飞沫或接触传播侵入呼吸道。 易患人群为儿童、老年人、体质虚弱者及长期处于密闭环境人群。
- 发病原理
病毒侵入呼吸道黏膜上皮细胞并复制,导致上皮细胞损伤、脱落,黏膜完整性破坏;引发局部炎症反应,刺激血管扩张、腺体分泌亢进,导致鼻塞、流涕;炎症因子释放引发咽痛、咳嗽;病毒毒素入血可引起低热、乏力等全身症状。人体免疫系统可逐渐清除病毒,故多数呈自限性。
- 治疗原理
以支持治疗和对症治疗为主,无需常规使用抗生素(仅合并细菌感染时用)。
- 支持治疗
每日饮水1500-2000ml、保证睡眠、清淡饮食,增强免疫力;
- 对症治疗
生理盐水洗鼻缓解鼻塞,润喉片或淡盐水漱口改善咽痛,发热>38.5℃用对乙酰氨基酚/布洛芬,干咳短期用右美沙芬;
- 抗病毒治疗
仅高危人群早期(48小时内)可酌情使用利巴韦林等,多数患者无需抗病毒治疗。
急性扁桃体炎
- 核心症状
咽痛剧烈,吞咽时加重且放射至耳部;扁桃体红肿,化脓性者隐窝内可见黄白色脓栓,伴高热(38.5℃以上)、畏寒、乏力、头痛,儿童可流涎、拒食、哭闹,病程7-10天。
- 详细原因
主要致病菌为A组溶血性链球菌,其次为肺炎链球菌等;少数由腺病毒等病毒感染引发。诱因包括口腔卫生差、受凉、上呼吸道感染迁延等。易患人群为儿童、青少年,春秋季气候多变时高发。
- 发病原理
病原体通过飞沫或直接接触传播,侵入扁桃体隐窝后大量繁殖,引发急性化脓性炎症;炎症导致扁桃体充血水肿,隐窝内黏膜坏死脱落与渗出物形成脓栓;细菌毒素入血引发全身中毒症状;扁桃体肿大压迫周围组织,导致咽痛放射至耳部,吞咽时疼痛加重。治疗不彻底可转为慢性,或诱发风湿热、急性肾小球肾炎等并发症。
- 治疗原理
以抗感染治疗为主,兼顾对症治疗。
- 抗感染治疗
细菌性感染首选青霉素类,过敏者选头孢类或大环内酯类,足疗程(7-10天)使用;病毒性感染无需抗生素;
- 对症治疗
高热用布洛芬/对乙酰氨基酚,咽痛用西地碘含片或复方硼砂溶液漱口;
- 局部治疗
化脓严重者可进行扁桃体隐窝冲洗;
- 手术治疗
反复发作者(每年≥3次)、过度肥大影响呼吸吞咽者或引发并发症者,可行扁桃体切除术。
急性支气管炎
- 核心症状
初期为刺激性干咳,后期咳黄白色黏痰或脓痰,伴胸闷、气短、胸骨后隐痛,可伴低热(37.5-38.5℃)、乏力,病程1-2周。
- 详细原因
病毒感染占多数,如流感病毒、鼻病毒等;细菌感染多为继发,常见致病菌为肺炎链球菌等。诱因包括上呼吸道感染未控制、吸烟、空气污染、冷空气刺激等。易患人群为老年人、婴幼儿、长期吸烟人群及慢性基础病患者。
- 发病原理
病原体侵袭支气管黏膜,引发黏膜充血水肿、纤毛上皮细胞损伤脱落,纤毛运动减弱,黏液分泌亢进且排出受阻,形成黏痰或脓痰;炎症刺激支气管平滑肌痉挛,导致气道狭窄引发胸闷、气短;炎症因子刺激气道神经末梢引发咳嗽;炎症累及周围组织可出现胸骨后隐痛;全身症状多由病毒毒素或细菌感染引发的全身炎症反应导致。
- 治疗原理
对症治疗为主,合并细菌感染时抗感染治疗。
- 止咳祛痰
痰多者用氨溴索/乙酰半胱氨酸,干咳无痰者用右美沙芬/喷托维林;
- 抗感染治疗
细菌感染证据明确时,选用头孢类、大环内酯类或喹诺酮类(18岁以下禁用喹诺酮类);
- 解痉平喘
胸闷喘息者用沙丁胺醇气雾剂;
- 辅助治疗
戒烟、避免刺激物,多喝水、保证休息。
社区获得性肺炎
- 核心症状
高热(38.5℃以上)、寒战,咳嗽(初期干咳,后期咳黄脓痰,肺炎链球菌感染可咳铁锈色痰),胸痛(深呼吸、咳嗽时加重),呼吸困难,可伴乏力、食欲减退、恶心呕吐。重症者可出现意识模糊、血压下降(感染性休克)。
- 详细原因
主要致病菌为肺炎链球菌(占40%-70%),其次为支原体、衣原体等;病毒感染也可引发或混合感染。诱因包括免疫力低下、受凉、劳累、上呼吸道感染迁延等。病原体通过飞沫吸入肺部,或由上呼吸道感染蔓延引发感染。
- 发病原理
病原体吸入肺泡后,引发局部炎症反应,肺泡毛细血管扩张、通透性增加,肺泡内充满炎性渗出物形成实变灶;渗出物中红细胞破坏后,血红蛋白分解为含铁血黄素,使痰液呈铁锈色;肺泡实变导致肺换气功能障碍,引发呼吸困难;炎症刺激胸膜导致胸痛;病原体毒素入血引发全身中毒症状;重症者可引发感染性休克、呼吸衰竭。
- 治疗原理
以抗感染治疗为核心,兼顾对症支持治疗。
- 抗感染治疗
肺炎链球菌感染首选青霉素类,过敏者用头孢类;支原体、衣原体感染首选大环内酯类或喹诺酮类;病毒感染可选用奥司他韦等;足疗程使用(细菌性7-14天,支原体10-14天);
- 对症治疗
高热用退热药物或物理降温,咳嗽咳痰用氨溴索,胸痛明显用布洛芬;
- 支持治疗
卧床休息、清淡高蛋白饮食,呼吸困难者给予氧疗,脱水者静脉补液;
- 并发症治疗
感染性休克时,快速补液、使用血管活性药物维持血压。
支气管哮喘
- 核心症状
反复发作的喘息、胸闷、咳嗽,夜间或凌晨加重,接触花粉、尘螨等诱因后发作;发作时双肺可闻及哮鸣音,缓解后症状可完全消失。重症哮喘可出现呼吸困难、发绀,甚至呼吸衰竭。
- 详细原因
遗传与环境因素共同作用。遗传因素 过敏体质基因,父母有过敏性疾病者,子女发病风险升高2-3倍;环境因素 过敏原暴露、空气污染、呼吸道感染、冷空气刺激等。此外,长期吸烟、服用阿司匹林等也可能诱发。
- 发病原理
属于气道慢性炎症性疾病,核心机制为免疫异常介导的气道高反应性。过敏原进入体内后,刺激B细胞产生IgE抗体,使机体处于致敏状态;再次接触过敏原时,触发肥大细胞等脱颗粒,释放组胺、白三烯等炎症介质;炎症介质导致气道平滑肌痉挛、黏膜充血水肿等,引发气道狭窄,出现喘息、胸闷、咳嗽;长期反复发作可导致气道结构重塑,使气道狭窄不可逆。
- 治疗原理
以控制炎症、缓解症状、预防发作为核心,分急性发作期与慢性持续期治疗。
- 急性发作期
短效β₂受体激动剂(沙丁胺醇气雾剂)快速舒张气道;病情较重者联合吸入性糖皮质激素雾化吸入;严重发作时静脉使用糖皮质激素、氨茶碱;
- 慢性持续期
吸入性糖皮质激素(布地奈德福莫特罗粉吸入剂)为首选,联合长效β₂受体激动剂增强效果,白三烯调节剂适用于过敏原/运动诱发的哮喘;
- 预防措施
规避过敏原,规律用药,接种流感疫苗,加强体育锻炼。
慢性阻塞性肺疾病(COPD)
- 核心症状
长期慢性咳嗽(晨起明显,咳白色黏液或泡沫痰),气短或呼吸困难(早期活动后出现,后期静息时也可出现),喘息、胸闷,冬季或受凉后易急性加重;病程迁延,逐渐进展,可伴体重下降、食欲减退。晚期可出现肺心病、呼吸衰竭。
- 详细原因
主要危险因素为长期吸烟(占80%-90%),其次为空气污染、职业暴露、反复呼吸道感染等;遗传因素(α₁-抗胰蛋白酶缺乏)为罕见原因。易患人群为40岁以上中老年人、长期吸烟人群、长期处于污染环境者。
- 发病原理
核心病理改变为气道慢性炎症与气道结构重塑,导致不可逆性气道狭窄。刺激物持续损伤气道黏膜,引发慢性炎症,导致黏膜充血水肿、黏液分泌亢进,形成慢性咳嗽、咳痰;长期炎症导致气道平滑肌增生、纤维化,气道管腔狭窄,出现气短、呼吸困难;炎症累及肺实质,形成肺气肿,进一步加重通气功能障碍;长期缺氧可导致肺动脉高压,引发肺心病。
- 治疗原理
以戒烟为核心,长期综合治疗。
- 病因治疗
戒烟,避免接触刺激物;
- 支气管舒张剂
长效抗胆碱能药物(噻托溴铵)、长效β₂受体激动剂,急性加重期加用短效制剂;
- 吸入性糖皮质激素
仅用于反复急性加重者,与长效支气管舒张剂联合使用;
- 氧疗
重症患者给予长期家庭氧疗(1-2L/min);
- 抗感染治疗
急性加重期选用头孢类、喹诺酮类抗生素;
- 康复治疗
进行呼吸功能锻炼、适度运动;
- 并发症治疗
出现肺心病、呼吸衰竭时,给予利尿、扩血管、机械通气等治疗。
过敏性鼻炎
- 核心症状
鼻痒、阵发性打喷嚏(每次3个以上)、流清水样鼻涕、鼻塞,部分伴眼痒、流泪、嗅觉减退;春秋季或接触过敏原后发作,症状持续数天至数周。
- 详细原因
遗传与环境因素共同作用。遗传因素 过敏体质,父母有过敏性疾病者,子女发病风险升高;环境因素 过敏原暴露、空气污染、冷空气刺激等。此外,过度清洁、长期使用抗生素等可能导致免疫功能紊乱,增加发病风险。
- 发病原理
属于IgE介导的Ⅰ型变态反应。过敏原进入鼻腔后,激活B细胞产生IgE抗体,使机体致敏;再次接触过敏原时,触发肥大细胞等脱颗粒,释放组胺等炎症介质;组胺导致鼻黏膜血管扩张、通透性增加,引发鼻塞、流清涕;刺激神经末梢引发鼻痒、打喷嚏;炎症介质刺激眼结膜导致眼痒、流泪;长期反复发作可导致鼻黏膜增生肥厚,加重鼻塞与嗅觉减退。
- 治疗原理
以规避过敏原为基础,对症治疗为主,必要时免疫治疗。
规避过敏原
明确过敏原者避免接触,如花粉季佩戴口罩、尘螨过敏者定期清洁家居; 对症治疗 抗组胺药(氯雷他定、西替利嗪)缓解鼻痒、打喷嚏,鼻用糖皮质激素(糠酸莫米松)缓解所有症状,鼻用减充血剂(盐酸羟甲唑啉)短期使用缓解鼻塞,生理盐水洗鼻清除过敏原与分泌物; 免疫治疗 适用于过敏原明确、常规治疗效果不佳者,通过逐渐增加过敏原剂量,使机体产生耐受。
消化系统疾病
急性胃肠炎
- 核心症状
突发腹痛(阵发性绞痛,多见于上腹部或脐周)、腹泻(每日数次至数十次,水样便或稀便,可带黏液)、恶心呕吐(严重时可呕吐胆汁);严重者可出现脱水(口干、尿少等)、电解质紊乱(乏力、肌肉痉挛),少数伴低热(37.5-38.5℃)。
- 详细原因
分为感染性与非感染性两类。感染性 病毒(诺如、轮状病毒等)、细菌(沙门氏菌、大肠杆菌等,多因食用变质食物引发);非感染性 暴饮暴食、食用刺激食物、酗酒、服用某些药物等,腹部受凉、精神紧张也可诱发。感染性胃肠炎可通过粪-口途径传播,诺如病毒传染性极强。
- 发病原理
感染性胃肠炎 病原体侵入胃肠黏膜后复制或繁殖,释放毒素刺激黏膜,导致黏膜充血水肿、糜烂,肠道吸收功能下降且蠕动加快,引发腹泻;毒素刺激胃黏膜引发恶心呕吐;大量水分电解质丢失导致脱水、电解质紊乱。非感染性胃肠炎 刺激物直接破坏胃肠黏膜屏障,引发炎症,胃肠蠕动紊乱,导致腹痛、腹泻、恶心呕吐,一般无发热。
- 治疗原理
以补液、对症治疗为主,感染性合并细菌感染时加用抗感染治疗。①补液治疗 轻度脱水者口服补液盐(每日1000-2000ml),严重脱水者静脉补液;②对症治疗 蒙脱石散(吸附毒素、保护黏膜)、洛哌丁胺(抑制肠道蠕动,急性感染性腹泻早期慎用)止泻,甲氧氯普胺止吐,山莨菪碱缓解腹痛;③抗感染治疗 细菌感染证据明确时,选用喹诺酮类(18岁以下禁用)、头孢类抗生素;④辅助治疗 卧床休息,急性期禁食或清淡流质饮食,腹部保暖。
慢性胃炎
- 核心症状
上腹部隐痛、胀痛、灼痛(进食后或空腹时加重,部分疼痛无规律),腹胀、嗳气、反酸、烧心,食欲减退;部分患者无明显症状,仅胃镜检查时发现;病程迁延,反复发作者可出现消瘦、乏力、贫血。
- 详细原因
最主要原因是幽门螺杆菌(Hp)感染(占70%-80%),可通过口-口、粪-口途径传播;其次为理化刺激(饮食不规律、吸烟饮酒、服用非甾体抗炎药等);此外,精神压力大、自身免疫因素也可引发。易患人群为中老年人、长期饮食不规律者、Hp感染者。
- 发病原理
Hp感染相关胃炎 Hp定植于胃黏膜,分泌尿素酶产生氨保护自身,释放毒素损伤胃黏膜上皮细胞,引发慢性炎症;长期炎症导致胃黏膜充血水肿、糜烂,甚至肠上皮化生、不典型增生;炎症刺激神经末梢引发腹痛,黏膜屏障受损引发反酸、烧心,胃肠动力紊乱导致腹胀、嗳气。理化刺激相关胃炎 刺激物直接破坏胃黏膜屏障,引发炎症,胃酸和胃蛋白酶对黏膜产生“自身消化”。自身免疫性胃炎 自身抗体攻击胃壁细胞,导致胃酸分泌不足,引发巨幼细胞性贫血。
- 治疗原理
去除病因,对症治疗,Hp感染者根除治疗。①根除Hp治疗 四联疗法(质子泵抑制剂+两种抗生素+铋剂),疗程10-14天,停药4周后复查;②对症治疗 抑酸药(质子泵抑制剂、H₂受体拮抗剂)抑制胃酸,胃黏膜保护剂(硫糖铝、枸橼酸铋钾)促进修复,促动力药(多潘立酮)缓解腹胀;③去除病因 规律饮食,戒烟戒酒,避免刺激物,停用损伤胃黏膜药物;④自身免疫性胃炎 补充维生素B₁₂纠正贫血,酌情使用稀盐酸。
消化性溃疡(胃溃疡/十二指肠溃疡)
- 核心症状
胃溃疡 餐后半小时至1小时上腹痛(餐后痛),隐痛、胀痛或灼痛,位于上腹部正中或偏左,进食后加重,空腹时缓解;十二指肠溃疡 空腹时或夜间上腹痛(空腹痛、夜间痛),进食后缓解,疼痛位于上腹部偏右,更剧烈且有节律性;两者均可能伴反酸、烧心、嗳气、腹胀,严重时可出现出血、穿孔、幽门梗阻等并发症。
- 详细原因
核心病因是Hp感染(占90%以上),其次为长期服用非甾体抗炎药;此外,遗传因素、精神压力大、吸烟饮酒等均为诱因。胃溃疡多见于中老年人,十二指肠溃疡多见于青壮年(20-40岁),男性发病率高于女性。
- 发病原理
核心机制为“攻击因子增强”与“防御因子减弱”失衡。攻击因子 胃酸、胃蛋白酶分泌过多,Hp感染,理化刺激;防御因子 胃黏膜屏障、前列腺素、胃黏膜血流量。当攻击因子超过防御因子时,胃酸和胃蛋白酶对黏膜产生“自身消化”,形成溃疡;Hp感染可导致溃疡反复发作;溃疡侵蚀血管可出血,穿透浆膜层可穿孔,周围组织水肿或瘢痕收缩可导致幽门梗阻。
- 治疗原理
根除Hp、抑制胃酸、保护黏膜,预防并发症。①根除Hp治疗 四联疗法,疗程10-14天;②抑酸治疗 质子泵抑制剂(奥美拉唑等)强效抑酸,疗程胃溃疡6-8周,十二指肠溃疡4-6周;H₂受体拮抗剂适用于轻度溃疡;③胃黏膜保护剂 枸橼酸铋钾、硫糖铝等保护溃疡面,促进修复;④对症治疗 反酸者加用促动力药,疼痛明显者短期用解痉药;⑤生活调理 规律饮食,戒烟戒酒,避免刺激物;⑥并发症治疗 出血者禁食、止血,必要时胃镜下止血;穿孔者立即手术;幽门梗阻者禁食、胃肠减压,严重者手术。
功能性消化不良
- 核心症状
上腹部胀满、嗳气、反酸、烧心,食欲减退,进食后腹胀加重,可伴轻度无规律上腹痛;胃镜等检查无器质性病变;症状与精神压力、饮食因素密切相关,病程超过6个月且反复发作。
- 详细原因
病因尚未完全明确,可能与胃肠动力障碍、内脏高敏感性、精神心理因素、饮食因素、肠道菌群失调相关。易患人群为中青年、精神压力大、饮食不规律者。
- 发病原理
核心为胃肠功能紊乱与脑-肠轴调节异常。胃肠动力障碍导致胃排空延迟,食物发酵产气,引发腹胀、嗳气;内脏高敏感性使胃肠对轻微刺激产生过度反应,引发腹痛、腹胀;精神压力通过脑-肠轴影响胃肠功能,加重内脏高敏感性,形成恶性循环;肠道菌群失调导致产气增加,加重腹胀、食欲减退。
- 治疗原理
以对症治疗为主,结合生活调理与心理调节。①促动力治疗 多潘立酮、莫沙必利等促进胃肠蠕动;②调节肠道菌群 益生菌(布拉氏酵母菌等)改善微生态;③抑酸对症 反酸、烧心明显者短期使用质子泵抑制剂或H₂受体拮抗剂;④助消化 乳酶生、健胃消食片改善食欲;⑤心理调节 缓解精神压力,必要时服用抗焦虑药;⑥生活调理 规律饮食(少食多餐),低脂清淡饮食,适度运动,保证睡眠。
便秘
- 核心症状
排便次数减少(每周<3次),粪便干结(羊粪状、球状),排便费力(时间>10分钟,需用力),排便不尽感;慢性便秘病程超过6个月,可伴腹胀、腹痛、食欲减退;长期便秘可引发痔疮、肛裂等并发症。
- 详细原因
分为器质性与功能性两类。器质性 肠道疾病(肠梗阻、肿瘤等)、内分泌疾病(甲状腺功能减退等)、神经系统疾病(帕金森病等);功能性 膳食纤维摄入不足、饮水少、久坐不动、排便习惯不良、药物因素、精神压力大。功能性便秘占80%以上,多见于中青年、久坐人群、老年人。
- 发病原理
器质性便秘 肠道狭窄导致粪便无法通过,代谢减慢或神经病变导致胃肠蠕动减弱,痔疮肛裂患者因疼痛憋便引发便秘。功能性便秘 膳食纤维不足、饮水少导致粪便干结,久坐缺乏运动导致蠕动动力不足,憋便导致排便反射减弱,长期使用刺激性泻药导致肠道依赖。
- 治疗原理
先排除器质性疾病,再对症治疗,以生活调理为基础。①生活调理 每日摄入25-30g膳食纤维,饮水1500-2000ml,适度运动,养成晨起或餐后排便习惯(时间控制在5-10分钟);②药物治疗 容积性泻药(聚乙二醇等)温和软化粪便,刺激性泻药短期使用(≤7天),润滑性泻药(开塞露)适用于急性便秘;③治疗原发病 器质性便秘需治疗原发病,肛肠疾病患者先缓解疼痛再调整排便习惯。
急性胆囊炎
- 核心症状
右上腹剧烈阵发性绞痛,可放射至右肩、背部,进食油腻食物后诱发或加重;伴恶心呕吐(严重时呕吐胆汁)、发热(38.5-39℃,高热提示感染严重);查体右上腹有压痛、反跳痛,Murphy征阳性;严重者可出现胆囊坏死、穿孔,引发弥漫性腹膜炎。
- 详细原因
最主要原因是胆囊结石堵塞胆囊管(占90%以上),其次为细菌感染(大肠杆菌等);诱因包括进食高脂高胆固醇食物、暴饮暴食、饮酒等。易患人群为40岁以上女性、肥胖人群、长期高脂饮食者、有胆囊结石病史者。
- 发病原理
胆囊结石堵塞胆囊管→胆汁排出受阻,胆囊内压力升高→胆囊黏膜充血水肿(急性单纯性胆囊炎);炎症加重可发展为急性化脓性、坏疽性胆囊炎,严重时胆囊穿孔,胆汁流入腹腔引发弥漫性腹膜炎;细菌在积聚胆汁中繁殖,释放毒素入血,引发全身发热、畏寒;胆囊炎症刺激周围神经,引发右上腹疼痛并放射至右肩背部,进食油腻食物后胆囊收缩,加重疼痛。
- 治疗原理
禁食禁水、抗感染、解痉止痛,必要时手术治疗。①禁食禁水 减少胆汁分泌,缓解后过渡到清淡流质饮食;②抗感染治疗 选用头孢类+甲硝唑等抗生素,静脉输注;③解痉止痛 山莨菪碱、阿托品缓解痉挛,疼痛剧烈者可使用哌替啶;④对症支持 静脉补液,高热者退热;⑤手术治疗 腹腔镜胆囊切除术首选,适用于结石反复发作、胆囊坏死穿孔等情况,病情稳定者可先保守治疗,炎症控制后1-3个月手术,危重者需紧急手术。
非酒精性脂肪肝
- 核心症状
多数患者无明显症状,仅体检时发现肝大、肝功能异常(转氨酶轻度升高);少数患者可出现右上腹隐痛、胀痛、乏力、食欲减退、体重增加;病情进展至脂肪性肝炎时,可出现黄疸;晚期可进展为肝硬化,出现腹水、肝性脑病等并发症。
- 详细原因
核心危险因素为肥胖(尤其是腹型肥胖)、2型糖尿病、高脂血症、久坐不动、长期高脂低糖饮食;其他因素包括快速减重、营养不良、长期服用某些药物、遗传因素。无饮酒史或饮酒量极少,排除其他肝病。
- 发病原理
核心为脂肪代谢紊乱,导致甘油三酯在肝细胞内异常堆积(肝细胞脂肪变性)。肥胖、2型糖尿病患者存在胰岛素抵抗,导致肝脏脂肪合成增加、分解减少,外周脂肪组织动员增加,大量脂肪酸进入肝脏,超出代谢能力而沉积;长期高脂饮食也可增加肝脏脂肪沉积;肝细胞内脂肪过度堆积,引发氧化应激和炎症反应,导致肝细胞损伤(脂肪性肝炎);长期炎症可导致肝纤维化,逐渐进展为肝硬化,严重者可引发肝功能衰竭、肝癌。
- 治疗原理
以生活方式干预为核心,控制病因,延缓病情进展。①病因治疗 控制体重(每周减重0.5-1kg,减重5%-10%可显著改善),控制血糖(二甲双胍等)、血脂(贝特类药物);②饮食调理 低脂低糖饮食,增加膳食纤维和优质蛋白摄入,避免快速减重;③运动调理 规律有氧运动(每周150分钟以上),促进脂肪代谢;④保肝治疗 转氨酶升高或脂肪性肝炎患者,可使用多烯磷脂酰胆碱等保肝药物;⑤定期监测 每6-12个月复查肝功能、肝脏超声等,进展为肝硬化者按规范治疗。
痔疮
- 核心症状
便血(鲜红色,便后滴血或手纸带血,血液与粪便不混合),肛门瘙痒、疼痛(内痔脱出嵌顿时疼痛剧烈),肛门肿块脱出(内痔Ⅱ度以上可脱出,轻者可自行回纳);分为内痔、外痔、混合痔,久坐、久站、便秘后症状加重。
- 详细原因
核心原因是肛周静脉丛淤血、扩张、迂曲。肛周静脉无静脉瓣,腹压增高(便秘、怀孕等)、久坐久站、辛辣饮食、饮酒等导致静脉丛淤血,逐渐扩张迂曲形成痔核;此外,遗传因素、肛周感染、排便习惯不良也可诱发。易患人群为中老年人、久坐久站人群、孕妇、便秘患者、长期饮酒者。
- 发病原理
肛周静脉丛分为内痔静脉丛和外痔静脉丛,腹压增高或回流受阻时,静脉丛内压力升高,静脉壁扩张迂曲形成痔核;内痔核位于齿状线以上,黏膜脆弱,排便时易破损引发便血,增大后可脱出,嵌顿后引发剧烈疼痛;外痔核位于齿状线以下,易受摩擦刺激,引发瘙痒、疼痛;混合痔为内外痔静脉丛融合形成,兼具两者症状。
- 治疗原理
以保守治疗为主,症状严重者手术治疗。①保守治疗 饮食调理(多吃膳食纤维、多喝水,避免刺激物),生活习惯调整(避免久坐久站,排便时间<5分钟),每日温水坐浴(1-2次,每次15分钟),外用痔疮膏/栓;②手术治疗 适用于痔核脱出无法回纳、大量便血等保守治疗无效者,手术方式包括痔切除术、PPH等;③预防 保持肛周清洁,适度进行提肛运动(每日3-4次,每次10-15分钟)。
心血管系统疾病
原发性高血压
- 核心症状
早期多无症状,仅体检时发现血压升高;血压持续升高(收缩压≥140mmHg和/或舒张压≥90mmHg)后,可出现头晕、头痛(后脑勺胀痛或搏动性头痛)、耳鸣、失眠、乏力、注意力不集中;长期未控制者,可累及心、脑、肾、眼等靶器官,出现胸闷、肢体麻木、蛋白尿、视物模糊等并发症。
- 详细原因
遗传与环境因素共同作用,遗传因素占40%,环境因素占60%。遗传因素 父母均有高血压,子女发病风险升高2-3倍;环境因素 高盐饮食(每日盐摄入>5g)、肥胖、长期熬夜、精神紧张、缺乏运动、吸烟、过量饮酒等;此外,年龄增长、长期服用某些药物也可诱发。原发性高血压占高血压的90%-95%,多见于中老年人。
- 发病原理
核心机制为外周血管阻力增加、血容量增多。高盐饮食导致水钠潴留,血容量增加,血压升高;交感神经兴奋导致心率加快、血管收缩,外周血管阻力增加;长期高血压导致血管壁增厚硬化,血管弹性下降,进一步加重血压升高,形成恶性循环;肾素-血管紧张素-醛固酮系统激活,也会升高血压;肥胖者胰岛素抵抗,通过水钠潴留、血管收缩升高血压。长期高血压可导致靶器官损伤,引发冠心病、脑梗死、高血压肾病等。
- 治疗原理
以控制血压、保护靶器官、预防并发症为核心,长期综合治疗。①生活方式干预 低盐饮食(每日盐摄入<5g),低脂低糖饮食,控制体重(BMI<24kg/m²),规律运动(每周150分钟中等强度有氧运动),戒烟限酒,缓解精神压力,保证每日7-8小时睡眠;②药物治疗 血压≥160/100mmHg或生活方式干预3-6个月未达标者,启动药物治疗,常用钙通道阻滞剂、ARB、ACEI、β受体阻滞剂、利尿剂,优先选择长效制剂,不可自行停药,定期监测血压;③靶器官保护 合并冠心病者加用阿司匹林、他汀类药物;合并肾病者优先选择ACEI/ARB类药物;④定期复查 每3-6个月复查肝肾功能、血脂、心电图。
冠状动脉粥样硬化性心脏病(冠心病)
- 核心症状
心绞痛型 劳累、情绪激动后出现胸骨后压榨性、紧缩性胸痛,可放射至左肩、左臂等,休息3-5分钟后缓解,伴胸闷、气短、出冷汗;心肌梗死型 突发剧烈持久的胸骨后疼痛(>15分钟不缓解),伴濒死感、大汗淋漓等,重症者可出现心律失常、心力衰竭、心源性休克;无症状性心肌缺血型 无明显胸痛,仅体检发现心肌缺血;缺血性心肌病型 长期心肌缺血导致心肌纤维化,出现心悸、气短、下肢水肿等;猝死型 突发心脏骤停,多因严重心律失常引发,48小时内死亡。
- 详细原因
核心病因是冠状动脉粥样硬化,血管内脂质沉积形成粥样硬化斑块,导致冠脉管腔狭窄或闭塞。危险因素包括高血压、高血脂、糖尿病、吸烟、肥胖、缺乏运动、年龄增长、遗传因素等。此外,高同型半胱氨酸血症、长期饮酒也可增加发病风险。
- 发病原理
核心机制是血管内皮损伤与脂质沉积。危险因素损伤冠脉内皮细胞,低密度脂蛋白胆固醇沉积于血管内皮下,被氧化后形成氧化型低密度脂蛋白,被巨噬细胞吞噬形成泡沫细胞,聚集形成脂质条纹,逐渐发展为粥样硬化斑块。斑块增大导致冠脉管腔狭窄,运动时心肌耗氧量增加而供血不足,引发心绞痛;斑块破裂后血小板聚集形成血栓,完全阻塞冠脉管腔,导致急性心肌梗死;长期心肌缺血可导致心力衰竭、心律失常,严重心律失常可引发猝死。
- 治疗原理
以改善心肌供血、减轻心肌耗氧、稳定斑块、预防心肌梗死和猝死为核心。①药物治疗 抗血小板药物(阿司匹林等)预防血栓,他汀类调脂药(阿托伐他汀等)稳定斑块,硝酸酯类药物(硝酸甘油等)扩张冠脉,β受体阻滞剂降低心肌耗氧量,ACEI/ARB改善心肌重构;②介入治疗(PCI) “放支架”,适用于药物治疗无效的心绞痛或急性心肌梗死患者;③手术治疗(CABG) 冠脉搭桥,适用于多支冠脉严重狭窄者;④生活方式干预 低盐低脂饮食,控制体重,规律运动,戒烟限酒,控制血压、血糖、血脂达标;⑤急性心肌梗死急救 卧床休息、吸氧,嚼服阿司匹林+替格瑞洛,尽快行再灌注治疗(12小时内介入或溶栓)。
心力衰竭(心衰)
- 核心症状
左心衰(肺循环淤血) 劳力性呼吸困难、夜间阵发性呼吸困难、端坐呼吸,咳粉红色泡沫样痰(急性左心衰)、乏力、心悸;右心衰(体循环淤血) 下肢水肿(对称性凹陷性)、腹胀、食欲减退、肝大、颈静脉怒张;全心衰 同时出现左、右心衰症状,重症者可出现心源性休克。
- 详细原因
分为原发性与继发性两类。原发性 冠心病、心肌病、高血压性心脏病等;继发性 糖尿病心肌病、肺源性心脏病、药物性心肌损伤等。诱因包括感染(呼吸道感染最常见)、过度劳累、情绪激动、输液过快过多等。易患人群为中老年人、有心血管基础病者、长期控制不佳的高血压/糖尿病患者。
- 发病原理
核心为心肌收缩或舒张功能障碍,导致心脏泵血能力下降,无法满足机体代谢需求,引发淤血和灌注不足。心肌收缩功能障碍由心肌细胞坏死、纤维化导致,心肌舒张功能障碍由心肌肥厚、僵硬度增加导致。心衰发生后,机体启动神经-体液调节,短期可代偿心输出量,长期过度激活会加重心脏负荷,形成恶性循环;同时,心肌重构进一步加剧心脏功能障碍。
- 治疗原理
以减轻心脏负荷、改善心肌功能、抑制神经-体液激活、预防恶化和并发症为核心。①一般治疗 低盐饮食(每日盐<3g),限制液体摄入(重症者每日<1500ml),适度休息,控制体重,预防感染;②药物治疗 利尿剂(呋塞米等)减轻水肿和心脏负荷,RAAS抑制剂(ACEI/ARB/ARNI)改善心功能,β受体阻滞剂改善心肌重构,正性肌力药(地高辛等)增强心肌收缩力;③非药物治疗 心脏再同步化治疗、植入式心脏复律除颤器,终末期心衰可考虑心脏移植;④诱因治疗 控制感染、纠正电解质紊乱、调整输液速度;⑤康复治疗 病情稳定后进行适度运动。
心律失常(以房颤为例)
- 核心症状
房颤(最常见持续性心律失常) 心悸(心跳杂乱无规律)、胸闷、气短、头晕、乏力,部分患者无症状;心室率过快(>150次/分)时,可引发心绞痛、心力衰竭;房颤易形成心房血栓,血栓脱落可导致脑梗死、肺栓塞等严重并发症。其他常见心律失常 室性早搏(心脏“咯噔”一下,伴停顿感)、房性早搏(轻微心悸)、窦性心动过速(心率>100次/分,伴心悸)、窦性心动过缓(心率<60次/分,伴头晕)。
- 详细原因
房颤常见病因 冠心病、高血压性心脏病、心力衰竭等;其他原因 饮酒、吸烟、肥胖、睡眠呼吸暂停综合征等;孤立性房颤多见于中青年。其他心律失常 室性早搏常见于冠心病、心肌病,也可见于健康人(熬夜、劳累诱发);窦性心动过速多由贫血、甲亢、感染引发;窦性心动过缓可见于老年人、甲状腺功能减退等。
- 发病原理
核心是心脏起搏或传导功能异常。房颤 心房肌细胞电活动紊乱,多个异位起搏点异常兴奋,导致心房快速无序颤动,心房血液淤积易形成血栓,房室结传导部分电信号,导致心室率绝对不规则,心输出量下降。室性早搏 心室肌细胞提前发出电信号,引发心脏提前收缩,随后出现代偿间歇。窦性心动过速 窦房结起搏频率加快,多因交感神经兴奋导致。窦性心动过缓 窦房结起搏频率减慢或房室传导阻滞,导致心室率减慢,脑供血不足引发头晕。
- 治疗原理
根据类型、症状严重程度及病因,采取对症治疗,预防并发症。①房颤治疗 控制心室率(β受体阻滞剂、地高辛),转复窦性心律(药物或电转复),抗凝治疗(华法林、利伐沙班),非药物治疗(射频消融术、左心耳封堵术);②室性/房性早搏 无症状者无需治疗,去除诱因,症状明显者用抗心律失常药;③窦性心动过速 治疗原发病,用β受体阻滞剂减慢心率;④窦性心动过缓 心率<50次/分或伴头晕者,用阿托品提升心率,严重房室传导阻滞者植入心脏起搏器;⑤通用原则 治疗原发病,纠正电解质紊乱,避免使用致心律失常药物,定期复查心电图。
神经系统疾病
脑梗死(缺血性脑卒中)
- 核心症状
突发肢体偏瘫、偏身感觉障碍、同向性偏盲、言语障碍、头晕、头痛、饮水呛咳、吞咽困难,严重者可出现意识模糊、昏迷;症状多为突发且持续存在,部分患者可出现短暂性脑缺血发作(TIA,症状持续<24小时缓解,为脑梗死预警信号)。
- 详细原因
核心病因是动脉粥样硬化,其他病因 房颤(心源性栓塞)、颈动脉夹层、小血管病变、血液高凝状态等。危险因素与冠心病相似 高血压(最主要)、高血脂、糖尿病、吸烟、肥胖等。诱因包括 劳累、情绪激动、熬夜、受凉、脱水。
- 发病原理
脑部血液供应障碍,导致脑组织缺血、缺氧、坏死。动脉粥样硬化型 脑动脉斑块增大或破裂形成血栓,阻塞血管;心源性栓塞型 房颤等导致的心房血栓脱落,阻塞脑动脉;小血管病变型 长期高血压、糖尿病导致脑小动脉狭窄闭塞,引发腔隙性脑梗死。脑组织缺血后,核心区域迅速坏死,周围形成缺血半暗带,若及时恢复供血可减轻神经功能缺损,缺血超过6小时则半暗带脑组织不可逆坏死。
- 治疗原理
以尽早恢复脑部供血、挽救缺血半暗带、减轻神经功能缺损、预防复发为核心。①急性期治疗(发病4.5-6小时内) 静脉溶栓治疗(rtPA)、动脉取栓术;②急性期支持治疗 吸氧、监测生命体征,维持血压稳定,纠正水、电解质紊乱,预防感染、应激性溃疡;③恢复期治疗 抗血小板治疗(阿司匹林、氯吡格雷)、他汀类调脂药,控制危险因素,尽早启动康复治疗;④预防复发 长期服用抗血小板药和他汀类药物,控制基础病,戒烟限酒,规律运动,定期复查颈动脉超声。
脑出血(出血性脑卒中)
- 核心症状
突发剧烈头痛、喷射性呕吐(颅内压升高)、肢体偏瘫、偏身感觉障碍、言语障碍、意识模糊、昏迷,部分患者可出现癫痫发作;症状多在活动中或情绪激动时突发,进展迅速,重症者可短时间内出现脑疝(危及生命)。常见出血部位 基底节区(最常见,表现为偏瘫、偏盲)、脑干(病情危重)、小脑(表现为头晕、走路不稳)。
- 详细原因
最主要原因是高血压合并细小动脉硬化,其他原因 脑动静脉畸形、颅内动脉瘤、淀粉样脑血管病、凝血功能障碍、外伤。危险因素 未控制的高血压、吸烟、酗酒、情绪激动、剧烈运动、长期服用抗凝/抗血小板药物。易患人群为中老年人、高血压控制不佳者、长期饮酒者。
- 发病原理
长期高血压导致脑内细小动脉壁玻璃样变、纤维化,血管壁弹性下降、脆性增加;血压突然升高时,脆弱血管壁破裂,血液溢出到脑组织内形成血肿;血肿压迫周围脑组织,导致脑水肿、颅内压升高,引发头痛、呕吐、意识障碍;血肿破坏脑组织功能区,导致神经功能缺损;血肿持续扩大,颅内压急剧升高,可引发脑疝,导致呼吸心跳停止。
- 治疗原理
以控制颅内压、止血、稳定生命体征、预防并发症为核心,必要时手术治疗。①急性期治疗 绝对卧床休息,保持安静,平稳控制血压(尼卡地平、乌拉地尔),降低颅内压(甘露醇、甘油果糖),止血治疗(氨甲环酸,高血压性脑出血一般不推荐强力止血);②手术治疗 适用于血肿较大、颅内压急剧升高、脑疝风险者,手术方式包括血肿清除术、去骨瓣减压术;③恢复期治疗 病情稳定后启动康复治疗,严格控制高血压,预防并发症;④禁忌 急性期禁用抗凝/抗血小板药物。
短暂性脑缺血发作(TIA,小中风)
- 核心症状
突发肢体偏瘫、偏身麻木、言语障碍等,症状与脑梗死相似,但持续时间短(<24小时,多数<1小时),可完全缓解,无后遗症;TIA是脑梗死的重要预警信号,7天内发生脑梗死的风险极高。
- 详细原因
与脑梗死病因基本一致,主要为动脉粥样硬化(微血栓脱落)、房颤(微血栓脱落)、颈动脉狭窄、小血管病变、血液高凝状态。危险因素 高血压、高血脂、糖尿病、吸烟、肥胖、房颤、年龄增长。诱因 劳累、情绪激动、熬夜、脱水、血压骤变。
- 发病原理
微血栓阻塞脑部血管或脑部短暂供血不足,导致脑组织暂时性缺血缺氧,引发神经功能缺损症状;微血栓可自行溶解或供血恢复,脑组织未发生不可逆坏死,故症状可完全缓解。但TIA提示脑部血管存在病变,不及时干预易引发脑梗死。
- 治疗原理
以紧急评估、干预危险因素、预防脑梗死为核心,视为“急诊”处理。①急性期评估 完善头颅CT/MRI、颈动脉超声、心电图等检查,明确病因;②药物治疗 双联抗血小板(阿司匹林+氯吡格雷,服用1-3个月后改为单药),他汀类调脂药强化降脂;③病因治疗 颈动脉狭窄>50%且有症状者,可行内膜切除术或支架置入术;房颤患者需抗凝治疗;④生活方式干预 戒烟限酒、低盐低脂饮食、规律运动、避免熬夜;⑤定期随访 每3-6个月复查颈动脉超声、血脂。
偏头痛
- 核心症状
单侧头部搏动性疼痛(胀痛、跳痛),中等至剧烈程度,可伴恶心、呕吐、畏光、畏声,活动后疼痛加重;发作持续4-72小时,可自行缓解,缓解期无明显症状;部分患者发作前有先兆(视觉先兆 闪光、暗点;肢体先兆 单侧麻木);女性多见,月经周期、情绪波动时易发作。
- 详细原因
遗传因素(家族史阳性者风险升高3-6倍),内分泌因素(女性雌激素波动),环境因素(强光、噪音、睡眠异常、精神压力大、食用含酪氨酸食物),药物因素(硝酸酯类药物、避孕药)。病因尚未完全明确,可能与神经血管调节紊乱相关。
- 发病原理
主流机制为“神经血管学说” 偏头痛发作时,脑部神经细胞异常兴奋,释放神经肽,导致脑部血管扩张、通透性增加,引发血管源性脑水肿;扩张血管刺激周围神经末梢,引发搏动性疼痛;神经肽刺激脑干呕吐中枢,引发恶心、呕吐;畏光、畏声与脑干感觉中枢敏感性升高相关。先兆症状可能与脑部血管短暂收缩、脑组织短暂缺血有关。
- 治疗原理
分为发作期治疗与预防性治疗。
- 发作期治疗
轻度疼痛用布洛芬、萘普生;中重度疼痛用曲坦类(舒马曲坦)、麦角胺类药物;伴恶心呕吐者加用甲氧氯普胺;发作时需休息,避免强光、噪音刺激;
- 预防性治疗
适用于发作频繁(每月>4次)、疼痛剧烈者,常用β受体阻滞剂(美托洛尔)、钙离子拮抗剂(氟桂利嗪)等;
- 诱因规避
避免接触诱发因素,女性月经周期发作频繁者可调整激素水平;
- 非药物治疗
针灸、按摩、生物反馈治疗,适用于药物不耐受者。
癫痫
- 核心症状
全身性发作(大发作) 突发意识丧失、全身强直-阵挛抽搐(四肢僵硬、抽搐,伴口吐白沫、牙关紧闭),发作持续1-3分钟,发作后意识模糊、乏力;部分性发作 局部肢体抽搐、感觉异常,意识清醒或模糊;失神发作(小发作,多见于儿童) 突发短暂意识丧失(<10秒),目光呆滞,动作停止,可自行恢复;癫痫持续状态(危及生命) 发作持续>5分钟,或频繁发作,意识未恢复。
- 详细原因
分为特发性与继发性两类。特发性 与遗传因素相关,多见于儿童、青少年,无明确脑部器质性病变;继发性 脑部器质性病变(脑梗死、脑出血、脑肿瘤等),全身性疾病(低血糖、低钙等),药物因素(停用抗癫痫药等)。诱因包括 劳累、熬夜、情绪激动、强光刺激、饮酒、暴饮暴食、发热。
- 发病原理
核心为脑部神经元异常过度放电,导致中枢神经系统功能短暂紊乱。正常情况下神经元放电受调控,存在病变、遗传异常或诱因刺激时,神经元细胞膜稳定性下降,大量神经元同步放电,引发癫痫发作。不同部位神经元放电,表现为不同类型发作 大脑皮层运动区放电引发肢体抽搐,意识中枢放电引发意识丧失,失神发作与丘脑-皮层环路异常放电相关。癫痫持续状态时,持续放电导致脑组织缺血缺氧,引发脑水肿、脑损伤。
- 治疗原理
以控制发作、减少脑损伤、提高生活质量为核心,长期规范治疗。
- 药物治疗(首选) 根据发作类型选用抗癫痫药,全身性发作首选丙戊酸钠,部分性发作首选卡马西平,失神发作首选乙琥胺;单药起始,逐渐加量,足量足疗程服用,不可自行停药;
- 病因治疗
继发性癫痫需治疗原发病;
- 手术治疗
药物治疗无效者,可行癫痫病灶切除术、神经调控手术;
- 癫痫持续状态治疗
立即静脉注射地西泮、苯巴比妥控制抽搐,保持呼吸道通畅,纠正水、电解质紊乱;
- 生活方式干预
规律作息,避免诱因,清淡饮食,定期复查脑电图、肝肾功能。
八大系统
一、循环系统(详细版)
核心功能 不仅是物质运输,更兼具免疫防御(白细胞、抗体运输)、体温调节(血液传导热量)功能,通过体循环、肺循环双回路,维持全身细胞的营养供应与代谢平衡,是机体功能联动的“核心枢纽“。
关键器官及细分结构
- 心脏:分为左心房、左心室、右心房、右心室四腔,心腔内有二尖瓣(左房室瓣)、三尖瓣(右房室瓣)、主动脉瓣、肺动脉瓣,防止血液倒流;心肌为横纹肌,能自主节律收缩(窦房结为“起搏点“)。
- 血管:动脉(从心脏出发,逐级分支为小动脉、微动脉,管壁含平滑肌,可调节血流)、毛细血管(管壁仅1层内皮细胞,是物质交换核心场所)、静脉(从全身回流,逐级汇合为大静脉,管壁薄、管腔大,含静脉瓣防倒流)。
- 血液:由血浆(占55%,含水分、蛋白质、电解质等)和血细胞(占45%,含红细胞、白细胞、血小板)组成;红细胞运氧(含血红蛋白),白细胞抗感染,血小板参与凝血。
运行原理(双循环联动)
- 肺循环(换气):右心室→肺动脉→肺部毛细血管→肺泡(O₂入血、CO₂出)→肺静脉→左心房,完成血液“充氧“。
- 体循环(供能):左心房→左心室(高压泵血)→主动脉→全身各级动脉→组织毛细血管(O₂、营养入细胞,废物入血)→各级静脉→上/下腔静脉→右心房,完成血液“供能与废物收集“,随后重复肺循环,形成闭环。
二、呼吸系统(详细版)
核心功能 除气体交换外,还能调节体内酸碱平衡(通过排出CO₂调节血液pH)、过滤吸入气体(防御异物),同时发声(喉内声带振动),是机体与外界沟通的“气体桥梁“。
关键器官及细分结构
- 上呼吸道:鼻(鼻毛过滤、鼻黏膜湿润加温)、咽(呼吸与消化共用通道,含扁桃体防御)、喉(有声带,兼具通气与发声功能)。
- 下呼吸道:气管(管壁含软骨环,保持气道通畅)→支气管→细支气管→终末细支气管(逐级分支,气道变细),最终连接肺泡。
- 肺:由无数肺泡组成(成人肺泡总数约3亿个,表面积达70-80㎡),肺泡壁薄(1层上皮细胞),外缠绕毛细血管,利于气体扩散;肺实质为肺泡,间质为结缔组织,起支撑作用。
- 呼吸肌:主要为膈肌(核心动力)、肋间肌(辅助),还有腹肌(用力呼气时参与)。
运行原理(呼吸运动+气体交换)
- 吸气(主动):膈肌收缩(膈顶下降)、肋间外肌收缩(肋骨上提)→胸腔容积扩大→肺内气压低于外界→空气经呼吸道入肺,肺泡扩张。
- 气体交换:肺泡内O₂浓度高于血液,CO₂浓度低于血液→O₂经肺泡壁、毛细血管壁扩散入血(与血红蛋白结合),CO₂从血液扩散入肺泡,完成“换气“。
- 呼气(被动,平静时):膈肌、肋间外肌舒张→胸腔容积缩小→肺内气压高于外界→肺泡内CO₂经呼吸道排出体外;用力呼气时,肋间内肌、腹肌收缩,辅助排气。
三、消化系统(详细版)
核心功能 分 “机械消化” (物理研磨)和 “化学消化” (酶解分解),将大分子食物(淀粉、蛋白质、脂肪)分解为小分子可吸收物质,同时排出未消化残渣,为机体供能、供原料,肝脏还兼具解毒、代谢调节功能。
关键器官及细分结构
- 消化道:口→咽→食道→胃→小肠(十二指肠、空肠、回肠)→大肠(盲肠、结肠、直肠)→肛门;小肠黏膜表面有肠绒毛,绒毛上有微绒毛,增大吸收面积(达200-300㎡)。
- 消化腺:
- 唾液腺(分泌唾液,含淀粉酶)
- 胃腺(分泌胃液,含胃酸、胃蛋白酶)
- 肝脏(最大消化腺,分泌胆汁,储存在胆囊,进食后排出)
- 胰腺(分泌胰液,含多种消化酶,经胰管入十二指肠)
- 肠腺(分泌肠液,含多种酶)
运行原理(分段消化+吸收)
- 口腔消化:牙齿咀嚼(机械消化),唾液淀粉酶将淀粉初步分解为麦芽糖;舌搅拌食物,形成食团。
- 食道运输:食团经食道蠕动(平滑肌收缩)入胃,食道下段有贲门括约肌,防止胃内容物反流。
- 胃内消化:胃壁平滑肌蠕动(机械研磨),将食团变为食糜;胃酸(盐酸)杀菌、激活胃蛋白酶,胃蛋白酶将蛋白质初步分解为多肽;胃排空约需4-6小时,食糜分批入小肠。
- 小肠消化(核心):十二指肠接收胃内食糜、胆汁(乳化脂肪,便于酶解)、胰液(含淀粉酶、蛋白酶、脂肪酶,分别分解淀粉、蛋白质、脂肪);肠液进一步分解小分子,最终淀粉→葡萄糖、蛋白质→氨基酸、脂肪→甘油+脂肪酸。
- 吸收与排泄:葡萄糖、氨基酸经肠绒毛入血(静脉回流),甘油、脂肪酸入淋巴(再汇入血);未吸收残渣入大肠,大肠吸收水分、无机盐,形成粪便,经直肠、肛门排出。
四、泌尿系统(详细版)
核心功能 精准过滤血液中废物(尿素、肌酐)、多余水分及电解质,通过尿液排出,同时重吸收有用物质(葡萄糖、氨基酸、部分电解质),维持体内水、电解质、酸碱平衡,肾脏还能分泌肾素(调节血压)、促红细胞生成素(促进造血)。
关键器官及细分结构
- 肾:实质分为皮质(含肾小体、近曲小管、远曲小管)和髓质(含髓袢、集合管);每个肾约100万个肾单位(基本功能单位),肾单位=肾小体(肾小球+肾小囊)+肾小管(近曲小管、髓袢、远曲小管)。
- 输尿管:左右各一,管壁含平滑肌,通过蠕动将尿液输送至膀胱,末端有输尿管口括约肌,防膀胱尿液反流。
- 膀胱:平滑肌构成的囊性器官,容量约300-500ml,底部有尿道内口,周围有括约肌;膀胱黏膜能感知充盈度,触发排尿反射。
- 尿道:男性尿道长(16-22cm),兼具排尿、排精功能;女性尿道短(3-5cm),易发生尿路感染;末端有尿道外口括约肌,可自主控制排尿。
运行原理(尿液生成+排泄)
- 滤过(肾小体):血液流经肾小球(毛细血管球),除血细胞、大分子蛋白质外,其余物质(水、葡萄糖、氨基酸、废物、电解质)经滤过膜入肾小囊,形成原尿(每日约180L)。
- 重吸收(肾小管):原尿流经近曲小管(重吸收葡萄糖、氨基酸、大部分水和电解质)、髓袢(重吸收部分水、钠)、远曲小管(重吸收剩余水、电解质,调节酸碱平衡),最终剩余物质形成终尿(每日约1.5-2.0L)。
- 排泄:终尿经集合管汇入肾盂→输尿管→膀胱(储存);当膀胱充盈至150-200ml,刺激膀胱壁感受器,信号经传入神经至脊髓排尿中枢,再经传出神经引发膀胱平滑肌收缩、括约肌舒张,尿液经尿道排出;大脑皮层可自主抑制或启动排尿反射。
五、神经系统(详细版)
核心功能 作为机体 “指挥调控中心” ,接收内、外环境刺激(如温度、疼痛、内脏信号),整合分析后发出指令,调节运动、内分泌、内脏活动等,同时实现意识、思维、记忆、情感等高级功能,维持机体稳态与环境适应。
关键器官及细分结构
- 中枢神经系统(CNS):脑(位于颅腔,含大脑、小脑、脑干)、脊髓(位于椎管内,上连脑干,下至腰椎);脑和脊髓表面有脑脊液(缓冲、保护、营养),被脑膜/脊髓膜包裹。
- 大脑:分左右半球,表面为大脑皮层(灰质,含神经元胞体,是高级功能中枢),内部为白质(神经纤维,连接皮层与其他部位);皮层功能区:
- 躯体运动区(支配对侧肢体运动)
- 躯体感觉区(接收对侧躯体感觉)
- 视觉区(枕叶,处理视觉信号)
- 听觉区(颞叶,处理听觉信号)
- 语言区(人类特有,调控语言表达与理解)
- 小脑:位于大脑后方,分前庭小脑(调节平衡)、脊髓小脑(调节肢体协调)、皮层小脑(参与运动计划制定),维持躯体平衡与运动精准性。
- 脑干:连接大脑、小脑、脊髓,分中脑(调控眼球运动)、脑桥(连接大脑与小脑,参与呼吸调节)、延髓(“生命中枢”,控制呼吸、心跳、血压、吞咽等基本生命活动)。
- 周围神经系统(PNS):由脑神经(12对,支配头面部器官)、脊神经(31对,支配躯干、四肢)、自主神经(交感神经、副交感神经,支配内脏、腺体,自主调节,不受意识控制)组成。
运行原理(信号传导+反射调控)
- 信号传导:感受器(如皮肤痛觉感受器、内脏感受器)接收刺激,转化为神经冲动→传入神经(感觉神经)→中枢神经系统(脑/脊髓)整合分析→传出神经(运动神经/自主神经)→效应器(肌肉、腺体、内脏),产生反应(如肢体收缩、腺体分泌、内脏活动调整)。
- 反射活动:是神经系统基本反应形式,反射弧(感受器→传入神经→神经中枢→传出神经→效应器)是基础;简单反射(如膝跳反射、缩手反射)由脊髓调控,快速且无需意识参与;复杂反射(如望梅止渴)由大脑皮层调控,需结合经验与记忆。
- 高级功能:意识、思维、记忆等依赖大脑皮层神经元的复杂联动,通过神经递质(如多巴胺、乙酰胆碱)传递信号,实现信息储存与处理。
六、内分泌系统(详细版)
核心功能 与神经系统协同(神经-体液调节),通过分泌激素(微量、高效),精准调控机体生长发育、新陈代谢、生殖功能、免疫反应等,维持内环境稳态;激素作用具有特异性(仅作用于靶器官/靶细胞,因靶细胞含特异性受体)。
关键器官(内分泌腺)及功能
- 甲状腺:位于颈部前方,分泌甲状腺激素(T3、T4),调节新陈代谢(加快产热)、生长发育(尤其脑和骨骼发育);分泌不足(呆小症,幼年)、过多(甲亢)均会导致功能紊乱。
- 胰岛:位于胰腺内,是内分泌细胞团,A细胞分泌胰高血糖素(升血糖,促进肝糖原分解),B细胞分泌胰岛素(降血糖,促进葡萄糖摄取与储存),两者拮抗,维持血糖稳定(正常值3.9-6.1mmol/L)。
- 垂体:位于颅内(垂体窝内),是 “内分泌之王” ,分腺垂体(分泌生长激素、促甲状腺激素、促性腺激素等,调控其他腺体)和神经垂体(释放抗利尿激素、催产素,分别调节尿量、促进子宫收缩);生长激素分泌不足(侏儒症,幼年)、过多(巨人症,幼年)会影响发育。
- 肾上腺:位于肾脏上方,分皮质(分泌糖皮质激素、盐皮质激素,调节糖代谢、水盐平衡)和髓质(分泌肾上腺素、去甲肾上腺素,应对应激,加快心跳、升高血压)。
- 性腺:男性睾丸(分泌雄性激素,促进精子生成、第二性征发育,如喉结突出、体毛增多);女性卵巢(分泌雌性激素、孕激素,促进卵子发育、子宫内膜增生,维持月经周期与妊娠)。
运行原理(激素调控+反馈调节)
- 激素分泌调节:受神经调节(如交感神经兴奋促进肾上腺髓质分泌)和体液调节(如促甲状腺激素促进甲状腺分泌)双重调控。
- 激素作用过程:激素分泌后入血,运输至靶器官/靶细胞,与细胞膜或细胞内受体结合,激活细胞内信号通路,引发代谢、生长、分泌等一系列反应;激素发挥作用后迅速灭活(主要在肝、肾),避免持续作用。
- 反馈调节(稳态关键):多为负反馈,如甲状腺激素分泌过多→抑制垂体分泌促甲状腺激素→甲状腺激素分泌减少;正反馈少见,如分娩时催产素分泌增加→促进子宫收缩→进一步增加催产素分泌,直至分娩结束。
七、运动系统(详细版)
核心功能 构成人体支架(支撑躯体)、保护内脏(如颅骨护脑、肋骨护心肺、骨盆护盆腔脏器)、完成躯体运动(屈伸、旋转、行走等),同时骨骼是钙、磷储存库,骨骼肌收缩可产生热量(维持体温)。
关键器官及细分结构
- 骨:成人约206块,分长骨(如肱骨、股骨,起支撑、运动杠杆作用)、短骨(如腕骨、跗骨,缓冲震荡)、扁骨(如颅骨、肋骨,保护内脏)、不规则骨(如椎骨、下颌骨,形态特殊,适配功能);骨由骨质(骨密质,坚硬;骨松质,多孔)、骨膜(含血管、神经,促进骨生长与修复)、骨髓(红骨髓造血,黄骨髓储能)组成。
- 关节:骨与骨的连接部位,分不动关节(如颅骨缝,无活动)、半活动关节(如椎骨间关节,少量活动)、动关节(如肩关节、膝关节,活动灵活,占多数);动关节结构:关节面(覆盖关节软骨,减少摩擦)、关节囊(密封关节腔,分泌滑液润滑)、关节腔(含滑液,缓冲冲击)、韧带(加固关节,限制过度活动)。
- 骨骼肌:附着于骨骼,约600余块,由肌腹(肌肉主体,收缩部分,含肌纤维)和肌腱(两端,白色坚韧,附着于骨)组成;骨骼肌受躯体神经支配,可自主收缩,收缩时消耗能量(ATP供能),产生热量。
运行原理(运动产生+调控)
- 运动杠杆原理:骨骼相当于杠杆,关节相当于支点,骨骼肌收缩相当于动力,当骨骼肌收缩时,牵拉附着的骨骼,围绕关节转动,完成运动(如肱二头肌收缩、肱三头肌舒张→屈肘;反之→伸肘)。
- 肌肉收缩原理:肌丝滑行学说,骨骼肌收缩时,肌细胞内肌动蛋白与肌球蛋白丝相对滑行,肌小节缩短,肌腹收缩,牵拉肌腱带动骨骼运动;收缩需神经冲动触发(神经末梢释放乙酰胆碱),同时需Ca²⁺参与、ATP供能。
- 运动调控:大脑皮层运动区发出指令→脊髓→传出神经→骨骼肌,引发收缩;小脑、前庭系统协同调节,维持运动平衡与协调;运动时呼吸、心跳加快(神经-体液调节),为骨骼肌提供充足O₂和营养。
八、生殖系统(详细版)
核心功能 产生生殖细胞(精子/卵子)、分泌性激素(调节生殖发育与第二性征)、完成受精与孕育(女性),实现物种繁衍;同时性激素对代谢、骨骼发育等也有调节作用。
关键器官及细分结构(男/女)
(一)男性生殖系统
- 睾丸:位于阴囊内,左右各一,是生殖腺,实质含生精小管(产生精子,需低于体温1-2℃,阴囊调节温度)和间质细胞(分泌雄性激素);精子生成周期约74天,生成后进入附睾。
- 附睾:附着于睾丸后端,分头、体、尾,储存精子并促进精子成熟(获得运动能力),成熟精子经附睾尾进入输精管。
- 输精管:长约50cm,从附睾尾→盆腔→尿道,输送精子;射精时,输精管平滑肌收缩,将精子推送至尿道。
- 附属腺:前列腺(位于膀胱下方,分泌前列腺液,中和尿道酸性环境,利于精子存活)、精囊腺(分泌黏液,含果糖,为精子供能)、尿道球腺(分泌少量液体,润滑尿道,中和酸性尿液);腺体分泌物与精子混合形成精液(每次射精约2-5ml,含精子约3-5亿个)。
- 尿道:贯穿前列腺、阴茎,是排尿与排精共用通道,末端开口于阴茎头。
(二)女性生殖系统
- 卵巢:位于盆腔内,左右各一,是生殖腺,实质含卵泡(产生卵子)和黄体(排卵后形成,分泌孕激素、雌性激素);女性一生约有400-500个卵泡发育成熟并排卵,其余退化。
- 输卵管:长约10-12cm,连接卵巢与子宫,分壶腹部(受精主要部位)、峡部(较细,输送受精卵);输卵管平滑肌蠕动、纤毛摆动,将卵子向子宫推送。
- 子宫:位于盆腔中央,呈倒置梨形,分子宫底、子宫体、子宫颈;子宫壁由子宫内膜(周期性增生、脱落,形成月经)、子宫肌层(平滑肌,分娩时收缩)、子宫浆膜层组成;子宫是受精卵着床、胎儿发育的场所。
- 阴道:连接子宫颈与外界,是性交器官、月经排出通道、胎儿分娩通道;阴道黏膜含糖原,乳酸杆菌分解糖原产生乳酸,维持酸性环境(防御感染)。
运行原理(生殖过程)
- 生殖细胞生成与成熟:男性睾丸持续产生精子(青春期后开始,终身可持续),经附睾成熟;女性卵巢每月发生1次排卵(青春期后开始,绝经后停止),卵子排出后寿命约12-24小时。
- 受精:性交后,精液进入阴道,精子经子宫颈→子宫→输卵管壶腹部,与卵子相遇并结合,形成受精卵(受精后30小时开始分裂)。
- 着床与孕育:受精卵经输卵管峡部→子宫腔,在子宫内膜着床(受精后6-7天),逐渐发育为胚胎、胎儿;妊娠期间,黄体、胎盘分泌孕激素、雌性激素,维持子宫内膜增生,为胎儿提供营养,抑制排卵;妊娠约40周(280天)后,进入分娩期。
- 分娩:子宫肌层强烈收缩(宫缩),胎儿经子宫颈→阴道娩出,随后胎盘娩出;分娩后,子宫内膜脱落,形成产后恶露,逐渐恢复至未孕状态。
性激素调节
- 雄性激素:促进男性生殖器官发育、精子生成,维持第二性征
- 雌性激素:促进女性生殖器官发育、子宫内膜增生,维持第二性征
- 孕激素:协同雌性激素,为妊娠做准备,维持妊娠
症状
一、发热
生理原理 发热核心是体温调节中枢调定点上移。人体正常体温由下丘脑视前区-下丘脑前部(POAH)调控,维持产热与散热平衡。当机体受病原体、炎症因子等刺激时,POAH上调“正常体温标准“,导致产热大于散热,引发体温升高。
发展过程
- 升温期:调定点上移后,机体启动产热(骨骼肌收缩、肝脏代谢增强)、抑制散热(皮肤血管收缩、汗腺分泌减少),表现为畏寒、寒战、皮肤苍白,体温持续上升至新调定点。
- 高热期:产热与散热在较高水平平衡,患者感燥热,皮肤发红温热,呼吸心率加快,持续时间取决于致热原清除速度(数小时至数天)。
- 退热期:调定点恢复正常,机体启动散热(皮肤血管扩张、大量出汗)、抑制产热,体温逐渐回落,出汗过多可能导致脱水、电解质紊乱。
常见引发原因
- 感染性因素(最常见):病毒感染(流感、新冠等)、细菌感染(肺炎、扁桃体炎等)、其他病原体感染(真菌、寄生虫、支原体等)。
- 非感染性因素:免疫性疾病(类风湿关节炎、系统性红斑狼疮等)、肿瘤性疾病(淋巴瘤、白血病等)、代谢异常(甲亢危象等)、物理化学因素(中暑、药物热等)。
二、疼痛
生理原理 疼痛是机体对伤害性刺激的主观感知与防御反应,由“伤害性感受器-神经传导-中枢整合“完成。伤害性感受器识别刺激后,经Aδ纤维(快痛,尖锐定位明确)和C纤维(慢痛,钝痛定位模糊)传入脊髓,再投射至大脑皮层,边缘系统参与情绪反应。
发展过程
- 刺激识别阶段:伤害性刺激导致组织释放炎症介质,激活或敏化伤害性感受器,产生电信号。
- 信号传导阶段:电信号经Aδ纤维(快痛)和C纤维(慢痛)传入脊髓,先后引发不同痛感。
- 中枢感知与反应阶段:信号经丘脑中转后,大脑皮层识别疼痛信息,触发躯体防御反应(肌肉收缩等)和情绪反应(焦虑、烦躁等),慢性疼痛可能导致抑郁。
常见引发原因
- 躯体痛(定位明确):皮肤软组织(外伤、烧伤等)、肌肉骨骼(劳损、骨折、颈椎病等)。
- 内脏痛(定位模糊):消化系统(胃炎、胆囊炎等)、心血管系统(心绞痛、心梗等)、泌尿生殖系统(肾结石、痛经等)。
- 神经痛(烧灼样/刺痛):带状疱疹后遗症、坐骨神经痛、糖尿病周围神经病变等。
- 心理性疼痛:焦虑症、抑郁症等导致疼痛感知异常放大。
三、咳嗽
生理原理 咳嗽是呼吸道反射性防御动作,目的是清除分泌物与异物。反射中枢位于延髓咳嗽中枢,受大脑皮层调控。呼吸道黏膜的咳嗽感受器受刺激后,经迷走神经传入中枢,再由中枢指令效应器完成咳嗽动作。
发展过程
- 刺激触发阶段:咳嗽感受器被机械、化学、病理刺激(异物、烟雾、感染等)激活。
- 反射启动阶段:信号传入咳嗽中枢,引发深吸气、声门关闭,随后膈肌腹肌收缩、肺内压力骤增,声门开放排出异物/分泌物。
- 后续阶段:单次咳嗽清除少量异物,阵咳因刺激持续引发,可能伴随胸闷、咽痛。
常见引发原因
- 呼吸道疾病(核心诱因):上呼吸道感染(感冒、咽喉炎等)、下呼吸道感染(支气管炎、肺炎等)、气道高反应性(哮喘、过敏性咳嗽等)。
- 胸膜疾病:胸膜炎、气胸引发刺激性干咳。
- 其他系统疾病:胃食管反流病(反流性咳嗽)、鼻后滴漏综合征、药物副作用(如卡托普利)。
四、痒(瘙痒)
生理原理 瘙痒是皮肤黏膜的特殊感觉,由瘙痒感受器(C纤维为主)被激活后传导信号至中枢。瘙痒介质(组胺、蛋白酶等)激活神经末梢,信号经脊髓丘脑束上传,大脑皮层识别后引发搔抓欲望,脊髓存在“痒-痛拮抗“机制(轻微疼痛可缓解瘙痒)。
发展过程
- 致敏阶段:皮肤黏膜受刺激后释放瘙痒介质(过敏时肥大细胞释放组胺,炎症时释放炎症因子等)。
- 信号传导与感知阶段:介质激活神经末梢,信号传入中枢,产生痒觉与搔抓欲望。
- 搔抓与反馈阶段:搔抓产生轻微疼痛暂时缓解瘙痒,但过度搔抓会损伤皮肤屏障,加重炎症与瘙痒,形成“越抓越痒“循环。
常见引发原因
- 皮肤疾病(最主要):过敏性皮肤病(荨麻疹、湿疹等)、感染性皮肤病(疥疮、体癣等)、其他(皮肤干燥、银屑病等)。
- 系统性疾病:代谢内分泌疾病(糖尿病、甲亢等)、血液系统疾病(真性红细胞增多症等)、自身免疫病(系统性红斑狼疮等)。
- 其他因素:药物过敏、精神心理因素(焦虑、压力大)、环境因素(紫外线、蚊虫叮咬等)。
五、头晕
生理原理 头晕是空间定向能力障碍的主观感觉(头重脚轻、站立不稳),核心是平衡系统(前庭、视觉、本体感觉系统)信号整合异常。三者信号传入小脑和大脑皮层维持平衡,任一系统异常或信号不协调,均会引发头晕。
发展过程
- 诱因触发阶段:前庭、视觉、本体感觉系统异常或全身因素(低血压、低血糖等)干扰平衡功能,表现为活动后短暂头晕,休息后缓解。
- 信号整合紊乱阶段:平衡系统信号矛盾,小脑与大脑皮层无法准确整合,引发空间定向障碍。
- 主观感知与伴随症状阶段:产生头晕感,伴随站立不稳、恶心、出冷汗等,诱因持续则症状反复发作。
常见引发原因
- 前庭系统异常:耳源性疾病(耳石症、梅尼埃病、前庭神经炎等)。
- 脑血管与神经系统疾病:脑供血不足、脑卒中、偏头痛、颅内肿瘤等。
- 全身因素:心血管问题(低血压、高血压等)、血液系统疾病(贫血、低血糖等)、颈椎病(压迫椎动脉)。
- 其他诱因:视疲劳、药物副作用、精神心理因素(焦虑、惊恐发作)。
六、恶心
生理原理 恶心是上腹部不适、紧迫欲吐的感觉,核心是延髓呕吐中枢或化学感受器触发区(CTZ)被激活。CTZ感知血液中有害物质,呕吐中枢整合多系统信号,激活自主神经,引发唾液分泌增加、胃蠕动减弱等反应。
发展过程
- 刺激传入阶段:胃肠道、中枢、前庭系统或心理因素触发恶心信号。
- 中枢整合阶段:呕吐中枢激活迷走神经与交感神经,引发胃排空延迟、唾液分泌增加、心率减慢等。
- 主观感知阶段:大脑皮层产生恶心感,轻重不一,持续刺激可进展为呕吐。
常见引发原因
- 胃肠道疾病:急性胃炎、胃溃疡、肠梗阻、食物中毒等。
- 中枢神经系统疾病:颅内压升高(脑出血、脑肿瘤等)、偏头痛。
- 前庭系统异常:晕车、晕船、梅尼埃病。
- 其他因素:药物副作用、内分泌代谢异常(孕吐、糖尿病酮症酸中毒等)、精神心理因素。
七、呕吐
生理原理 呕吐是胃和部分肠内容物经食管、口腔排出的反射动作,核心是呕吐中枢协调膈肌、腹肌、胃平滑肌等多器官肌肉协同收缩,清除胃内有害物质。
发展过程
- 前驱期(恶心阶段):上腹不适、唾液分泌增加、胃蠕动减弱,为呕吐准备阶段。
- 干呕期:声门关闭,膈肌腹肌收缩,胃内容物未排出,表现为反复腹部收缩、喉部不适。
- 呕吐期:腹腔压力骤增,胃内容物经食管口腔排出,伴随自主神经反应(心率加快、出冷汗等)。
- 恢复期:呕吐后胃内压力降低,患者感乏力、口干,病理性呕吐可能反复发生,引发脱水等。
常见引发原因
- 胃肠道疾病(核心诱因):急性胃肠炎、幽门梗阻、肠梗阻、急性胰腺炎等。
- 中枢神经系统疾病:颅内压升高(喷射性呕吐,伴轻微恶心或无恶心)。
- 前庭系统异常:晕车、晕船、前庭神经炎(呕吐与头晕同步)。
- 其他因素:药物与毒物、内分泌疾病、精神心理因素(神经性呕吐)。
八、发麻
生理原理 发麻是感觉神经传导异常或神经受损引发的异常感觉(麻木、蚁行感等),核心是感觉神经通路(外周神经、脊髓、丘脑、大脑皮层)结构或功能异常,导致信号传导障碍、延迟或异常发放。
发展过程
- 诱因触发阶段:神经受压迫、损伤、缺血等刺激,导致感觉神经末梢或传导通路受损,出现轻微发木、感觉迟钝。
- 信号传导异常阶段:受损神经信号传导障碍或异常发放,大脑皮层接收错误信号。
- 主观感知与后续阶段:产生明确发麻感,诱因短暂则数小时内缓解,持续则症状反复,甚至伴随运动功能障碍。
常见引发原因
- 神经压迫性因素(最常见):局部压迫、颈椎病、腰椎疾病、腕管综合征、肘管综合征等。
- 神经损伤性因素:代谢性疾病(糖尿病周围神经病变等)、营养缺乏(维生素B族缺乏等)、药物与毒物、感染与炎症(吉兰-巴雷综合征等)。
- 血液循环障碍因素:血管性疾病(脑动脉硬化、下肢动脉硬化等)、血栓与栓塞、雷诺氏症等。
- 中枢神经系统疾病:脑卒中、多发性硬化、颅内肿瘤或脊髓病变、脊髓损伤等。
- 其他因素:精神心理因素、电解质紊乱(低钾、低钙)。
九、瘀斑
生理原理 瘀斑是皮下出血表现(直径>5mm暗红色斑块),核心是止血凝血功能异常、血管壁损伤或外力导致血管破裂,血液外渗积聚。正常情况下,血管受损后血小板聚集、凝血因子激活形成凝块止血,机制失效则引发瘀斑。
发展过程
- 出血期:血管破裂,血液外渗至皮下,初期呈鲜红色或暗红色,按压不褪色,可能伴随肿胀压痛。
- 扩散与吸收期:出血停止后,血红蛋白分解,瘀斑颜色依次变为暗红→紫色→暗绿色→淡黄色,边界模糊,肿胀压痛缓解(3-7天)。
- 修复期:代谢产物被清除,皮下组织恢复正常,瘀斑消退(1-2周),出血量极大或感染可能遗留色素沉着。
常见引发原因
- 血管壁异常因素:过敏性紫癜、感染性疾病、维生素C缺乏、老年性血管壁改变、药物影响(糖皮质激素)。
- 血小板异常因素:血小板减少(原发性血小板减少性紫癜等)、血小板功能异常(先天性血小板无力症等)、抗血小板药物影响。
- 凝血因子异常因素:先天性凝血因子缺乏(血友病等)、维生素K缺乏、肝脏疾病、弥散性血管内凝血(DIC)。
- 其他因素:外力损伤、抗凝药物使用、酗酒、遗传性出血性毛细血管扩张症。
十、腹胀
生理原理 腹胀是胃肠道内气体、液体或食物残渣积聚导致的胀满不适,核心是胃肠道内容物生成与排出失衡,或动力异常,牵拉胃肠道壁牵张感受器引发不适。正常情况下,胃肠道气体经嗳气、排气排出,失衡则引发腹胀。
发展过程
- 诱因触发阶段:饮食不当、胃肠道疾病等导致气体生成过多、排出受阻,或内容物滞留。
- 积聚与扩张阶段:内容物持续积聚,胃肠道扩张,牵拉牵张感受器,引发轻微饱胀、隐痛。
- 主观感知与后续阶段:产生明确腹胀感,伴随腹部膨隆、嗳气等,诱因短暂则1天内缓解,持续则症状反复。
常见引发原因
- 饮食因素(最常见):摄入易产气食物、暴饮暴食、饮食缺乏膳食纤维。
- 胃肠道疾病:动力障碍性疾病(功能性消化不良等)、梗阻性疾病(幽门梗阻等)、炎症性疾病(胃炎等)、肠道菌群失调。
- 肝胆胰疾病:肝脏疾病(肝炎、肝硬化等)、胆道疾病(胆囊炎等)、胰腺疾病(胰腺炎等)。
- 其他因素:药物影响、精神心理因素、术后肠麻痹、内分泌疾病(甲减)。
十一、牙出血
生理原理 牙出血是牙龈/牙周组织血管破裂渗出的表现,核心是局部炎症、损伤或全身凝血异常,导致血管通透性增加、脆性增强,或血管直接受损,血液无法正常凝固。
发展过程
- 诱因触发阶段:局部或全身因素导致牙龈充血水肿,血管壁脆弱,未出现明显出血。
- 出血阶段:轻微刺激(刷牙、进食)引发血管破裂,出血量从唾液带血丝到自发性出血不等。
- 愈合或加重阶段:诱因短暂则出血自行停止,持续则炎症反复,伴随牙龈萎缩、牙齿松动等。
常见引发原因
- 局部因素(最常见):牙周疾病(牙龈炎、牙周炎)、局部刺激(食物嵌塞、不良修复体等)、口腔感染(牙龈脓肿等)。
- 全身因素:凝血功能异常(血友病、白血病等)、激素水平变化(妊娠期、青春期)、营养缺乏(维生素C、K缺乏)、药物影响(抗凝血药)。
- 其他因素:口腔卫生差、吸烟酗酒、糖尿病(血糖控制不佳加重牙周炎症)。
十二、水肿
生理原理 水肿是组织间隙液体积聚过多导致的肿胀,核心是血管内外液体交换失衡和水钠潴留。正常情况下,血管内液体与组织间隙液体动态平衡,调控异常则液体渗出至组织间隙,形成水肿。
发展过程
- 诱因触发阶段:脏器功能异常等导致液体交换失衡或水钠潴留,组织间隙少量积液,表现为局部轻微沉重感。
- 液体积聚与肿胀阶段:积液增多引发明显肿胀,初期为凹陷性,后期可能变为非凹陷性,伴随皮肤紧绷。
- 消退或加重阶段:诱因短暂则1天内缓解,持续则水肿反复加重,甚至出现胸腔积液、腹水。
常见引发原因
- 心源性水肿(全身性,下肢先出现):心力衰竭、心包炎等。
- 肾源性水肿(眼睑面部开始,蔓延全身):肾病综合征、肾小球肾炎等。
- 肝源性水肿(以腹水为主,伴下肢水肿):肝硬化、肝癌等。
- 局部性水肿:血管性因素(静脉血栓等)、淋巴性因素(淋巴回流受阻)、炎症性因素、过敏因素(血管神经性水肿)。
- 其他因素:营养不良性水肿、内分泌因素(甲减等)、药物影响、生理性因素(妊娠期、久坐)。
十三、失眠
生理原理 失眠是睡眠启动、维持或质量异常导致的睡眠障碍,核心是睡眠-觉醒调节中枢功能紊乱、神经递质失衡(GABA减少、多巴胺增多)及昼夜节律紊乱,导致睡眠周期无法正常推进。
发展过程
- 诱因触发阶段:心理压力等导致大脑皮层兴奋,入睡时间延长,夜间易醒,日间无不适(暂时性失眠)。
- 睡眠调节紊乱阶段:诱因持续,出现入睡困难加重、频繁觉醒,日间疲劳(亚急性失眠,1-3个月)。
- 慢性化或恢复阶段:未干预则发展为慢性失眠(>3个月),伴随头痛、记忆力下降,干预后可恢复正常。
常见引发原因
- 心理与情绪因素(最常见):焦虑症、抑郁症、急性应激、睡前焦虑。
- 环境与生活习惯因素:环境变化、不良睡眠习惯、睡前摄入刺激性物质。
- 疾病因素:躯体疾病(疼痛、咳嗽等)、精神疾病、内分泌疾病(甲亢等)。
- 药物与生理因素:药物影响、生理阶段变化(青少年、妊娠期、老年)。
- 其他因素:昼夜节律紊乱、睡眠相关运动障碍、睡前过度运动。
十四、流涕
生理原理 流涕是鼻腔黏膜分泌异常增多或血管通透性增加导致的黏液流出,核心是黏膜受刺激后黏液腺分泌亢进、血管扩张,黏液量超过清除能力,进而流出鼻腔。
发展过程
- 诱因触发阶段:感染、过敏等刺激鼻腔黏膜,释放炎症介质,黏液腺开始加速分泌,表现为鼻腔轻微不适。
- 分泌增多与流涕阶段:黏液分泌显著增加,形成鼻涕(清水样、脓性等),伴随鼻塞、鼻痒等。
- 愈合或慢性化阶段:诱因短暂则数天内缓解,持续则流涕反复,引发鼻后滴漏综合征。
常见引发原因
- 局部因素(最常见):呼吸道感染(感冒、鼻窦炎等)、过敏性疾病(过敏性鼻炎)、物理化学刺激、鼻腔结构异常(鼻中隔偏曲等)。
- 全身因素:全身性过敏反应、内分泌疾病(甲减等)、神经系统疾病(自主神经功能紊乱)。
- 其他因素:药物副作用、鼻腔异物、术后反应。
十五、声音嘶哑
生理原理 声音嘶哑是声带振动或功能障碍引发的发声异常,核心是声带黏膜充血、水肿、损伤等,导致声带振动与闭合异常,影响气流控制与声音共鸣。
发展过程
- 诱因触发阶段:感染、过度用嗓等导致声带轻微充血水肿,声音轻微变粗,休息后缓解。
- 症状显现阶段:声带病变加重,出现小结、息肉等,声音嘶哑明显,伴随喉部不适。
- 愈合或慢性化阶段:诱因短暂则1-2周内缓解,持续则症状反复,严重时失声。
常见引发原因
- 局部因素(最常见):喉部感染(急性/慢性喉炎)、用嗓过度或不当、喉部外伤、喉部结构异常、喉部肿瘤。
- 神经因素:喉返神经损伤(手术误伤、肿瘤压迫等)。
- 全身因素:内分泌异常、自身免疫病、全身性感染、脱水或环境因素。
- 其他因素:药物副作用、胃食管反流、精神心理因素。
十六、烧心
生理原理 烧心是胸骨后或剑突下的烧灼感,核心是胃食管内容物(主要是胃酸)反流至食管,刺激食管黏膜引发炎症或损伤,食管黏膜缺乏黏液保护屏障,易被胃酸腐蚀。
发展过程
- 诱因触发阶段:食管下括约肌松弛等导致少量胃酸反流,表现为胸骨后轻微灼热感,站立后缓解。
- 症状显现阶段:反流频率增加,食管黏膜充血水肿,烧灼感加重,放射至咽喉部,餐后或平卧时明显。
- 愈合或慢性化阶段:诱因短暂则数天内缓解,持续则进展为食管炎,甚至Barrett食管。
常见引发原因
- 消化系统疾病(核心诱因):胃食管反流病、反流性食管炎、胃炎、胃溃疡、食管裂孔疝等。
- 饮食与生活习惯因素:饮食不当、暴饮暴食、肥胖、妊娠、吸烟。
- 药物与生理因素:药物影响、生理阶段变化、精神心理因素。
- 其他因素:食管动力障碍、胃排空延迟、长期便秘。
十七、口臭
生理原理 口臭是口腔或全身疾病引发的口腔异味,核心是口腔细菌分解有机物产生挥发性硫化物,或全身疾病异味物质经呼吸道排出。分为口源性(80%-90%)和非口源性两类。
发展过程
- 诱因触发阶段:口腔卫生差等导致细菌滋生,异味轻微,刷牙后缓解。
- 异味显现阶段:细菌大量繁殖,异味加重,伴随牙龈出血等,刷牙后缓解不明显。
- 持续或缓解阶段:诱因短暂则1-2天内缓解,持续则口臭反复,影响社交。
常见引发原因
- 口源性因素(最常见):口腔卫生不佳、牙周疾病、口腔感染与损伤、口腔黏膜疾病、饮食与生活习惯。
- 非口源性因素:消化系统疾病(胃食管反流病等)、呼吸道疾病(鼻窦炎等)、全身性疾病(糖尿病酮症酸中毒等)。
- 其他因素:口腔干燥、药物副作用、精神心理因素。
十八、腰背酸痛
生理原理 腰背酸痛是腰背部组织受损或功能异常引发的疼痛,核心是局部组织劳损、炎症等激活痛觉感受器,信号传导至中枢产生痛感,严重时伴随神经受压症状。
发展过程
- 诱因触发阶段:久坐、负重等导致肌肉紧张,代谢产物堆积,表现为轻微酸胀,休息后缓解。
- 症状显现阶段:劳损加重,炎症介质释放,酸痛持续,伴随下肢放射痛,活动受限。
- 愈合或慢性化阶段:诱因短暂则1-2周内缓解,持续则发展为慢性酸痛,伴随脊柱侧弯等。
常见引发原因
- 肌肉骨骼与软组织因素(最常见):肌肉劳损、韧带损伤、筋膜炎症、脊柱退变、椎间盘突出。
- 神经因素:神经根受压、带状疱疹病毒感染、脊髓病变。
- 全身与疾病因素:骨质疏松、风湿免疫病、感染性疾病、内脏疾病牵涉痛。
- 其他因素:姿势与生活习惯、外伤、肥胖、精神心理因素。
十九、关节疼痛
生理原理 关节疼痛是关节及周围组织受损、炎症引发的不适,核心是炎症介质释放激活痛觉感受器,或关节结构破坏导致机械性压迫,引发疼痛。
发展过程
- 诱因触发阶段:外伤、劳损等导致关节轻微损伤,表现为轻微酸痛,休息后缓解。
- 症状显现阶段:炎症加重,关节肿胀、疼痛明显,活动时加剧,伴随僵硬。
- 愈合或慢性化阶段:诱因短暂则1-2周内缓解,持续则关节结构破坏,疼痛反复,伴随畸形。
常见引发原因
- 关节及周围组织病变(最常见):退行性关节病(骨关节炎)、滑膜炎、韧带与肌腱损伤、软骨损伤。
- 全身性疾病:风湿免疫病(类风湿关节炎、痛风等)、感染性疾病(化脓性关节炎等)、代谢性疾病(骨质疏松等)。
- 其他因素:外伤、肥胖、药物影响、精神心理因素。
二十、耳鸣
生理原理 耳鸣是无外界声源时的异常声音感知,核心是听觉系统结构或功能异常,导致神经信号异常发放或中枢解读紊乱,多为主观性耳鸣。
发展过程
- 诱因触发阶段:噪音、感染等导致耳蜗毛细胞轻微损伤,耳鸣短暂,安静环境下察觉。
- 症状显现阶段:毛细胞损伤加重,耳鸣持续,伴随轻度听力下降、烦躁。
- 愈合或慢性化阶段:诱因短暂则1-2周内缓解,持续则发展为慢性耳鸣,伴随失眠、焦虑。
常见引发原因
- 听觉系统局部病变(最常见):耳部感染与损伤、内耳疾病、听神经与中枢病变、耳部衰老。
- 全身性疾病:心血管疾病、代谢与内分泌疾病(糖尿病等)、其他(肾功能不全等)。
- 环境与生活习惯因素:噪音暴露、不良生活习惯、精神心理因素。
- 其他因素:药物副作用、年龄因素、头部外伤、气压损伤。
二十一、皮肤脱皮
生理原理 皮肤脱皮是角质层代谢异常或屏障受损导致的表层细胞异常脱落,核心是角质细胞生成与脱落失衡,或屏障受损导致细胞黏附力下降。
发展过程
- 诱因触发阶段:干燥、刺激等导致屏障轻微受损,皮肤轻微粗糙,少量细小鳞屑。
- 症状显现阶段:屏障进一步受损,片状脱屑明显,伴随发红、瘙痒。
- 愈合或慢性化阶段:诱因短暂则1-2周内缓解,持续则脱皮反复,伴随皮肤增厚。
常见引发原因
- 皮肤局部因素(最常见):皮肤干燥与环境因素、炎症性皮肤病、感染性皮肤病、物理化学刺激、皮肤损伤后修复。
- 全身性疾病:代谢与内分泌疾病、自身免疫病、感染性疾病、营养缺乏(维生素A、E缺乏)。
- 其他因素:药物副作用、精神心理因素、不良生活习惯、遗传性疾病(鱼鳞病)。
二十二、多尿
生理原理 多尿是单位时间内尿量显著增多(成人24小时>2500ml),核心是肾脏滤过与重吸收失衡,抗利尿激素缺乏/作用障碍、肾小管受损等导致水分重吸收减少,终尿生成增多。
发展过程
- 诱因触发阶段:饮水过多等导致尿量轻度增多,排尿次数增加,伴轻微口渴。
- 症状显现阶段:肾脏功能异常加重,尿量显著增多,伴明显口渴多饮,电解质流失引发乏力。
- 愈合或慢性化阶段:诱因短暂则1-2周内缓解,持续则多尿反复,伴随电解质紊乱。
常见引发原因
- 内分泌与代谢疾病(最常见):糖尿病、尿崩症、甲状腺功能亢进、原发性醛固酮增多症。
- 肾脏疾病:肾小管功能障碍、肾小球疾病、肾移植术后。
- 药物与饮食因素:药物影响(利尿剂等)、短期大量饮水或高糖饮食。
- 其他因素:中枢神经系统疾病、精神心理因素(精神性多饮)、感染性疾病。
二十三、血尿
生理原理 血尿是尿液中红细胞异常增多,核心是泌尿系统血管破裂或肾小球滤过膜受损,红细胞漏出至尿液,分为镜下血尿(离心尿每高倍视野≥3个红细胞)和肉眼血尿(每升尿液含血量≥1ml)。
发展过程
- 诱因触发阶段:感染、结石等导致血管轻微损伤,表现为镜下血尿,可能伴随轻微不适。
- 症状显现阶段:血管损伤加重,出血量增多,出现肉眼血尿,伴随腰部绞痛、尿频尿急等。
- 愈合或慢性化阶段:诱因短暂则1-2周内缓解,持续则血尿反复,伴随贫血、肾功能下降。
常见引发原因
- 泌尿系统局部疾病(最常见):肾小球疾病、尿路结石、感染性疾病、尿路肿瘤、尿路损伤、尿路畸形。
- 全身性疾病:凝血功能异常、自身免疫病、感染性疾病、代谢性疾病。
- 其他因素:药物副作用、剧烈运动、女性特殊时期、血管性疾病、精神心理因素。
二十四、胸闷、气短
生理原理 胸闷是胸部压迫感,气短是呼吸费力,二者常并存,核心是心肺功能异常导致供氧不足、二氧化碳潴留,或胸壁胸膜病变引发机械性呼吸受限。
发展过程
- 诱因触发阶段:劳累等导致气道轻微痉挛、心肌短暂缺血,活动后短暂胸闷气短,休息后缓解。
- 症状显现阶段:心肺功能异常加重,静息状态下也出现胸闷气短,伴随呼吸加快、口唇发绀等。
- 愈合或慢性化阶段:诱因短暂则1-2周内缓解,持续则症状反复加重,甚至出现端坐呼吸。
常见引发原因
- 心血管系统疾病(核心诱因):心力衰竭、冠心病、心肌梗死、心律失常、心包疾病。
- 呼吸系统疾病:气道阻塞性疾病、肺部感染、肺实质与间质疾病、胸膜疾病、肺血管疾病。
- 胸壁与胸廓疾病:胸壁肌肉损伤、肋骨骨折、胸廓畸形、肋软骨炎。
- 其他因素:精神心理因素、贫血、肥胖、药物副作用、环境因素。
二十五、心悸
生理原理 心悸是主观上对心脏跳动的异常感知(过快、过慢、不规律等),核心是心脏节律、频率异常或心肌收缩力改变,异常信号经自主神经传入中枢引发不适。
发展过程
- 诱因触发阶段:劳累等导致窦房结兴奋性升高,出现偶发早搏,活动后短暂心悸,休息后缓解。
- 症状显现阶段:心脏异常加重,静息状态下也出现心悸,伴随胸闷、头晕、脉搏不规律。
- 愈合或慢性化阶段:诱因短暂则1-2天内缓解,持续则心悸反复,严重时出现晕厥、心力衰竭。
常见引发原因
- 心血管系统疾病(核心诱因):心律失常、冠心病、心力衰竭、心肌病、心包疾病。
- 全身性疾病:内分泌与代谢异常、血液系统疾病、感染性疾病、电解质紊乱。
- 药物与物质因素:药物副作用、物质摄入(咖啡因等)、药物过量。
- 精神心理与神经因素:精神心理异常、神经功能失调、中枢神经系统疾病。
- 其他因素:生理性因素、环境与生活习惯、胸部外伤。
省钱就医
省钱就医核心要点
一、医院选对:小病别跑大医院!
- 🌟 社区/乡镇医院(一级):感冒、高血压、慢病随访 → 挂号 5-20 元,医保报 90%,自付 0-2 元(最省钱)
- 🌟 二级医院:肠胃炎、骨折、常见手术 → 挂号 10-30 元,医保报 65-85%,自付 2-10 元
- 🌟 三甲医院:肿瘤、疑难杂症、复杂手术 → 仅这类病去,别拿感冒凑数(挂号 + 检查都贵)
二、医护等级速查:选对人更省钱!
(一)医生等级(从低到高)
| 等级 | 职称 | 适用场景 | 挂号费 | 核心作用 |
|---|---|---|---|---|
| 初级 | 住院医师 | 初诊基础诊疗、病历记录、简单开药 | 5-20元 | 搞定普通小病,做基础检查 |
| 中级 | 主治医师 | 独立处理常见病、慢病管理、常规手术 | 20-50元 | 80% 常见病首选,性价比最高 |
| 高级 | 副高/主任医师 | 专科疑难病、复杂并发症、高难度操作 | 50-100元 | 确诊后复诊、普通病治疗效果不佳 |
| 高级 | 主任医师 | 罕见病、疑难重症、学科带头人 | 100-200元 | 仅重症/难治病例挂,别盲目抢 |
(二)护士等级(从低到高)
| 等级 | 职称 | 职责范围 | 适用场景 |
|---|---|---|---|
| 初级 | 护士/护师 | 基础护理(打针、输液、测血压) | 普通门诊、住院日常护理 |
| 中级 | 主管护师 | 专科护理(糖尿病护理、伤口护理)、指导初级护士 | 专科门诊、术后护理、慢病随访 |
| 高级 | 副主任护师/主任护师 | 护理管理、疑难病例护理指导、教学科研 | 重症监护室(ICU)、护理会诊、护士长 |
三、挂号省钱:5个关键词!
- 🌟 优先医保:带身份证 + 医保卡(或电子医保),挂号直接选“医保支付”,自动减钱
- 🌟 优先普通号:初诊先挂住院/主治医师号,做基础检查,需要再转专家(省一半钱)
- 🌟 优先社区:社区挂号最便宜、报销最高,65 岁以上老人常免挂号费
- 🌟 错峰挂号:避开周一上午、节假日后 → 选周四/五下午,人少不用等,号源多
- 🌟 线上挂号:医院 APP / 微信公众号 / 支付宝 → 无手续费,提前 7-15 天约(比现场好抢)
四、看病再省:3个实用技巧!
- 🌟 带齐旧报告:别让医生重复开检查(省 200-500 元)
- 🌟 问清医保范围:医生开单前问“这项目医保能报吗” → 避开自费坑
- 🌟 社区转诊:先去社区开转诊单,再去上级医院 → 报销比例能提高(多省 10-20%)
五、黄金法则(记牢不花冤枉钱)
- 小病 → 社区 + 住院/主治医师 + 医保 = 几乎不花钱
- 中病 → 二级医院 + 主治医师 + 普通号 = 少花钱
- 大病 → 三甲 + 副高/主任医师 + 转诊 = 花在刀刃上
家庭常用药品实用指南
一、核心药品分类对比(一看就懂)
(一)处方药(Rx)vs 非处方药(OTC)
| 对比维度 | 处方药(Rx) | 非处方药(OTC) |
|---|---|---|
| 怎么认 | 包装标 “Rx”,必须要医生开处方才能买 | 包装标 “OTC”(红/绿色),超市/药店直接买,不用处方 |
| 治啥病 | 重病(肺炎、高血压、糖尿病)、有风险的病 | 小毛病(感冒、咳嗽、拉肚子、轻微擦伤) |
| 优点 | 疗效准,针对重病,医生指导更安全 | 买着方便、价格便宜、用着简单 |
| 缺点 | 买着麻烦(得去医院开方)、价格偏贵、副作用可能大 | 疗效有限,治不了重病;用错可能耽误病情 |
| 价格 | 偏贵(比如抗生素 50-200 元/盒) | 便宜(比如感冒药 10-30 元/盒) |
| 常见例子 | 阿莫西林、降压药、降糖药 | 感冒灵、退烧药(美林/泰诺林)、创可贴 |
(二)原研药 vs 仿制药
| 对比维度 | 原研药 | 仿制药 |
|---|---|---|
| 怎么认 | 有专属商品名(比如 “泰诺林”“美林”),原厂家生产(如辉瑞),价格贵 | 多是通用名(比如 “对乙酰氨基酚混悬液”),国内厂家生产,价格低 |
| 核心区别 | 第一个研发的药,测试充分,疗效稳 | 原研药专利到期后仿制,成分一样,过了 “效果一致测试” |
| 优点 | 安全性明确,适合新生儿、孕妇等特殊人群 | 价格只占原研药 30%-70%,买着方便,医保能报 |
| 缺点 | 价格太贵,长期吃负担重 | 少数没通过测试的,疗效可能稍差 |
| 价格 | 贵(比如原研退烧药 30-50 元/瓶) | 便宜(比如仿制药退烧药 10-20 元/瓶) |
| 常见例子 | 泰诺林、希刻劳(抗生素)、络活喜(降压药) | 国产对乙酰氨基酚混悬液、恒瑞头孢克洛颗粒 |
二、药品剂型选择指南(避坑省钱)
| 剂型 | 特点(性价比) | 适用人群/场景 | 溢价情况 | 关键提醒 |
|---|---|---|---|---|
| 片剂/胶囊 | 工艺简单、价格最低、药效稳 | 能正常吞咽的人,治普通感冒、感染、慢性病 | 最低(无溢价,省钱首选) | 能吃片剂就别买贵的剂型 |
| 分散片/泡腾片 | 溶解快、不用硬咽(泡腾片冲水喝) | 老人、小孩、吞药片困难的人 | 比普通款贵 3-5 成(图方便可选) | 非刚需没必要花冤枉钱 |
| 缓释/控释片 | 长效(1天1-2次)、不用频繁吃药 | 高血压、糖尿病等慢性病患者 | 比普通款贵 5成-1倍 | 处方药,遵医嘱,千万别掰开吃 |
| 口服液/糖浆 | 口感甜、不用嚼、易吸收 | 3岁以下小孩、肠胃敏感的人 | 比普通款贵 1-2倍(含甜味辅料) | 孩子不抗拒再选,优先买仿制药 |
| 颗粒剂 | 冲水喝、剂量好调、口感温和 | 婴幼儿、怕苦的人、吞咽困难者 | 比普通款贵 5-8成 | 比口服液便宜,儿童常用 |
| 软膏剂/乳膏剂 | 外用直接涂、温和不刺激 | 皮肤过敏、湿疹、轻微擦伤 | 比普通外用款贵 3-5成 | 外用刚需,价格差别不大 |
剂型选择核心原则:
有效成分一样!剂型只影响怎么吃,不影响效果!能选片剂/胶囊,就不买口服液/糖浆,能省50%以上的钱。
三、高性价比常见药品清单(按场景分)
🌡️ 感冒退烧类
-
对乙酰氨基酚片
- 核心功能:退烧、止轻中度痛
- 能治啥:感冒发烧、头痛、关节痛
- 仿制药价格:5-15元(100片)
- 避坑提示:别和其他感冒药一起吃,怕成分过量伤肝
-
布洛芬混悬液(儿童)
- 核心功能:退烧、止痛
- 能治啥:0-12岁儿童发烧,持续6-8小时
- 仿制药价格:10-20元(100ml)
- 避坑提示:38.5℃以上用,按年龄/体重给药
-
复方氨酚烷胺片
- 核心功能:缓解感冒多种症状
- 能治啥:普通感冒/流感:发烧、鼻塞、流涕
- 仿制药价格:8-15元(20片)
- 避坑提示:成人吃,服药别喝酒
-
感冒灵颗粒
- 核心功能:疏风解表、清热解毒
- 能治啥:感冒引起的头痛、发热、咽痛
- 仿制药价格:10-15元(10袋)
- 避坑提示:含咖啡因,睡前别多喝
🤢 消化不适类
-
健胃消食片
- 核心功能:助消化、开胃口
- 能治啥:积食、腹胀、没胃口(成人/儿童)
- 仿制药价格:5-10元(36片)
- 避坑提示:儿童减量,没副作用
-
蒙脱石散
- 核心功能:止泻、保护肠黏膜
- 能治啥:成人/儿童拉肚子、水样便
- 仿制药价格:8-15元(10袋)
- 避坑提示:和别的药隔开1-2小时吃
-
多潘立酮片
- 核心功能:促胃动力
- 能治啥:胃胀、嗳气、饭后胀得慌
- 仿制药价格:10-20元(30片)
- 避坑提示:成人吃,饭前15-30分钟吃
-
铝碳酸镁咀嚼片
- 核心功能:中和胃酸、护胃
- 能治啥:胃痛、反酸、烧心
- 仿制药价格:15-25元(50片)
- 避坑提示:嚼着吃,饭后1-2小时吃
🤧 皮肤问题类
-
炉甘石洗剂
- 核心功能:止痒、收敛
- 能治啥:湿疹、痱子、蚊虫叮咬、皮肤痒
- 仿制药价格:5-10元(100ml)
- 避坑提示:外用涂抹,成人小孩都能用
-
红霉素软膏
- 核心功能:外用消炎杀菌
- 能治啥:脓疱疮、毛囊炎、轻微擦伤感染
- 仿制药价格:3-8元(10g)
- 避坑提示:别碰到眼睛
-
氯雷他定片
- 核心功能:抗过敏
- 能治啥:过敏性鼻炎、皮肤过敏痒
- 仿制药价格:10-20元(14片)
- 避坑提示:成人/6岁以上用,吃了不犯困
-
盐酸特比萘芬乳膏
- 核心功能:抗真菌
- 能治啥:脚气、手癣、体癣(脱皮/水泡)
- 仿制药价格:8-15元(15g)
- 避坑提示:症状消失后再用1周,别断药复发
🩹 外伤处理类
-
碘伏
- 核心功能:皮肤消毒
- 能治啥:擦伤、割伤、黏膜消毒
- 仿制药价格:3-5元(60ml)
- 避坑提示:比酒精温和,不刺激伤口,儿童能用
-
创可贴(普通款)
- 核心功能:止血、护伤口
- 能治啥:轻微擦伤、割伤临时保护
- 仿制药价格:2-5元(20片)
- 避坑提示:选透气的,伤口化脓了就别用
-
云南白药气雾剂
- 核心功能:消肿止痛、散瘀
- 能治啥:跌打损伤、肌肉酸痛、关节肿痛
- 仿制药价格:20-30元(60ml)
- 避坑提示:别喷在破皮肤上
🫁 呼吸道不适类
-
川贝枇杷膏(普通款)
- 核心功能:润肺、止咳、化痰
- 能治啥:干咳、少痰、咽痛
- 仿制药价格:10-18元(150ml)
- 避坑提示:含糖,糖尿病患者别用
-
西瓜霜含片
- 核心功能:清热、消肿、止痛
- 能治啥:咽喉肿痛、口舌生疮、扁桃体发炎
- 仿制药价格:5-10元(24片)
- 避坑提示:含着吃,孕妇慎用
-
盐酸氨溴索口服溶液
- 核心功能:稀释痰液、帮着排痰
- 能治啥:痰多黏稠(感冒/肺炎后期)
- 仿制药价格:10-15元(100ml)
- 避坑提示:成人/2岁以上用,按年龄减量
👁️ 眼部问题类
-
左氧氟沙星滴眼液
- 核心功能:眼部消炎杀菌
- 能治啥:细菌性结膜炎、麦粒肿(针眼)
- 仿制药价格:10-20元(5ml)
- 避坑提示:滴眼睛用,开封后1个月内用完
-
玻璃酸钠滴眼液(无防腐剂)
- 核心功能:滋润眼球、缓解干涩
- 能治啥:干眼症、视疲劳(长时间看手机)
- 仿制药价格:15-25元(10支)
- 避坑提示:无防腐剂更安全,不含抗生素
-
红霉素眼膏
- 核心功能:眼部外用消炎
- 能治啥:眼睑炎、结膜炎、新生儿泪囊炎
- 仿制药价格:3-8元(2g)
- 避坑提示:涂眼内或眼皮边缘
👄 口腔问题类
-
甲硝唑含漱液
- 核心功能:口腔消炎杀菌
- 能治啥:牙龈炎、牙周炎、口腔溃疡炎症
- 仿制药价格:8-15元(200ml)
- 避坑提示:含着漱口,别咽下去,孕妇/哺乳期禁用
-
口腔溃疡散
- 核心功能:消肿、止痛、促愈合
- 能治啥:口腔溃疡、创面疼痛
- 仿制药价格:3-6元(3g)
- 避坑提示:棉签涂患处,别吃辛辣过烫的食物
-
维生素 B2 片
- 核心功能:补充维生素 B2
- 能治啥:口角炎、舌炎(烂嘴角、舌头痛)
- 仿制药价格:5-10元(100片)
- 避坑提示:吃多了尿黄,是正常现象
🚺 妇科基础类(外用)
-
甲硝唑栓
- 核心功能:阴道消炎杀菌
- 能治啥:细菌性/滴虫性阴道炎(白带异味/痒)
- 仿制药价格:10-15元(7粒)
- 避坑提示:外用栓剂,用药期间别同房
-
洁尔阴洗液(普通款)
- 核心功能:清热、止痒
- 能治啥:外阴瘙痒(外阴炎/日常护理)
- 仿制药价格:15-25元(200ml)
- 避坑提示:稀释后洗外阴,别冲阴道内部,孕妇禁用
-
克霉唑栓
- 核心功能:阴道抗真菌
- 能治啥:霉菌性阴道炎(白带豆腐渣样/痒)
- 仿制药价格:10-18元(5粒)
- 避坑提示:按疗程用7天,别断药复发
🚽 泌尿系统类
-
三金片
- 核心功能:清热、通淋
- 能治啥:尿频、尿急、尿痛(尿路感染初期)
- 仿制药价格:10-18元(36片)
- 避坑提示:成人吃,多喝温水,严重了要搭抗生素
-
左氧氟沙星片(处方药)
- 核心功能:泌尿系统消炎杀菌
- 能治啥:膀胱炎、肾盂肾炎等感染
- 仿制药价格:15-25元(12片)
- 避坑提示:处方药,18岁以下禁用
-
金钱草颗粒
- 核心功能:利尿、排小结石
- 能治啥:泌尿系小结石、尿路感染辅助治疗
- 仿制药价格:8-15元(10袋)
- 避坑提示:结石大了要去医院,别自己吃药
🥛 维生素补充类
-
维生素 C 片(普通款)
- 核心功能:补充维 C、增强抵抗力
- 能治啥:牙龈出血、辅助感冒恢复
- 仿制药价格:3-8元(100片)
- 避坑提示:每天1片就行,吃多了可能拉肚子
-
复合维生素 B 片
- 核心功能:补充 B 族维生素
- 能治啥:脚气病、皮炎、容易疲劳
- 仿制药价格:5-10元(100片)
- 避坑提示:饮食不均衡、经常熬夜的人适合吃
-
碳酸钙 D3 片(普通款)
- 核心功能:补钙 + 补维生素 D
- 能治啥:儿童佝偻病、老人骨质疏松(缺钙)
- 仿制药价格:15-25元(60片)
- 避坑提示:饭后吃,别和浓茶、咖啡一起吃(影响吸收)
💊 慢性病基础类(处方药)
-
苯磺酸氨氯地平片
- 核心功能:降压
- 能治啥:高血压,1天1片平稳降压
- 仿制药价格:10-20元(50片)
- 避坑提示:遵医嘱吃,定期测血压
-
二甲双胍片
- 核心功能:降糖
- 能治啥:2型糖尿病,控制餐后血糖
- 仿制药价格:5-15元(100片)
- 避坑提示:遵医嘱吃,别空腹吃太多
-
头孢氨苄胶囊(处方药)
- 核心功能:口服消炎杀菌
- 能治啥:轻度呼吸道/泌尿系统/皮肤感染
- 仿制药价格:8-15元(50粒)
- 避坑提示:头孢过敏者禁用,吃药别喝酒
-
阿莫西林胶囊(处方药)
- 核心功能:广谱消炎杀菌
- 能治啥:中耳炎、鼻窦炎、扁桃体炎等感染
- 仿制药价格:10-18元(50粒)
- 避坑提示:青霉素过敏者禁用
四、通用避坑 & 安全用药提醒(必看)
1. 省钱核心技巧
- 优先选通用名 + 片剂/胶囊,同款药仿制药比原研药便宜30%-70%
- 非处方药选绿色 OTC(乙类),比红色 OTC(甲类)更安全、更便宜
- 长期吃药主动问药师:“有没有效果和原研药一样的仿制药?” 医保报完更划算
2. 安全用药重点(一句话避坑)
- 处方药必须听医生的,别自己买着吃(比如头孢、左氧氟沙星),怕过敏或耐药
- 孩子用药:0-28天新生儿所有药要医生开方;3岁以下选颗粒/混悬液,按年龄/体重给药
- 别叠加吃药(比如吃了复方感冒药,别再单独吃退烧药),避免成分过量
- 眼药、妇科药等外用黏膜药,按说明书用,开封后及时用完
- 维生素、钙片每天1片就行,吃多了可能伤肝、长结石
3. 特殊人群禁忌(❌ 明确禁用)
- 孕妇/哺乳期:禁用甲硝唑类(口服/外用)、含伪麻黄碱的感冒药
- 18岁以下:禁用左氧氟沙星(影响骨骼发育)
- 糖尿病患者:慎用含糖的药(比如川贝枇杷膏、糖浆)
- 过敏体质:吃头孢、青霉素前,确认自己不过敏
五、医保 & 集采药终极省钱攻略(省最多)
(一)医保省钱技巧(直接减钱,必用!)
-
慢特病备案(关键!):高血压、糖尿病等62种慢性病,备案后门诊买药报销70%-95%,比不备案多报10%-25%
- 备案材料:身份证/社保卡 + 医生开的诊断证明 + 近期检查报告
- 办理方式:① 线上(国家医保APP搜“慢特病备案“上传材料,20天左右生效);② 线下(社区卫生服务中心/医院医保科,3-15天生效);③ 行动不便可申请上门办理(免费)
-
定点机构买药:去医保定点药店/医院买,能刷医保卡,处方药报销比例更高
-
异地就医先备案:异地看病买药,提前备案后能直接刷社保卡结算,不用攒单据回参保地报
-
查医保目录:用“国家医保服务平台APP“查药品能不能报,优先选“甲类药“(报销比例最高)
(二)集采药省钱技巧(价格腰斩,闭眼冲!)
-
啥是集采药:国家“团购“药品,砍掉中间加价,价格平均降50%以上,部分降90%,且效果和原研药一样
-
怎么认集采药:① 药店有“集采药品“专区/标识,包装可能标“国家集采“;② 同款药比普通仿制药便宜30%-50%(比如原研降压药50元/盒,集采药可能才10-15元)
-
购买渠道:① 医院/医保定点药店(步行15分钟内基本能找到);② 线上医保定点平台(支持比价)
-
省钱关键:① 集采药药店加价不超15%,用当地“医保药品比价“小程序查,价比三家;② 慢性病优先选集采药,长期吃每年能省几千元;③ 集采药能叠加医保报销(先享低价,再报一部分)
(三)医保 + 集采叠加用法(省最多!)
-
慢性病患者:办慢特病备案 → 让医生开集采药处方 → 去定点药店买 → 直接刷社保卡(集采低价 + 医保报销,最后只花少量钱)
-
普通患者:感冒、感染等常见病,优先选医保目录里的集采药(比如阿莫西林、对乙酰氨基酚),药店直接买能刷医保,比普通仿制药便宜一半
-
注意:集采药供应充足,药店至少有50种常用集采药,没货可提前打电话问
体检指标
健康体检核心指标参考表
一般体格检查
| 指标名称 | 理想范围 | 异常说明 | 关键备注 |
|---|---|---|---|
| 身高体重(BMI) | 18.5~23.9 kg/m² | 100 次/分 = 心动过速(贫血、甲亢、感染等可能) | 静息状态测量 |
| 血氧饱和度 | 95%~98% | 1.04 mmol/L;女性 > 1.29 mmol/L | 降低 = 心血管疾病风险升高(“好胆固醇” 不足) |
| 低密度脂蛋白(LDL-C) | 1.5 提示酒精性肝损伤 | ||
| 血肌酐(Cr) | 男性 53~106 μmol/L;女性 44~97 μmol/L | 升高 = 肾小球滤过功能下降(肾功能受损),需结合尿素氮综合判断 | 肌肉量多者可能偏高(生理性差异) |
| 血尿素氮(BUN) | 3.2~7.1 mmol/L | 升高 = 肾功能受损、脱水、高蛋白饮食;降低 = 营养不良、肝病 | 需空腹,避免大量摄入肉类 |
| 血尿酸(UA) | 男性 208~428 μmol/L;女性 155~357 μmol/L | 升高 = 高尿酸血症(痛风、肾结石风险);降低 = 罕见(营养不良、肝病) | 避免高嘌呤饮食(海鲜、动物内脏、啤酒) |
| 血同型半胱氨酸(HCY) | 5~15 μmol/L | 15~30 μmol/L = 轻度升高;30~100 μmol/L = 中度升高;>100 = 重度升高(心脑血管疾病、认知障碍风险) | 2025 新增必查项目,叶酸可降低该指标 |
甲状腺功能
| 指标名称 | 理想范围 | 异常说明 | 关键备注 |
|---|---|---|---|
| 促甲状腺激素(TSH) | 0.27~4.2 μIU/ml | 升高 = 甲状腺功能减退(乏力、体重增加);降低 = 甲状腺功能亢进(心慌、消瘦) | 甲状腺功能筛查核心指标 |
| 游离甲状腺素(FT4) | 12~22 pmol/L | 升高 = 甲亢;降低 = 甲减,需结合 TSH 确诊 | 不受甲状腺结合球蛋白影响,结果更准确 |
尿常规核心指标
| 指标名称 | 理想范围 | 异常说明 | 关键备注 |
|---|---|---|---|
| 尿蛋白 | 阴性 | 弱阳性 = 生理性波动(劳累、高蛋白饮食);阳性 = 肾小球损伤、肾炎、高血压肾损害 | 建议复查尿常规 + 尿微量白蛋白 |
| 尿糖 | 阴性 | 阳性 = 糖尿病可能(需结合血糖)或肾性糖尿(肾小管功能异常) | 大量摄入甜食可能导致假性阳性 |
| 尿潜血 | 阴性 | 阳性 = 泌尿系统出血(结石、炎症、肿瘤)或红细胞破坏(溶血) | 女性需避开月经期检查 |
辅助检查
| 指标名称 | 理想范围 | 异常说明 | 关键备注 |
|---|---|---|---|
| 心电图 | 窦性心律,无明显 ST-T 改变 | 非窦性心律 = 心律失常;ST-T 段异常 = 心肌缺血、心梗可能 | 静息状态下检查,避免运动后立即检测 |
| 甲状腺超声 | 甲状腺大小正常,无结节 / 钙化 | 出现结节 = 需分级(4 级及以上需穿刺活检);钙化 = 恶性风险升高 | 甲状腺癌筛查首选项目 |
| 腹部超声(肝脾肾) | 脏器形态正常,无占位性病变 | 肝实质回声增强 = 脂肪肝;占位性病变 = 囊肿、肿瘤等需进一步检查 | 需空腹 8 小时以上(避免气体干扰) |
| 胸部低剂量 CT(40 岁 +) | 无结节 / 肿块,肺纹理清晰 | 肺纹理增粗 = 炎症 | 肺癌筛查灵敏度优于胸片,40 岁以上建议每年 1 次 |